
基于Transformer 和多尺度CNN 的图像去模糊
2023-09-18 04:36李现国
计算机工程 2023年9期
李现国,李 滨
(1.天津工业大学 电子与信息工程学院,天津 300387;2.天津市光电检测技术与系统重点实验室,天津 300387)
0 概述
图像去模糊是利用图像处理技术将模糊图像恢复成有清晰边缘结构和丰富细节的图像。由于造成图像模糊的原因很多,因此图像去模糊问题是一个有多个未知解的高度不适定问题。在图像去模糊任务中,传统方法多数是将其建模为模糊核估计问题进行求解,但在现实世界中模糊核是未知的且非常复杂,最终会因为模糊核估计的不准确而导致模糊图像的恢复效果不佳。传统图像去模糊方法主要有基于最大后验概率(Maximum A Posterior,MAP)[1-3]、基于变分贝叶斯(Variational Bayesian,VB)[4-5]和基于LMS 自适应算法[6]。通过将原始图像与模糊核的联合后验概率在图像空间边际化,然后求解模糊核的边际分布,进而实现图像盲复原。传统图像去模糊研究通常集中于解决简单的相机抖动或者目标运动产生的模糊问题,仅在特定模糊图像上具有良好的效果。
近年来,学者们对基于卷积神经网络(Convolutional Neural Network,CNN)的图像去模糊方法进行了广泛研究[7-9]。早期,基于CNN 的图像去模糊方法将CNN 作为模糊核估计器,构建基于CNN 的模糊核估计和基于核反卷积的两阶段图像去模糊框架[10-11]。JIAN 等[11]提出使用CNN 估计运动模糊的空间变化核,去除非均匀模糊,但由于模糊特性复杂,模糊核估计方法在实际场景中不能很好地恢复模糊图像。目前,基于CNN 的图像去模糊方法旨在以端到端方式直接学习模糊-清晰图像对之间的复杂关系[12-14]。KUPYN 等[12]提出DeblurGAN,基于GAN 和内容损失,以单尺度的方式实现图像去模糊。尽管单尺度在去模糊效率上表现良好,但由于未能提取多种特征信息,导致去模糊性能和恢复图像细节上效果欠佳。NAH 等[13]基于coarse-to-fine 策略,引入一种用于动态场景去模糊的深度多尺度CNN 网络DeepDeblur,在不估计任何模糊核的情况下提取图像多尺度信息,直接从模糊图像中恢复清晰图像。ZHAO 等[14]提出一种轻量化和实时的无监督图像盲去模糊方法FCL-GAN,既没有图像域限制,也没有图像分辨率限制,保证了轻量化和性能优势。ZHAO 等[15]提出一种用于盲运动去模糊的通用无监督颜色保留网络CRNet,易于扩展到其他受色彩影响的畸变任务,同时引入模糊偏移估计和自适应模糊校正,改进去模糊任务。
虽然CNN 在单图像去模糊领域取得了良好的效果,但存在以下问题:1)卷积算子的感受野有限,难以捕获到远程像素的信息,若要增加感受野,则只能增加网络深度,然而会造成计算量过大和信息丢失问题;2)卷积核在推理时有静态权值,不能灵活地适应输入内容。受Transformer[16-17]具有全局信息建模特性的启发,DOSOVITSKIY等[18]提出视觉Transformer(Vision Transformer,ViT)来执行图像识别任务,以具有位置嵌入的2D 图像块为输入,在大数据集上进行预训练,取得了与基于CNN 的方法相当的性能。TOUVRON 等[19]将Transformer 与蒸馏方法相结合,提出一种高效的图像Transformer(DeiT),可在中型数据集上训练Transformer,具有较好的鲁棒性。
受UNet多尺度单图像去模糊[20]和Transformer[16,21-22]工作的启发,本文将Transformer 引入CNN 网络,但直接将Transformer 嵌入CNN 网络存在以下问题:1)嵌入后应用CNN 网络的训练策略因Transformer参数量过多导致无法训练;2)应用局部方式计算多头自注意力(Multi-Head Self-Attention,MHSA)会造成局部窗口之间缺少信息联系且去模糊效果差。针对上述问题,本文提出一种基于Transformer 和多尺度CNN 的图像去模糊网络(T-MIMO-UNet)。利用CNN 网络提取空间特征,同时对输入图像进行下采样得到多尺度的特征图,通过将多尺度特征相互融合和补充,有效利用每个尺度的信息,更好地处理各种图像模糊问题。设计一种局部增强Transformer 模块(Enhanced Local Transformer Module,EL-TM),能够利用Transformer 的全局特性有效获取全局信息。当每个尺度的特征输入到EL-TM 中进行全局建模时,针对输入图像尺寸过大的问题,设计一种局部多头自注意力计算网络(Local Multi-Head Self-Attention Network,L-MHSAN),采用窗口的方式在局部逐块计算MHSA,以解决图像尺寸过大导致的训练难度增加的问题。针对在L-MHSAN 中划分窗口计算MHSA 后跨窗口的信息交互消失问题,设计一种增强前馈网络(Enhanced Feed-Forward Network,EFFN),通过增加深度可分离卷积层,促进不同窗口之间的信息交互,有效获取全局信息,提升图像清晰度和计算效率。
1 图像去模糊网络
本文提出的T-MIMO-UNet 结构如图1 所示。该网络主要由多尺度输入编码器、EL-TM、非对称特征融合(Asymmetric Feature Fusion,AFF)模块和多尺度输出解码器组成,其中,编码器采用两个编码块(Encoder Block,EB),解码器采用3 个解码 块(Decoder Block,DB),EL-TM采用12 个局部增强Transformer 层(Enhanced Local Transformer Layer,EL-TL)。
T-MIMO-UNet 建立在基于编码器-解码器的单一UNet 架构上,可充分利用CNN 从图像中提取的多尺度空间特征。此外,为了捕获全局依赖关系,利用Transformer 编码器对全局空间进行建模,并基于EL-TM 进行局部窗口之间的信息交互,实现多尺度去模糊。
1.1 多尺度输入编码器
多尺度架构可以有效地处理不同程度的图像模糊[23],同时各种基于CNN 的去模糊方法[13,24-25]也都采用将不同尺度的模糊图像作为网络的基本输入。在T-MIMO-UNet 的编码器中,通过编码块将不同尺度的模糊图像作为输入,其中,EB1由卷积层、残差块构成,EB2由卷积层、特征融合模块(FAM)[20]和残差块构成,已有实验[20]证明了FAM 能够提高模型性能。
使用多尺度策略作为单个U-Net 的输入,将原始尺度的模糊图像B1进行2 次1/2 下采样,得到另外2 个尺度的模糊图像B2和B3。B1和B2尺度的模糊图像通过EB1和EB2提取特征,B3尺度的模糊图像在经过预处理后输入Transformer架构EL-TM 进行全局特征建模。此外,除了在每个尺度的编码器或EL-TM 中提取特征外,对于B2和B3尺度,还会分别从上面尺度的模糊图像中提取缩小的特征,然后将这2 种特征融合,2种信息相互补充,更有助于处理图像模糊问题。
在每个尺度的编码器或Transformer 模块中提取特征时,使用浅卷积模块(Shallow Convolution Module,SCM)[20]对下采样图像B2和B3进行特征提取处理。SCM 使用2 个堆叠的3×3 和1×1 的卷积层,然后在最后一个1×1 卷积层中将提取的特征与输入的当前尺度图像连接起来,再使用一个1×1 卷积层进一步细化连接,经过SCM 的输出用Zk,out表示。
对于原始尺度的模糊图像B1,没有使用SCM,而是直接输入编码块EB1。对于使用了SCM 的模糊图像B2,将SCM 的输出Z2,out与B1尺度的编码器输出E1,out使用FAM 进行融合,在融合前使用stride 取值为2 的卷积层以保证2 个特征具有相同的尺寸,最后使用1 个残差块继续细化特征。
对于B3尺度的模糊图像,将此时SCM 的输出Z3,out与B2尺度的编码器输出E2,out进行特征融合,此时的特征图经过多次浅层特征提取和前2 个尺度的卷积特征提取后,每个像素具备了更深的感受野,这时输入EL-TM 利用Transformer 的全局特征信息建模能力,进一步学习与全局感受野的远程相关性,之后将提取的全局特征输入残差块。
1.2 局部增强Transformer 模块
自Transformer 架构[16]被应用于深度学习领域以来,其全局信息建模特性引起了学者们的广泛关注。CNN 作为视觉领域的通用主干网络,在图像去模糊任务中应用广泛,但CNN 卷积算子存在感受野有限的问题,随着网络层数的不断加深,CNN 这一问题体现的越发明显,Transformer 的全局性可以缓解这一缺陷。在处理模糊图像时,Transformer往往因数据集中过大的图像尺寸而造成计算复杂度过高,最终使去模糊的视觉任务失败。为了增强Transformer 架构在去模糊领域的通用性,设计一种局部增强Transformer 模块,如图2 所示。局部增强Transformer 模块由多个局部增强Transformer 层构成。每个局部增强Transformer层由L-MHSAN 和EFFN 构成。

图2 局部增强Transformer 模块结构Fig.2 Structure of the enhanced local Transformer module
在T-MIMO-UNet 结构中,将B1和B2尺度提取的特征与B3尺度融合,然后将所获得的特征图I∊RN×D通过EL-TM 进一步进行特征提取,其中,N表示输入分辨率H×W,H表示图像高度,W表示图像宽度,D表示输入通道数。
B3尺度的图像特征在与其他尺度特征相加并输入局部增强Transformer 模块计算MHSA 前,需要经过浅卷积模块的处理,处理后的图像与B2尺度的编码器输出E2,out相融合。由于图像去模糊数据集的大尺寸特性导致计算MHSA 时计算量过大,大大增加了训练难度。为了解决这个问题,在局部增强Transformer 层中设计了一种局部多头自注意力计算网络。
局部多头自注意力计算网络结构如图3 所示。首先读取融合特征的维度并进行记录,由于融合特征仍然与图像维度一致,即(Y,H,W,D),其中,Y表示图像批处理大小。使用Flatten 操作将图像的宽度、高度等展开成一维数据的形式,即(Y,D,H×W),之后将展开后的数据形式转换为(Y,H×W,D),便可将融合后的图像特征输入局部增强Transformer 层计算MHSA。

图3 局部多头自注意力计算网络结构Fig.3 Structure of the local multi-head self-attention network
图像特征输入局部增强Transformer 层后,局部多头自注意力计算网络将特征图I∊RN×D划分成P个不重叠的窗口I→{I1,I2,…,IP},窗口个数P的计算公式如式(1)所示。在每个窗口中独立计算多头自注意力。针对一个局部窗口特征图X∊RM2×D,Query、Key、Value 矩阵Q、K、V计算公式如式(2)所示。基于局部窗口的自注意力计算公式如式(3)所示。将AQ,K,V并行计算C次并连接,得到多头自注意力计算结果AQ,K,V,然后经过窗口特征合并操作重构得到中间特征fM,计算公式如式(4)所示。
其中:M2表示被划分的窗口尺寸;PQ、PK、PV分别表示在不同窗口共享的投影矩阵;d表示,C为多头自注意力的头数量;View 表示重构操作;Window-reverse表示窗口特征合并操作;fM特征维度为(Y,H,W,D)。
将多头自注意力在局部不重叠的窗口中分别计算时,不同窗口之间信息交互会消失,跨窗口之间没有信息交流会限制建模能力。为了解决这个问题,在局部增强Transformer 层中的前馈网络(Feed-Forward Network,FFN)结构上进行改进,设计一种增强前馈网络,在2 个全连接层间增加了2 个深度可分离卷积层(Depthwise separable Convolution,DepthConv),并合理利用跳跃连接与输入特征建立联系。增强前馈网络结构如图4 所示。

图4 增强前馈网络结构Fig.4 Structure of the enhanced feed-forward network
首先,对于输入的中间特征fM,经过第1 个全连接层,再经过正则化和激活操作输入第1 个深度可分离卷积层后以残差的方式进行跳跃连接得到中间特征计算的第1 个阶段的计算结果,计算过程可表示如下:
其中:LN 表示全连接操作;DepthConv 表示深度可分离卷积操作。
然后,fM,1经过正则化操作和第2 个深度可分离卷积层,通过残差相加得到中间特征计算的第2 个阶段的计算结果fM,2,fM、fM,1和fM,2跳跃连接得到中间特征计算的第3 个阶段的计算结果fM,3,即:
最后,fM,3经过第2 个全连接层和正则化、卷积操作后与fI相加得到EL-TL 模块最终提取的特征fF。
深度可分离卷积不仅能增强局部性,而且能增加窗口之间特征的局部信息交互[26],同时相对于普通卷积而言,深度可分离卷积能有效减少模型的参数量。
1.3 非对称特征融合模块
使用AFF 模块[20]将编码器中提取的特征进行融合。特征融合策略没有使用对称融合[27]及只进行相邻2 个尺度的特征融合[13],而是将3 个尺度的特征再次进行融合输入至DB1和DB2。
1.4 多尺度输出解码器
使用上采样或下采样操作将不同尺度的特征输入AFF 模块进行特征融合后,将这些特征输入网络解码端,对每个尺寸的图像进行重建。解码器依然采用单个U 形网络模拟多级联U 型网络输出不同尺度的去模糊图像。解码块均由卷积层和残差块构成。由于解码块的输出是一个特征图而不是一幅图像,因此在重建每一层图像时,使用一个卷积层作为生成图像的映射函数。在实验过程中,因无需B2和B3尺度的去模糊图像S2和S3,本文模型只将原始B1尺度进行去模糊,输出S1在后面的实验中进行对比。
2 实验与结果分析
网络模 型在训 练时使 用Intel®Xeon®Silver 4210 CPU @ 2.20 GHz 硬件平台,内存为93.1 GB,GTX1080Ti 11 GB。软件环境为Ubuntu18.04 操作系统,深度学习环境为PyTorch1.4.0。
2.1 数据集和实现细节
使用GoPro[13]训练数据集来训练网络,训练数据集中包括2 103 对模糊和清晰的图像对;使用GoPro 测试数据集来测试网络,测试数据集中包括1 111 对图像 对。此外,在RealBlur[28]真实场 景数据集中测试了模型的有效性,RealBlur 测试数据集包含RealBlur-R 和RealBlur-J 这2 个子数据集,每个数据集包括980 对图像对。
网络训练的初始学习率为10-4,之后每迭代训练500 轮就下降50%。对于每次迭代训练,都将图像随机剪切为256×256 像素。为了使模型充分收敛,在GoPro 训练数据集中进行3 000 轮的迭代训练,以使模型收敛。
2.2 损失函数
在优化网络参数时,使用多尺度内容损失函数[13],定义如下:
其中:K表示尺度;SK和GK分别表示模型预测的清晰图像和真实清晰图像;使用每一轮计算的损失次数tK进行归一化处理。
研究表明:增加辅助损失项可以提高模型性能,且最小化特征空间中输入和输出之间距离的辅助损失项已在图像恢复任务中得到广泛应用,并取得了良好的效果[29]。去模糊主要是恢复图像高频分量的特性,使用多尺度频率重建(Multi-Scale Frequency Reconstruction,MSFR)损失函 数[20]作为辅 助损失项。尺度频率重建损失函数能够测量频域中多尺度真实图像和去模糊图像之间的L1 距离,定义如下:
其中:FT 表示快速傅里叶变换。
网络训练的损失函数可表示如下:
2.3 去模糊定量效果分析
将T-MIMO-UNet与DeblurGAN[12]、DeepDeblur[13]、FCL-GAN[14]、CRNet[15]、MIMO-UNet[20]、MIMOUNet+[20]、PSS-NSC[24]、SRN[25]、DMPHN[30]、MPRNet[31]、DeblurGAN-v2[32]等经典的去模糊网络进行比较,定量地分析其性能。为了实现计算复杂度和去模糊精度之间的权衡,同时提出T-MIMO-UNet 的变体,即T-MIMO-UNet+和T-MIMO-UNet++,其中,T-MIMOUNet 中使用10 个残差块和12 个EL-TM,T-MIMOUNet+中使用20 个残差块和6 个EL-TM,T-MIMOUNet++是在T-MIMO-UNet+的基础上将EFFN 中的深度可分离卷积替换成普通卷积。在GoPro 测试数据集上与其他网络的测试结果比较如表1 所示,其中,粗体表示每列最优值,下划线表示每列次优值。由表1 可以看出:与MIMO-UNet 基础网络相比,T-MIMO-UNet 及其2 个变体网络的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)分别提升了0.39 dB、0.54 dB、0.66 dB;与DeepDeblur、DeblurGAN、SRN网络相比,T-MIMO-UNet 的PSNR 分别提升了2.89 dB、3.42 dB、1.86 dB;特别是在平均SSIM 指标上,T-MIMO-UNet 及其变体网络明显优于对比网络;与MPRNet 网络相比,T-MIMO-UNet 及其变体网络尽管PSNR 略有欠缺,但在模型参数量和去模糊处理时间上有更好的表现,T-MIMO-UNet 参数量减少为MPRNet 的1/2,处理时间减少为MPRNet 的1/8。

表1 在GoPro 测试数据集上的测试结果比较 Table 1 Comparison of test results on the GoPro test dataset
为了验证多尺度策略去模糊性能的优越性,与基 于CNN 的单尺 度去模 糊网络Deblur-GAN[12]、SDWNet[33]和基于 双尺度 策略的 去模糊网络DeblurGAN-v2[32]进行比较。在GoPro 测试数据集上单尺度、双尺度与多尺度定量性能比较结果如表2所示。由表2 可以看出,多尺度特征提取方式优于单尺度和双尺度特征提取方式,验证了多尺度信息提取的优势。
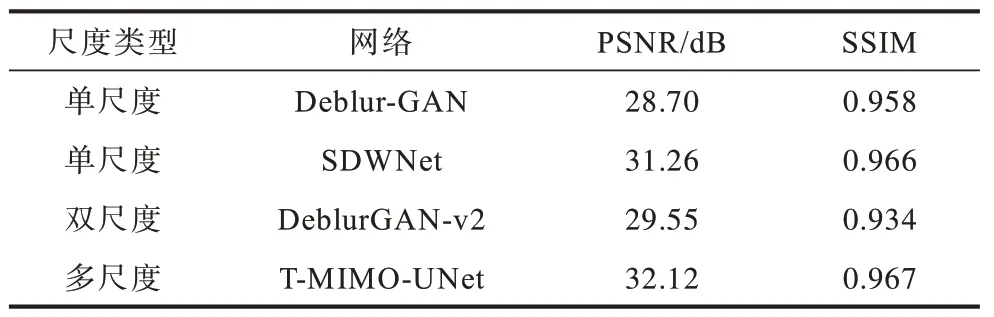
表2 在GoPro 测试数据集上单尺度、双尺度与多尺度定量性能比较 Table 2 Comparison of quantitative performance among single-scale,double-scale and multi-scale on the GoPro test dataset
为了验证T-MIMO-UNet 在真实场景中的有效性,在RealBlur 测试数据集[28]上将T-MIMO-UNet 与DeblurGAN[12]、DeepDeblur[13]、FCL-GAN[14]、MIMOUNet[20]、MIMO-UNet+[20]、SRN[25]、DMPHN[30]、MPRNet[31]、DeblurGAN-v2[32]等经典的去模糊网络进行比较,平均PSNR 和SSIM 定量比较结果如表3 所示,其中,粗体表示每列最优值,下划线表示每列次优值,可以看出T-MIMO-UNet 及其变体网络仍然取得了比较好的效果,PSNR 和SSIM 值非常接近MPRNet。

表3 在RealBlur 测试数据集上的平均PSNR 和SSIM Table 3 Average PSNR and SSIM on the RealBlur test dataset
2.4 去模糊定性结果分析和消融实验
对T-MIMO-UNet 的图像去模糊效果进行主观分析,并将其与其他网络的图像去模糊效果进行比较,如图5 所示,为了充分展示去模糊效果,放大了图中的细节。由图5 可以看出,与其他网络的去模糊结果相比,T-MIMO-UNet 获取的去模糊图像纹理更清晰,视觉效果更好。

图5 在GoPro 测试数据集上的去模糊效果Fig.5 Deblurring effects on the GoPro test dataset
为了证明增强前馈网络中使用深度可分离卷积对于降低网络模型参数量的有效性,在T-MIMOUNet 中将深度可分离卷积替换为普通卷积进行性能对比实验,实验结果如表4 所示。由表4 可以看出,对于T-MIMO-UNet,在增强前馈网络中使用传统卷积时,相比使用深度可分离卷积的网络模型的PSNR 提升了0.09%,参数量提升了5.6%。在参数量上使用深度分离卷积的网络模型具备较大的优势,满足部分场景中需要模型规模小、运行速度快的需求。此外,使用深度分离卷积的网络模型能够增加窗口之间特征的局部信息交互。因此,根据综合性能和模型参数量,在T-MIMO-UNet 模型中使用深度可分离卷积。

表4 深度可分离卷积与普通卷积的性能对比 Table 4 Performance comparison between depthwise separable convolution and ordinary convolution
为了验证所设计的EL-TM 的有效性,并验证所使用EL-TM 中EL-TL 数量的最优选择,针对EL-TM中EL-TL 数量在GoPro 测试数据集上进行消融实验,实验结果如表5 所示。当EL-TL 数量为0 时表示没有使用本文提出的EL-TM 时的网络模型性能,由表5 可以看出,加入了EL-TM 的网络模型相比未加入EL-TM 的网络模型在性能上有了明显的提升,且随着EL-TL 数量的增加性能逐渐提升。但在EL-TL数量大于12 后,由于网络模型的复杂度提升,在本文设定的硬件条件下难以进行训练,因此选择ELTL 数量为12 与CNN 结合作为最终模型。需要说明的是:若硬件条件允许,则可继续增加网络模型中的EL-TL 数量,从而取得更好的PSNR 和SSIM 性能。

表5 在GoPro 测试数据集上的EL-TM 消融实验结果 Table 5 Ablation experimental results of EL-TM on the GoPro test dataset
3 结束语
本文提出一个新的去模糊网络T-MIMOUNet,将Transformer 整合到基于CNN 的UNet,实现动态场景下的单图像盲去模糊,不仅继承了CNN 在建模局部上下文信息方面的优势,而且还利用了Transformer 学习全局语义相关性。在GoPro 和RealBlur 测试数据集上的实验结果验证了T-MIMO-UNet 的有效性。后续将继续对视觉Transformer 进行研究,探索结合多尺度CNN 与视觉Transformer 的网络模型,进一步提升其在动态场景下的去模糊性能。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
科学与财富(2018年30期)2018-12-28
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
计算机应用(2016年9期)2016-11-01
太空探索(2016年5期)2016-07-12
体育科技(2016年2期)2016-02-28
电子器件(2015年5期)2015-12-29
时代英语·高三(2014年5期)2014-08-26
电测与仪表(2014年13期)2014-04-04
