
融合事实文本的问句分解式语义解析方法
2023-09-06 04:29杨玉倩高盛祥余正涛
小型微型计算机系统 2023年9期
杨玉倩,高盛祥,余正涛,宋 燃
(昆明理工大学 信息工程与自动化学院,昆明 650500)
(昆明理工大学 云南省人工智能重点实验室,昆明 650500)
1 引 言
知识库问答(Knowledge Base Question Answering,KBQA)技术旨在从预先建立好的结构化知识库中查找问题的答案,因其广泛的应用场景和巨大的应用价值成为学术界和工业界的研究热点之一.随着知识库的规模越来越大,如Freebase[1]、DBpedia[2]、Wikidata[3]等大型知识库中存储了丰富的关联知识,这为知识库问答提供了数据基础.
然而,目前的问答系统大多只能回答事实型问题,不能很好的处理复杂问题,难以理解问题中的复杂语义[4].原因在于,回答一个复杂问题通常会涉及知识库中多个关联的三元组信息,三元组需要满足与问题相关的约束条件,再经过一系列多跳推理或数值计算才能得到正确答案[5,6].比如:“The author of The Art of War lived in what city? ”,这个复杂问题的主题实体是“The Art of War”,涉及知识库中两个三元组信息
语义解析(Semantic Parsing,SP)作为知识库问答技术的主流方法之一,核心是将非结构化的自然语言问题转化成机器能够理解和执行的形式语言,如SPARQL等,并使用该形式语言作为结构化查询语句对知识库进行查询,从而获取答案[7,8].目前,此类方法在解析复杂问题时主要依赖于句法分析方法,为句子中不同的词标记不同的角色,辅助解析句子的语义.但是,单纯依靠基于句法的模型并不能很好的理解复杂问题中的语义,会导致语义角色标注错误,从而影响后续推理与计算.并且,随着问题复杂度的提高,语义解析的方法几乎失效.因此,如何更好地理解自然语言问句中的复杂语义依旧是一个难点问题.
事实上,当人类在面临复杂问题时,往往先将其简化成若干个简单问题,先逐个回答简单问题,再进行整合和推理获得最终答案.因此,将复杂问题分解为若干简单问题是解决复杂问题语义理解的有效途径.同样地,我们可以借鉴这个分治的思想,先把复杂问题分解得到简单问题序列,这些简单问题往往可以直接从知识库中获取答案,再整合简单问题的信息生成查询语句,这也更符合形式语言的逻辑结构,从而更好地生成查询语句.然而,在将复杂问题分解成简单问题序列的过程中,模型往往会错误地判断或丢失问句中的主题实体,这将导致分解后的子问题与原始的复杂问题并不匹配,从而生成错误的查询语句.如图1(a)给出的错误示例,原始复杂问题的主题实体为“The Art of War”,经问句分解后得到两个简单问题,其中简单问题1错误地将“author”判断为一个地点,并且分解后的两个简单问题都丢失了主题实体,正确的分解结果如图1(b)中第1阶段所示.
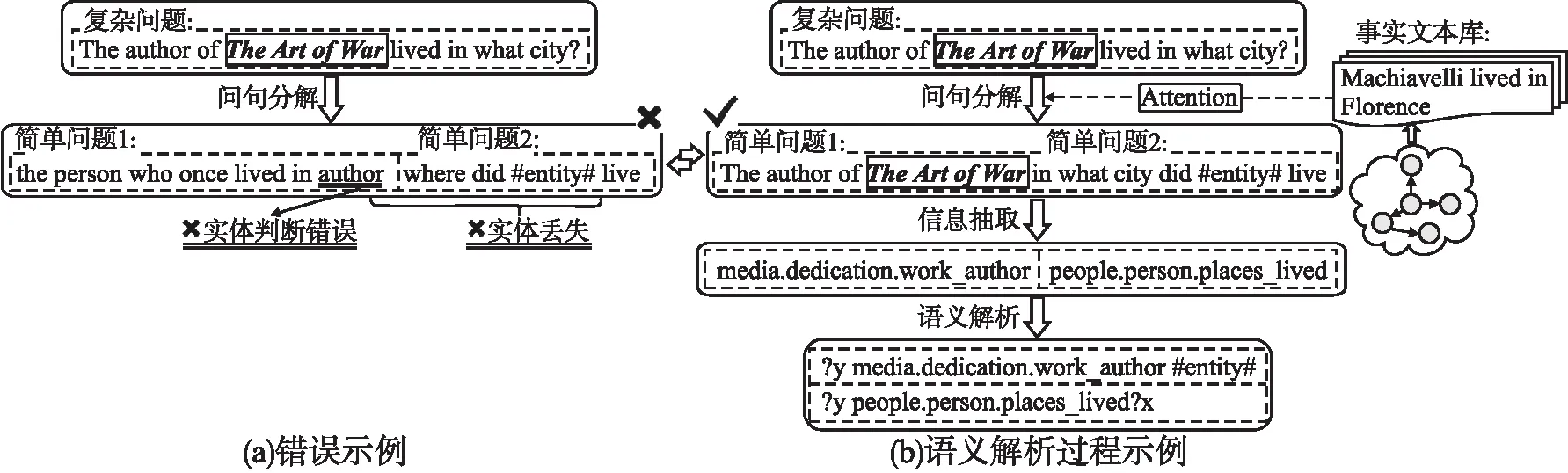
图1 示例图Fig.1 Sample graph
针对上述问题,本文提出了一种融合事实文本的问句分解式语义解析模型.我们将知识库中的三元组转化成用自然语言描述的事实文本信息,构建了一个事实文本库.并采用注意力机制获取更丰富的知识表示作为辅助信息,使生成的子问句与原问题更加切合,提高了子问句的质量,有效减少了错误传播,进而指导模型生成更好的查询语句.本文将复杂问题的语义解析过程分为3个阶段,如图1(b)所示,首先在问句分解阶段,将复杂问题分解成一系列简单的子问题序列;然后在信息抽取阶段,对原问题和子问题序列进行信息抽取和整合,获取关键信息;最后在语义解析阶段,生成相应的结构化查询语句.本文的主要贡献如下:
1)构建了一个事实文本库,将知识库中用图结构表示的事实转化成用自然语言描述的文本,使知识与问句在形式上保持一致;
2)利用文本库感知注意力机制融合了关键的事实信息,改善了主题实体残缺或错误的问题,进而提高了分解后子问题的质量,减少了错误传播;
3)提出了一种融合事实文本的问句分解式语义解析模型,借鉴分治的思想对复杂问题进行分解,使模型更好地理解复杂语义,指导模型生成更精准的查询语句;
4)在大规模公开数据集ComplexWebQuestions[9]上验证了方法的合理性和有效性.
2 相关工作
2.1 语义解析
基于语义解析的方法将自然语言描述的问句解析为逻辑形式语言,然后在知识库上执行获得答案.核心是从自然语言到逻辑形式的转换.
语义解析模型首先要充分理解一个问题,分析问句的语义和句法,将非结构化的文本转换为结构表示.与简单问题相比,复杂问题具有更复杂的查询类型和组合语义,这增加了语言分析的难度.为了提高模型的理解能力,许多现有方法依赖于句法分析,如依存句法[10,11]和抽象语义表示[12],使句子成分和逻辑要素之间做到更好的对齐.但是在具有长距离依赖的复杂问题上,句法解析的准确率较低,为了提升句法分析到下游语义解析任务的准确率,Sun[13]等人用一种骨架结构来表示复杂问题的高级结构,本质上是一个依赖语法的备选子集,以骨架结构作为粗粒度的表示来获取复杂问题的主干.而另一类方法旨在改进逻辑形式和问题之间的匹配程度,主要利用逻辑形式的结构属性(如树结构或图结构)对候选解析进行排序.Zhu[14]等人将查询视为一棵树,将实体和关系的顺序编码到其表示中,首先从实体、类型和数值运算中构造给定问题的候选查询,然后对候选查询进行编码并将其解码为给定的问题,用一种基于树的编码器-解码器结构来正确建模查询中实体或关系的上下文.Chen[15]等人将复杂的逻辑形式语法视为一个图,将查询图生成视为一个分层决策问题,先通过简单策略收集相关实例作为候选实例,然后通过槽填充分层生成查询图.但是复杂问题的类型多种多样,其逻辑形式的表达方式也非常丰富,使得模型在生成逻辑形式的过程中面临很多挑战.Lan[16]等人提出了一种迭代序列匹配模型来解析问题,为找到答案实体迭代地增加候选关系路径,逐步将匹配分数分配给路径,在回答多跳类型的问题上取得了很好的效果.为了使模型适应更多的复杂类型,Lan[17]提出了一种分段查询图生成方法,可以同时支持具有约束条件或多跳关系的复杂查询,该方法可以更灵活地生成查询图,而且还有效地缩减了搜索空间.但是上述方法更关注于问句的结构信息,没有充分利用迭代分解的思想来解决复杂知识库问答的研究难点.
2.2 问句分解
问句分解技术逐渐成为解决复杂问答的主流方法之一.通常复杂问题具有组合性或嵌套性等特征,因此可以利用其结构特征对复杂问题进行分解.Talmor[9]等人将复杂问题的分解视为一颗计算树,采用指针网络生成分割点做为计算树的结点,将原始输入切割成若干文段,每一段是一个简单问题.Shin[18]等人将复杂问题视为一个完整查询图,根据复杂问题的语法模式和依存句法树将其拆分为多个子问题,从预先定义的查询图库中搜索对应的子查询图.Guo[19]等人利用复杂问题的组合性,采用迭代语义分割的方式来增强神经语义解析器,从输入中分割一个跨度并将其解析为部分表示,并将这一过程进行迭代.此类方法的优势是不需要任何手工模板或额外标注数据来进行语义分割,但得到的子问题往往是不完整的,因此丢失了很多关键的有效信息.为了使模型在训练过程中能够利用更多的知识信息,He[20]等人结合了实体信息和领域知识信息,用序列标注的方式准确地识别实体和相关属性信息,将简单子问题集合起来实现复杂问题的自动分解.Das[21]等人提出了一种基于案例推理的知识库问答方法,通过检索的方式从训练集中检索相关案例,利用其标注信息和结构信息,进一步将复杂问题转化成若干简单问题的表示.此类方法在问题分解时得到了完整的子问题,具备更强的可解释性,能够获得更丰富的知识信息,但模型遇到新的复杂问题时泛化能力较差.Perez[22]等人采用无监督的方法来生成子问题,提出了一种一对多的无监督序列转导算法,将一个困难的多跳问题映射到若干更简单的单跳子问题.Zhang[23]等人则采用端到端的序列生成模型,将分解任务转化成生成任务,在Embedding层将复杂问题分解成若干简单问题,直接生成完整的子问题,并且能够适应4种主流的复杂类型.Zhang[24]等人则进一步优化了子问题的回答顺序,提出了一种强化学习的方法,动态地决定在每个推理阶段回答哪个子问题.但此类生成式的方法在分解阶段不可避免的会产生很多错误,导致子问题与原始复杂问题并不匹配,为后续的任务带来错误积累.
3 任务定义
本文对知识库问答技术的研究基于语义解析的方法,即对于一个给定的复杂问题q={w1,…,w|q|}(wi(1≤i≤|q|)表示问句中的词),将其转化为逻辑形式lf={w1…,w|lf|}(wi(1≤i≤|lf|)表示查询语句中的词).
为了使模型能理解和回答复杂问题,借鉴分治的思想:1)问句分解模块将复杂问题分解成若干简单子问题dq={w1,…,w|dq|}(wi(1≤i≤|dq|)表示子问题中的词);2)信息抽取模块会抽取原始复杂问题和子问题序列中的有效信息ei={w1,…,w|ei|}(wi(1≤i≤|ei|)表示抽取的信息中的词),包括问题类型和谓词信息等;3)语义解析模块会整合前两阶段的信息生成相应的SPARQL语句.
同时,为了解决上述步骤中存在的错误积累问题,在每一阶段都融入外部知识.首先将知识库K={V,R}(其中V代表实体集合,R代表关系集合)中与主题实体相关的三元组(vs,r,vo)∈K(其中vs,vo∈V,r∈R) 根据模板转换成事实文本信息ft={w1,…,w|ft|}(wi(1≤i≤|ft|)表示事实文本句中的词).然后计算它们与原始复杂问题之间的语义相似度,选取top-n的句子作为外部知识.最后采用注意力机制更新各阶段的特征向量,融入外部信息.
每个训练样本都是一个五元组(q,lf,dq,ei,F),其中F=(ft1,…,ftn)为这一复杂问题对应的事实文本集合,包含n个事实文本句子.
4 模 型
4.1 模型总览
针对上述分治思想和错误积累问题,本文提出了融合事实文本的问句分解式语义解析模型,整体结构如图2所示,主要包括4个部分:事实文本库、问句分解模块、信息抽取模块和语义解析模块.其中,问句分解模块、信息抽取模块和语义解析模块都是基于Transformer[25]的编码器-解码器框架,在Transformer的基础上利用文本库感知注意力机制融入事实文本信息.其输入是由输入序列i=(i1,…,ii)和附加信息e=(e1,…,ee)两部分组成,输出是目标序列o=(o1,…,oo),事实文本集合是F=(ft1,…,ftn).

图2 模型整体结构示意图Fig.2 Overall structure of the model
4.2 事实文本库
本文构建了一个事实文本库作为知识来源.在知识库中,信息以三元组的形式存在,包括头实体、关系和尾实体,通过<头实体,关系,尾实体>这样的结构构建了一张图网络.但是不同的知识图谱中三元组的表述形式也不相同,为了将知识库的信息与自然语言的问题在形式上保持一致,方便后续的序列建模,本文将三元组通过人工设计模版转化成用自然语言描述的句子.
在数据预处理时,首先用斯坦福的命名实体识别工具(1)https://nlp.stanford.edu/software/CRF-NER.html识别出问句中的实体,得到一个实体集合,以该集合中的实体作为头实体或尾实体抽取知识库(2)本文在Freebase知识库上进行抽取.中的三元组.然后根据人工设计模板将三元组表示为事实文本(如5.2节所示).最后利用BERT[26]将问句和事实文本编码成向量,计算问句和事实文本之间的余弦相似度,选取top-n的事实文本句子构建事实文本库.
4.3 文本库感知注意力机制
为获取更丰富的知识信息,在编码端和解码端都利用了文本库感知注意力机制动态地关注输入序列中的局部信息,让模型在面对当前输入序列时更专注于与事实文本相关联的实体信息或关系信息,有效地缓解了主题实体残缺或错误的问题,减少了错误传播.如图3所示,为基于文本库感知注意力机制的编码器-解码器结构示意图.
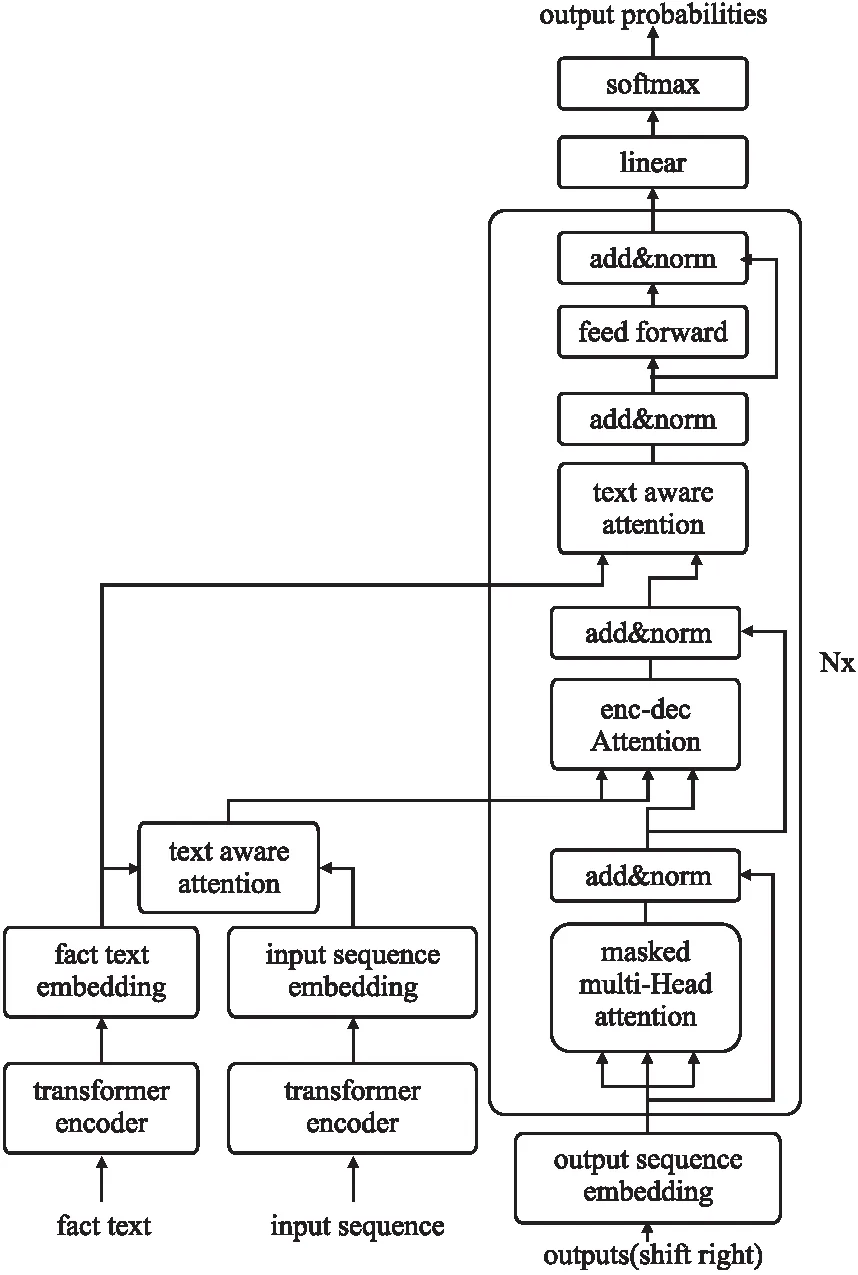
图3 基于文本库感知注意力机制的编码器-解码器结构Fig.3 Encoder-decoder architecture based on text base-aware attention mechanism
在编码端,首先使用Transformer的编码器对输入序列i=(i1,…,ii)进行编码得到向量表示hi,对事实文本集合F=(ft1,…,ftn)中每个事实文本序列进行编码得到向量集合(hft1,…,hftn)并将其进行拼接,拼接后的向量为hF,然后经过文本库感知注意力机制,计算输入序列对事实文本序列的注意力向量为h.整个过程表示为:
hi=fenc(i)
(1)
hft=fenc(ft)
(2)
hF=hft1⊕…⊕hftn
(3)
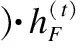
(4)
其中,fenc(·)代表Transformer编码器的编码过程.
在解码端,Transformer解码器的主要由Masked Multi-Head Attention和Encoder-Decoder Attention两大机制组成.本文在解码端主要做了两处改进:1)在Encoder-Decoder Attention处,用注意力向量h取代原来的输入序列向量hi作为编码器传递到解码器的隐向量,即K=V=h,Q=hV;2)在解码器中新增了文本库感知注意力机制,输入是事实文本序列的特征向量hF和Encoder-Decoder Attention输出的向量henc-dec,输出是注意力向量ht-aware.解码过程遇到“[BOS]”标签代表解码开始,遇到“[EOS]”标签代表解码结束.
整个过程表示为:
(5)
henc-dec=Attention(hF,henc-dec)
(6)
综上,本文使用了基于文本库感知注意力机制的编解码框架,在后续论述中用fenc(·)表示模型的编码过程,fdec(·)表示模型的解码过程.
4.4 问句分解模块
该模块的学习目标是把复杂问题分解成简单子问题序列.输入为复杂问题q,事实文本集合为F,输出为分解后的子问题序列dq.首先在编码端,对输入问题q进行编码得到问题嵌入hi=fenc1(q),对事实文本F进行编码后拼接得到事实文本嵌入hF=fenc1(F),经过文本库感知注意力机制得到一个注意力向量h=Attention(hi,hF).然后在解码端,接收注意力向量h,并通过文本库感知注意力机制预测分解的表示dq=fdec1(h).在每个时间步,先前的输出右移并送入解码器.
4.5 信息抽取模块
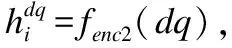
4.6 语义解析模块
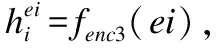
4.7 损失函数
本文的训练目标是生成简单子问题序列,抽取关键谓词和实体信息,最终生成相应的查询语句.设计的联合训练损失函数如下,分别由3个阶段的损失函数l1,l2和l3组成:
L(θ)=λ1l1+λ2l2+l3
(7)
其中,3个阶段的任务都使用生成式模型的损失函数:
P(x)=softmax(Wx+b)
(8)
(9)
5 实验及分析
5.1 数据集
本文在大规模复杂问题数据集ComplexWebQuestions(version1.0)[9]上进行了实验.该数据集包含27734训练样本、3480验证样本和3475测试样本.每个样本都包含复杂问题、分解的子问题序列、SPARQL格式的结构化查询语句.该数据集有4种复杂类型:组合问题(46.7%)、聚合问题(42.4%)、最高级问题(5.3%)和比较级问题(5.6%).
5.2 事实文本库模版
根据Freebase的数据格式,三元组包含头实体,谓词关系和尾实体,其中谓词关系为三段式,如“people.person.places_lived”.通过分析该特征,本文只保留谓词关系的第3段,设计了通用模版为“头实体+谓词关系+is+尾实体”生成一句事实文本,如表1所示.

表1 事实文本库的生成模版Table 1 Generating Template for Factual Text Database
5.3 实验设置
本文的语料库由复杂问题、所有的中间表示、SPARQL查询语句和事实文本构成,构造词表时是由语料库中词频大于3的所有单词构成.本文使用预训练的词嵌入GloVe[27],维度为300维.对于没有预训练的词嵌入(包括UNK、BOS和EOS)使用随机初始化.本文所有的编码器和解码器都是由6个相同层堆叠起来的,隐向量为300维.使用Adam优化器,β1=0.9,β2=0.98,ε=10-9.学习率在训练过程中动态调整.Dropout[28]设置为0.2.标签平滑率设置为0.1.在训练过程中,batchsize=64,训练步长为40000.每1200步验证一次,验证过程的batchsize=160.训练结束后,采用beam size=16的束搜索策略生成SPARQL语句.
5.4 基线模型
为了验证融合事实文本的问句分解式语义解析方法的有效性和优越性,选取了7个当前主流的方法作为基线模型进行对比实验.
1)PointerGenerator[29]使用了序列到序列的模型,第1次将语义解析任务视为以自然语言作为源语言,其逻辑形式作为目标语言的翻译任务.主要是利用数据重组的框架将先验知识注入序列到序列的模型中,并且使用了一种基于注意力的复制机制.
2)Transformer同样采用序列到序列的模型,抛弃了传统的RNN和LSTM,整个网络结构完全由注意力机制组成,运用在很多的自然语言处理任务上都取得了更好的成绩.本文主要利用Transformer在ComplexWebQuestions数据集上做语义解析任务.
3)Coarse2Fine[30]提出一个结构感知的神经架构,采用由粗到细的两阶段生成方法,先生成忽略细节的表示,再将细节填充到之前的表示中.将语义解析任务分步骤进行,比一步生成目标序列的方法准确率更高.
4)PointerNetwork[9]主要针对复杂问题提出了一个基于问题分解和与Web交互的框架,主要通过指针网络生成分割点,直接切分原始复杂问题,得到一系列简单问题片段.
5)SPARQA[13]用一种骨架结构来表示复杂问题的主干,采用基于BERT的解析算法的粗粒度表示,还采用了一种多策略的方法结合句子级和单词级语义.
6)PDE[19]提出了一个迭代分解的框架,该框架在两个神经模块之间迭代:一个是从问句中分解跨度的分解器,另一个是将跨度映射为局部意义表征的解析器.
7)HSP[23]主要针对复杂问题提出基于序列到序列模型的层次语义解析方法,主要利用复杂问题的分解性为复杂问题直接生成完整的子问题,将语义解析任务转化为多层次的生成任务,在ComplexWebQuestions数据集上的实验效果显著提高.
5.5 实验结果
本文对模型在语义解析任务和问题分解任务中的实验结果都进行了相应的对比实验和消融实验.下面将介绍本文的方法在两大任务中的性能表现,并且直观地给出了相应的实例分析.
5.5.1 语义解析任务的对比实验和消融实验
本文提出的方法是针对复杂问题的语义解析任务,模型的目标是将自然语言描述的复杂问题最终解析为逻辑形式,即SPARQL格式的结构化查询语句.因此语义解析任务的实验效果是验证该方法有效性的重要指标.在该任务中,选取PointerGenerator、Transformer、Coarse2Fine、SPARQA和HSP作为基线模型在验证集和测试集上进行了对比实验.评价指标为EM值,即模型生成SPARQL语句的正确率.实验结果如表2所示.
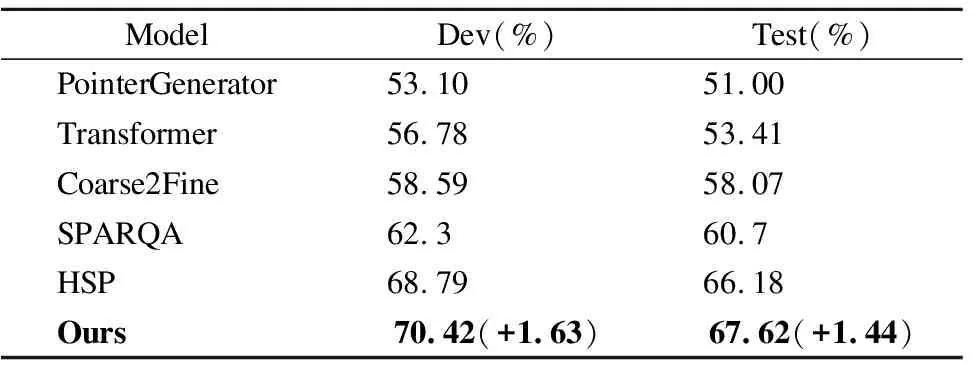
表2 语义解析任务的对比实验结果Table 2 Comparative experimental results on semantic parsing
通过分析表中数据可以得出以下3点结论:
1)Transformer在测试集上的准确率为53.41%,比PointerGenerator高2.41%.这组实验证明,对于传统的序列到序列模型来说,在ComplexWebQuestions数据集上做语义解析任务是比较困难的.因此针对复杂问题的语义解析任务本身是存在难度的.
2)HSP在测试集上的准确率为66.18%,比Coarse2Fine高8.11%,比SPARQA高5.48%,性能得到很大提升.这组实验证明,与其他的神经语义解析模型相比,HSP的性能提升显著.说明将复杂问题分解成简单问题,采用分治的思想可以简化模型在每个阶段的表示学习,同时通过信息整合可以帮助模型更好的生成结构化查询语句.
3)本文的方法在测试集上的准确率为67.62%,比HSP高1.44%.这组实验证明,本文提出的文本库感知注意力机制能够将知识库中的事实文本信息融入模型的学习过程,使模型在生成任务中获得更高的准确率.
为了验证文本库感知注意力机制对语义解析任务的作用,本文做了相应的消融实验.实验设置如表3所示:完全剔除文本库感知注意力机制,只剔除编码端的文本库感知注意力机制,只剔除解码端的文本库感知注意力机制,完全保留文本库感知注意力机制.实验结果表明,在语义解析任务中融入文本库感知注意力机制是有效的.分析数据可知,融入的事实信息越多实验效果越好,说明高质量的外部知识能够减少生成模型的误差,使结果更精确.
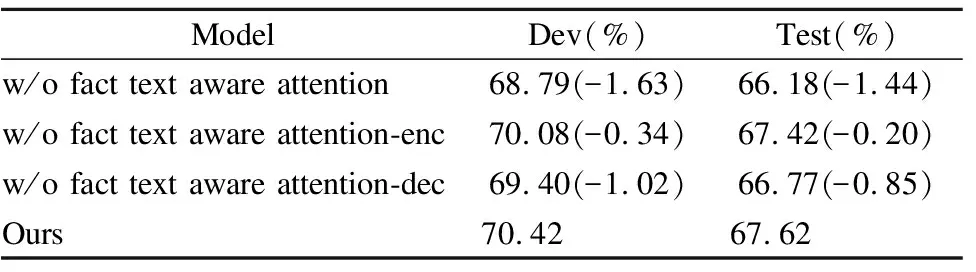
表3 语义解析任务的消融实验结果Table 3 Ablation experimental results on semantic parsing
5.5.2 问题分解任务的对比实验和消融实验
本文提出的方法旨在缓解问题分解过程中的错误积累问题,减少实体误判和丢失的情况,为后续的语义解析任务提供保障.因此提升问题分解任务的实验效果是十分必要的,能够充分验证分治思想的有效性.在该任务中,选取PointerNetwork、PointerGenerator、PDE和HSP作为基线模型在验证集和测试集上进行了对比实验.评价指标为 Bleu-4[31]和Rouge-L[32]得分.对于所有模型,输入是复杂问题,输出是分解的子问题序列.实验结果如表4所示.
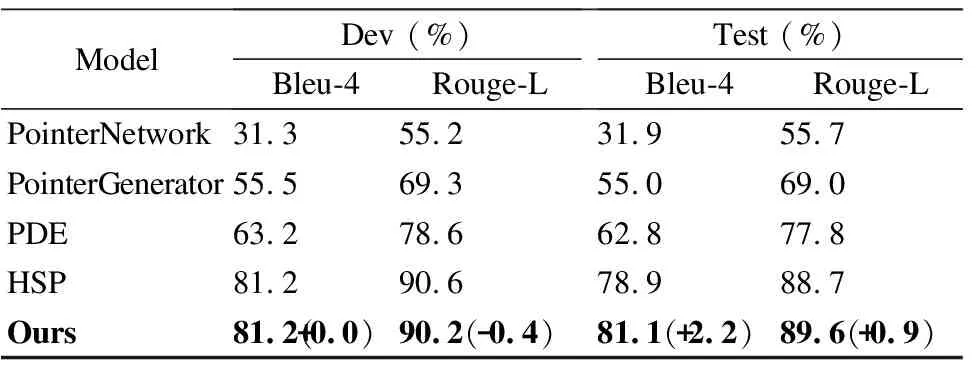
表4 问题分解任务的对比实验结果Table 4 Experimental results on question decomposition
通过分析表中数据可以得出以下3点结论:
1)与PointerNetwork 相比,其他3个模型的实验结果更好,说明对于问题分解任务,相比利用直接切分的思想在问题中寻找分割点的方法,采用神经生成问题的方法更有效.
2)PDE和HSP与其他两个模型相比性能提升显著.说明将复杂问题分解成简单问题的思想能够指导模型更好的理解复杂语义.而相比之下,HSP的方法在性能上仍大幅优于PDE的方法,说明生成完整的子问题能够有效减少片段式的子问题所丢失的关键信息.
3)本文的方法与HSP相比,在测试集上Bleu-4值提升了2.2,Rouge-L值提升了0.9.说明在分解任务中,融入事实文本信息能够使模型获取更丰富的知识表示,有效减少错误传播.
为了验证文本库感知注意力机制对问题分解任务的作用,本文做了相应的消融实验.实验设置如表5所示,完全剔除文本库感知注意力机制,只剔除编码端的文本库感知注意力机制,只剔除解码端的文本库感知注意力机制,完全保留文本库感知注意力机制.实验结果表明,在问题分解任务中融入文本库感知注意力机制可以有效提升分解的准确率和子问题的连续性.分析数据表明,融入事实文本可以使模型更关注问句的局部信息,有助于理解复杂问题的深层语义.
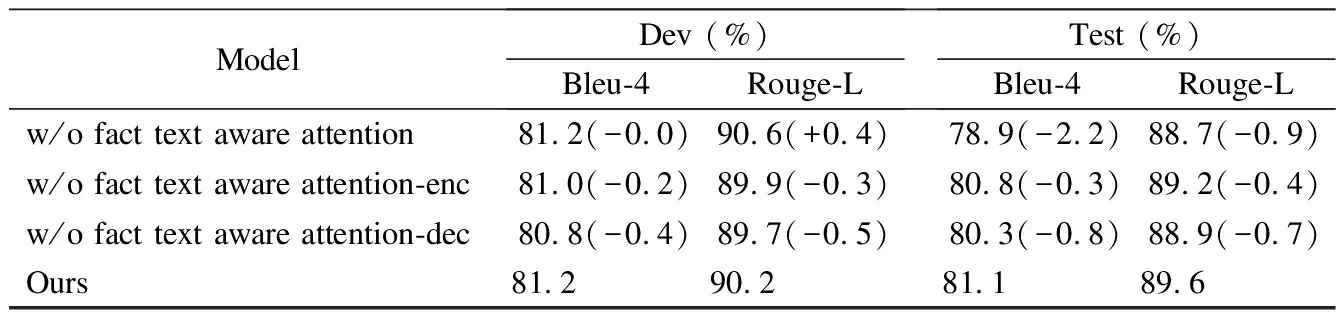
表5 问题分解任务的消融实验结果Table 5 Ablation experimental results on question decomposition
5.6 实例分析
为了直观的对实验结果进行分析和对比,使本文的方法具备更高的可解释性,此节将结合测试集中的一个实例来分析模型在每个阶段的实验效果,选取性能较好的HSP作为基线模型,验证以上实验结果的准确性.
比如输入一个复杂问题“The author of The Art of War lived in what city?”,主题实体为“The Art of War”.基线模型HSP在经过每个模块后,输出的序列如表6所示.当输入的复杂问题经过问题分解模块后,分解成两个简单子问题序列,使用“[#]”作为分割符,通常第2个子问题会包含第1个子问题的答案实体,使用“[#entity#]”作为占位符.接下来,信息抽取模块将抽取原始复杂问题和简单子问题的关键信息,包括复杂类型和谓词信息,使用“[#]”作为分割符.最后,语义解析模块生成对应的逻辑形式,使用“[.]”作为分隔符,使用“[#entity#]”作为占位符.

表6 基线模型HSP的输出序列Table 6 Output sequence of baseline model HSP
对表6中的实例进行分析,可知基线模型HSP中问题分解模块的输出序列是错误的.实现结果表明,问题分解阶段的Bleu-4值为0.35×10-4,Rouge-L值为0.46.因为第一个子问题将“author”解析成一个居住地点,且两个子问题中都不包含主题实体“The Art of War”,导致后续信息抽取和语义解析模块的输出序列仍然是错误的.实验结果表明,语义解析阶段的Bleu-4值为0.43×10-3,Rouge-L值为0.54.
所以,本文的方法将融入事实文本信息以缓解实体识别错误和实体丢失的现象.仍以该复杂问题为例,融入的事实文本如表7所示.这些文本信息虽然在语法上并不符合规范,但却极大程度的保留了三元组的事实信息.

表7 融入的事实文本序列Table 7 Incorporated factual text sequence
因此,本文的模型在经过每个模块后,输出的序列如表8所示.可以看出,问题分解模块的输出序列已经被矫正,一定程度上缓解了错误积累的问题.实验结果表明,问题分解阶段和语义解析阶段的的Bleu-4值均为1,Rouge-L值均为1.由此验证了本文方法的优越性和准确性.

表8 本文模型的输出序列Table 8 Output sequence of our model
5.7 错误分析
本文针对语义解析任务和问题分解任务的实验结果进行了错误分析,分别从任务对应的输出序列中随机挑选了Bleu-4值和Rouge-L值均低于0.3的100条样例.本文的方法仍有需要改进的地方,总结如下:
1)当面对最高级问题(5.3%)和比较级问题(5.6%),模型的处理能力较弱,在问题分解时无法获得子问题之间正确的逻辑关系,在语义解析时无法生成正确的运算符号.比如一个最高级问题”What tourist attraction in Miami Florida that was first opened on 2008-06-06?”,要回答这个问题首先需要枚举出所有的旅游景点及它们的开放时间,再进行数值运算或逻辑运算.而本文的方法注重于外部知识辅助,缺少人工设计规则来学习这类问题.
2)本文在构造事实文本库时需要从知识库中抽取相关的三元组,在这一过程中发现知识库中有少量的实体或关系存在缺失的现象,知识库的不完整性会影响构造的事实文本库的质量.而大型的知识图谱往往都会存在不完整性的问题,为知识库问答的研究工作带来了挑战.
6 总 结
本文提出了融合事实文本的问句分解式语义解析模型,实现了对复杂问题采用分治的方法进行回答,构建了一个事实文本库作为外部知识指导模型学习更丰富的知识信息,在语义解析的过程中兼顾了实体的完整性,降低了错误积累带来的负面影响,增强了模型对复杂语义的理解能力.实验结果表明本文的方法在ComplexWebQuestions数据集上取得了更好的性能.未来,我们将针对错误分析中的难点问题探索性能更优的应对方法,进一步提升知识库问答的性能.
猜你喜欢
中学生数理化·高一版(2021年4期)2021-07-19
开放教育研究(2020年2期)2020-03-31
制造技术与机床(2019年6期)2019-06-25
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
摄影之友(影像视觉)(2016年2期)2016-08-16
中国交通信息化(2016年9期)2016-06-06
现代语文(2016年21期)2016-05-25
图书馆研究(2015年5期)2015-12-07
大连民族大学学报(2015年2期)2015-02-27
