
基于机器学习的地铁站区域共享单车需求预测
2023-09-14 12:18杨鑫宇
石家庄铁道大学学报(自然科学版) 2023年3期
杨鑫宇, 靳 群
(1.石家庄铁道大学 交通运输学院,河北 石家庄 050043;2.石家庄铁道大学 河北省交通安全与控制重点实验室,河北 石家庄 050043)
共享单车作为近几年新兴的交通工具,其便捷、高效等优点深受众多出行者青睐,其位置分布多集中于地铁站附近,并常以接驳的方式衔接地上与地面交通,与此同时,供需不平衡及堆积问题日渐凸显。
为了科学准确地了解地铁站周边区域的单车投放量,国内外学者将更多的目光聚焦于单车的实时需求预测,例如ZHOU et al[1]利用马尔可夫模型对中山市共享单车的需求量进行了预测;王鹏涛[2]构建出一种基于随机森林-RBF神经网络分位数回归的共享单车需求量预测模型; XU et al[3]通过长短期记忆网络模型对不同时段的共享单车出行量进行了预测;YANG et al[4]针对传统预测方法过拟合风险问题,提出一种基于机器学习的共享单车短时预测模型,并采用City Bike公开数据对其进行验证;宋鹏等[5]构建了基于支持向量机和主成分分析方法的共享单车预测模型;LU et al[6]利用RNN网络模型预测未来一天的共享单车租赁情况,并用You Bike数据进行测试验证;王凌苏[7]利用GCN-LSTM组合模型预测未来0.5 h的共享单车交通量;CHEN et al[8]建立了一种以递归神经网络为基础的预测模型,并将其运用到了纽约花旗银行区域的共享单车使用量预测中;孙启鹏等[9]构建出一种非负矩阵分解算法的BP神经网络预测模型,并利用北京市摩拜单车工作日骑行数据对其进行了辅助验证,结果显示该模型的预测效果优于传统BP模型。
通过总结发现,已有研究考虑因素不全,以天气、时间、历史数据居多,在预测方法上以传统的神经网络模型为主,此类模型极易出现过拟合现象,导致预测结果误差较大,而岭回归模型中损失函数的惩罚项可以很好地解决上述问题,其主要应用于电力、金融、计算机等领域,在城市公共交通领域应用较少。基于上述原因,将研究重点侧重于地铁站周边的共享单车投放量预测中,并借助相关计算机软件建立出一种以岭回归法为导向的地铁站区域共享单车投放量预测模型,为类似站点的单车量化预测提供借鉴。
1 共享单车影响因素的筛选
1.1 影响因素初选
共享单车的使用受多种因素影响,包括人口社会经济、自然环境、建成环境、天气、时间和出行者属性等。结合地铁站周边居民出行特征,本次主要考虑社会经济、城市建设用地类型、建成环境、交通设施和天气等因素,初步建立起机器学习算法中特征矩阵,具体如表1所示。

表1 共享单车影响因素初选特征矩阵
1.2 影响因素复选
1.2.1 基于随机森林的影响因素复选
随机森林模型[10-11]的特征选择指对初始特征变量的优良性和重要性进行评价,结合表1,设定每轮剔除特征变量比例为0.1,停止迭代条件为m=13。过程如表2所示。

表2 随机森林特征选择过程
表2数据显示,第3次迭代的袋外评分达到最高,即表示模型的袋外数据最好,因此,剔除交运功能区密度、旅游休闲区密度、风速、交叉口个数、人口密度、非机动车道长度6个特征变量。
1.2.2 基于AdaBoost的影响因素复选
AdaBoost算法[12-13]的特征选择过程与随机森林类似,具体过程如表3所示。

表3 AdaBoost特征选择过程
从表3可看出,依旧第3次迭代时误差率达到最高,即此时模型误差最小,故剔除交运功能区密度、旅游休闲区密度、交叉口个数、非机动车道长度、人口密度、公交站数量6个特征变量。
结合表2、表3,剔除其相同因素,保留剩余15个特征,即产业功能区密度、商业功能区密度、地铁出站客流、温度、居住用地面积占比、交通设施用地面积占比、空气质量指数、地铁进站客流、路网长度、非机动车停车区面积占比、居住功能区密度、商业用地面积占比、公共服务区密度、公交站数量、风速。
2 共享单车投放量预测模型构建
2.1 岭回归模型
2.1.1 计算原理
岭回归[14-15]是一种用于线性回归分析的统计方法,其通过向用于优化模型的损失函数添加惩罚项来降低模型中系数的大小,防止过度拟合,强度可以通过alpha参数控制,值越高模型越简单且系数更少;反之模型越复杂且系数较多。在OLS方法中,Y与X的关系式如下
(1)
其中,损失函数的正则化公式为
argmin(β)=‖Xβ-Y‖2+‖γβ‖2
(2)
将γ=kI代入式(2),化简得
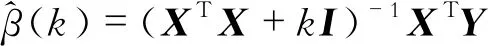
(3)
式中,I为单位矩阵;k取值范围为[0,+∞)。
2.1.2 岭参数K选择
岭回归模型中K值的大小直接决定预测结果的误差变化程度,其选择又依赖于参数β和σ2,结合此特点,决定选用岭迹图法进行K值选择,如图1所示。图1中,横轴为岭参数K的取值,纵轴为标准化回归系数,其中岭估计协方差公式如下
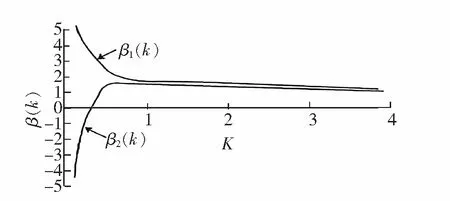
图1 岭迹图
(4)
式中,cij(k)为方差扩大因子,与参数K呈负相关。
2.2 基于岭回归的共享单车投放量预测模型
在Python中,调用第三方库scikit-learn模块中自带的岭回归函数,分别设置工作日和节假日的因变量为shb_1和shb_2,自变量为终选后的15个影响因素,岭参数为0~0.30,步长为0.01,绘制的岭迹图如图2、图3所示。

图2 工作日共享单车岭迹图

图3 节假日共享单车岭迹图
根据式(4)确定此时工作日模型岭参数K=0.12,节假日岭参数K=0.13,模型处于最优,测算公式分别为
shb_1=-192.807-25.424×Res_1+264.51×Bus_1+44.711×Tra_1-0.059×Res_a+0.011×
Bus_a-0.167×Pub_a+0.245×Ind_a+0.307×Sub_1+0.197×Sub_2+151.354×Roa_l-362.437×
Nov_a+1.796×Bus_s-0.044×Air_i+2.658× Tem_a-0.629×Win_s
(5)
shb_2=-197.964-60.547×Res_1+829.676×Bus_1+134.816×Tra_1-0.264×Res_a+0.04×
Bus_a-0.752×Pub_a+0.989×Ind_a+0.19×Sub_1+0.314×Sub_2+170.92×Roa_l-241.149×
Nov_a-0.173×Air_i+1.653×Bus_s+1.686×Tem_a-0.291×Win_s
(6)
3 实例应用
3.1 站点概况
益康路站、济泺路站和北园站分别为济南地铁二号线西起的第7、9、11站点,如图4~图7所示,所属线路整体呈东西走向,西起王府庄站,东至彭家庄站,2021年3月26日正式运营,线路途经西客站片区、腊山片区、老城区、东部新区和唐冶新区,全长36.4 km。

图4 济南市地铁线路图

图5 益康路站地理位置图

图6 济泺路站地理位置图

图7 北园站地理位置图
经过对3个站实际调查,发现其邻近区域均有公交站、商场、酒店、住宅区等,共享单车需求量较大,有必要对此范围内的单车投放量进行预测。
3.2 数据来源
本次所获取的数据主要为2022年6月18日至6月24日期间的行政区划数据、共享单车的时段变化量、轨道交通客流进出站数据、轨道交通站点数据、城市道路网数据和各类POI数据,具体如表4所示。
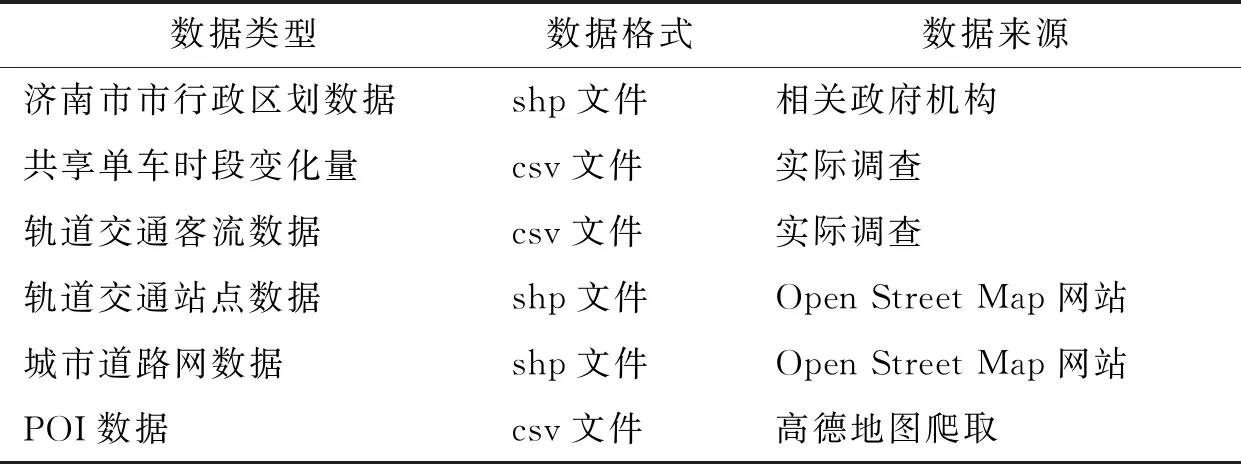
表4 数据文件划分
3.3 单车投放量预测流程
结合前2节梳理的共享单车影响因素及需求预测模型,给出地铁站共享单车投放量预测整体流程,具体如图8所示。
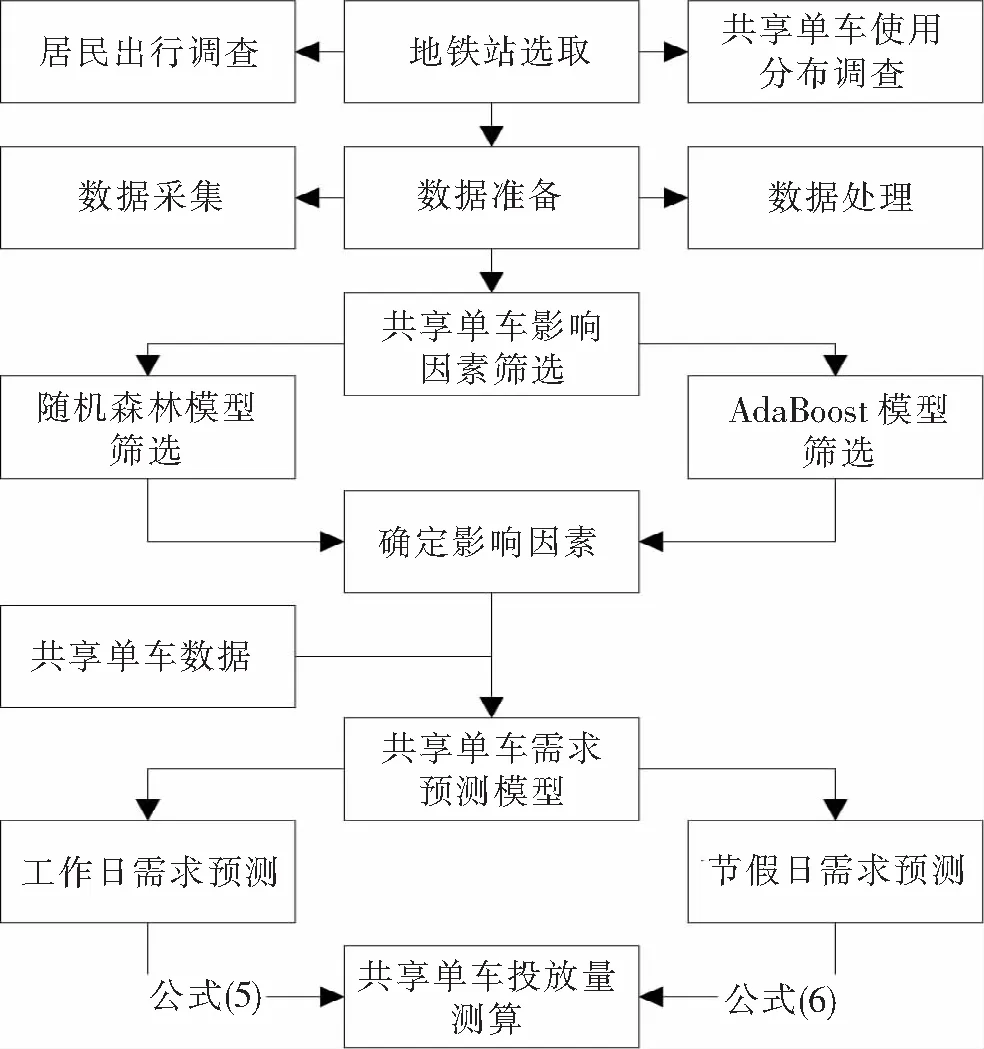
图8 共享单车投放量预测流程
投放量一般会结合共享单车的高峰小时借车系数和周转率指标进行测算,公式如下

(7)
(8)
式中,T为单车高峰小时借车系数;β为单车高峰小时周转率;shb为单车需求量。
3.4 单车投放量预测结果
(1)小区划分。根据益康路站、济泺路站及北园站位置特点和相关划分原则,将其周边小区统一划分为4类,具体如表5所示。

表5 交通小区划分类型及特点
(2)工作日各站点小区单车投放量预测结果。结合表4数据库文件、2.2节单车需求预测模型及式(5)、式(6),得到各车站4类小区工作日和节假日期间的单车投放量,如表6、表7所示。
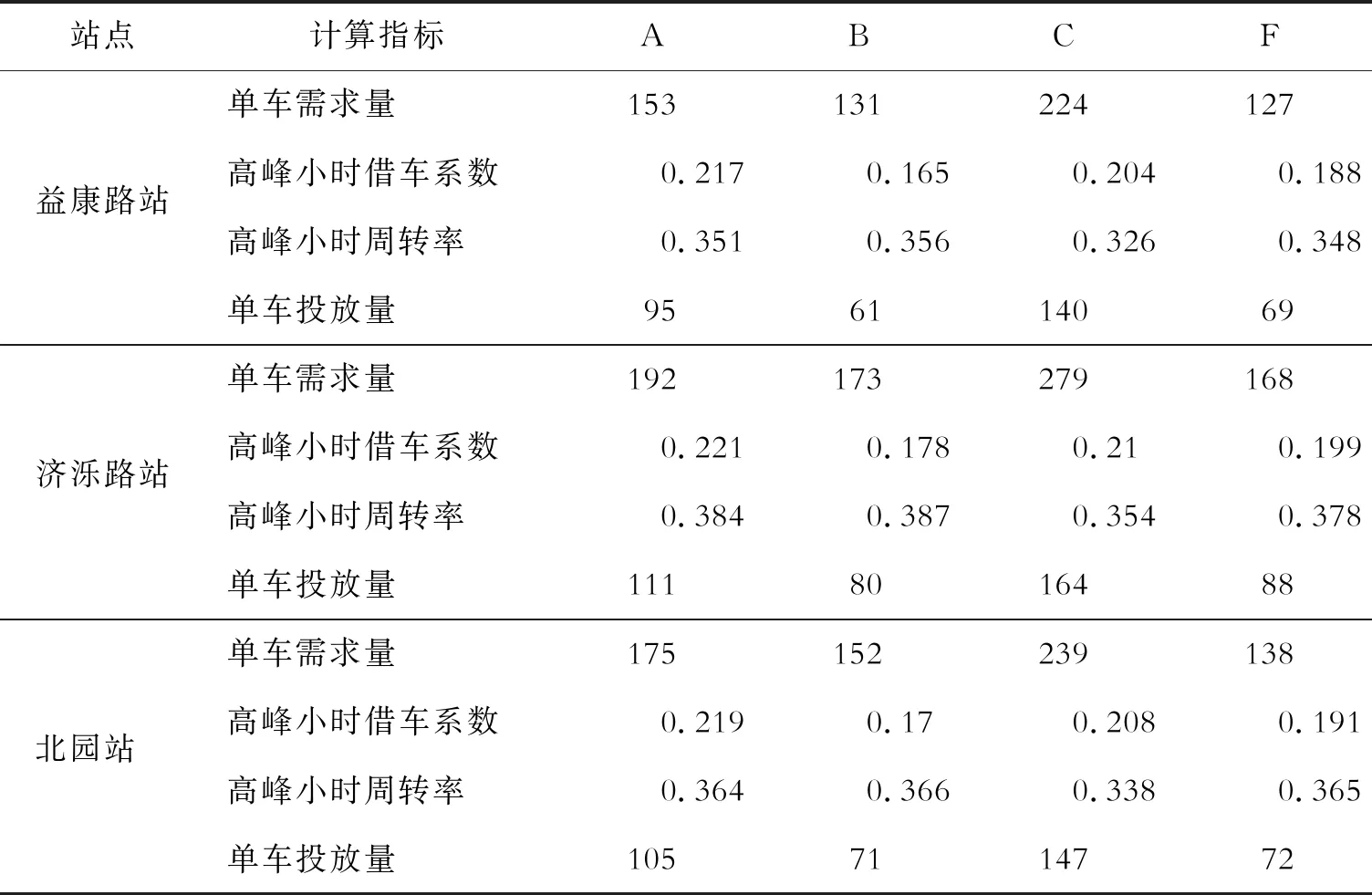
表6 工作日各站点小区单车投放量

表7 节假日各站点小区单车投放量
结合表6、表7中数据可看出,3个车站的单车投放量自上而下依次为济泺路站>北园站>益康路站,且3站节假日整体投放量之和高于工作日,与需求量相差不大。
4 结论
以地铁站点区域内的共享单车为研究对象,提出一种基于岭回归的预测模型,并将其运用到了益康路站、济泺路站及北园站的单车投放量预测中,结论如下:
(1)借助随机森林模型与AdaBoost模型对造成单车数量变化的影响因素进行筛选,通过袋外评分及误差率对特征进行判别,二者均在第3次迭代满足模型最优,故最终剔除交运功能区密度、旅游休闲区密度、交叉口个数、非机动车道长度、人口密度等5项指标,选取剩余15项指标作为后期岭回归模型预测的自变量。
(2)将岭回归模型导入至Python软件中,得出3站周边4类小区未来工作日期间单车投放量共计1 203辆,节假日期间共计1 375辆,与济南市共享单车实际使用量特征大致相同。通过此类讨论,间接突出了岭回归模型在共享单车预测领域方向上具有实用性高、适用范围广等优点,为相关人员进行后续深入研究打下基础。
