
中医电子病历入院记录信息自动抽取方法研究*
2023-09-01 12:23李灿,解丹
世界科学技术-中医药现代化 2023年5期
李 灿,解 丹
(湖北中医药大学信息工程学院 武汉 430065)
中医电子病历记录了中医诊疗的全过程,蕴藏着丰富的中医学知识。中医电子病历入院记录中主诉、刻下症等当前状态信息与病人现病史、既往病史等病史类信息均是中医四诊诊断的重要依据。其中,刻下症即现症,现在时刻患者四诊所获资料,是中医电子病历特有的部分,存在大量的症状描述,有一词多义、同名异义、异名同义等现象。现病史是指患者本次疾病的发生、演变、诊疗等方面的详细情况[1]。现病史具有叙事性强、口语化重、句子长等特点[2]。此外,疾病名称、检查、药物、时间、机构、科室等内容也存在表达不规范的情况[3]。因此,中医电子病历入院记录信息的不规范导致人工识别的成本很高,为后期电子病历信息的深度应用带来了巨大阻碍。
为节省人力,研究者广泛采用信息抽取技术来实现电子病历的自动识别任务,将电子病历中的信息进行规范化和结构化。目前,对电子病历信息的抽取主要是对症状信息进行识别。袁玉虎等[4]抽取出了中医病历现病史中的症状信息。原旎等[5]应用深度表示的方法实现临床上的现病史数据中的症状术语的抽取。但是电子病历中除了症状信息外,还有疾病、检查、药物等信息,这些对中医诊断也起着重要参考作用。为此,本文利用事件抽取和命名实体识别技术,提出了一种针对中医电子病历入院记录信息的自动抽取方法。依据已有标准和经典文献,构建蕴含多种属性的实体语料库,通过比较实验从多个主流模型中选取最适用于本研究的抽取模型,实现中医电子病历入院记录信息的自动识别与规范化存储。
1 相关研究
信息抽取通常包括命名实体识别、关系抽取、事件抽取3 个核心任务:①命名实体识别(Named entities recognition,NER)的目标是从大量的数据中找出相关的命名实体,并将它们分离出来,在文本中标注这些信息[6]。随着深度学习的兴起,双向长短期记忆网络(BiLSTM)、膨胀卷积(IDCNN)、BERT 预训练模型等深度学习模型逐渐应用于医疗实体的识别。高佳奕等[7]利用CRF 模型实现了中医临床医案症状的命名实体抽取。肖瑞等[8]通过BiLSTM-CRF 方法实现了对中医医案文本进行命名实体识别。陈琛等[9]采用BERTBiLSTM-CRF 方法识别电子病历中的解剖部位、疾病等命名实体。②关系抽取(Relation extraction,RE)目标是从无结构文本中提取出已知实体对的语义关系[10]。它可用于抽取出医疗实体之间的关系。武小平等[11]提出了BERT-CNN 抽取出了心血管医疗指南中医疗实体之间的关系。张玉坤等[12]基于联合神经网络模型抽取出了中文医疗实体之间的治疗、上下位等关系。由于电子病历中不仅含有医疗实体、实体之间存在某种关系,也存在着诊疗事件,研究者开始抽取电子病历中的诊疗事件。③事件抽取(Event extraction,EE)是从自然语言中提取出使用者感兴趣的事件,并将其作为一种结构化的表达手段[13]。侯伟涛等[14]在BiLSTM 模型的基础上,提取了医学事件并进行了属性识别。余杰等[15]提出了联合抽取的方法,实现了医疗事件的联合抽取。刘子晴[16]提出了一个面向中医门诊电子病历信息抽取的通用框架,以临床表现和临床事件为切入点,不仅抽取了症状、疾病名等实体,还抽取了肿瘤、手术、疗效等其他临床事件。
本文以中医电子病历入院记录中的刻下症与现病史为例分别展开信息自动抽取研究。如表1所示为湖北省某中医院内科臌胀病及河南省某中医院骨伤科电子病历入院记录的刻下症和现病史原始文本,两个文本描述的内容大体相差不大。其中,刻下症中包含了症状、舌象、脉象等中医术语,文本较短,仅对其进行命名实体识别(本文不考虑舌象、脉象);现病史文本较长,均由多个诊疗事件组成,考虑首先将现病史以诊疗事件为单位拆分成短句,然后再对诊疗事件进行命名实体识别。由于本文不必分析医疗实体之间的关系因此不考虑关系抽取。

表1 不同医疗机构的电子病历现病史原始信息
2 研究方法
2.1 方法介绍
2.1.1 事件抽取
常见的事件抽取方法有2 种:①基于模式匹配算法:事件的提取是由人工或自动生成的,由人工或自动生成的特征格式表示的,通常被称作模式匹配;②触发词法:触发词法也被叫作事件关键词法。在统计处理事件句的过程中,有一类事件句在语句中的出现频率较高,通常指的是在语句中存在特定的术语或者词汇。所以,可以通过建立一个事件触发词字典来使事件提取更加有效[17]。本文通过分析现病史句子的特征,确定触发词,随后抽取出现病史的诊疗事件。
本文通过分析现病史的原始文本,首先将中医电子病历中的诊疗事件分为患者症状、疾病诊断、入院入科、检验检查、手术情况、药物治疗及非药物治疗7种子事件,如表2 所示。以上划分的7 种子事件中至少含有一个即可定义为一次诊疗事件,几种子事件组合起来也可以成为一次诊疗事件。
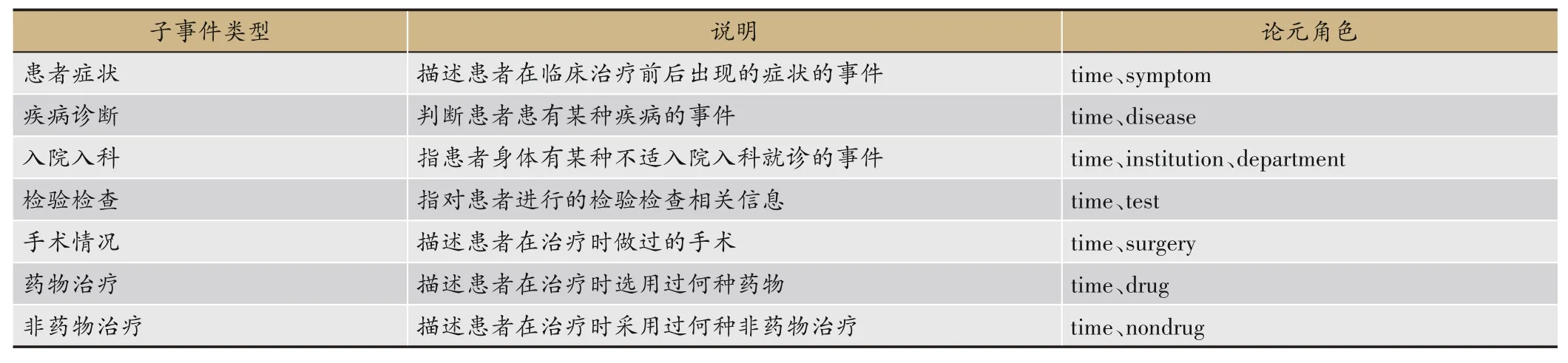
表2 诊疗事件子类型及其说明
无论是诊疗事件还是其子事件都由多个事件论元组成,事件论元是指事件所涉及的使用者所关心的语义对象,一般指一个名词,而论元则是事件的参与者[18],可以理解为本文的实体类型。本文定义了9 种论元角色类型,分别为时间(Time)、症状(Symptom)、疾病(Disease)、机构(Institution)、科室(Department)、检查(Test)、手术(Surgery)、药物(Drug)、非药物(Nondrug)。
2.1.2 命名实体识别
常用命名实体识别模型有BiLSTM-CRF、IDCNNCRF、BERT-IDCNN-CRF、与BERT-BiLSTM-CRF 模型等。
①BiLSTM-CRF 模型:该模型融合了双向长短期记忆模型(BiLSTM)和条件随机场模型(CRF),结合词语的上下文有关信息,将词的分布式表达引入到特征提取中,最大程度地利用词与标签之间的关系,从而提高识别效果[19]。
②IDCNN-CRF 模型:该模型将扩展卷积神经网络与条件随机场模型相结合,在卷积核中添加扩展距离,并将4个相同尺寸的扩展卷积块进行叠加,然后把语句输入IDCNN,通过卷积层抽取特征,然后通过映射层与CRF 层相连。神经网络中包含多个膨胀卷积块,可利用GPU的并行性以提升训练速度[20]。
③BERT-IDCNN-CRF 模型:它包括BERT 层、IDCNN 层、CRF 层。BERT 层是对文本进行关联提取的向量,IDCNN 层用于提取特征,CRF 层用于阻止标记序列的非法标记,从而获得最大概率的标记[21]。
④BERT-BiLSTM-CRF 模型:该模型通过BERT模型构建字向量在进行特征提取之前引入了注意力机制,并且通过语料库进行字向量的构建,可以提高特征不明显、组成复杂的实体识别的准确性[22]。
2.2 方法流程
本文构建了中医电子病历入院记录信息抽取的规范化流程,如图1 所示。整个流程分为以下5 个阶段:①数据获取及预处理:从中医电子病历中获取入院记录信息,以刻下症和现病史信息为研究对象对其进行数据预处理工作,然后构建中医电子病历实体语料库;②识别模型遴选:从常用信息抽取模型中遴选出适合本研究的信息抽取模型;③事件抽取:根据触发词将现病史中的诊疗事件抽取出来;④实体抽取:结合中医电子病历实体语料库,利用识别模型分别识别刻下症及现病史诊疗事件中的医学实体并抽取出来;⑤数据存储:将抽取出来的各类实体存储至数据库中。
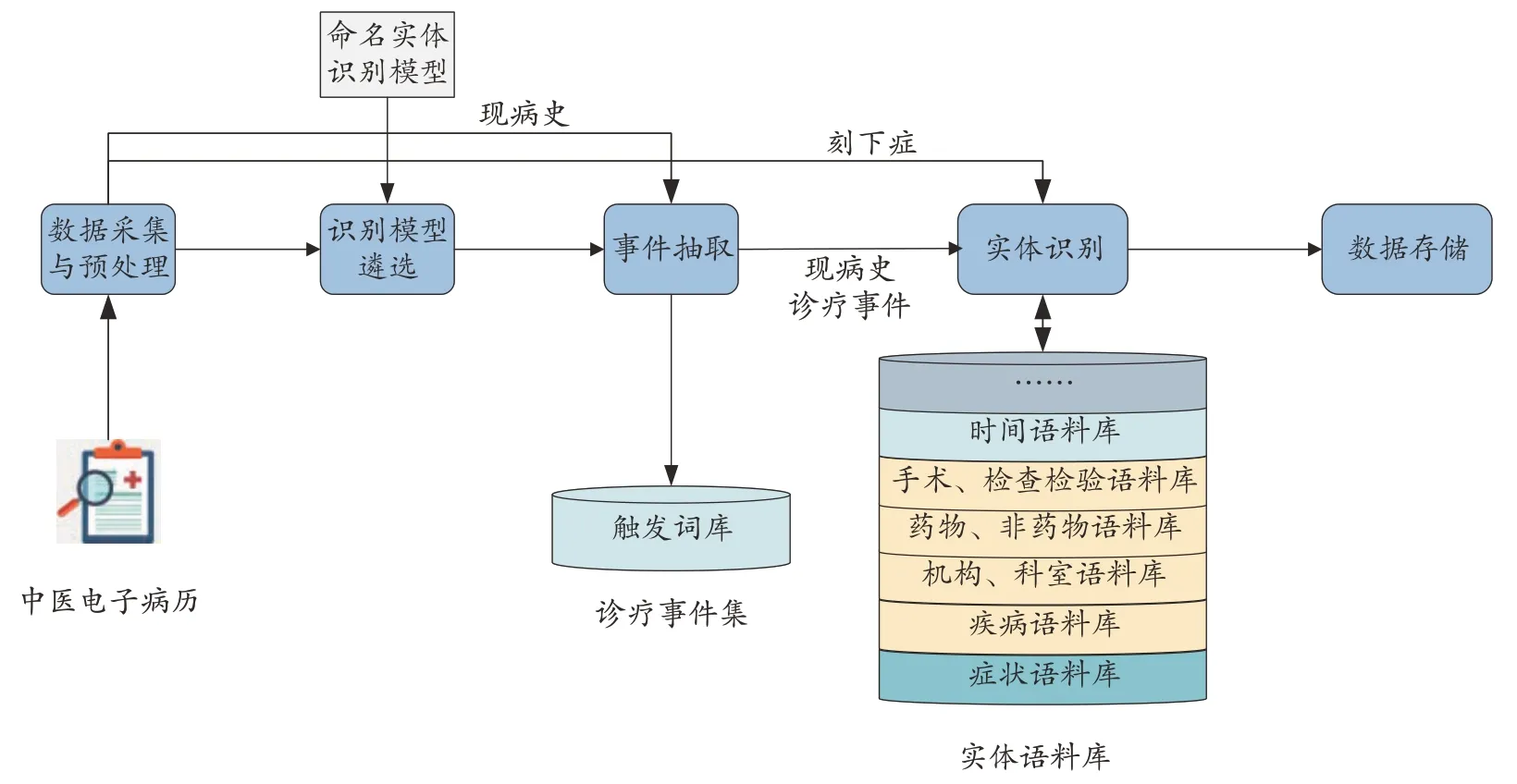
图1 中医电子病历入院记录信息自动抽取规范化流程示意图
2.3 评估指标
在本文实验中,用到的模型性能评估指标包括:精确率(Precision)、召回率(Recall)和F1 值。其中,TP为模型正确识别出的实体数,FP为模型识别出的其他类实体数,FN 为模型未识别出的其他类实体数[23]。具体公式如下:
3 实验过程与结果
3.1 数据获取及预处理
3.1.1 数据来源
选取2018 年河南省某中医院骨伤科的767 份电子病历的入院记录作为本研究的数据基础。选择其中的刻下症与现病史作为研究对象。
3.1.2 数据预处理
通过去掉重复电子病历、删除缺失值、去掉多余空格等操作对其进行“数据清洗”等预处理工作后还剩563份数据。
3.1.3 语料库构建
语料库的构建质量高低能够决定实体识别模型训练的识别率的高低,而现病史中几乎覆盖了所有的临床诊疗事件,因此本文根据真实世界中医电子病历,构建了与上述9种论元相对应的时间、症状、疾病、机构、科室、检查、手术、药物、非药物共9 种实体语料库,作为模型训练的基础,症状语料库是其中最为重要的一环。
(1)症状实体语料库
由于不同专科专病的症状属性存在较大差异,为了更有效地识别出各种症状实体,将症状实体语料库分为中医临床基础症状语料库和专科专病症状语料库。其中中医临床基础症状语料库主要源于《中医药学名词:内科学·妇科学·儿科学(2010)》[24],其收纳了中医专科专病的骨科加外科诊断术语1109条,诊断术语中包含有疾病名称、证型以及症状等信息。再利用《中医临床基本症状信息分类与代码》[25]对其中的症状进行标注,给出骨干症状、获取方式以及人体部位、性质等多个属性。例如对于诊断“骨性关节炎”标注后的形式为“关节软骨进行性退变,骨质增生,以{symptom:疼痛-问疼痛;<A:关节>疼痛}、肿胀、局部压痛、{symptom:四肢不用-问不适;活动受限}为主要临床表现的疾病。”其中,用“symptom”表示症状实体,在“-”前后分别是症状必要类目属性“骨干症状”与“获取方式”,在“;”后是症状实体描述,“<>”是对症状属性的描述,Xie等[26]对标注过程进行了详细描述。由于专科专病的症状属性存在较大差异,为了更好地识别专科电子病历中的信息,还需构建专科专病语料库。选取去重后的563 份电子病历中的30%条(169 条)进行标注,构建骨伤专科专病症状语料库。完善后的语料库包含之前的1109 条和专科专病169 条,共计1278条症状诊断术语。
(2)疾病实体语料库
疾病名称参考《ICD-10/11》构建疾病实体语料库。将《ICD-10/11》中骨科常见疾病名称纳入疾病实体语料库。例如疾病名称“骨关节炎”标注后为“{disease:骨关节炎}”。构建的疾病实体语料库包含510个疾病实体。
(3)机构、科室实体语料库
由于实证研究中选取的电子病历来源于河南省某中医院,因此这里选取河南省统计局和河南省卫生健康委员会中发布的各级医疗机构名称构建机构语料库。例如“偃师市中医院”标注后为“{institution:偃师市中医院}”。根据国家发布的《医疗机构诊疗科目名录》构建科室语料库,例如“骨科”标注后为“{department:骨科}”。构建的机构、科室语料库分别包含1337个机构实体和34个科室实体。
(4)检查、手术实体语料库
对于现病史中出现的检查、手术等信息,从国家发布的《手术分类与代码》标准(《ICD-9-CM3》)中选取骨科相关手术,以及搜狗词库中骨科常见检查的种类,加上电子病历标注数据中包含的骨科常见手术名称和检查种类,共同构建检查检验、手术实体语料库。例如“椎体成形术”标注后为“{surgery:椎体成形术}”,“腰椎磁共振”标注后为“{test:腰椎磁共振}”。构建的检查、手术实体语料库分别包含25个骨科常见检查实体和26个手术实体。
(5)药物、非药物实体语料库
由于实验中选取的是骨伤科电子病历,为了更好地识别骨科药物,选取了开源平台:搜狗词库,其中包含了骨科常用药,同时从电子病历已标注数据中获取得到骨科用药及非药物治疗,共同构建药物和非药物实体语料库。例如“骨化三醇软胶囊”标注后为“{drug:骨化三醇软胶囊}”,“ 针灸”标注后为“{nondrug:针灸}”。构建的药物、非药物实体语料库分别包含105个骨科常用药物实体和11个非药物实体。
(6)时间实体语料库
在现病史中会出现各类有关时间的描述,多为相对时间和绝对时间。相对时间:例如“前2 天,1 个月后”等;绝对时间:例如“2021 年1 月10 日,4 月22 日”等。为此,将时间实体分为简单时间表达式、复合时间短语及时间介词短语,简单时间分为日历型时间(Date)、具体时间(Time)、时间词(TimeN)、段时间(TimeD)及周或星期时间(TimeSet)[27]。例如日历型时间“2012-06-14”标注后为“{Date:2012-06-14}”;时间词“前天”标注后为“{TimeN:前天}”;复合时间短语“3 月9 日8 点30 分”标注后为“{Date+Time:3 月9 日8点30 分}”;时间介词短语“1 年前”标注后为“{TimeD+TimeLN:1年前}”。构建的时间实体语料库包含26个时间实体。
3.2 识别模型遴选
由于症状实体的识别最为复杂,因此选取1109条骨科加外科的病证诊断术语作为遴选识别模型的训练数据。合适的参数设置会在模型训练时获得较高的识别率[28]。因此本文通过修改的参数包括学习率(Learning rate)、批样本数量(Batch-size)和迭代次数(Epoch)的值选出一个最适合现病史信息抽取的模型。
利用BiLSTM-CRF、IDCNN-CRF、BERT-IDCNNCRF 和BERT-BiLSTM-CRF 模型对症状实体进行识别,并修改Learning rate、Batch-size、Epoch 参数的值。采用BIO 标注法时,当Learning rate 为0.01,Batch-size为16,Epoch 为100 时BiLSTM-CRF 模型的精确率、召回率、F1 最高可分别达到91.35%、71.08%、81.20%;当Learning rate 为0.001,Batch-size 为64,Epoch 为100 时IDCNN-CRF 模型精确率、召回率、F1 最高可分别达到89.07%、87.94%、86.85%;当Learning rate 为0.01,Batch-size 为64,Epoch 为40 时BERT-IDCNN-CRF 模型的精确率、召回率、F1 最高可分别达到89.7%、72.1%、78.7%;当Learning rate 为0.001,Batch-size 为32,Epoch 为90时BERT-BiLSTM-CRF 模型的精确率、召回率、F1 最高可分别达到87.71%、91.14%、88.89%。综上所述,BERT-BiLSTM-CRF 模型对症状实体的识别效果最好。因此,选用BERT-BiLSTM-CRF 作为识别模型,此时,Learning rate、Batch-size、Epoch 分别为0.001、32、90。当采用BIOES 标注法时,BERTBiLSTM-CRF 模型的精确率、召回率、F1 分别为80.04%、87.20%、83.47%,比采用BIO 标注法时低,因此最终选用BIO标注法进行实验。
3.3 事件抽取
由于刻下症中不含诊疗事件,因此本小节不考虑刻下症。本文综合考虑了匹配触发词的方式抽取诊疗事件和利用命名实体识别模型来识别诊疗事件两种方式。实验发现,前者依赖于触发词的选定以及待抽取的原始数据的选择。当事先对数据无任何预知的情况下,识别诊疗事件的结果会根据触发词的不同以及选取的现病史数据的不同而有所差异,好的情况识别诊疗事件的F1 值能够高达100%,差的情况识别的F1 值只有30%左右。而后者采用命名实体识别技术进行识别时F1值可达70%,与前者取平均的结果相差不大,但此种方式不会因为数据的不同而导致结果有很大的波动。由此考虑将两者相结合的方式抽取诊疗事件,首先利用命名实体识别模型识别出诊疗事件,然后根据总结出的触发词再次划分诊疗事件,按此种方式抽取后的Precision、Recall 和F1 值分别到达79.20%、83.96%和81.77%。
例如对表1中河南省骨伤科现病史的例子进行诊疗事件抽取后变为:“{event:1 周前病人无明显原因出现腰背部疼痛加重,弯腰、翻身、起床等活动明显受限,休息数日后疼痛缓解不明显。}{event:今日至我科就诊,为求进一步系统治疗,由门诊拟‘严重骨质疏松、胸腰椎多发压缩骨折’收入我病区治疗。}”一共2次诊疗事件。
3.4 实体抽取
由于刻下症中包含了大量中医术语,而现病史中则包含了几乎所有电子病历中主要的实体,因此本文的实验对象主要针对电子病历中刻下症和既现病史进行抽取,下面将分别对刻下症与现病史中的内容进行识别。
3.4.1 刻下症实体抽取
刻下症中的实体主要是症状实体,而症状实体包括了必要属性和附加属性,如骨干症状、人体部位等,Du 等[29]对知识属性的识别过程做了详细描述。利用BERT-BiLSTM-CRF 模型对骨伤科刻下症中症状实体进行识别,将骨科加外科的病证诊断术语共1109 条名词作为基础语料,分别随机选取10%(56 条)、15%(84条)、20%(112)、25%(141 条)、30%(169 条)5 种比例的骨伤科专科专病语料中刻下症内容进行识别,比较精确率、召回率F1 值。训练结果如表3 所示。当加入25%的专科专病语料库时精确率和F1值最高,分别为79.76%、83.75%,召回率较高,为88.16%。见表3。
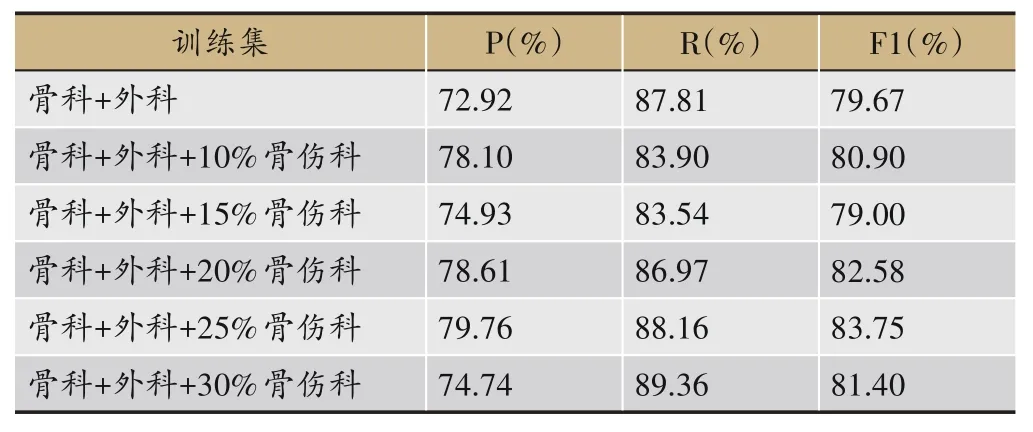
表3 BERT-BiLSTM-CRF模型对刻下症症状实体识别结果
例如,对表1 中河南省某中医院的刻下症文本进行实体抽取,能识别出阴性症状有“神志清”、“精神可”、“饮食可”、“小便可”、“无发热”;阳性症状有“表情痛苦”、“大便秘”、“消廋”。
3.4.2 现病史实体抽取
利用BERT-BiLSTM-CRF 模型对现病史中症状、疾病等实体进行识别,将骨科加外科的病证诊断术语共1109 条名词作为基础语料,加入实体语料库,然后分别随机选取10%、15%、20%、25%、30%共5 种比例的骨伤科专科专病语料中现病史内容进行事件抽取后得到的诊疗事件,进行实体识别,比较精确率、召回率和F1值。当加入30%的专科专病语料库时精确率、召回率和F1 值最高,分别为88.15%、85.94%、90.48%。各种实体的识别情况以及平均效果如表4所示。
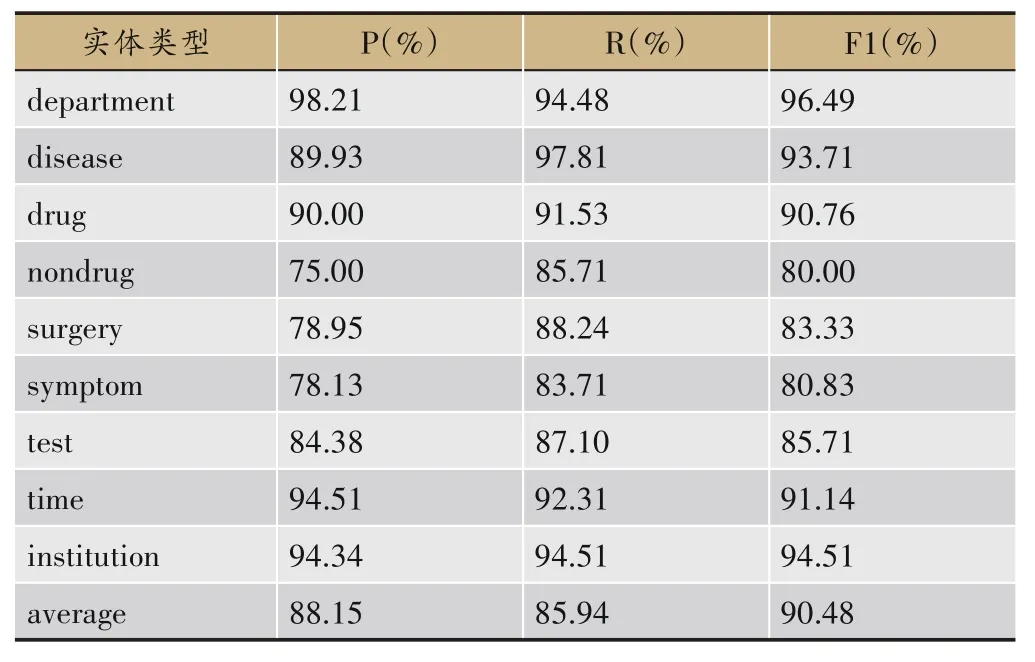
表4 BERT-BiLSTM-CRF模型对现病史各类实体的识别结果
例如对3.3 节事件抽取中的第二个诊疗事件可识别出时间实体为“今日”,科室实体为“我科”、“门诊”,疾病实体为“严重骨质疏松”、“胸腰椎多发压缩骨折”。
3.5 数据存储
将抽取出来的症状、疾病等9 种实体按照一定的结构存储至Excel 表中,使自然语言形式表达的中医电子病历文本信息得以规范化、结构化,方便后续对中医电子病历入院记录信息进行深度挖掘研究。
4 结论
本文提出了中医电子病历入院记录信息自动抽取的方法,并基于相关标准构建了蕴含知识属性的实体语料库。利用事件抽取与命名实体识别技术,通过对多个常用信息抽取模型进行比较,最终遴选出了BERT-BiLSTM-CRF 模型。利用该模型分别对刻下症中的症状实体和现病史中的症状、疾病、机构、科室、药物等9 类实体进行识别与抽取,对刻下症中症状实体的识别率达83.75%,对既往病史中症状、疾病、药物等实体的识别率达90.48%。运用该方法可将中医电子病历入院记录信息以结构化、规范化的形式存储到Excel表中,有助于研究人员对中医电子病历数据再次利用,深度挖掘其潜在价值,对中医临床辨证论治的传承与创新起到了重要作用。在研究过程中发现语料库的质量对实体识别率有显著影响,因此在今后的研究中将不断扩充和完善语料库,此外需进一步优化命名实体识别模型以提高电子病历现病史的识别率。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18
中国毕业后医学教育(2021年2期)2021-12-06
中国毕业后医学教育(2020年6期)2020-12-06
数学小灵通·3-4年级(2020年9期)2020-10-27
天津外国语大学学报(2020年1期)2020-03-25
智能计算机与应用(2019年4期)2019-09-12
中国卫生(2016年10期)2016-11-13
中国卫生(2016年9期)2016-11-12
中国卫生(2015年10期)2015-11-10
语言与翻译(2015年4期)2015-07-18
