
基于最近邻注意力与卷积神经网络的服装分类模型
2023-09-15 05:00关紫微滕金保
毛纺科技 2023年8期
关紫微,吕 钊,滕金保
(1.西安工程大学 服装与艺术设计学院, 陕西 西安 710048; 2.西安邮电大学 计算机学院, 陕西 西安 710121)
随着电子商务的发展,人们网购商品的行为变得越来越普遍,尤其是服装行业,其电子商务的销售额占比越来越大。目前,购物网站进行商品搜索多采用输入关键字,而网站能快速定位同类型商品服饰的前提是将相应的服装进行识别和精准分类,因此服饰类别的分类具有很高的商业价值,有助于商品的快速定位。
传统的服装分类算法多基于深度学习模型[1],Zhou等[2]提出一种新的MultiXMNet方法进行服装图像分类,该方法主要由2个卷积神经网络(Convolutional Neural Networks, CNN)分支组成,一个分支通过改进异常网络设计的Multi_X从整个表情图像中提取多尺度特征,另一个分支通过MobileNetV3网络从整个图像中提取注意机制特征;在进行分类之前,对多尺度和注意机制特征进行聚合;在训练阶段,使用全局平均池化、卷积层和Softmax分类器代替全连接层对最终特征进行分类,加快了模型的训练,并缓解了因参数过多而导致的过度拟合问题。Yu等[3]提出基于CNN的服饰分类模型,设计了2种具有不同卷积层和池化层的CNN,并使用Fashion-MNIST数据集进行训练和测试,实验结果表明CNN是一种有效的服装分类方法,可以获得更高的分类精度,但会增加计算成本。陈巧红等[4]提出多尺度SE-Xception服装图像分类,采用多尺度的深度可分离卷积来提升模型特征信息的丰富度,并嵌入SE-Net模块增强有用特征通道,减弱无用特征通道,模型在2种噪声程度不同的服装数据集中均取得不错表现。以上基于传统深度学习的服装分类模型虽然有着各自的优势,并在公开数据集上的实验结果表现很好的分类效果,但没有考虑到数据集中其他样本的实例信息,因此分类效果有待提升。
针对以上分析,本文提出基于最近邻注意力(KNN-Attention)与卷积神经网络(CNN)的服装分类模型(KAMC),模型训练时通过引入KNN-Attention获取数据集中实例样本的服装信息,同时采用CNN进一步提取服装的关键特征,并进一步进行池化操作,最后将KNN-Attention的输出信息与CNN的输出信息进行融合,使模型提取的服装信息更加全面,达到提升分类效果的目的。
1 KAMC模型
本文提出的KAMC模型主要包含CNN层与KNN-Attention层,其总体架构如图1所示。
1.1 CNN层
CNN作为最常用的深度学习模型之一,在图像处理领域表现优异[5]。CNN具有较强的特征提取能力,通过设置不同大小的卷积核可以有效地提取图像潜在的深层信息,然后通过池化层对输入的特征图进一步压缩,缩减特征图,简化网络计算复杂度,最后由全连接层连接所有的特征,将输出值送给分类器,输入到系统中的服饰信息经过卷积池化后得到CNN的输出向量X°。CNN结构如图2所示。
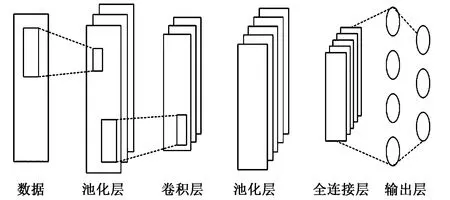
图2 CNN结构图Fig.2 CNN structure diagram
1.2 KNN-Attention层
KNN[6]是传统的机器学习算法之一,其核心思想是如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别,该算法思想简单且高效,在实际应用中较为广泛,样本之间的距离多采用欧式距离进行计算。从图1可以看出,KNN-Attention层由KNN和Attention构成,具体又包含K相似图像、标签、图像的相似度、加权标签、加权图像向量部分,其中“K相似图像”代表与当前服装图像前K个相似的服装,“标签”对应该前K个服装图像的标签,“图像的相似度”代表该K个服装图像与原服装的相似度,“加权标签”意味着加权值的大小与相似度成正相关。
假设整个训练集数据样本为X={X1,X2,…,Xn},其对应的数据集样本的标签为Y={y1,y2,…,yn},则相应的距离计算公式为:
(1)
式中:Xi为当前的预测样本;Xj为训练集数据样本X中的第j个服装样本;Xit和Xjt分别为当前预测样本和第j个服装的第t维向量;n为样本的维数。
采用欧式距离计算公式计算预测服装和整个服装数据集之间的相似度,得到整个数据集中最临近的前K个相似服装集{X1,X2,…,XK},其对应的相似服装集的标签为{y1,y2,…,yK}。使用式(2)(3)进行相似度计算得到前K个相似样本:
Si=sim(X,Xi)
(2)
S={S1,S2,…,SK}
(3)
式中:i∈{1,2,…,K};Si为进行相似度计算得到的相似度分值;S为数据集前K个序列的注意力权重,对得到的服装数据集前K个相似服装的输出标签和输出向量使用S进行加权。
对服装数据集中前K个相似样本的输出标签进行加权的公式为:
(4)
式中:Sp表示注意力权重;yp表示第p个输出标签值;p∈{1,2,…,K}。
对服装数据集中前K个相似样本的输出向量进行加权的公式为:
(5)
式中:Xp表示第p个实例样本。
数据集中的实例样本经过计算后得到加权后的输出标签y^和实例样本向量X^,将CNN的输出向量X°与X^进行融合得到Xθ,更好地表达服装图像最真实的信息,然后将融合后的Xθ输入到Softmax层进行分类。
训练环节采用Adam[7]优化器更新权重,重新定义交叉熵损失函数为:
(6)
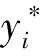
2 实验设计及分析
2.1 实验环境及数据集
实验在Ubuntu18.04系统上进行,具体实验环境如表1所示。

表1 实验环境Tab.1 Experimental environment
实验数据集为公开的Deep Fashion2[8]和Fashion AI[9]数据集中的服装数据集,Deep Fashion2是一个包含801 000张图像的大型服装数据集,该数据集来源于购物网站和Deep Fashion的收集,共包含13个类别,分别为Short sleeve top(短袖上衣)、Long sleeve top(长袖上衣)、Short sleeve outswear(短袖外套)、Vest(背心)、Sling(吊带)、Short(短裤)、Trousers(长裤)、Skirt(半身裙)、Short sleeve dress(短袖连衣裙)、Long sleeve dress(长袖连衣裙)和Sling dress(吊带裙),取Deep Fashion2数据集中Short sleeve top(短袖上衣)、Long sleeve top(长袖上衣)、Short sleeve outswear(短袖外套)、Vest(背心)4种类别进行标记和实验。Fashion AI包含8种属性维度共计114 805张图像,取其中上身视角中的领子设计属性维度进行实验,该属性下对应4种类别,分别是娃娃领、清道夫领、衬衫领、飞行员领,对4种类别分别进行标记,然后进行对比实验。所有的数据集按照5∶3∶1的比例分别作为训练集、验证集和测试集,然后输入到模型中进行学习。
2.2 参数设置
模型的参数设置对最终结果有较大的影响[10],为了使模型达到最优分类效果,在模型进行训练时对其涉及的主要参数进行动态调节。模型的参数设置主要分为模型参数和训练参数2个部分。
2.2.1 模型参数
提出的KAMC模型主要由CNN层和KNN-Attention层组成,对不同层的参数设置如下:
①CNN层的核心参数主要是卷积核的大小,卷积核的大小不同可能会对实验结果造成不同的影响,因此后续章节将进一步讨论CNN卷积核大小的设置,对比实验中卷积核大小设置为(3,4,5),Drop_out值设置为0.5,随机失活50%的神经单元。
②KNN-Attention层核心参数为K值的大小,KAMC模型中K的取值相较于其他参数对最终的结果产生的影响较大,因此后续章节将着重分析K的不同取值对实验结果造成的影响,对比实验中设置K的默认值为8。
2.2.2 训练参数
训练参数主要包括激活函数、批处理的大小(批大小)、优化器、学习率等[11],训练参数设置如下:
①激活函数通过为模型增加非线性能力使得模型可以更好地学习更深层次的信息,因此为模型选择合适的激活函数是非常有必要的,KAMC模型的激活函数设置为ReLU。
②批大小会对梯度下降的方向产生较大的影响,过大的批处理会导致泛化能力差,过小的批处理会导致KAMC模型的收敛速度慢,实验批大小设置为256。
③合适的优化器可以让KAMC模型在训练时找到模型的最优解,增强模型的效果,KAMC模型对比实验采用的优化器为Adam。
④学习率的设置对最终的结果影响较大,过大的学习率会出现损失值震荡,过小的学习率会导致模型收敛速度慢,发生过拟合现象,KAMC模型的学习率设置为0.001。
2.3 评估指标
采用准确率(Acc)、精确率(Pre)、召回率(Rec)、精准率和召回率的调合平均数(F1)作为评价指标,混淆矩阵如表2所示。

表2 混淆矩阵Tab.2 Confusion matrix
表2中行和列分别表示分类前样本的实际类别及分类后对样本的预测类别,具体计算公式见式(7)~(10):
(7)
(8)
(9)
(10)
2.4 对比实验
为验证KAMC模型的性能,在相同条件下与以下基准模型进行对比:
①AlexNet[12]由8个网络层组成,包括前5个卷积层和后3个全连接层,并在每个卷积层和全连接层之后使用ReLU非线性激活函数,然后输入到分类器中进行分类。
②CNN-Attention[13]由CNN和Attention组成,模型先用CNN提取图像信息,然后使用Attention进一步将模型的注意力集中在对分类结果影响较大的像素点上,经过Attention加权后输入到分类器中进行分类。
③KNN[14]K值设置为8,通过欧式距离计算公式计算预测样本和其他样本的距离,通过前8个样本投票表决该样本的分类结果。
④Agrawal[15]使用2种新颖的CNN架构,一种架构的过滤器数量随着网络深度的增加保持不变,而另一种架构的过滤器数量随着深度的增加而减少,2种架构全部采用大小为8的卷积核。
KAMC模型和以上基准模型在公开数据集上的实验结果如表3~6所示。其中,表3为模型在Deep Fashion2数据集上的总体效果,表4为模型在DeepFashion2数据集上识别不同服装类别的准确率,表5为模型在Fashion AI数据集上的总体效果,表6为模型在Fashion AI数据集上对领子设计属性识别的准确率。
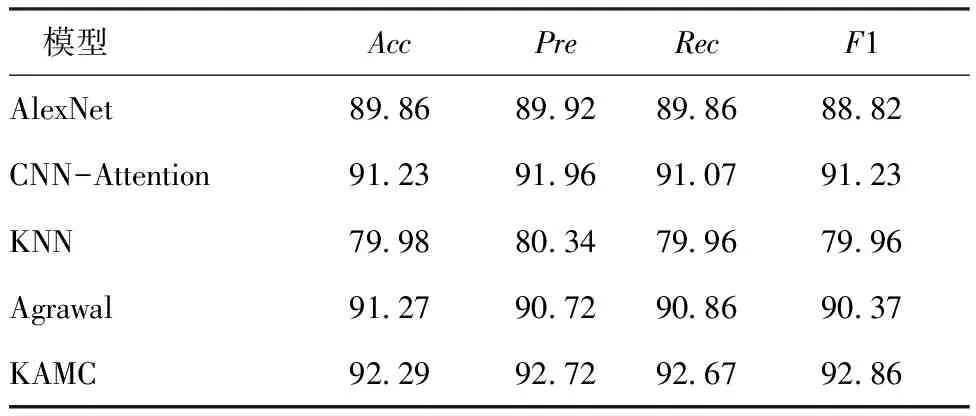
表3 Deep Fashion2总体实验结果对比Tab.3 Comparison of overall experimental results of Deep Fashion2 %
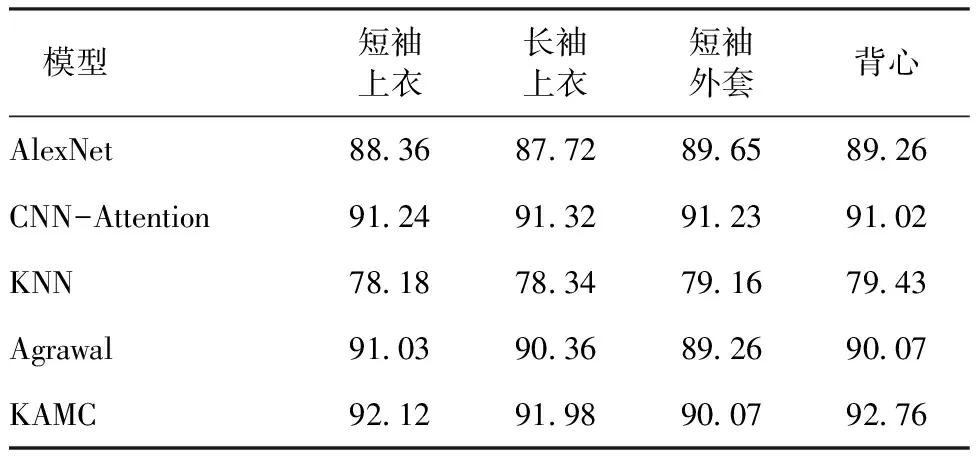
表4 Deep Fashion2不同服装类别Acc实验结果对比Tab.4 Comparison of experimental results of Acc of different clothing categories in Deep Fashion2 %

表5 Fashion AI总体实验结果对比Tab.5 Comparison of overall experimental results of Fashion AI %

表6 Fashion AI不同领子设计Acc实验结果对比Tab.6 Comparison of experimental results of different collar design Acc of Fashion AI %
由表3~6可以看出,KAMC模型在2个数据集上的分类效果最好,KAMC模型在Deep Fashion2和Fashion AI上的准确率相较于AlexNet模型性能分别提升了3.43%、3.90%,相较于CNN-Attention模型性能分别提升了2.06%、2.21%,相较于Agrawal提出的模型性能分别提升了2.02%、1.76%。AlexNet模型、CNN-Attention模型和Agrawal提出的模型进行图像特征提取时通过其改进的CNN可以更有效地提取当前样本的深层信息,但没有有效地利用训练集数据中其他样本的实例信息,因此提取的特征是不全面的,而KAMC模型不仅可以提取当前样本的信息,在此之上通过引入KNN-Attention使得在数据集中实例样本的信息也得到了充分的使用,因此提取的特征更全面,更能代表最真实的图像信息,因此分类效果也更好。KAMC模型相较于KNN模型在Deep Fashion2和Fashion AI上的准确率分别提升了13.4%、11.87%,这是因为KNN模型进行分类时只关注与当前样本相似的其他样本的信息,没有考虑到当前样本潜在的深层信息,而提出的KAMC模型在此基础上引入Attention使得提取相似样本的信息更有优势,除此之外还引入了CNN,弥补了对当前样本信息提取的不足,因此分类效果也更好。
同时还可以看出,KAMC模型在精确率、召回率、F1值上的性能提升也很大,相较于AlexNet模型,KAMC模型在Deep Fashion2数据集上精确率、召回率、F1值上分别提升了4.08%、3.81%、5.04%,KAMC模型在Fashion AI数据集上精确率、召回率、F1值上分别提升了2.24%、2.83%、2.90%;相较于CNN-Attention模型,KAMC模型在Deep Fashion2数据集上精确率、召回率、F1值分别提升了2.02%、2.60%、2.63%,在Fashion AI数据集上精确率、召回率、F1值分别提升了9.24%、2.83%、2.90%;相较于KNN模型,KAMC模型在Deep Fashion2数据集上精确率、召回率、F1值分别提升了13.64%、13.71%、13.90%,在Fashion AI数据集上精确率、召回率、F1值分别提升了12.10%、13.70%、12.27%;相较于Agrawal提出的模型,KAMC模型在Deep Fashion2数据集上精确率、召回率、F1值分别提升了3.26%、2.81%、3.49%,在Fashion AI数据集上精确率、召回率、F1值分别提升了1.24%、2.54%、2.38%,以上实验结果充分显示了KAMC模型的优势。
模型训练所耗费的时间是评价模型的另一个重要指标,因此在以上对比实验的基础上进行模型训练时所花费时间的实验,实验结果如表7所示。

表7 训练时间实验结果Tab.7 Experimental results of training time min
训练时间实验是在单机下进行的,系统为 Ubuntu Server 18.04 LTS,GPU为Ampere A100 77 40GB,CPU 为 Intel(R) Xeon(R) Gold 5218,采用 CUDA10.1加速计算。从表7可以看出,KAMC模型训练时间与对比模型所消耗的时间接近,在可接收训练时间范围内提高了模型的分类效果。
2.5 参数分析
参数设置不同会对最终的分类效果产生不同的影响。为进一步探究最符合KAMC模型的参数设置以提升模型性能,对CNN卷积核大小、KNN-Attention层的K值进行详细分析。将卷积核大小分别设置为3、4、5、(3,4)、(3,5)、(4,5)、(3,4,5),K值固定为8,在Deep Fashion2数据集上进行实验,实验结果如表8所示。

表8 卷积核大小对实验结果的影响Tab.8 Effect of convolution kernel size on experimental results %
由表8可以看出,当卷积核大小设置为(3,4,5)时,KAMC模型在公开数据集上的表现最优,与单个最优卷积核为5时相比性能提升了2.09%,这是因为多尺寸卷积核可以提取更多的服装信息,对结果起到了促进作用,因此由多尺寸卷积核组成的模型要比单一尺寸卷积核组成的模型效果好,模型的卷积核大小设置为(3,4,5)。
为验证K值设置的大小对实验结果的影响,设置K值的取值范围为1~20,固定卷积核大小设置为(3,4,5),在Deep Fashion2数据集上进行实验,实验结果如图3所示。当K值等于0时模型预测性能较低,此时KNN-Attention层不发挥作用,模型退化为CNN模型,KAMC模型的准确率为87.92%。当K值从0逐渐增大时,可以看出KAMC模型的预测性能逐渐提升,此时KAMC模型由于结合了KNN-Attention,相较于CNN模型可以更有效地提取预测样本的实例信息,因此性能更好。当K值设置为8~10时模型的表现最好,准确率为93.36%。从图3还可以看出,K值的不同设置对最终结果会造成不同的影响,当K值从0在一定的范围内增大时KAMC模型的预测性能也逐渐提升,但当K值的设置超过阈值时,模型的预测性能开始降低。这是因为K值的设置超过阈值时会引入过多对结果影响不大的相似服装,从而出现特征冗余的问题,影响KAMC模型的分类性能,因此K值的设置要适中,KAMC模型的对比实验中的最佳K值应设置在8~10,使KAMC模型的预测性能达到最大值。

图3 K值对实验结果的影响Fig.3 Influence of K value on the experimental results
2.6 消融实验
消融实验可以进一步检验KAMC模型的性能,以便更好地理解神经网络的学习行为,因此对所提模型进行消融实验。分解KAMC模型,设置为KNN模型、KNN-Attention模型和CNN模型,在相同的实验环境下进行对比实验,结果如表9、10所示。
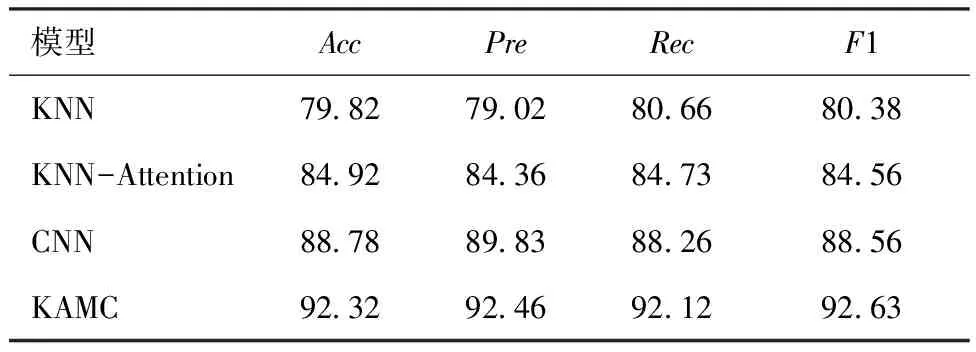
表9 Deep Fashion2消融实验结果Tab.9 Ablation experiment results of Deep Fashion2 %
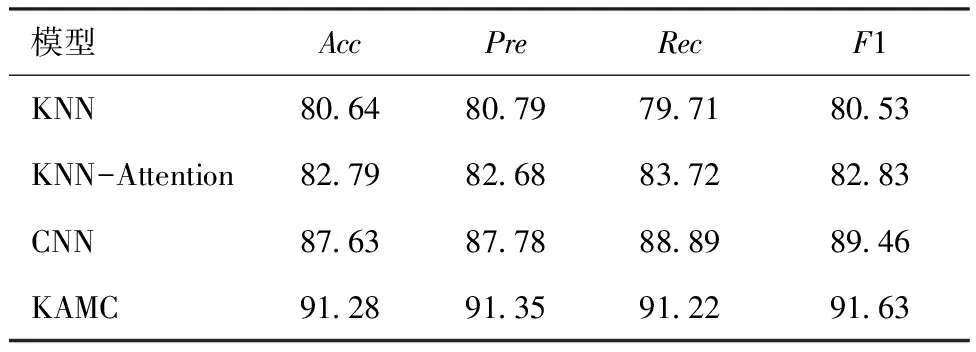
表10 Fashion AI消融实验结果
从表9、10可以看出,KNN-Attention在2个公开数据集中的实验效果优于单一的KNN模型,这是因为单一的KNN模型进行分类任务时无法有效区分不同的实例信息对最终结果造成的不同影响,认为提取的K个实例样本发挥同等作用,而通过Attention计算后可以看出提取的K个实例样本与原样本的近似程度不同,因而对最终结果造成的影响也不同,与原样本更近似的样本应该发挥更大的作用,因而权重也更大。CNN模型的分类效果优于KNN模型和KNN-Attention,这是因为CNN特有的网络结构可以学习到服装图像更深层次的信息,而KNN模型和KNN-Attention进行分类时只采用了类比投票的方式,没有考虑到当前样本潜在的特征,因此CNN模型的分类效果更好。从表9、10可以看出,KAMC模型的分类效果最好,这是因为进行分类任务时KAMC模型不仅可以通过CNN模型提取服装局部关键特征,还引入了KNN-Attention模型,使得KAMC模型在提取训练集实例信息上更有优势,因此KAMC模型的表现最优。
3 结 论
为了解决传统服装分类模型进行分类时无法有效提取训练集中其他样本的实例信息的问题,提出基于最近邻注意力(KNN-Attention)与卷积神经网络(CNN)的服装分类模型(KAMC)。通过引入KNN-Attention使得模型在提取数据集其他相似样本信息上更有优势,有效地解决了特征提取不全的问题。当卷积核大小为(3,4,5),K值为8时,KAMC模型在Deep Fashion2和Fashion AI上的准确率分别为92.29%和92.13%。通过与其他模型的对比实验进一步验证KAMC模型的优势,可以有效提升服装分类效果。
猜你喜欢
趣味(作文与阅读)(2021年9期)2022-01-19
北京航空航天大学学报(2021年9期)2021-11-02
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
数学物理学报(2017年5期)2017-11-23
米娜·女性大世界(2016年9期)2016-12-02
股市动态分析(2015年20期)2015-09-10
电视技术(2014年19期)2014-03-11
