
基于关联规则的数字图书馆书目查询系统设计
2023-08-27 09:02周香
电子设计工程 2023年17期
周香
(陕西电子信息职业技术学院,陕西西安 710500)
数字图书馆是一种新型的图书管理模式,满足了网络化的需求。数字化、多媒体信息资源是数字图书馆服务的基础与先决条件,也是数字图书馆建设的核心。作为信息资源的持有者和提供者,如何充分利用互联网,构建大规模的数字资源库,并通过互联网进行网上查询,是当前各大图书馆面临的一个重要难题。图书馆是使用者能够获取最丰富的文献资料的主要来源,过去的文献资料则把图书馆与网络之间的联系分割开来。另外,不同的数字图书馆系统开发语言、开发平台和通信协议也各不相同,在不同的数字图书馆体系中,信息资源的共享存在着很大的困难。文献[1]提出的基于Solr 的标准查询技术,通过Solr 查询引擎对标准书目进行拆分,并对查询结果排序,使其应用到数字图书馆书目查询工程实践中;文献[2]提出的基于人工智能技术的查询方案,通过对数据标准化处理,实现对数字图书馆书目的挖掘,结合人工智能技术实现数字图书馆书目查询。然而,这两种方法受到大量数字图书馆书目信息影响,导致查询效果不佳,为此,设计了基于关联规则的数字图书馆书目查询系统。
1 系统硬件结构设计
设计的基于关联规则的数字图书馆书目查询系统,硬件结构如图1 所示。
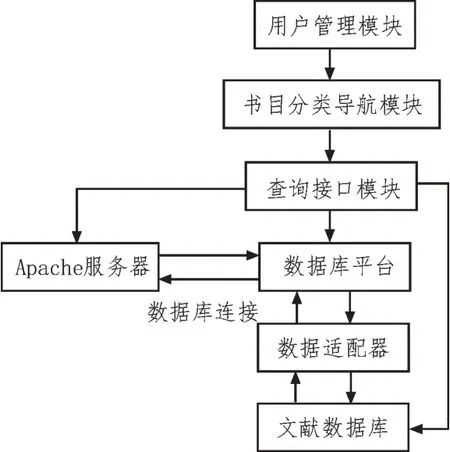
图1 系统硬件结构
1.1 书目分类导航模块
为了确保该书目分类导航模块基本功能,用户可以通过查询式目录的查询界面选取目录号,并按照目录进行查询。读者在进入分类导航界面后,开始查询书目,并向目录数据库发送查询请求[4]。
1.2 查询接口模块
使用的数字图书馆数目查询接口,如图2 所示。
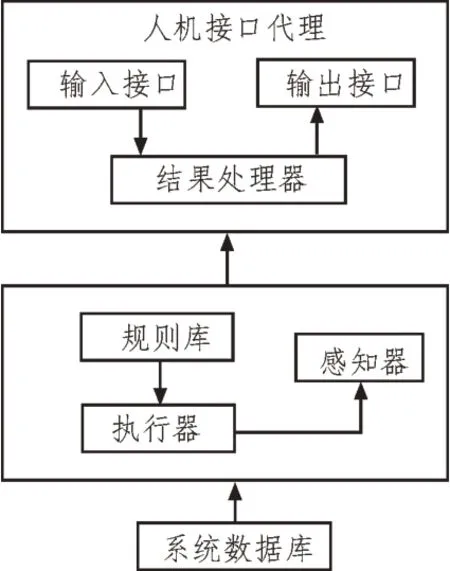
图2 查询接口
数字图书馆数目查询接口具有模糊查询功能,能够校验前后查询语句一致性和完整性。通过定位检索方式,构建索引标识,能够提高检索响应速度[5]。通常查询接口主要有两种,分别是人机代理接口和监控代理接口。
1.2.1 人机代理接口
人机代理接口包括输入接口、输出接口和输出处理模块,其工作方式如下:输入接口接收读者的输入信息,并对其进行检验,如果不满足接收条件,则提示读者修改输入信息;如果满足,则向结果处理器发送查询词[6-7]。结果处理器接收到查询词后,根据索引地址集获取查询词的相关属性信息,之后在MIS 系统中提取相关属性信息,并将提取结果发送给输出接口,输出接口负责显示和打印[8]。
1.2.2 监控代理接口
监控代理接口主要负责对查询界面中的索引文件进行维护,该部分主要由感知器、知识库、控制器和执行器组成。由于人机代理接口无法更改系统原始索引,所以只能通过监控索引结构进行更改[9]。如果出现变化,需要在书目中及时反映出来。监控代理工作方式如下:感应器是感应环境,并在第一时间作出指标[10]。在原始指标数据发生变化时,需要立即向控制器发送信号,依据控制器预先设置的关联规则来更改原始指标数据[11]。将更改后的指标数据加入系统,该记录就会被传送到该索引中。此时,系统会自动创建一个新的索引,控制器也会立刻执行索引更新任务,待控制器获取来自感知器的全部数据后,即可完成知识库全部索引更新任务[12]。通过监控代理接口,能够及时判断索引结构,一旦发现结构变化,只需更新关联规则,不用更改代理程序,就能快速完成索引的更新,该过程灵活、简便,方便移植。
HPV感染与肺癌预后相关性的机制暂不明确。既往研究提示,HPV阳性肺癌组织中HPV E6、E7癌蛋白的过度表达会下调p53蛋白,导致HPV阳性肺癌患者预后更好[23]。也有研究提出,HPV感染相关恶性肿瘤的主要特征为p53退化和p16上调,导致野生型TP53[24]和p16[25]基因携带几率增大,无病生存率提高。同时,遗传学研究提示,相比未感染HPV的肿瘤细胞,HPV感染肿瘤细胞的染色体畸变率和染色体增倍体出现几率明显降低,对放疗和化疗的敏感性明显升高,预后更好[26]。未来仍需进一步深入的基础研究来阐述HPV感染与肺癌预后相关性的可能机制。
1.3 Apache服务器模块
Apache 可以在任意一台计算机操作系统上运行,其结构如图3 所示。

图3 Apache服务器模块结构
由图3 可知,该服务器主要用于监视系统运行情况。Apache 能够在很大程度上灵活地记录和监控服务器的运行状态,并且能够满足用户的需要[13]。同时,它还配备了一个虚拟主机,主要功能是通过一个服务器实现多个主机之间的互联,为整个系统提供HTTP 服务[14]。Apache 模块可以在运行时进行动态加载,从而减少了内存负载。
2 系统软件部分设计
2.1 基于关联规则的查询索引构建
书目推荐算法一般都是以项集合来表达,这些项集合彼此独立,没有重复属性。对于关联规则,需要计算书目特征集的支持度,对于项集D的支持度,其计算公式为:
式中,Q表示全部数据集。如果项集D是一种频繁项集,那么该项集支持度大于等于频繁项集中的任意最小频繁项集。集合间的个性化规则必须符合以下条件:各项集合是有效的,且各项集合之间的个性化应具有某种普遍性[15]。以此为依据,构建的基于关联规则的查询索引模型,如图4 所示。

图4 基于关联规则的查询索引模型
由图4 可知,在确定特征采集结果和关键词后,在字段上建立索引,由此完成索引的构建。在查询系统中,构建查询索引模型详细步骤如下:首先,读者提出查询需求的条件,然后,系统按照查询需求来检索与查询相关的文件,同时系统根据查询条件与书目数据之间的关联性按照相似度大小依次排序,最后,将排序后的结果反馈给读者[16]。
2.2 数字图书馆书目查询步骤设计
根据构建的查询索引模型搜索频繁项集,待搜索完成后会产生强大的关联规则。在该规则中,设1为非空子集,0 为空子集,如果项集合的每一个频繁项集为1,说明该项集为非空子集,可以将此集合作为书目查询集合,反之,则不能。
针对数字图书馆查询书目存在特征集合xm,对这些特征进行矢量化处理,得到的特征均与书目单词相呼应。
设需要查询的书目库为W,可表示为:
式中,gn表示第n个书目;N表示书目总量。在需要查询的书目库中,将全部特征映射成一组节点数据,使其成为一条量化路径。
在该条量化路径上,使用一种能控制字段存储的估计参数,可表示为:
式中,l(μ)表示估计参数相对于特征集合xm的似然函数。通过对似然函数进行数据转化处理,能够得到书目查询模型,如下所示:
式中,Uμ表示数字图书馆书目全部查询结果。该公式计算结果越高,书目查询结果就越精准,由此完成数字图书馆书目查询。
3 系统测试
3.1 数据源选取
系统测试选取的图书馆历史记录数据作为图书馆查询系统的研究对象,登录某校图书馆自动化管理系统模块,统计2018 年1 月—2022 年1 月的读者查询历史记录。
3.2 系统生成的关联规则
从基于关联规则的数字图书馆书目查询系统生成的频繁数据库中产生具有强关联的规则,如果这些规则的支持度和置信度大于设定的阈值0.4 和0.7,则说明该系统查询结构与读者查询结果关联性较大。
使用该平台生成的15 条历史记录关联规则,如表1 所示。

表1 生成的关联规则
由表1 可知,读者在查询图书时表现出较强的个性化,因此,系统生成的关联规则支持度和置信度较高。根据系统测试结果可以看出,《邓小平思想概论》、《思想道德修养教程》、《现代国家的政策过程》关联规则较高,说明被查询的次数也较多。
3.3 测试结果与分析
为了进一步验证基于关联规则的数字图书馆书目查询系统设计合理性,需将其与基于Solr 的标准查询技术、基于人工智能技术的查询方案的查询结果进行对比分析。以查全率和查准率为指标,三种方法的查询效果对比结果如图5 所示。
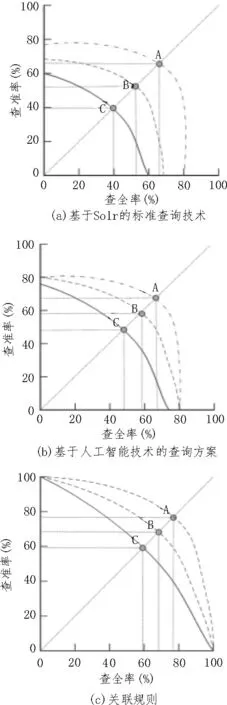
图5 三种方法查询效果对比分析
由图5 可知,A、B、C 三个点分别代表《邓小平思想概论》、《思想道德修养教程》、《现代国家的政策过程》书目,这三个点也为三种方法的平衡点,曲线A 完全包住曲线B,曲线B 完全包住曲线C,其中A 点为查询效果最佳点,C 点查询效果最差点。通过对比结果可知,使用基于Solr 的标准查询技术,C点查全率和查准率均为40%,A 点查全率和查准率均为67%;使用基于人工智能技术的查询方案,C 点查全率和查准率均为49%,A 点查全率和查准率均为68%;使用基于关联规则的数字图书馆书目查询系统,C 点查全率和查准率均为60%,A 点查全率和查准率均为78%。
通过上述分析结果可知,使用基于关联规则的数字图书馆书目查询系统查全率和查准率均最高,说明使用该系统具有高效查询效率。
4 结束语
文中设计了基于关联规则的数字图书馆书目查询系统,对查询数据进行了关联分析,确定图书馆书目之间存在的关联信息,并形成了强大的关联规则,为读者提供了一种主动的、个性化的查询服务,通过对查询方式分析向读者提供有关书籍的建议。
目前,数据查询技术在图书馆的应用尚处于起步阶段,对个性化查询服务的发展起到积极的推动作用。针对关联规则数字图书馆书目查询问题,提出了如下期望:下一步需要设置一个频率门限,来决定频繁书目集合,从而迅速找到读者所关心的书目。
猜你喜欢
都市人(2022年3期)2022-04-27
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
中国民间疗法(2012年1期)2012-07-27
中国管理信息化(2009年10期)2009-06-19
全国新书目(2009年1期)2009-04-13
全国新书目(2006年9期)2006-05-26
