
基于PPO2强化学习算法的空间站轨道预报方法
2023-09-18 04:16:08雷骐玮张洪波
中国空间科学技术 2023年4期
雷骐玮,张洪波
国防科技大学 空天科学学院,长沙 410073
1 引言
建设空间站是载人航天发展的高级阶段,高精度的轨道预报是空间站在轨安全稳定运行和制定合理的轨道控制策略的前提条件。空间站一般运行在低地球轨道,且面质比较大,大气阻力摄动是空间站轨道预报的主要误差源[1]。
计算低轨航天器所受的大气阻力时,误差主要来源于大气密度、阻力系数和迎风面积的计算误差,阻力系数和迎风面积的误差可以通过在线辨识的方法予以部分修正[2]。大气密度主要通过大气模型计算得到,但由于影响热层大气密度的因素较多且变化机理复杂,现有模型都不能准确描述大气密度的实际变化情况,从而造成轨道预报误差。
刘亚英等探索了大气阻力摄动的精密计算方法,提高了低轨道卫星轨道预报精度[3]。Kong等利用三种大气密度模型,对基于动力学模型的轨道预报方法进行了研究[4]。Chen等研究了仅使用两行轨道根数提高低轨航天器轨道预报精度的方法,利用实测轨道数据对经验模型进行校准[5]。李梦奇对低轨航天器的大气参数修正方法进行了研究,降低了大气阻力摄动误差并提高了轨道预报精度[6]。Ray等利用傅立叶阻力系数模型对大气阻力系数进行了精确建模,让阻力系数成为与航天器轨道和姿态相关参量的函数[7]。刘舒莳等基于线性回归分析建立了大气阻力系数补偿算法,提高了近地航天器轨道预报精度[8]。
强化学习是一种机器学习方法,将学习看成一个试探-评价的过程[9]。在强化学习中,智能体从环境获取信息,依据动作策略采取动作作用于环境;环境接受智能体的动作并发生变化,同时反馈给智能体奖励或惩罚,即环境对智能体的动作进行评价;智能体根据环境反馈信号和当前观测的环境状态选择下一时刻的动作,依据是能够最大化智能体得到的奖励或者累积奖励[10]。
诸多学者对强化学习技术在航天动力学领域中的应用开展了研究。Hovell等提出了一种基于深度强化学习的航天器接近操作制导策略,设计了一个航天器姿态跟踪和对接场景,并验证了该策略的可行性[11]。吴其昌基于MADDPG强化学习算法,对航天器追逃博弈问题进行了研究,并能满足航天器机动策略求解的实时性与快速性的要求[12]。王月娇等将DQN强化学习算法用于卫星自主姿态控制,有效解决了传统PD控制器依赖被控对象质量参数的问题[13]。Nicholas等采用强化学习算法来生成一种新型闭环控制器,该控制器能适用于复杂空间动态区域的星载低推力制导,并能够在初始偏差较大的情况下直接引导航天器,提高了制导精度[14]。
综上所述,对于航天器轨道动力学模型中大气阻力摄动建模不准确的问题,当前的研究工作主要是通过解析的方法进行参数矫正,进而提高航天器轨道预报精度。强化学习算法可以通过智能体在线学习适应动力学环境的变化。本文提出了一种基于轨道动力学模型修正的轨道预报方案,该方案将PPO2强化学习算法与大气参数可调的动力学模型相结合,在动力学积分预报轨道的过程中实时修正大气阻力引起的建模误差,从而提高轨道预报精度和预报效率。该方案对低轨航天器的轨道预报具有一定的参考价值。
2 动力学模型修正的轨道预报方案设计
空间站的轨道动力学方程可表示为
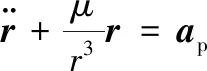
(1)
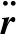
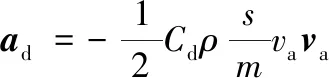
(2)
式中:Cd为阻力系数;ρ为大气密度;s为迎风面积;m为空间站质量;va为空间站相对于大气的速度。定义空间站的面质比与大气阻力系数的乘积为弹道系数B,即
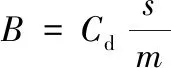
(3)
式中:阻力系数Cd和面质比s/m由地面实验数据及工程经验给定。假设大气与地球一起旋转,则由空间站在地心惯性坐标系中的位置r和速度v可得
va=v-ϖE×r
(4)
式中:ϖE为地球自转角速度。
轨道预报时一般用经验大气模型计算大气密度,常用的有US1976标准大气、NRLMSISE-00模型等。US1976标准大气模型表示了中等太阳活动期间,由地面到1000km的理性化、静态的中纬度平均大气结构,大气密度的计算公式为
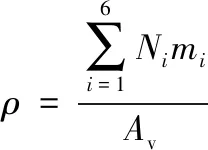
(5)
式中:Av为阿伏伽德罗常数;mi为N2,O,O2,Ar,He,H六种气体的标称分子量;Ni为气体分子的数密度。Ni只与高度有关,可以通过对标准大气气体成分数密度随高度变化表插值得到。因此基于US1976模型计算得到的大气密度只和高度有关,故计算时效率较高。相比于US1976模型,NRLMSISE-00大气模型计算精度较高,其详细计算公式可参考文献[15]。NRLMSISE-00大气模型的大气密度计算如下:

(6)
在计算大气密度时,NRLMSISE-00大气模型在US1976模型的基础上添加了6种气体分子数密度的修正项ΔNi,并引入了氮N和电离层正氧离子O+两项。基于中国空间站的轨道根数,分别采用两种大气模型计算得到1天内空间站所在高度的大气密度,结果如图1所示。
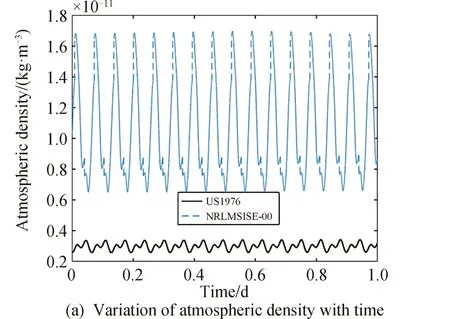
图1 大气密度与大气密度之差随时间变化
由图1可知,US1976模型计算得到的大气密度随时间变化幅度较小,NRLMSISE-00模型计算得到的大气密度随时间呈周期性波动,波动周期大致和空间站轨道周期相同。
在实际工程应用中,根据星载轨道大气环境探测器的探测结果发现,在太阳和地磁活动平静期,NRLMSISE-00大气模型计算得到的大气密度日均误差值也能达到10%,其变化规律难以用解析表达式描述。且由于空间站的真实轨道数据难以实时获取,故考虑在各时刻基于经验大气模型计算得到的大气密度的基础上引入一个连续随机噪声,作为真实大气密度值,然后进行轨道数值积分,将得到的数据作为真实轨道数据。为验证强化学习方法的修正效果,本文工作中引入了一个随机信号Δk(t)来模拟真实大气密度,即
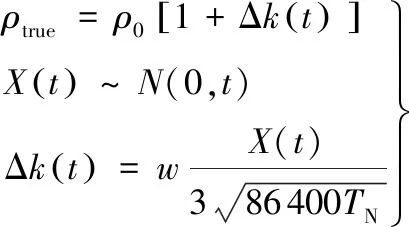
(7)
式中:ρ0为基于NRLMSISE-00大气模型计算得到的大气密度。|Δk(t)|<0.15。真实大气密度具有时空连续性,故Δk(t)是一个随时间连续变化的量,考虑采用随时间呈正态分布的变量X(t)来描述Δk(t)的变化。X(t)经过标准化处理(仿真时段长度为TN,单位为天;规范化系数w=0.15),限制Δk(t)的取值范围。
相比于NRLMSISE-00模型,US1976模型的计算量更小,因此考虑在轨道预报中,通过对US1976模型进行修正来计算大气密度。根据式(7),定义
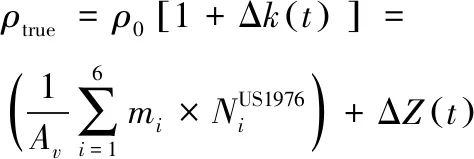
(8)
式中:ΔZ(t)表示US1976模型与真实大气模型密度之差。若能通过强化学习得到ΔZ(t)随时间的变化规律,并补偿到预报模型中,则能有效提高轨道预报精度和效率。
基于上述分析,将空间站轨道预报的运动模型表示为
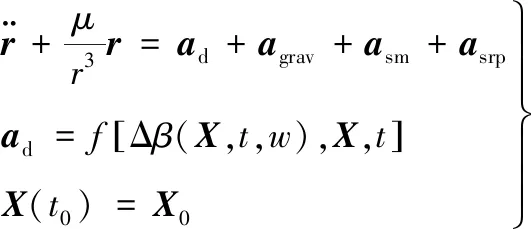
(9)
式中:ad,agrav,asm,asrp分别为大气阻力摄动、地球非球形引力摄动、日月引力摄动、太阳光压摄动产生的摄动加速度,
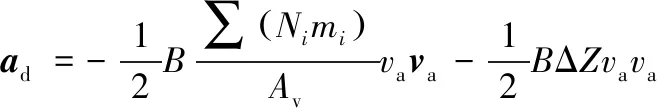
(10)
记Δβ=BΔZ。方程(9)即为大气参数可调的动力学模型。Δβ综合考虑了大气模型计算不准确和轨道动力学模型建模时弹道系数B估计不准确的影响。由之前的分析可知ΔZ(t)随时间呈周期性变化,实际工程应用中弹道系数B的估计误差较小,故Δβ随时间呈周期性变化。若能够利用强化学习网络学习得到大气参数修正量Δβ随时间的变化规律,则能够利用强化学习网络提高空间站轨道动力学模型建模精度,从而提高轨道预报精度。
由此,设计一种基于轨道动力学模型修正的轨道预报方案,其原理如图2、图3所示。其中箭头表示利用奖励函数Re(t)对强化学习网络进行训练,将大气参数修正量Δβ加到大气参数可调整的动力学模型上。
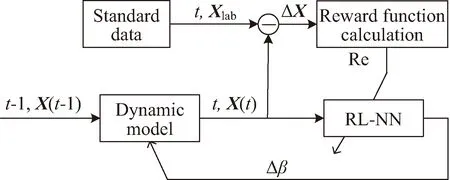
图2 训练段轨道动力学模型修正方案框架
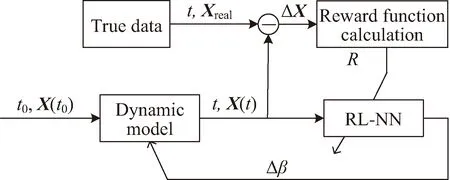
图3 预报段轨道动力学模型修正方案框架
图2表示的是强化学习网络的训练段。已知J2000.0惯性坐标系下t-1时刻空间站的状态量X(t-1),根据式(9)得到下一时刻的状态量X(t),并与已知的标准轨道数据Xlab(t)作差得到状态偏差量ΔX(t),
ΔX(t)=X(t)-Xlab(t)
(11)
图2中RL-NN为强化学习网络,其输入为状态量X(t)和时间t,输出为大气模型参数调整量Δβ,其映射关系为
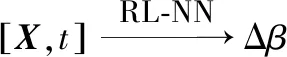
(12)
为补偿大气模型不准造成轨道预报偏差,应使状态偏差量ΔX接近于0,因此将RL-NN的奖励函数R定义为ΔX的函数:
R(t)=f(X(t),Xlab)
(13)
按照图2完成网络训练后,利用强化学习网络进行轨道预报,其原理如图3所示。
3 强化学习算法设计与样本生成
3.1 强化学习过程建模与训练流程设计
强化学习过程可抽象为马尔可夫决策过程。其中,状态空间S中的状态量为[X(t),t]T,动作空间A中动作量为[Δβ],状态转移函数P由大气参数可调的动力学模型决定;奖励函数Re为f(X(t),Xlab),表征t时刻轨道数值积分结果X(t)与标准状态量Xlab的接近程度,奖励函数值越大,表明两者越接近,即当前智能体所采取的策略表现越好。图3中RL-NN的输出量Δβ为连续型变量,故考虑选择适用于连续动作空间的高斯策略作为探索策略进行策略优化。
近端策略优化算法,简称PPO算法,该算法的特点是实现复杂度较低,超参数调试较为容易。在PPO算法中智能体每一步训练时都会选择新策略,通过自适应的方式选择超参数,确保了智能体与环境交互过程中每一步获得的奖励值单调不减,从而持续获得更优的策略。
PPO算法包含策略网络与评价网络,采用重要性采样方法实现参数更新。策略网络输出一个均值μ和标准差σ,得到一个由该均值和方差确定的正态分布。智能体输出的动作,即大气模型参数调整量Δβ通过对该正态分布采样得到,有
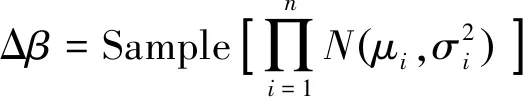
(14)
式中:n为动作矢量的维数;Sample函数为采样函数。在PPO网络权重参数更新过程中,引入了重要性采样方法,采样公式如下:
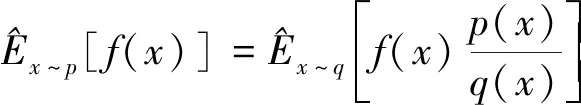
(15)
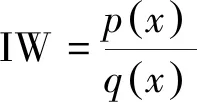
(16)
从而将f(x)对于策略分布函数p的期望值转化为相对于策略分布函数q的期望值。PPO算法中的策略网络可等价为策略分布函数,PPO算法中的策略网络包含行为策略网络和目标策略网络两部分,行为策略网络输出的数据用于更新目标策略网络。
为定量评估PPO算法中策略网络的性能表现,要定义目标函数。先定义优势函数Aθ′(st,at),其大小与各时刻智能体从环境中获得的奖励值rt相关,反映了当前策略得到的大气参数补偿量Δβ对US1976模型的有效补偿程度,即动力学模型轨道数值积分得到的状态量与标准状态量的偏差量越小,则补偿效果越好,rt与Aθ′(st,at)的取值越大。PPO2算法是PPO算法的一种,运用了截断函数来控制策略网络参数的梯度更新,PPO2算法的截断函数为
(17)
式中:clip函数为TensorFlow中numpy函数库所包含的函数,用于限制ht(θ)的取值范围,min为取最小值的函数,θ为策略网络参数,式(17)中ht(θ)的定义如下:
(18)
式(17)引入了超参数ε对重要性采样获得的优势函数进行截断化处理,在策略网络参数进行梯度更新时控制最大更新步长,防止参数更新速度过快导致训练发散。PPO2算法进行策略网络参数梯度更新的目标函数为
clip(ht(θ),1-ε,1+ε)Aθk(st,at)]
(19)
PPO2算法的网络结构与训练流程如图4所示。PPO2算法仿真训练流程的具体步骤可描述如下。
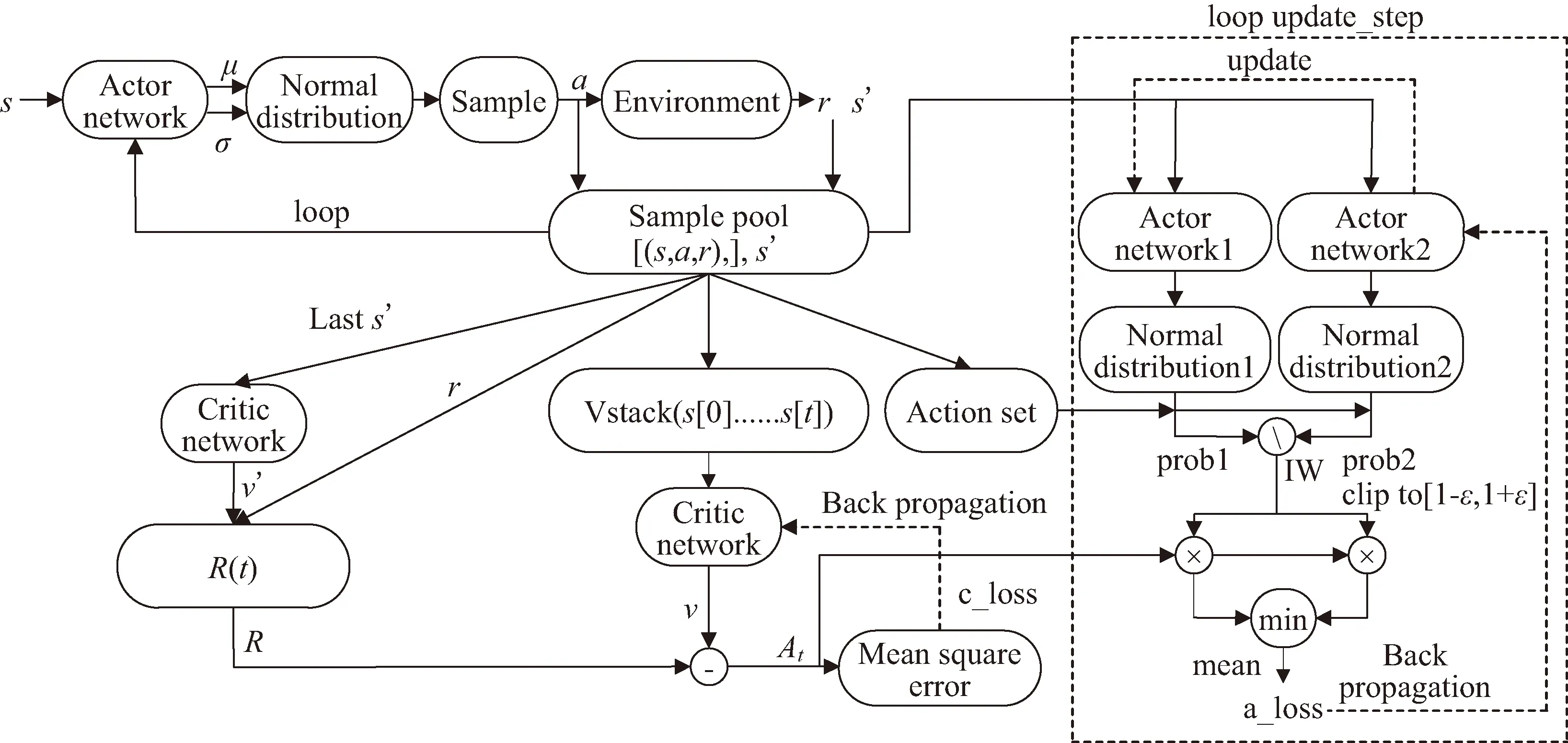
图4 PPO2网络结构与训练流程
At=R-v
(21)
Step 1:将智能体状态量s输入到策略网络,得到大气参数修正量Δβ的均值μ和标准差σ,由该均值与标准差构建一个正态分布,采样得到动作量Δβ,将其输入到动力学环境中得到奖励值rt和下一仿真时刻的状态s′,然后存储该时刻[(s,a,rt),…],将s′输入到策略网络,循环该过程,直到存储了一定量的[(s,a,rt),…]。
Step 2:将Step1循环完最后一步得到的s′输入到评价网络中,得到状态的v′值,计算折扣奖励,即奖励函数,有
R(t)=rt+γrt+1+…+γTE-t+1rT-1+γTE-tv′
(20)
式中:γ为折扣因子,表示智能体在学习过程中对未来潜在奖励的关注程度。由此得到各时刻折扣奖励列表R=[R[0],R[1],…,R[t],…,R[TE]],TE为一个训练仿真回合的最后时刻。
Step 3:将存储的所有状态s组合输入到评价网络中,得到所有状态下的v值,计算优势函数,
Step 4:计算评价网络优化的损失函数c_loss,取均方误差,
c_loss=MSE(At)
(22)
将c_loss值反向传播,用于更新评价网络。
Step 5:将存储的所有状态s组合输入策略网络1和策略网络2,输出大气参数修正量Δβ的均值和标准差,分别构造得到正态分布1和2。将样本池中所有动作量Δβj组合为动作序列[Δβ1,Δβ2,…]传入到正态分布1和2,得到相应状态下每个Δβj对应的概率值prob1和prob2,用prob2除以prob1得到重要性权重IW。
Step 6:根据式(19)计算策略网络的损失函数a_loss,如图4所示,进行反向传播,更新策略网络2。
Step 7:循环Step 5~6,一定步数后循环结束,用策略网络2权重更新策略网络1。
Step 8:循环Step 1~7,直到满足迭代结束条件,即达到训练精度要求或最大训练轮次,训练结束。
3.2 强化学习训练参量与网络模型设计
在轨道预报场景中,强化学习智能体训练时观察到环境信息o为大气参数可调的轨道动力学模型在数值积分后,得到的空间站各时刻运动状态量S以及时刻量T,记为
o=[S,T]
(23)
智能体状态量s通过轨道数值积分得到,即引入强化学习网络的轨道动力学模型进行轨道积分得到空间站各时刻的运动状态量S,记为
s=S
(24)
智能体的动作为PPO2算法中策略网络的输出,即各时刻大气参数调整量Δβ采样的正态分布的均值和标准差,
a=[μ,σ]Δβ
(25)
奖励函数选择为预期结果与实际预测结果的范数,用于表征两者的偏离程度。经反复试验后,在仿真中最终选择了两种奖励函数:
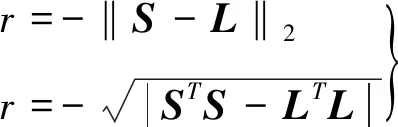
(26)
式中:L为已知的标准轨道数据在J2000.0系下各时刻的空间站运动状态量。奖励函数取负值的原因是PPO2算法的优化目标是最大化与累加奖励相关的目标函数项。
PPO2网络包含策略网络和评价网络。策略网络包含目标网络与行为网络,且假定两者具有完全相同的结构,包含7个输入量,即各时刻空间站的运动状态量及对应的时间,策略网络包含2个输出量,即各时刻大气参数修正量Δβ正态分布采样的均值和方差;评价网络包含7个输入量,与策略网络的输入一致,评价网络包含1个输出量,为当前的状态值函数v。
按照从少到多的原则,经过反复试验,最终选择隐藏层数为3、神经元个数为200的策略网络模型,以及隐藏层数为3、神经元个数为220的评价网络模型。隐藏层激活函数选择SELU函数,输出层激活函数选择tanh函数,其中SELU函数的公式如下:
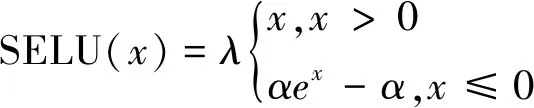
(27)
式中:α和λ是训练前预设的。网络训练优化算法采用Adam算法,性能指标选择为回合累加奖励。回合累计奖励rs为一个仿真回合中,各时刻环境反馈奖励ri(i=0,1,2,…,TE)的累加,有
rs=r0+r1+r2+…+rTE
(28)
3.3 训练与测试数据生成
轨道预报前需要用标准轨道数据对强化学习网络进行训练。选择2022年4月25日某时中国空间站的轨道参数作为初始标准轨道参数,其半长轴为6765.12km,偏心率为0.0012238,轨道倾角为41.4694°,升交点赤经为182.3343°,纬度幅角为210.1109°,平近点角为130.8179°。
在NRLMSISE-00大气模型上加入了一个时长13天的连续维纳噪声信号|Δk(t)|<0.15模拟真实大气密度,然后通过轨道积分得到模拟的真实轨道数据。仿真时长设置为13天,引力场模型选择EGM2008(72×72阶),光压模型选择BERN模型,三体引力仅考虑日月引力,日月星历选择DE405,数值积分方法选择RKF7(8),最大积分步长设置为10s,地磁指数为3,日均F10.7为270,面质比选择为0.02m2/kg,大气阻力系数为2.2。以前10天的数据作为训练数据样本,后3天的数据作为测试数据样本。
由于原始数据的量级差别较大,需要在训练前进行归一化处理。假设某时刻空间站的运动状态量为[rx,ry,rz,vx,vy,vz],以仿真时段内各方向上位置、速度量模的最大值为标准,对策略网络与评价网络的输入量进行归一化处理。
4 数值仿真分析
PPO2算法中对策略网络和评价网络的权重参数按照标准正态分布进行初始化后,还需要对PPO2网络训练初始化条件进行设置,各项初始化条件设置如表1所示。
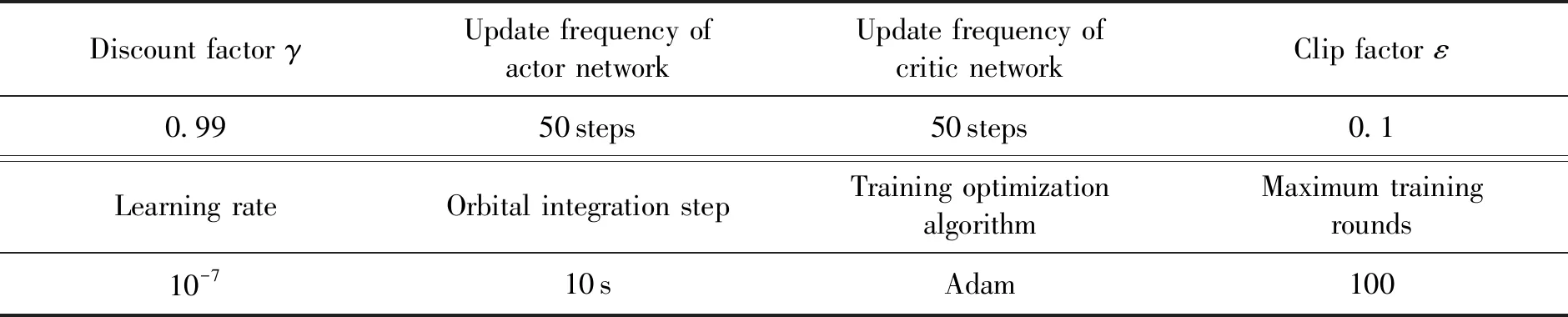
表1 仿真训练参数设置
为保证策略网络表现性能的单调提升,记录每经过一个回合(即对应10天训练样本)训练后训练样本的累计奖励(性能指标,见式(28))。若性能指标相比上一轮提升超过1%,则保存此时的神经网络模型参数;若新一轮训练后性能指标变差,则载入当前已获得的最优网络模型参数进行训练,直到最终模型性能表现不再有明显提升。当完成一个回合训练后,清零累积奖励,重置动力学环境参数,开始下一回合的训练。
经过100回合训练后,训练样本对应累积奖励的变化情况如图5所示。采用两种奖励函数时,性能指标分别提升92.97%、92.84%,累积奖励分别从-0.20285提升到-0.01427,从-0.213741提升到-0.015303。
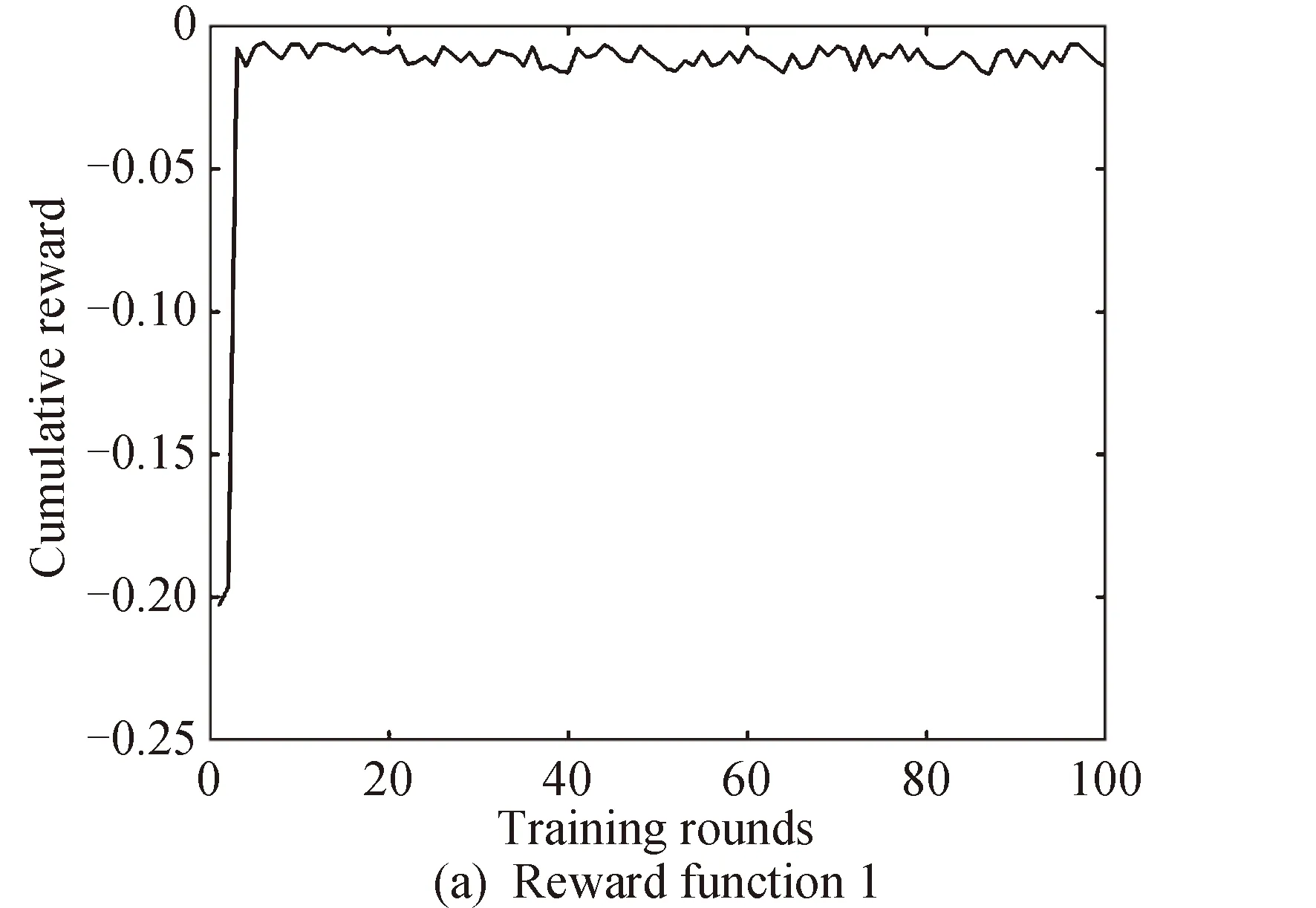
图5 累积奖励随训练回合变化(训练段)
利用测试样本测试强化学习网络表现时,强化学习网络不再更新,直接用于轨道预报,轨道预报结果与标准轨道数据之间存在的偏差即强化学习方法的轨道预报精度,由此验证强化学习方法的泛化能力。
基于测试样本,分别采用两种奖励函数进行轨道预报时的轨道根数误差变化如图6所示,进行轨道预报的位置误差(J2000.0系下)与仅考虑NRLMSISE-00大气模型进行轨道预报时的位置误差以及程序运行时间的对比情况如图7、图8、表2所示。
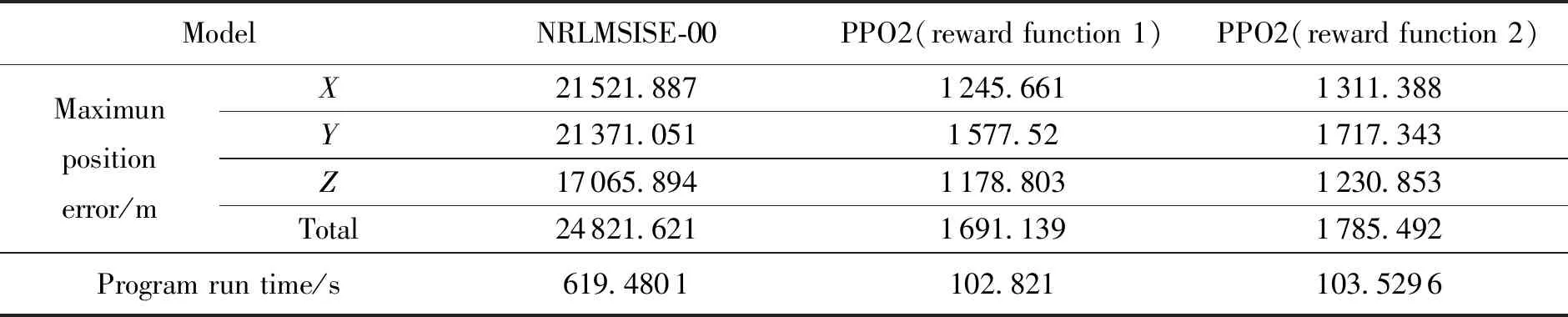
表2 基于经验大气模型与混合动力学模型的最大预报位置误差与预报时间

续图6
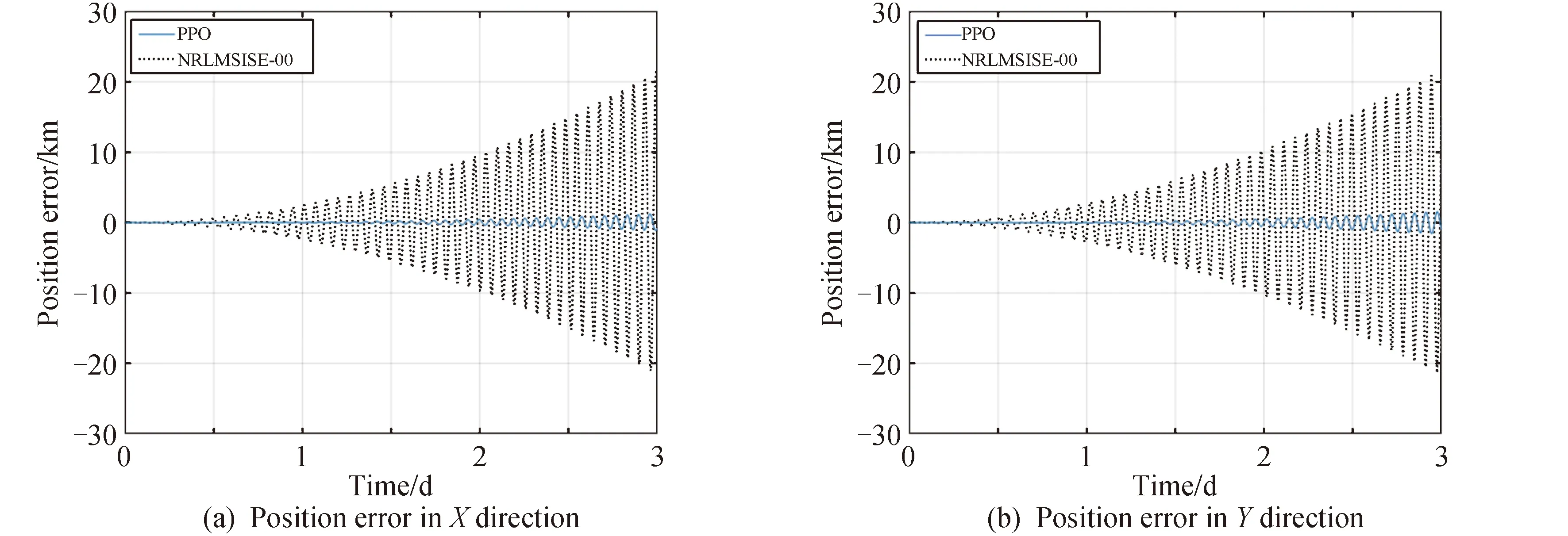
图7 基于经验大气模型与混合动力学模型所得位置误差(奖励函数一)
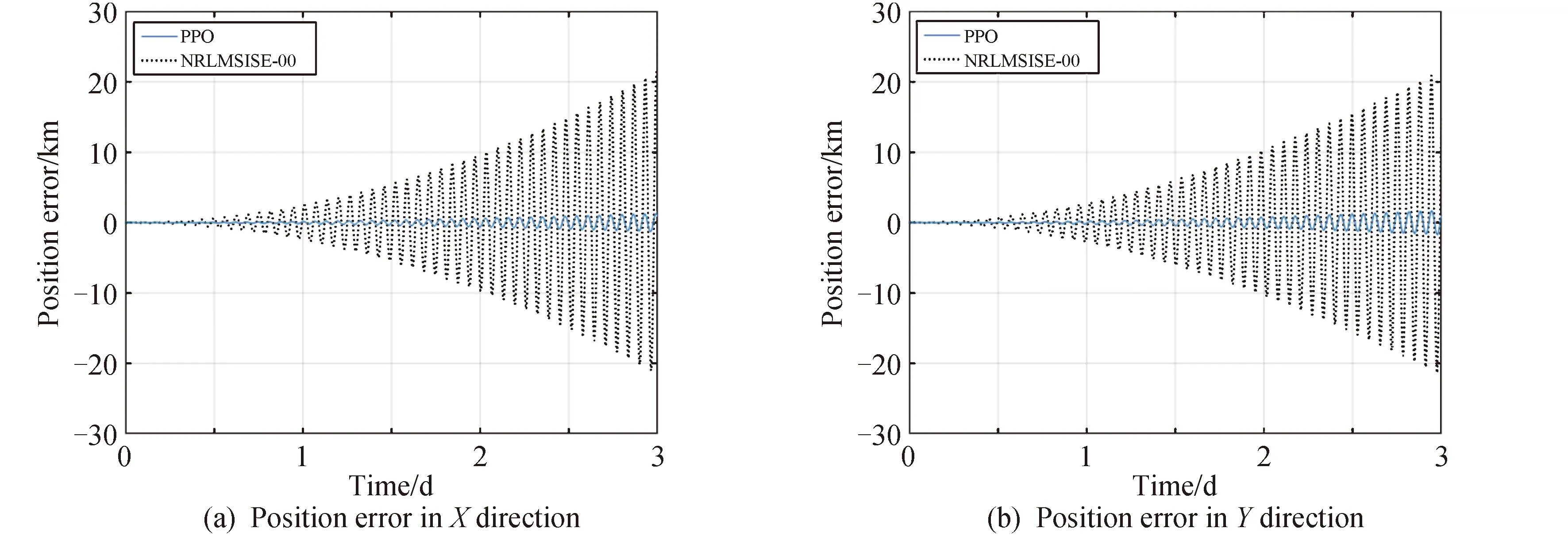
图8 基于经验大气模型与混合动力学模型所得位置误差(奖励函数二)
由图6、图7、图8和表2可知,在测试样本中,相比于仅考虑NRLMSISE-00模型,包含强化学习网络的混合动力学模型用于轨道预报的误差更小。采用奖励函数一时X、Y、Z方向上的最大位置误差与最大总位置误差分别减少了94.21%、92.62%、93.09%、93.19%;在采用奖励函数二时X、Y、Z方向上的最大位置误差与最大总位置误差分别减少了93.91%、91.96%、92.79%、92.81%,且轨道根数误差变化更为平缓,波动幅度较小。将训练后得到的强化学习网络用于预报,程序运行时间分别减小了83.40%,83.29%,由此验证了强化学习方法的有效性。
另构造与PPO2网络中策略网络隐藏层层数与神经元个数相同的深度神经网络模型,令其输入量为仅考虑NRLMSISE-00模型进行轨道数值积分得到的空间站J2000.0系下各时刻的状态量,令其输出量为输入状态量相比于标准状态量的偏差量,采用10天的标准轨道数据对神经网络模型进行训练,随后进行3天的轨道预报,预报状态量为神经网络输出状态偏差量与神经网络输入状态量的和,此时轨道预报的最大位置误差与程序运行时间如表3所示。
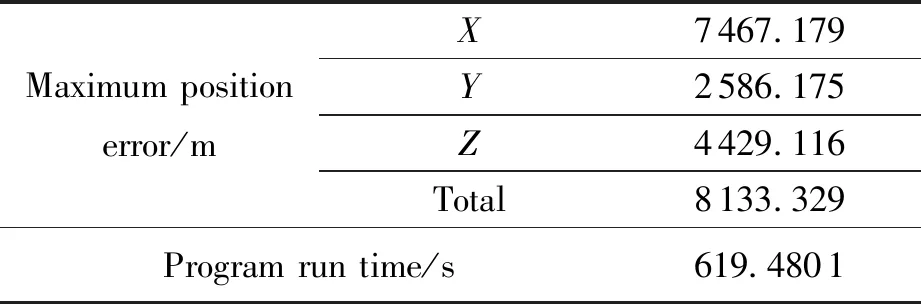
表3 基于强化学习网络模型的最大预报位置误差与预报时间
由表3可知,在进行轨道预报时,相比于强化学习方法,直接利用深度神经网络对原动力学模型的轨道数值积分结果偏差进行补偿,其预报的程序运行时间更长,预报精度更低,由此验证了本文研究的强化学习方法的优越性。
5 结论
本文针对大气阻力摄动难以准确建模的问题,提出了一种融合PPO2强化学习网络和轨道动力学模型修正的轨道预报方案,随后完成了网络模型构建,训练和测试。结合最终仿真测试结果进行如下总结:
1)该方案具有较高的预报精度和预报效率,相比于经验大气模型,采用两种奖励函数时,三方向上最大位置误差与最大总位置误差分别减少了94.21%、92.62%、93.09%、93.19%及93.91%、91.96%、92.79%、92.81%;进行轨道预报时,程序运行时间分别减小了83.40%、83.29%。
2)利用PPO2算法和强化学习网络可有效修正经验大气模型得到的大气模型参数存在的误差,与深度学习方法不同,强化学习方法引入了奖励函数,在与动力学环境互动过程中为强化学习网络的训练优化提供了一个学习目标。
3)与空间站轨道预报类似,该方案对其他低轨航天器的轨道预报同样具有一定参考价值。
未来的研究工作中,可以考虑在本文研究工作的基础上,利用高精度定轨得到的轨道数据用于大气模型参数的实时修正。
猜你喜欢
军事文摘(2024年6期)2024-02-29 10:00:22
军事文摘(2023年10期)2023-06-09 09:15:06
中学生数理化·八年级物理人教版(2023年6期)2023-05-25 11:59:34
军事文摘(2022年18期)2022-10-14 01:34:16
空间科学学报(2020年6期)2020-07-21 05:37:04
空间科学学报(2020年6期)2020-01-08 16:50:22
环球时报(2019-12-05)2019-12-05 05:13:15
河北书画研究(2016年2期)2016-08-24 02:14:50
新农业(2016年18期)2016-08-16 03:28:27
小猕猴智力画刊(2015年2期)2015-01-27 22:21:45
