
基于云-雾-边缘协同的变电站图模自动更新控制研究
2023-09-19 09:44周志烽朱文夏伟方文崇何超林
电气传动 2023年9期
周志烽,朱文,夏伟,方文崇,何超林
(1.中国南方电网有限责任公司,广东 广州 510000;2.南方电网数字电网研究院有限公司,广东 广州 510000)
能源互联网使用频率的大量增长,改变了电力设备原有的使用方式和信息交流方式,以物联网为载体建立了以变电站网络为核心导入循环持续可再生的理念,依托互联网技术为纽带实现了能源与信息快速融合的能源网络应用方式。能源互联网的量感知层节点的接入获得了海量数据,原有云计算层具备了相应的数据计算和存储能力。云端计算的优势是可实现规模化的存储,并实现多感知端的连接调用。在实际应用中其劣势是信息传输带宽不够,不足以支撑全部终端的快速调用[1]。面向各种专业应用特性的图形化监视与分析界面的维护平台为使用者提供强大和全面的监视、控制、分析的态势感知与态势可视化平台,其图形系统要求美观、清晰,但由于人力所限,往往只能进行局部的图形维护。因此,自动成图成为发展趋势。海量的客户端和云端之间存在一定信息通信速度的屏障,过载传输已经成为限制物联网络应用的瓶颈。在云服务器、应用终端之间爆发性传输大量数据可能引起服务中断,增加变电站图模自动更新负担,延缓了终端信息加载速度。
当前,针对变电站图模更新的研究出现了一些较好的成果。文献[2]提出一种基于Prüfer编码的随机图模型生成算法。该算法根据图模型的结构特征和参数特征等要素设计生成随机的模型,根据顶点数与度的大小生成随机结构的条件偏好网(conditional preference networks,CP-nets),其原理是通过改进Prüfer 编码得到有向无环图(directed acyclic graph,DAG)编码,又建立DAG编码与图结构的一对一映射实现图模型的随机生成。但是由于图模生成的随机性,导致其无法根据变电站的输电线路以及各个设备的变化完成图模信息的更新。文献[3]提出一种基于约束张量规范多元分解的图模生成方法。在该文献中,以社区为图模构建对象,引入稀疏张量表示,与矩阵表示相比具有更丰富的结构,使图模可靠性更高。引入约束张量近似框架,产生的约束三线性优化问题采用交替极小化处理,保证图模构建过程的收敛性。但是该方法的图模处理对计算设备的性能要求较高,无法广泛应用。
因此,本文提出一种新的基于云-雾-边缘协同技术的变电站图模自动更新控制设计方法。通过重新分配云层数据,并自动更新不同层级信息素,完成变电站图模自动更新。
1 基于云-雾-边缘协同的变电站图模自动更新控制设计
设计的变电站图模自动更新方法结合云-雾-边缘协同计算,将原有云端具备的智能计算进行“智能边缘化”。在云端存储层与终端设备层之间设有一个缓冲层,缓冲层又叫雾层,雾层能够提供适量程度的计算,并且具备短时间存储功能,还兼备终端信息快速传输通信服务,从时间角度而言,有效地缓解从用户端生成的海量数据压力。上层云端计算执行能力强,但针对图模自动更新这种数据更替敏感性要求高的业务,支撑性薄弱。在图模自动更新过程中对数据移动性、调用区域分布性有着更高的要求,同时用户端设备自身信息能耗也会随着传输节点的增加造成更多能耗。云计算是在传输宽带足够的情况下,没有延时,雾层计算更接近使用用户端,本身具备低延时快速位置感知特性,因此,选用云-雾-边缘协同技术将云端计算与雾层计算相结合,针对实际中海量感知层节点数据量实施分流执行。
1.1 设定间隔规则和存储规则
重新配置应用端数据源以及用户端数据库,变电站图模数据源通常是以图形或图例的形式存在,图例会详细描述变电站资源变化、设备运行状况,原有统一建模语言(unified modeling language,UML)的文档属性是MicroStation 开发语言(MicroStation development language,MDL),经过传输层之间的口令代换,变为可扩展标记语言(extensible markup language,XML)文档,变电站图模应用端数据源会随着传输变化改变属性。应用层的变电站图模数据一般是设备图元,并包含一一对应关系,但是在云计算层与雾层之间,需要重新定义数据源的相应层次容积规则以及间隔规则,这样经过传输变换属性后数据可保证一致[4]。不同层计算方式不同,间隔规则和容器规则对应图形模板会有差异性,因此预先给定间隔和容器的类型,方便数据传输后的直接使用。
数据存储在不同计算层级上的设计侧重有所不同,应用偏于统计,将变电站现有图像模型数据进行汇总,则建立大表或者更新图例,将具备传输关系的字段标记在表头属性中,方便上层传出调用[5-6]。但由于标记在前会带来一定的字段冗余,本文使用结构化查询语言(structured query language,SQL)语句重新编写段落属性,以获取几乎所有统计值。数据存储在雾层时,数据量会逐渐增加,同时为满足雾层的读取速度,需要数据结构尽可能紧凑,摒弃掉现有重复数据,到了云计算层后,数据存储依照数据执行方式,统一导出数据模型,使数据交互可以开放式进行,方便在云计算层的计算口令调用。
1.2 雾层重设
整个更新方法的架构设计为3层,即云层、雾层和应用层。雾层位于云层和应用层之间,设定雾层向下支持各种应用层数据的无缝导入,向上可以实现与云计算及云存储的对接。重设雾层边缘节点和边缘管理方式,边缘节点包括雾层边缘网关、边缘存储方式、雾层计算器、雾层传输等实物载体,边缘存储方式以软硬件结合的形式实现边缘节点数据的统一存储[7-8]。为实现雾层数据的更新计算,雾层计算器可以直接通过调用接口实现变电站图模数据的计算请求。因此,从功能的角度可将雾层重设分为基础资源重设、功能规划和计算管理。
基础资源重设包括连接、更新计算和存储资源方式以及虚拟化服务。基础资源连接部分不仅要满足更新相关业务传输时间的确定性和数据完整性,还要支持业务的灵活部署和实施[9]。雾层更新计算部分则采用异构计算模式,使用多重种类和数量的计算单元,并对其更新计算。存储资源方式采用时序数据库,对存储数据序数化。加入虚拟化服务极大地降低了雾层部署规模,尽可能实现集成化服务。
功能规划包括更新、分析和优化。更新领域功能实现对存储数据感知和执行,主要包括对变电站建筑变化、变电站运行管理、变电站实体数据抽象化、数据变化感知和数据变更执行功能[10]。分析领域功能为雾层提供了变电站更新数据分析、变电站原始视频图像处理、智能计算和传输数据挖掘等。在不同的场景应用中,优化领域功能涵盖了包括规则测试与执行比对、传输与控制、多元更新协同等在内的多个层次的优化。
计算管理包括基于模型的更新业务排序和对更新数据的调用。基于模型的更新业务排序包括更新图例排序、数据排序和更新执行3 层。更新业务排序负责定义接收数据的时间间隔以及时间时序属性,保证在更新请求的每个数据时序内执行相应的更新业务。更新业务排序过程中,能够替换云计算更新的部分功能,更新后的数据直接导入雾层储存模块。更新数据调用是通过SQL 语言口令、传输端口和雾层数据库等协同方式实现对更新数据的直接调用。
1.3 重新分配云层数据
重新分配云层数据方便雾层直接参与更新计算,本文采用算法实现云层数据再分配。
为了解决云层所留更新数据分配计算问题,采用一种直观的方法,设A是0~9 的整数分配变量,共有MN种分配可能,找出其中适合被雾层计算的变更数据,但是,分配方法的时间复杂度为O(MN),当N小于规定时间时可以接受,但不能随着N的增加无限量地增加时间复杂度[11]。为了便于后续更新环节,首先将整数分配变量A,松弛处理0 ≤A≤9,也就是说,云层计算约束转换为以下松弛约束可得:
对式(1)可采用重构线性化方法(reformulation linearization technique,RLT)消除所有二次项,RLT 可以线性化目标函数以及数据计算中的约束。对于二次Aα,设L=Aα,其中,L为现有等待操作数据事件,α为L=Aα下的线性化可操作性数据。A和α的范围分别为0 ≤A≤9 和0 ≤α≤9。可以将L的RLT 绑定因子乘积约束描述如下:
再将式(1)代入式(2)中,目标函数的约束条件转化为
式中:Lj为第j种现有等待操作数据事件。
通过松弛和RLT 运算获得的等价约束条件可以作为判别雾层数据的条件,将传达到云层的数据导入约束条件中,完成计算周期的数据参与云层存储或者计算,未完成周期计算的数据判定为雾层数据,打回到雾层存储中,等待雾层调用计算,至此完成云层数据重新分配。
1.4 不同层级信息素更新
上述过程使用云-雾-边缘协同技术,将云层、雾层以及应用层数据设置后,云层限流数据,雾层会完成一部分简单的更新计算,应用层直接在采集中替换更新数据便完成自动更新。
1.4.1 更新雾层信息素
雾层变电站图模自动更新,应用Lagrange 函数定义拉格朗日乘子,引入约束条件得到剩余拉格朗日乘子,每个剩余的拉格朗日乘子表示一个增广后的Lagrange 函数目标。需要说明的是Lagrange 函数目标可直接定义为变更目标,使用的约束条件相当于在Lagrange函数基础上导入罚函数的理念,得到增广Lagrange函数目标,已经满足现有雾层更新计算的替补条件,使用卡罗需-库恩-塔克(Karush Kuhn Tucker,KKT)条件确认数据中原始数据与现有数据的不同标记点,替补不同点的数据,实现雾层的自动更新计算。Lagrange函数法的求解过程如下:
式中:θ为雾层更新前变电站图模记录数据;d(θ),c(θ),v(θ)分别为Lagrange 函数的接收条件、执行约束以及增广条件。
引入拉格朗日乘子增广后求取Lagrange函数目标:
使用KKT 条件,对增广Lagrange 函数目标进行数据标记:
式中:μ为互补松弛条件;β为符合拉格朗日平稳性的增广数据。
在KKT条件下,替补不同点位的数据:
替补不同点位的数据后,雾层自动存储。被云层剥离回的数据,通过固定其中原始可行性变量得到的变量值迭代关系,判断对偶可行性变量最终收敛,得到新的更新数据,新的更新数据再进行Lagrange 函数求解,完成最终雾层信息素更新[12]。雾层信息素在变电站图模自动更新中的占比增加,显现表达过程占比也需要修订,再次通过云-雾-边缘协同技术的协调机制,对现有硬件的连接询问反馈实施“一点多对”的反馈机制,完成雾层的电站图模自动更新部分。
1.4.2 更新云层信息素
云层信息素更新过程比较简单,应用云层中包含的各类数据算法,找到已经重复的变电站数据,建立规则数据表tabu(o),将已重复的变电站数据加入到tabu(o)。为避免云端信息素包含雾层数据多,影响更新信息速率,重复的变电站图模数据加入到tabu(o)后,重新数据识别,对未更新的云层信息素依照规则进行标记[13]。allowedk为云计算可以选择的下一个变电站图模数据,寻找tabu(o)外的其他的全部数据,即allowedk={W-tabu(o)},具体的更新规则如下:
1)云端局部数据更新。当云计算选择一个数据节点替换原有节点,依据下式进行局部更新:
式中:X为除tabu(o)以外在导入数据范围内容的更新数据[14];η为初始信息素浓度值,η∈[ 0,9 ];τ为标记规则参量,一般标记在属性标记前。
2)云端全局更新。假设需要k个更新的数据经过j次完成更新,云端全局数据更新如下:
其中
式中:τ(p)为全局更新因子的标记规则参量;p为全局更新因子,p∈[0,9];Δη为变电站图模数据信息素增量;Lη为全局最优解。
按照上述规则完成云层部分的信息素更新。更新方法在建立的3 个层面上完成应用端、雾层以及云层的信息素更新,以此完成变电站图模自动更新。
2 仿真实验设计与结果分析
通过计算机仿真对比的形式,分析在不同感知层节点的接入下,数据对所提方法产生的影响,并给出评价结果。文献[2]提出了基于Prüfer编码的随机图模型更新算法,文献[3]提出了智能电网调控中心变电站图形数据即插即用技术,将上述两种方法作为参考对象,观察实验结果。
2.1 构建仿真环境
按照某大型变电站的一组母线变电站组进行仿真,变电站组电路简图如图1 所示。假设已经外接发电装置,整体都为变电结构。选择的变电站组共有2 组4 个间隔,其中,A1,A2是双母带旁母出线间隔,A3是双母出线间隔,A4是双母联间隔。A1~A4组成一个简单的双母带旁母电压等级为100 kV 的母线容器,每个间隔都保持在100 kV 电压下,所有母线间隔变压容器组成变电站图形。
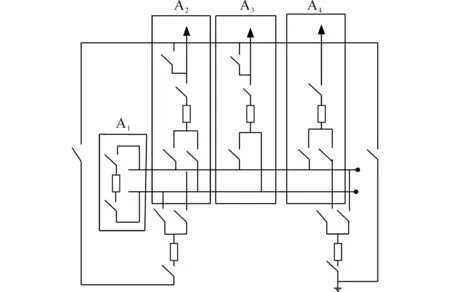
图1 实验设置的变电站组电路简图Fig.1 Circuit diagram of substation group in experiment
假设图1 中的主变压器均为多圈变,在所组成的变电站中仿真出的变电站图模满足一致性要求,仿真过程使用数据扩展后DFC31256CJKI模型。仿真的变电站增加了母线容器,同时将主变间隔分解为多个种类线圈间隔,并纳入到母线容器中,自底层向高层,分别简化为导电设备、母线容器和变电站外观形状,组成一个逐级拼装的变电站系统,方便仿真实验的进行[15-16]。
2.2 仿真分析
在此仿真中实验提供全位置感知节点,在规划电压等级下接入不同采集点,同时也可多渠道信息汇总,其中一次实验中,在原有仿真出的变电站组基础上,增加一个变电器,将原有的4个间隔变为5个间隔,采用非母线间隔形式,此时原有变电站组变为多间隔普通双母线变电站组,如图2所示。
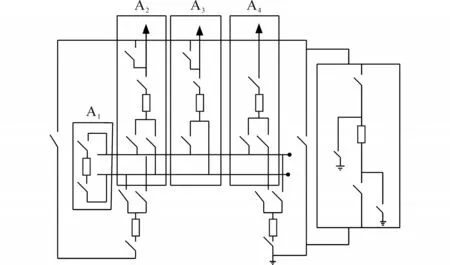
图2 增加变压设备后的变电站组Fig.2 Substation group after adding transformer equipment
随着原有变电站组的变化,接入的采集点增加,实验设计的接入点采集信息的属性会发生变化,造成每个接入点采集的数据属性都不同。使用文献[2]提出的基于Prüfer编码的随机图模型更新算法、文献[3]提出的智能电网调控中心变电站图形数据即插即用技术以及本文所提方法,共同进行变电站图模自动更新,观察不同方法下不同数据种类的变化对更新方法的数据承载的影响,实验结果如图3所示。
根据图3 所得的实验结果可知,随着接入点的增加,不同方法的信息承载量不断降低。当信息采集接入点数量达到18个时,文献[3]方法的信息承载量已经降至0 kbit,说明此时该方法的应用已经失效。当信息采集接入点数量达到24 个时,文献[2]方法的信息承载量低于1 000 kbit,相比之下,本文所提方法中此时的信息承载量为4 000 kbit。由此可知,本文所提方法依托了云-雾-边缘协同技术,将不同信息种类分层处理,极大地缓解了核心运算部分压力,因此表现出极强的信息承载能力。
在上一个仿真实验基础上,不同种类的信息接入后,汇总数据量的变化,统计数据量变化对不同方法更新的影响,结果如图4所示。
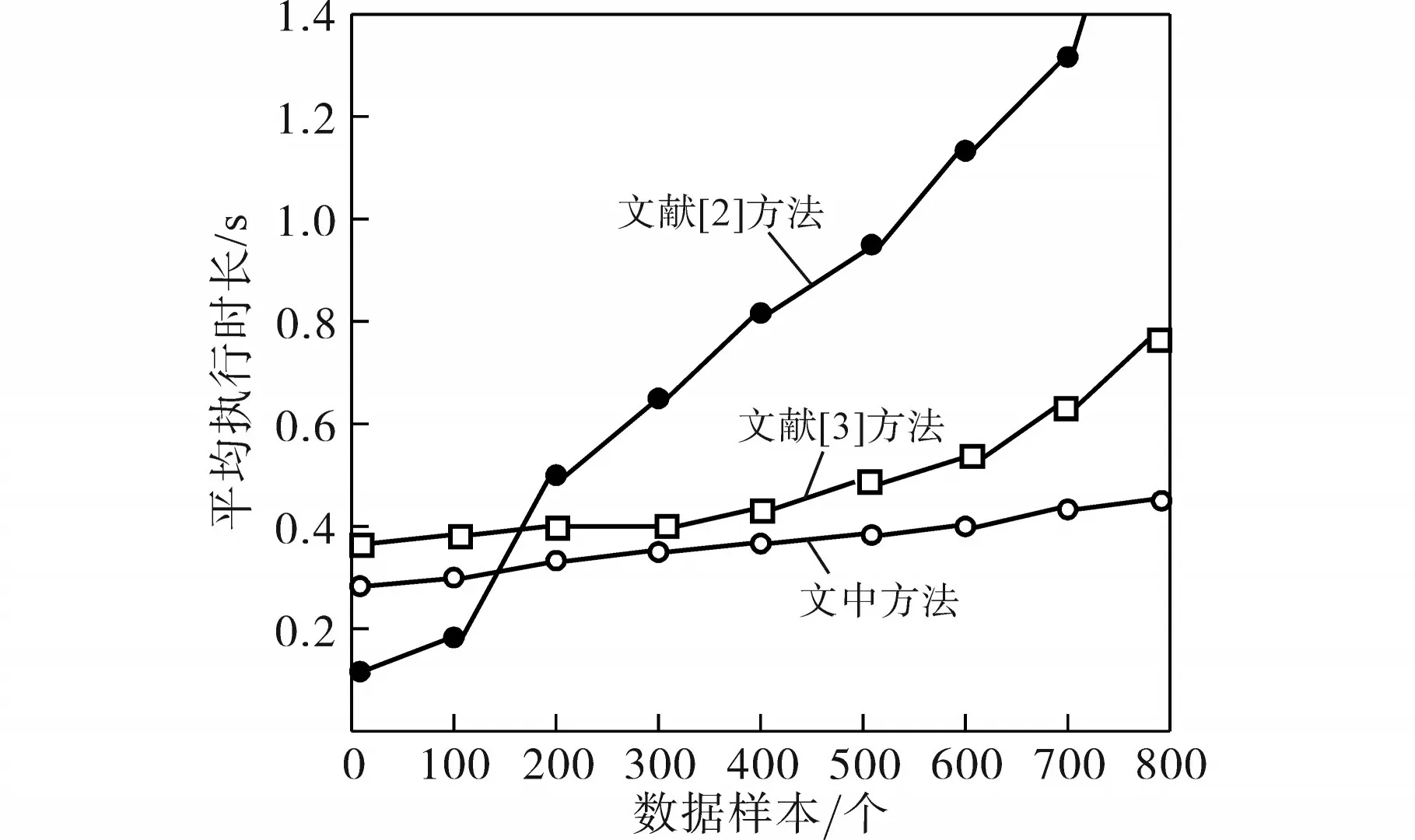
图4 数据量对不同方法的影响结果Fig.4 Effect of data volume on different methods
图4 中,变电站图模数据量的变化对不同方法的影响较大,通过几种方法的对比可知,文献[2]方法在数据样本量为700 个时,其耗时指标已经接近实验测试的极值;文献[3]方法虽然没有达到耗时的极值,但是当样本数量达到800个时,平均耗时高于0.6 s;本文研究方法的平均耗时低于0.4 s。此实验测试结果表明,本文方法能够在数据量显著增加的情况下,保持平稳的数据更新,并且稳定输出。
3 结论
为避免不同类型的数据量对变电站图模自动更新带来负担,考虑将云-雾-边缘协同技术应用在变电站图模自动更新控制上。云-雾-边缘协同技术改变原有变电站图模自下而上的更新方式,极大地优化了数据量的接收承载能力。重设雾层,采用应用层、雾层和云层的3 层配置方法,完成应用层和中心云节点之间的数据计算。重新分配云层数据,并更新不同层级信息素,实现变电站图模的自动更新。模型仿真结果表明,在不同种类信息数据的吞吐量下,所提方法能够应对自如,基本消除了数据量对变电站图模更新的影响,验证了其实际使用能力。在以后的研究中,将对不同层级信息素更新方面进一步优化,使其进一步提高变电站图模自动更新的效率。
猜你喜欢
数学小灵通(1-2年级)(2020年11期)2020-12-28
新作文·小学低年级版(2019年4期)2019-04-27
小学生学习指导(低年级)(2019年3期)2019-04-22
电子制作(2018年8期)2018-06-26
民族音乐(2018年1期)2018-04-18
电子制作(2017年8期)2017-06-05
滇池(2016年2期)2016-05-30
现代工业经济和信息化(2016年5期)2016-05-17
河南电力(2015年5期)2015-06-08
读写算·小学低年级(2014年4期)2014-07-24
