
面向绝缘手套佩戴状况检测的小目标检测与匹配算法
2023-09-06 04:29郑海洋宋纯贺武婷婷周忠冉
小型微型计算机系统 2023年9期
郑海洋,宋纯贺,武婷婷,刘 硕,周忠冉
1(中国科学院 沈阳自动化研究所 机器人学国家重点实验室,沈阳 110016)
2(中国科学院 网络化控制系统重点实验室,沈阳 110016)
3(中国科学院 机器人与智能制造创新研究院,沈阳 110169)
4(中国科学院大学,北京 100049)
5(中国科学院 沈阳自动化研究所,沈阳 110016)
6(南京南瑞信息通信科技有限公司,南京 210006)
1 引 言
随着社会经济和新能源经济的发展,对电力的需求越来越大.由于各种各样的原因,电力行业频频发生安全生产事故,影响了整个社会经济的正常运行,因此,在电力作业现场必须树立牢固的安全生产意识,所有现场人员按照规定穿着施工设备,防止安全事故的发生,确保电力供应的稳定.
在电力作业现场会出现一些不安全的施工行为,为安全事故的发生埋下了隐患,这些不安全施工行为包括:在施工现场随意吸烟、不佩戴安全帽、不正确穿着工作服装和不按规定佩戴绝缘手套等等,针对这些不安全行为,利用现有的施工现场的网络摄像头等视频采集设备,通过计算机视觉领域的目标检测算法,可以自动检测施工现场内的不安全施工行为.基于图像识别的变电站作业人员不安全施工行为检测可以有效的保障电力生产安全,目前对不安全行为的检测已经有了很多研究[1-4].但是,对于施工人员是否正确佩戴绝缘手套的研究相对较少.首先,绝缘手套佩戴情况检测需要完成人员手部和绝缘手套的检测,是典型的小目标检测[5-7]问题.因此,相对于一般的目标检测[8]问题,人员手部和绝缘手套的检测具有更高的难度.其次,在多人场景中,在完成人员手部和绝缘手套的检测后,还要识别未佩戴手套的具体人员,这进一步提升了绝缘手套佩戴情况检测的难度.图1给出两个变电站场景中人员与绝缘手套佩戴情况检测实例.在图1左图中看出两个人的手部位置面积占图片总体面积的比值非常小,对这种小目标的检测加大了模型预测的难度.图1右图表示目标检测模型可以分别检测到图片中的手与人体的位置,但是缺少手部的归属信息,无法快速定位到未佩戴绝缘手套的施工人员.

图1 变电站场景中人员与绝缘手套佩戴情况检测实例Fig.1 Examples of detection of wearing of personnel and insulating gloves in the substation scene
本文在YOLOv3[9]网络结构上进行改进,参考特征金字塔网络结构[10],设计了一种新的网络结构,进一步的进行信息融合,得到一个更大尺度预测特征层,新的预测特征层中包含了更多小目标的信息.借鉴空间金字塔池化[11]的思想,在提取特征的骨干网络之后加入空间金字塔池化层.改进的算法模型对小目标的检测精度得到了提升.对目标检测算法进行训练,直接预测作业人员是否为未佩戴手套的人(wronggloveperson)还是佩戴手套的人(gloveperson)的效果非常差.直接以人为单位在进行训练时,手的部分占人体部分较少,手的这部分特征会被忽视掉,而面积较大的身体部分会被作为主要特征,导致这种模型直接预测的效果比较差.针对这一个问题,本文设计了一套逻辑分配算法,使用改进的YOLOv3 算法检测之后,再进行逻辑分配,找到图片中未正确佩戴绝缘手套的人,判断出人的类别.
本文的主要贡献包括2个方面:
1)针对手部面积过小导致YOLOv3模型检测小目标能力差的问题,本文提出了一种改进多尺度融合的方法,将YOLOv3中小型目标预测特征层进行上采样,然后与骨干网络的第2个残差块的输出特征融合,在尺寸为152×152的特征图上预测小目标.融合得到的新特征层充份提取了浅层特征中的位置信息,使改进模型更加准确的预测小目标;
2)针对输出结果是人的类别这个问题,本文设计了一种双阶段检测模型,使用经过改进的YOLOv3模型先预测出手与人的位置,再把相应的类别的手分配给对应的人,正确识别未佩戴绝缘手套人员的准确度得到大幅度提升.
2 相关工作
在变电站施工现场的不安全行为会给电力生产造成极大的安全隐患.使用图像识别算法对变电站施工现场的作业人员进行实时检测,及时发现不安全行为,保证电力系统安全.在不正确佩戴安全帽方面,刘晓慧等[12]设计了一种传统检测算法,通过检测人脸皮肤颜色,裁剪帽子所在的位置,最后将提取的特征输入到支持向量机[13]进行分类识别.随着深度学习[14]的快速发展,卷积神经网络[15,16]已经广泛的应用在图像处理方面.王正等[17]提出了一种基于深度学习的安全帽佩戴状态实时检测方法.该方法使用目标检测算法找出画面中每个人体框的位置信息,再手动提取安全帽所在的位置,最后,使用卷积神经网络判断人员是否佩戴了安全帽.
孙召龙等[18]使用深度学习算法检测施工现场的吸烟行为,使用摄像头拍摄的人员吸烟图片来构造吸烟数据集,在构建的数据集上训练YOLOv5模型,用训练完成的算法模型检测和追踪吸烟行为.陈睿龙等[19]设计了包含注意力[20]等模块的深度学习检测模型,提高了对烟头等微型目标的检测精度.
王振等[21]提出一种基于颜色特征识别工作服的检测模型,使用对目标像素中心加权和削弱背景颜色权值的方法,通过计算工作服不同颜色的质心的变化距离,实现对工作服穿着情况的预测.刘欣宜等[22]提出一种基于深度学习的工程现场施工人员是否正确着装的检测方法,在Faster RCNN算法的基础上,对原算法的损失函数进行改进,改进后的算法可以有效的识别施工人员的着装情况.
对未正确佩戴绝缘手套不安全行为检测的相关研究较少.对未正确佩戴绝缘手套不安全行为检测的难点有两个方面:第1是手部目标较小,目前的算法模型检测精度不高;第2是要通过逻辑匹配定位到具体的人员.本文提出了一种基于卷积神经网络检测绝缘手套与分配的算法模型,首先使用深度学习算法检测图像中的目标,再通过逻辑分配算法确定具有不安全行为的施工人员.
3 提出的算法
针对手部/手套面积小、有效样本数量少、多人场景中未佩戴手套人员难以识别等问题对识别算法带来的挑战,本文的主要工作包括3点:
1)通过旋转、平移、改变饱和度、添加高斯噪声等方法扩增数据集的样本数量,增强模型的泛化能力.
2)对YOLOv3的特征金字塔结构进行改进,增加更大尺度的预测特征层,使深层特征的语义信息和浅层特征的位置信息充分融合.
3)针对模型检测到的目标之间无逻辑关系问题,设计了一套基于计算距离、交并比和面积占比的分配算法,可以有效的将手部匹配到相应的人.
整体流程图如图2所示.
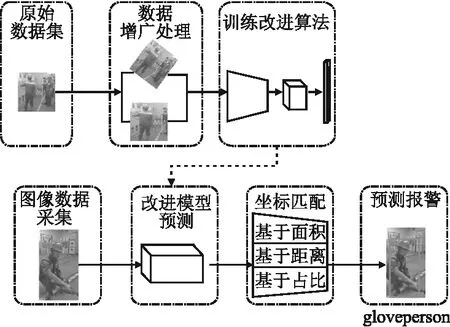
图2 提出算法的整体流程图Fig.2 Flow chart of the proposed method
3.1 数据增强
由于数据集中图片数量比较少,而且每一类特征的数量也不平衡,导致模型在预测类别时不准确,比如标签glove的数量过少,如图3所示.针对这一问题,本文对数据集进行数据扩增[23].

图3 原数据集Fig.3 Original data set
1)直方图均衡化
直方图均衡化主要是增强图片对比度,将图像的直方图分布处理成均匀分布,计算过程如公式(1)计算.对于本文中的RGB图像,首先把图像从RGB格式转换为HSV格式,之后再进行直方图均衡化处理.
(1)
其中,n是像素的总和,nk是灰度级为rk的像素个数,L为可能的灰度级总数.
(2)
通过公式(2)可将图像中灰度级为rk的各像素映射到输出图像中灰度级为sk的对应像素.
2)高斯模糊
高斯模糊方法首先由高斯分布函数计算出权重,如公式(3),再将原图像中的每一个像素点变换为每个像素与周边像素加权平均后的值:
(3)
3)随机平移
随机平移就是保持图像大小不变,将整副图像随机向上或向下或向左或向右移动一定的距离.
4)图像缩放
图像缩放是保持图像长宽比例不变,将整副图像作为一个整体,以图像中心为中心点进行整体缩放.
3.2 K-means聚类分析
YOLOv3模型需要预先手动设置初始候选框,选择合适的初始候选框可以提高模型的检测精度与检测速度.因此在对数据集进行数据增强之后,使用K-means聚类算法对数据集进行数据分析.
distance=1-IoU(B,C)
(4)
公式(4)中的作为衡量聚类结果的指标,B代表所有的边界框,C是在B中挑选出来的n个簇中心,通过比较distance的大小,distance越小表示离选定的簇心越近,则被分配到这一簇中,经过多次迭代,直到簇心不再改变,则聚类完成.
对输入尺寸为608×608的图片,经过K-mease聚类算法之后得到的初始候选框为[3,4] [5,6] [8,10] [12,13] [16,20] [26,27] [45,40] [24,77] [77,70] [45,151] [86,227] [166,336].
3.3 空间金字塔池化网络
由于深度卷积网络中全连接层的存在,需要固定大小的输入图像,在对图片进行裁剪或扭曲等一系列预处理操作时,会造成图片原有信息的部分丢失,影响算法模型的检测精度.空间金字塔池化层使用多尺寸空间箱,作用于不同尺寸的输入图像,而且使用可变的图像进行训练可以防止过拟合.不用考虑输入图像的尺寸,空间金字塔池化层都会生成一个固定大小的输出.与单窗口的滑动窗口相比,有更好的鲁棒性.本文参考空间金字塔池化的方法,在骨干网络与全连接层之间加入空间金字塔池化层,从细粒度到粗粒度多个级别中提取图像的局部特征,进行信息的融合.3个空间箱的卷积核尺寸依次为(13×13),(9×9),(5×5),如图4中SPP模块所示.

图4 改进YOLOv3模型Fig.4 Improved YOLOv3 model
3.4 改进yolov3结构
YOLOv3是一阶段检测算法的代表,由骨干网络和检测头组成.其骨干网络采用的是Darknet-53,负责提取输入图像的特征.Darknet-53的网络结构参考了ResNets[24]方法,引入残差学习,避免了深层网络中的梯度消失或梯度爆炸问题.骨干网络包含了5个残差组,一个残差组又由若干个残差组员(RES)构成,一个残差组员中有两个卷积标准化激活层(CBL)和跳层加法,如图4所示.卷积标准化激活层包括卷积层、批标准化层和Leaky ReLU层.
YOLOv3在3个不同尺度的预测特征层上进行物体检测,将深层特征与浅层特征相融合得到的52×52的特征层,在此特征层上进行小型目标的检测,26×26的特征层上检测中型目标,13×13的特征层上检测大型目标.因此,YOLOv3很好的兼顾了大目标和小目标的检测.当输入的图片尺寸为2048×2048时,图片中尺寸为158×158和76×76的物体,经过下采样之后,在中、小目标的预测特征层上已经被压缩为小于一个像素,所以模型无法检测那些尺寸小于76×76的物体.本文对YOLOv3网络结构进行改进,增加了一个更大尺度的预测特征层,提高了算法模型对小目标的检测准确率.
由于数据集中图片均为高清图片,本文将骨干网络的输入尺寸上调为608×608.深层网络包含了很多语义信息,浅层网络拥有更多的位置信息.本文将YOLOv3中76×76的小型目标预测特征层再进行上采样,得到152×152的特征层,再与Darknet-53的第2个残差块的输出进行融合产生新的小目标预测特征层.因此,改进后的YOLOv3模型的预测特征层的尺度为152×152、76×76、38×38和19×19.改进YOLO v3模型结构如图4所示.改进后的YOLOv3模型拥有4种不同尺度的预测特征层,提高了对图片中小目标的检测能力.
3.5 逻辑分配算法
使用训练好的检测模型对测试集进行预测,模型预测的结果会有大量重复边界框.本文通过非极大值抑制(IoU)方法去掉大量的重复边界框,如公式(5)所示.其中A、B表示两个预测物体的边界框,相交程度超过一定阈值的同一类别只保留分数最高的边界框.
(5)
经过筛选剩下的类别边界框散落在图片之上,每一个边界框之间没有对应的逻辑关系.本文设计了一套分配算法,可以将目标检测算法检测出的物体进行逻辑匹配,找到相对应的关系,具体的分配算法流程如图5所示.

图5 分配算法流程图Fig.5 Flow chart of matching algorithm
在手的分配阶段,首先,判别检测算法预测的物体种类里是否有人,若没有,则直接输出图片中无预测目标.如果有人,接着判断是否只有一个人,当只有一个人的情况,便可以直接查询预测种类中手的种类来确定图片中的施工人员是否正确佩戴了绝缘手套.若预测结果中有两个人以上,本文设计3种匹配手与人之间关系的算法规则.第1种规则是计算每只手的边界框的中心与每个人的边界框的中心的距离,将距离最小的手与人划分为一组;第2种规则是计算每一只手的边界框与每一个人的边界框的交并比,将交并比最大的手与人划分为一组.但是当近景的手边界框落入到远景人边界框时,由于远景人的边界框比较小,会导致交并比较大;通过第3种规则计算出每一个手部与每个人身体相交的面积与身体面积的比值,将比值最大的手与人划分为一类.最后,由上述3种规则,得到3种不同的分配组合,统计每一个手对每个人的投票,根据票数便可以确定最终人边界框与手边界框之间的匹配关系.
4 试验检测与结果分析
4.1 数据集及实验平台
本文训练模型使用的数据集是未公开的数据集,它是由广东电网在现场真实拍摄图像,标签有person,wrongglove,glove总共3个类别.对数据集进行图像增广后总共有3221幅图像,训练集有2577张图片,测试集包括644张图片.
实验平台:操作系统Ubuntu18.04,深度学习框架pytorch1.8,CPU为Intel(R)Xeon(R)W-2145,内存为64G,GPU为NVIDA GeForce RTX 2080,显存为16G.
4.2 算法评估标准
我们使用平均精度(AP)检测我们算法模型的工作性能,它是目标检测领域常用的一个评价指标.平均精度AP值越大,目标检测模型的检测精度就越高,模型性能越好.通过对正确率(Precision)和召回率(Recall)的计算,可以得到平均精度(AP).当模型的预测框与人工标记的真实框的交并比大于设定的IOU阈值时,预测框被认定为正样本.否则,将预测框划分为负样本.正确率和召回率的计算方法如下:
(6)
真实的正样本经过检测后,检测结果依然为正样本的样本个数为TP,真实的负样本经过检测后,检测结果为正样本的样本个数为FP.
(7)
真实的正样本经过检测后,检测结果为负样本或未检测到的样本个数为FN.
(8)
其中P(r)是精度-召回曲线
4.3 结果分析
本文在测试集上对SSD[25]、Faster RCNN[26]、YOLOv3和改进YOLOv3模型进行目标检测测试,4种模型的平均准确率如图6所示.

图6 4种模型的目标检测结果Fig.6 Object detection results of four models
通过图中实验结果可以观察到,4个模型对person的检测精度基本相同,SSD模型的AP仅有84.99%,其他3个模型的AP都达到了90%以上,表明4种模型对大目标的检测能力相当.但是在对中目标glove和小目标wrongglove检测方面的差异非常大,SSD的对中小目标的检测效果最差.原YOLOv3的效果仅仅比SSD好一些,但也比较差.经过改进的YOLOv3对中小目标的检测精度有大幅度提升.
本文在测试集上对原YOLOv3+分配算法模型和改进的YOLOv3+分配算法模型进行测试,两个模型的两种类别的平均准确率如图7和图8所示.
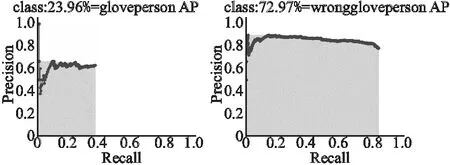
图7 原YOLOv3+分配算法的检测结果Fig.7 Detection results of the original YOLOv3+allocation algorithm
与原YOLOv3+分配算法模型相比,改进的YOLOv3+分配算法模型的平均准确率由48.47%提高到77.75%,实验结果表明,改进的YOLOv3+分配算法与原YOLOv3+分配算法相比,有更高的检测准确率.
对训练数据集中的图像进行检测,改进后的模型降低了对图片中物体的错检与漏检,并且能自动识别和定位图像中的类别,并显示相应的位置.图9是原YOLOv3模型预测得到的结果,通过图片可以发现原YOLOv3模型没有检测出图中所有的目标.图10是改进YOLOv3模型预测得到的结果,根据图片可以看出改进后的YOLOv3算法可以将图片中出现的人员全部检出,并且分配正确.

图9 原YOLOv3+分配算法的检测结果Fig.9 Detection results of the original YOLOv3+allocation algorithm

图10 改进YOLOv3+分配算法的检测结果Fig.10 Detection results of the improved YOLOv3+allocation algorithm
在相同的实验平台条件下,使用相同的数据集,分别使用YOLOv3、Faster R-CNN和SSD直接进行训练和检验,以及使用原YOLOv3+分配算法模型和改进YOLOv3+分配算法模型进行训练和预测.在测试集上得到的平均精度和算法模型大小的统计结果如表1所示.
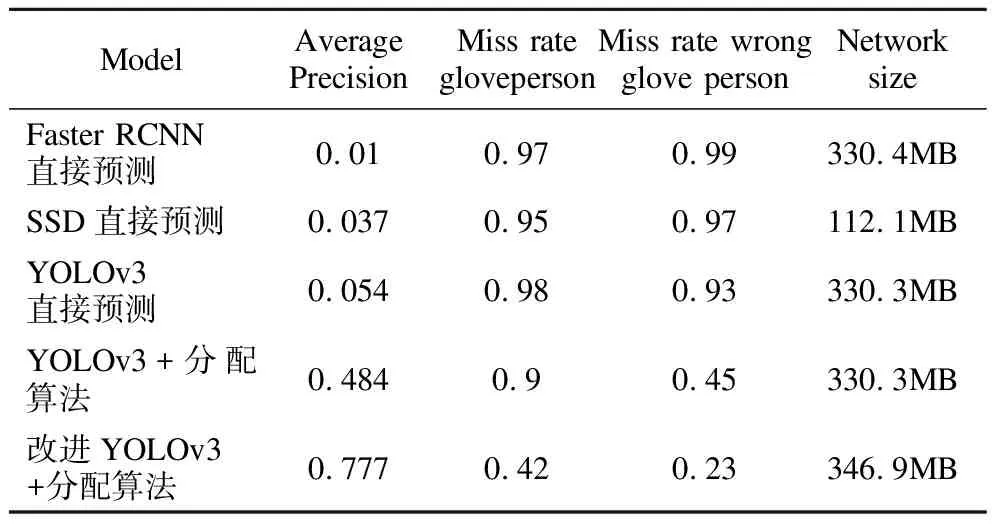
表1 不同方法的比较Table 1 Comparision of different methods
由表1可知,所有的直接预测施工人员是否正确佩戴绝缘手套的目标检测模型在测试集上基本都是不可用的,改进后的YOLOv3+分配算法的mAP值比原YOLOv3+分配算法高29.3%,表明本文采取的改进策略是有效的,提高了算法模型的检测能力.
在相同的实验平台条件下,使用相同的数据集,对SSD、Faster RCNN、YOLOv3和改进YOLOv3进行目标检测的测试,测试结果如表2所示.

表2 不同目标检测模型的比较Table 2 Comparision of different object detection algorithms
在表2中可以发现,在所有的1阶段算法模型中,改进的YOLOv3的mAP最高,在与2阶段算法模型Faster RCNN的比较可以看出,虽然mAP比较接近,但是改进YOLOv3的检测速度远远快于Faster RCNN.
5 总 结
本文提出了一种检测未佩戴绝缘手套不安全行为的方法.首先是平衡类别数量差异,并且对数据集图片数量进行扩增.然后通过聚类分析算法找出数据集特有的初始候选框,加快模型的检测速度.接着对YOLOv3的特征提取层进行改进,将预测小目标的特征层进行上采样,与骨干网络的第二个残差块输出进行融合,得到一个更大尺度的预测特征层.最后通过逻辑分配算法确定未佩戴绝缘手套的施工人员.实验结果表明,改进后的模型提高了对小目标的检测准确率,逻辑分配算法可以有效的对目标检测结果进行相互匹配.后续会增加需要检测的类别数量,如:监督人员,将所有人员信息关联分析,可以更好地保障电力作业安全生产.
猜你喜欢
阅读与作文(小学高年级版)(2021年8期)2021-09-12
铁道通信信号(2020年9期)2020-02-06
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
小哥白尼·趣味科学画报(2019年12期)2019-02-28
幸福(2018年33期)2018-12-05
经济技术协作信息(2018年30期)2018-11-22
铁道通信信号(2018年6期)2018-08-29
数位时尚(幼儿教育)(2018年3期)2018-04-12
阅读与作文(小学高年级版)(2017年7期)2017-08-04
