
基于改进型PPYOLOE的电力标志牌检测识别技术研究
2023-09-06 08:51袁靖,潘明,朱宁
上海电力大学学报 2023年4期
袁 靖, 潘 明, 朱 宁
(上海置信电气有限公司 研发中心, 上海 200335)
随着我国数字化、智能化的日益加深,电网智能升级成为了发展热点[1-2]。变电站和电缆线路的智慧巡检系统是智能电网建设的基础,也是实现设备互联和数据分析的关键环节[3]。因此,使巡检系统具备云边端数据协同处理能力意义重大[4]。
标志牌是变电设备和输电线路上必须装设的电力设施。其包含了设备和杆塔的电力线电压、标号和位置信息,通过标志牌信息能够快速定位设备或线路的故障位置[5]。无人机巡检识别标志牌信息可以提高工作人员的工作效率和安全系数,但同时需要机载系统能够高准确率地识别标志牌信息,从而快速定位故障。标志牌长期处在户外和强电场的环境中,普遍存在掉漆和锈蚀等情况。这就对标志牌识别系统提出了高要求。
目前,电力标志牌的主流识别系统基于深度学习技术模型搭建。文献[6]采用级联CascadeR-CNN模型解决了交通标志因被遮挡、目标小难以被高精度识别和定位的问题,但TDOA算法的局限性,在非视距环境下误差会变大。文献[7]采用基于轻量化 YOLOv3 和 Tesseract OCR(Optical Character Recognition,光学字符识别)的电力设备标志牌识别方法,实现了标志牌检测和文字的一体化识别,但 YOLOv3 模型本身的网络结构复杂,计算消耗较大。文献[8]探讨了一种改进的 MobileNetv3-YOLOv3 算法,并引入了SSPNet去重复特征,在交通标志牌检测速度上取得了提升,但是准确度的提升有限。文献[9]在YOLOF模型的网络检测分支中融入了注意力机制以增强网络对交通标志牌目标的表示,试图找到检测精度和速度的平衡点,但仅限于简单标识,尚未扩展到复杂文字标志牌检测任务。文献[10]采用两阶段算法,检测阶段检测出图像中的交通标志牌,分类阶段对交通标志牌先后进行大类和子类划分,算法精度上优于基准单阶段识别算法,但是检测速度为15帧/s,无法满足实时检测的要求。文献[11]提出了构建双尺度注意力模块,嵌入 YOLOv3 的特征提取网络,对特征通道进行重校准,同时进行多尺度特征的融合,增强了算法的特征信息提取能力,相较YOLOv3算法,检测精度得到了较大提升,但是对极端天气下的数据多样性考虑较少。文献[12] 提出了一种融合卷积神经网络YOLOv5t与传统机器学习方法M-split的轻量化中文交通指路标志文本提取与识别算法,在自制数据集 TS-Detect 上检测精度为90.1%,但其精度尚未满足工业应用要求。
深度神经网络模型通常存在准确率和实时性难以兼顾,且推理模型结构冗余的问题。因此,本文提出了一种基于改进型PPYOLOE检测模型,获得了较理想的精度和速度平衡,并通过量化蒸馏技术大幅压缩了模型体积,保证检测精度下降维持在可接受的范围内。实验结果表明,本文所提方法对电力标志牌的检测精度(mAP0.5)达到了98.4%。另外,采用OCR引擎Paddle OCR,结合自制样本库使文字检测查准率和识别准确率分别达到了92.6%和90.9%,为电力标志牌检测识别任务提供了应用参考。
1 电力标志牌检测模型
1.1 PPYOLOE模型建模
一阶段目标检测模型相较二阶段模型在速度上优势明显,其中YOLO系列作为一阶段模型代表在工业界被广泛应用。
以YOLOv1模型为例,输入图像被重置分辨率为448×448,同时由S×S网格分割,每个网格负责预测中心点落在该网格内的目标。其中,每个网格会预测B个边界框,每个边界框包括5个值:预测框左上角横纵坐标、边界框宽高以及是否包含目标为前提的预测框与真实框交并比值。同时,每个网格也预测C个条件类别概率,从而得到推理时预测结果的置信度。这既体现了目标类别出现在预测框中的概率,也体现预测框与真实框的匹配程度。
在PASCAL Visual Object Classes (VOC)数据格式中,设置S=7,B=2,C=20,那么最终预测结果是一个7×7×30的张量,YOLOv1模型结构和张量解析如图1所示。此时每个网格对应(B×5+C)=30的张量。
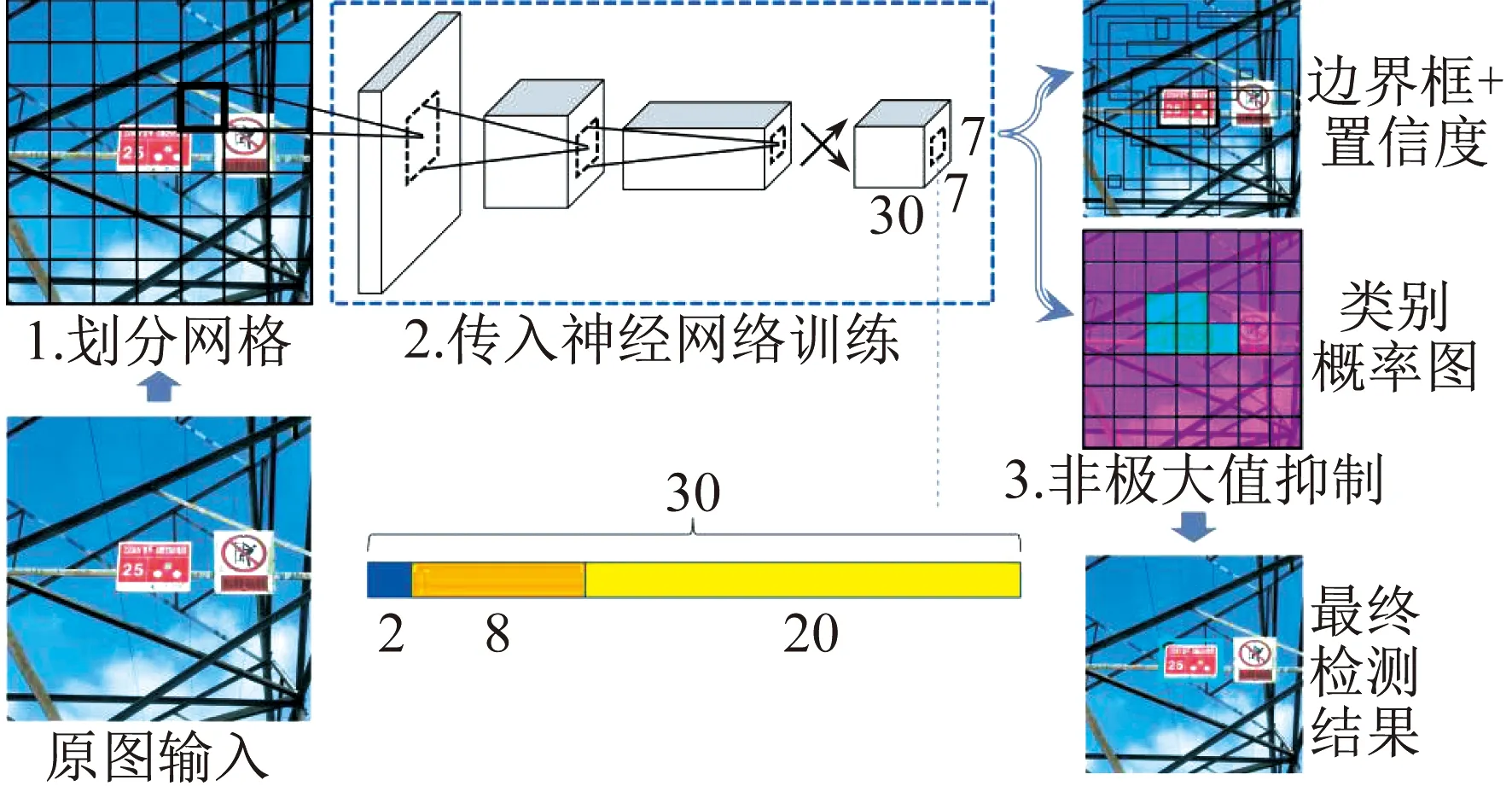
图1 YOLOv1模型结构和张量解析
随着学术界对YOLO系列模型的持续研究,其网络结构和标签分配等方面都在不断改进,其中PPYOLOE模型在公开数据集COCO(Microsoft Common Objects in Context)上性能表现突出。PPYOLOE采用兼具残差连接和密集连接特性的RepResBlock,提高了预测实时性;使用ESE(Effective Squeeze and Extraction)改进ET-head(Efficient Task-aligned Head),进一步提升了检测速度和精度;设计了任务对齐学习(Task Alignment Learning,TAL)克服任务不对齐问题。
PPYOLOE模型结构和训练预测过程如图2所示。在训练过程中,输入图像首先经过数据增强,例如翻转、Mixup操作,产生更为丰富的输入数据送到主干网络,由主干网络提取出不同尺度的特征信息,然后由颈部网络将不同尺度特征进行融合,再进入头部网络进行分类和回归,最后传入标签分配器计算损失值。在预测推理过程中,输入图像同样经过主干、颈部、头部网络,不同的是最后会传入后处理流程,进行非极大值抑制,得到预测结果。
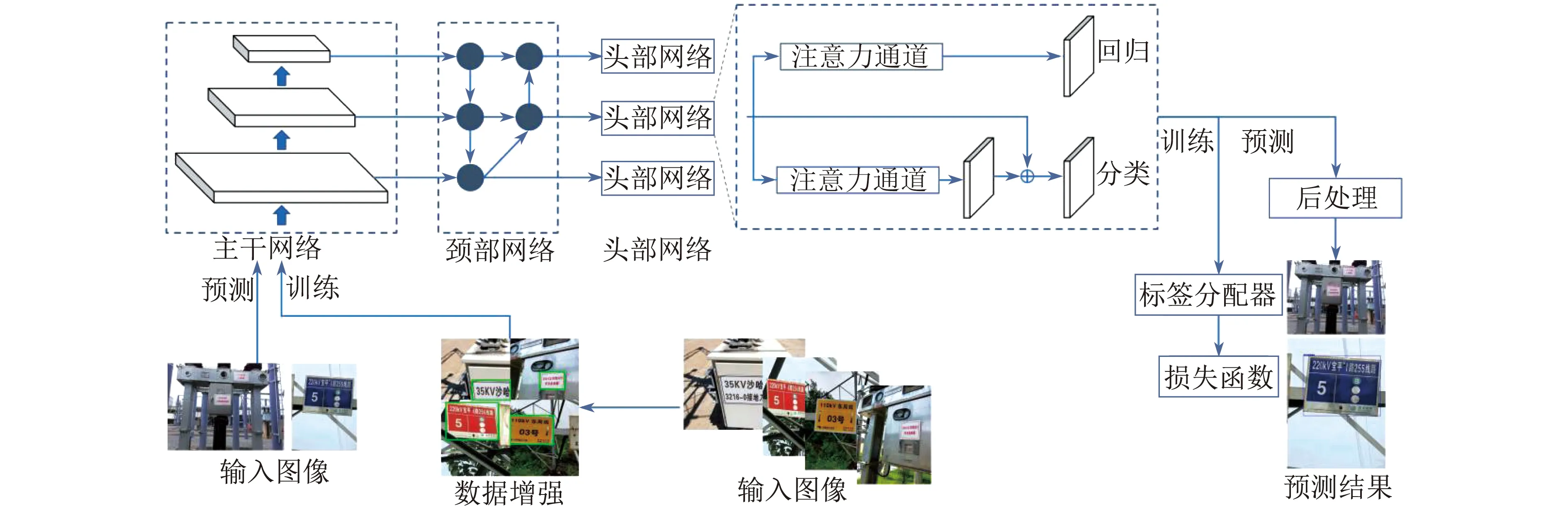
图2 PPYOLOE模型结构和训练预测过程
1.2 PPYOLOE模型改进
1.2.1 RepResBlock模块结构改进
PPYOLOE模型的RepResBlock改进过程如图3所示。
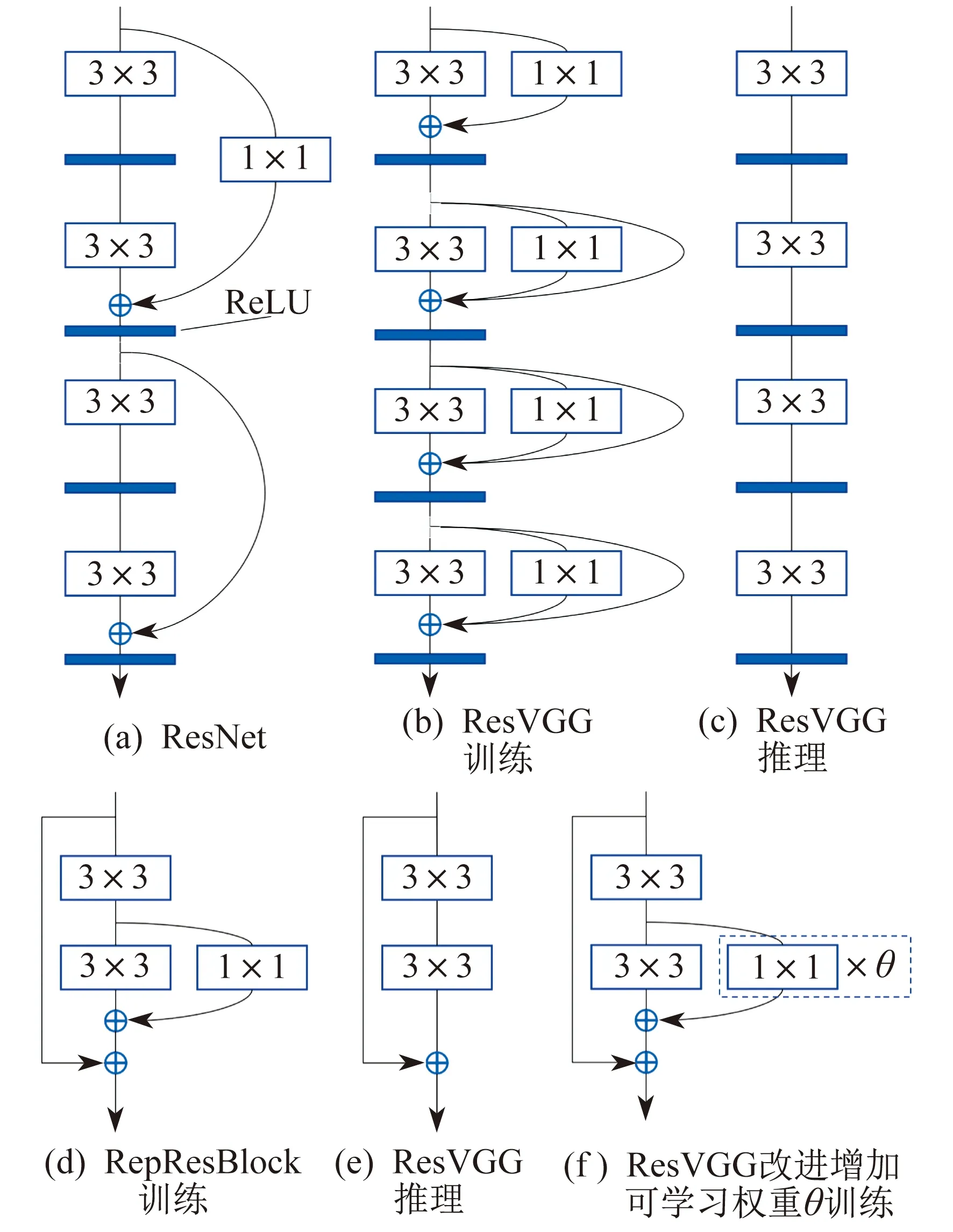
图3 RepResBlock改进过程
受ResNet中引入的瓶颈结构的启发,建立TreeNet模型[13]如图3(a)所示。首先提出了一种轻量级的树块,将每个3×3卷积层替换为3×3层和1×1卷积的堆栈。其中1×1层负责增加维度,3×3层由后续卷积层进一步处理。然后将所有1×1层和最后3×3层的输出连接。因此,当聚合相同数量的后续特征时树块具有更深的网络结构,同时减少了模型复杂性。受以上思想影响,RepVGG模型[14]的主体仅使用3×3 卷积和线性整流函数(Rectified Linear Unit,ReLU),并采用结构重参数化来解耦训练时的多分支结构和推理时的平面结构,具体如图3(b)和图3(c)所示。PPYOLOE模型[15]使用的 RepResBlock 在训练阶段如图 3(d)所示,在推理阶段将 RepResBlock 重参数化为 RepVGG样式的基本残差块,如图 3(e) 所示。
1×1卷积常被用于减少网络权重数量和计算量,同时引入激活函数增加网络的非线性,但在RepResBlock中要其负责参数学习和增加维度,其感受野过小,每个权重只学习一个位置的单独特征,存在表征不足的问题。RepResBlock中设计1×1卷积的主要用途就是提升模型训练时的网络表征能力,且RepResBlock又广泛用于主干和颈部网络,其性能好坏会影响整个网络的特征学习。因此,将1×1卷积运算公式F(x)=∑wixi+b改进为F(x)=(∑wixi+b)×θ,其中:xi为特征输入,wi为1×1卷积权重,b为偏置项,θ为可学习权重,i为特征通道数。1×1卷积结合可学习权重θ后,1×1卷积在模型训练时负责降低特征维度,θ可配合其一起挖掘样本的特征,相当于弥补了1×1卷积自身的不足,从而增强RepResBlock的表征能力,并提升整个网络的特征表达力和泛化能力。RepResBlock中1×1卷积增加可学习权重θ的结构如图3(f)所示。
本文通过采用改进的RepResBlock,解决了1×1卷积表征能力不足的问题,显著提升了模型的目标检测性能,同时增加的模型参数量和计算量可忽略不计。
1.2.2 损失函数改进
检测模型头部网络中的损失函数计算包括分类和回归两个分支。PPYOLOE模型的回归分支采用的是广义交并比(Generalized Intersection over Union,GIoU)损失函数[16]。GIoU损失函数将预测框和真实框非重叠区域作为影响因子,解决了IoU无法优化两框非相交情况而导致梯度消失的问题。其计算公式为
(1)
式中:IoU——A和B的交并比;
C——同时包含A和B的最小框;
A——预测框;
B——真实框。
但是,GIoU损失函数仍存在两个问题:一是在训练初期,预测框与真实框相交之后才开始回归,导致了收敛延迟;二是当预测框在真实框内部时,GIoU退化为IoU,无法反映两者的位置关系。因此,本文改进损失函数引入完全交并比(CompleteIntersection over Union,CIoU)损失函数[17]。其计算公式为
(2)
(3)
(4)
式中:ρ(·)——欧几里得距离;
b——预测框的中心点位置;
bgt——真实框中心点位置;
c——覆盖预测框和真实框的最小包围框对角线长度;
α——正权重参数;
v——测量纵横比的一致性;
wgt、hgt——真实框的宽和高;
w、h——预测框的宽和高。
CIoU损失函数同时考虑了预测框和真实框之间的3个几何因素:重叠面积、中心点距离和宽高比。在迭代中,可以保证预测框和真实框的宽高比更为接近,从而加快预测框的回归收敛。
本文通过采用CIoU损失函数,解决了预测框与真实框不相交收敛慢的问题,同时预测框在回归过程中获取了真实框的宽高比,提高了模型训练的收敛速度和回归精度。
1.2.3 数据增强Mosaic方法改进
本文采用了Mosaic方法[18]进行数据增强,相较于CutMix方法只混合2个图像,Mosaic方法混合4个训练图像。这可以使模型学习到常规数据以外的信息,也可以显著减小对大批处理数量的需求。Mosaic方法数据增强过程如图4所示。

图4 Mosaic方法数据增强过程
然而,Mosaic方法存在调整标注框后负样本误检率变高的问题。通过Mosaic方法裁剪拼接后,会出现大量标注框被裁剪的标志牌样本,如图4(c)和4(d)右上角图像所示,模型会根据裁剪结果自动调整标注框大小。但训练过程中正负样本的判定依据是预测框与真实框的交并比,而此类不完整的真实框会导致很多负样本被视作正样〗本,严重影响预测结果的合理性。本文提出一种Mosaic的改进方法,设置标注框可用性阈值,当调整后的标注框面积不足原本的30%时,该标注框会被弃用,从而保证训练样本的一致性。
另外,在Mosaic方法数据增强过程中,训练样本的真实框会被大量缩小,存在改变真实框分布的问题。这里引入YOLOX[19]的Mosaic使用技巧,即在总共80个epoch的训练周期最后10个epoch时关闭Mosaic,相当于变相加大了真实框分布,从而增益模型精度。
本文针对数据增强过程中标注框被调整缩小,导致负样本被误检为正样本,以及真实框分布不足的问题,通过设置标注框调整后的弃用阈值和最后10个epoch关闭Mosaic的方法,更好地提升模型识别电力标志牌的特征,提升检测模型的泛化能力,从而解决了Mosaic方法调整标注框大小机制不完善的问题。通过采用改进后的Mosaic方法,检测模型3个精度指标都得到了明显提升。
2 电力标志牌文字OCR
本文基于PaddleOCR对电力标志牌的文字信息进行检测识别。OCR识别过程如图5所示。
由于原OCR检测识别模型的训练样本库与电力场景有较大差异,所以其对电力标志牌的文字识别率并不能满足工业应用的要求。为了让模型网络学习到更有针对性的样本信息,采集制作了241个文字检测样本和509个文字识别样本,训练集和验证集划分比例均为8∶2,用作电力标志牌OCR模型进一步训练的场景专用样本,示例如图6所示。
3 实验过程与结果分析
3.1 实验环境介绍
实验使用的训练平台CPU为Intel Xeon Silver 4208 CPU @ 2.10GHz八核,GPU是NVIDIARTXA6000 48 GB,系统是Ubuntu20.04。软件环境是Python3.7.4和PaddlePaddle2.3。
3.2 PPYOLOE检测结果
实验使用了758张的电力标志牌图像,其中变电设备和输电线路样本数量分别为406张和352张,图像格式为3通道。在模型训练之前,将已标注的标志牌图像样本按8∶2的比例随机划分为训练集和验证集。基础超参数设置如表1所示,检测结果示例如图7所示。

表1 基础超参数设置
3.3 目标检测结果分析
本文采用COCO模型评价标准,查准率(Precision)代表模型预测出的所有目标中,预测正确的目标数占比;查全率(Recall)代表所有待测真实目标中,被模型正确预测出的目标数占比;AP(Average Precision)代表推理模型在每个类别上的好坏,用Precision-Recall曲线面积表示;mAP(mean AP over classes)代表推理模型在所有类别上AP平均值;mAP0.5代表预测框与真实框交集大于>0.5的目标被认定为正样本;mAP0.5:0.95代表预测框与真实框从0.5到0.95,每递增0.05的mAP取平均值,即mAP0.5:0.95=(mAP0.5+mAP0.55+…+mAP0.95)/10;FPS(Frames Per Second)表示每秒帧数。
实验中采用基于Objects365数据集的预训练模型,该数据集是由旷视和北京智源人工智能研究院联合推出的目标检测任务新基准,其在63万余张图像上标注了365个对象类,训练集中有超过1 000万个边界框,数据规模上超越了Pascal VOC、ImageNet和COCO数据集。另外,本文使用了HSV(色度Hue,饱和度Saturation,明度Value)方法,其具有直观特性的颜色空间,作为色度、饱和度、明度3个通道的扰动,实现数据增强的效果。
本文对PPYOLOE模型的训练过程逐步做了改进,包括引入基于Objects365大规模数据集的预训练模型,改进数据增强Mosaic方法,设置色调扰动系数(色度、饱和度、明度扰动系数分别为0.015、0.7、0.4),改进RepResBlock模块结构,以及采用CIoU损失函数,并通过消融实验进行了验证,最终得到3个mAP指标最佳的改进方案。表2为逐步改进后PPYOLOE模型消融实验结果比较。

表2 逐步改进后PPYOLOE模型消融实验结果比较
由表2可知:采用改进后的Mosaic方法,mAP0.5指标较上一步提升了0.5%;采用改进的RepRes Block(+θ),mAP0.5:0.95指标较上一步提升了1.1%;采用CIoU损失函数,mAP0.5:0.95指标较上一步提升了0.7%。
此外,对本文提出的改进型PPYOLOE模型与主流的几种目标检测算法进行对比测试,结果如表3所示。

表3 改进型PPYOLOE模型与其他主流模型性能对比
由表3可知:相比模型大小相当的YOLOv5-s模型,改进型PPYOLOE模型的mAP0.5:0.95指标提升了6.6%;相比检测速度相当的YOLOv6-nano模型,改进型PPYOLOE模型的mAP0.5:0.95指标提升了2.2%。
3.4 模型压缩
本文采用量化和蒸馏两种模型压缩方法。量化采用低比特定点计算替代浮点运算,模型的大小和计算量显著降低;蒸馏使用大模型监督小模型训练,达到比直接训练小模型更高的精度。另外,TensorRT作为NVIDIAGPU高性能推理C++库,已集成于PaddlePaddle中,并与深度学习框架以互补的方式工作。在模型推理时,TensorRT自动对网络进行压缩、优化,从而提升推理速度。
模型压缩前,为了进一步检验改进型PPYOLOE模型的性能,将标注样本增加到了1 500个,其中训练样本1 201个,验证样本299个,目标类别增加到8个。训练完成后,对模型进行量化和蒸馏,压缩后的模型大小仅为原来的26.1%。在NVIDIATeslav100 16 G推理显卡上进行了3种预测精度(FP32、FP16、INT8)下的验证,结果如表4所示。
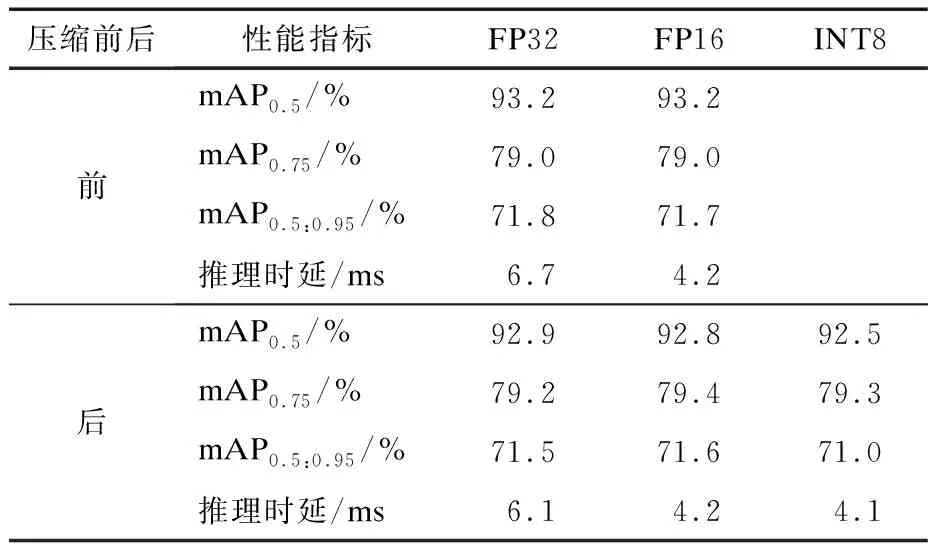
表4 压缩前后模型性能对比
由表4可知,模型在Tensor RT开启下精度指标仅下降0.5%以内。因此,本文的模型压缩方案在模型压缩率和查准率保持方面效果显著,为模型在边缘侧和端侧部署提供了参考价值。
3.5 文字检测识别结果分析
将经改进型PPYOLOE模型检测得到的标志牌图像传入PaddleOCR模型进行文字处理,其中OCR检测查准率使用上述COCO标准,OCR识别准确率(Accuracy)=正确识别出的文字数/总文字数×100%。本文使用了95个标志牌目标检测结果作为文字检测识别的输入样本,分别通过PaddleOCR原模型和自制样本库训练得到的模型进行验证和预测,实验结果如表5和图8所示。

表5 OCR文字检测识别结果对比
由表5可知,自制样本库模型比PaddleOCR原模型检测查准率和识别准确率分别提升了7.1%和9.1%。由图8可知,倾斜标志牌和110 kV残损内容被有效识别出。由此可见,通过自制样本库训练得到的OCR模型在电力巡检场景下可以取得更加优越的标志牌文字检测和识别效果。
4 结 论
(1) 在电力标志牌目标检测任务中,通过改进PPYOLOE模型的RepResBlock模块结构、引入CIoU损失函数、优化数据增强等方法,实现了mAP0.5=98.4%的高检测精度。其性能比其他主流检测模型更加优越。
(2) 针对边缘侧设备的存储限制,采用了量化和蒸馏方案,模型压缩为原来的26.1%,精度指标只下降了0.5%。
(3) 通过自制电力标志牌OCR样本库,文字检测查准率达到了92.6%,文字识别准确率达到了90.9%,满足电力巡检对标志牌信息识别的高精度要求。
猜你喜欢
建材发展导向(2023年24期)2024-01-11
环球时报(2022-12-28)2022-12-28
北京航空航天大学学报(2021年9期)2021-11-02
运输经理世界(2021年10期)2021-09-02
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
作文小学中年级(2018年2期)2018-03-28
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
