
改进MAHAKIL 的过采样技术
2023-08-27 09:02袁甜甜李凤莲左婷
电子设计工程 2023年17期
袁甜甜,李凤莲,左婷
(太原理工大学信息与计算机学院,山西榆次 030600)
在现实生活中,存在很多不平衡问题,如疾病诊断[1]、非法网络入侵[2]等。脑卒中是严重威胁全国居民公共健康的疾病之一,是全球范围内致死、致残的重要原因[3]。对脑卒中进行辅助诊断也常面临数据不平衡的问题。不平衡指的是不同类别中,一类(称为多数类或负数)所包含的样本数远多于其他类(称为少数类或正类)。机器学习算法训练分类器时,容易导致对多数类的偏向,使得分类结果具有高准确率,少数类样本却存在高误分率。
近年来,学者们对类不平衡问题展开了深入研究,在不降低多数类样本准确率的前提下,提高机器学习预测正类样本的准确性。文献[4]提出了SMOTE-LOF 算法,剔除合成少数类样本的噪声因子,通过添加局部利群因子(Local Outlier Factor,LOF)来改进传统的合成少数样本过采样技术(Synthetic Minority Oversampling Technique,SMOTE);文献[5]建立了一个分类器模型,结合遗传算法与BP神经网络,取得了良好的分类效果,但没有考虑算法的复杂度问题。文献[6]基于遗传算法提出MAHAKIL 过采样算法,将两个不同的少数类样本当作父母,继承父母不同的特征合成新的样本,该算法极大地提高了分类性能。但没有考虑合成样本的多样性及其噪声问题。以上研究证明,过采样技术对解决类不平衡问题有了良好的效果,但还存在进步空间。
为实现合成样本的多样性,该文提出了MARAIF算法(MAHAKIL Random and Isolation Forest)。首先,通过采用随机数替换平均数的方法合成新样本,提出了改进的MAHAKIL 算法。同时,采用了孤立森林(Isolation Forest,ISF)算法[7]检测离群样本,提高了预测精度。
1 相关理论
1.1 MAHAKIL过采样技术
1.1.1 马氏距离
马氏距离是由印度学者提出的[8],用来度量数据之间的相似性,与常用欧几里得距离不同的是,马氏距离考虑了样本数据特征之间的关系,消除了样本之间的相关干扰;利用样本数据之间的协方差,使得相似性不受样本维度的干扰。对于两个样本x=[x1,x2,…,xm]T与y=[y1,y2,…,ym]T,马氏距离计算公式如式(1)所示:
1.1.2 MAHAKIL算法原理
SMOTE 过采样技术采用K 近邻方法选取与样本点相近的样本[9],与之结合生成新样本。这种方法一方面容易拓宽少数类样本的边界,影响分类效果;另一方面若少数类样本存在类内不平衡问题,生成的新样本只会增加子簇的大小,恶化类内不平衡。针对该问题,文献[6]提出了MAHAKIL 过采样技术,利用初始种群中的样本进行连续交叉生成新的合成样本,使得子代样本与亲代样本之间保持一致性,又添加了新的特征。MAHAKIL 算法合成新样本步骤如下:
Step 1:将数据集D分为多数类Dmaj与少数类Dmin,计算T=Dmaj-Dmin为需要合成的新样本数目。计算D中每个样本到中心点的马氏距离,并进行降序排列。
Step2:按照马氏距离大小将样本分为两个部分,并依次为每个样本分配唯一的标签。
Step3:从两个分区中选择两个样本(具有相同的唯一标签),求取平均值生成新的合成样本。
Step4:子样本与亲代样本交叉结合,直至满足需要合成的样本数。
1.2 孤立森林算法
在过采样过程中,不可避免地会产生噪声因子,合成的少数类样本有时会成为多数类的一部分,影响了分类的效果。图1 描述了噪声样本的情况[10],其中,N 为噪声样本(Noisy Sample);B 为边界样本(Borderline Sample);S 为安全样本(Safe Sample),噪声被定义为错误的标签或属性值中的噪声。

图1 噪声样本
针对生成新样本中的噪声问题,可以采用异常值检测技术。孤立森林是一种有效的无监督异常值检测算法[11],孤立是指从整个数据集中分离出异常的数据,通常情况下,正常数据比异常数据要多。异常数据的特点如下:
1)异常样本占数据集的很小部分。
2)与正常数据相比,异常数据具有不同的行为或特征。
不同于传统的异常检测算法(如LOF[12]、KNN[13]),ISF 不计算距离或密度,因此显著减少了执行时间和内存需求;具有低而小的内存需求[11]和线性执行时间。
算法原理是递归地随机切分数据集,直至所有的样本点被孤立,在这种切分策略下,异常值通常切分较少的次数就可以被孤立。如图2 所示,密度较高的正常样本Xi需要切分很多次才能被孤立,而异常值X0则很容易就被孤立。
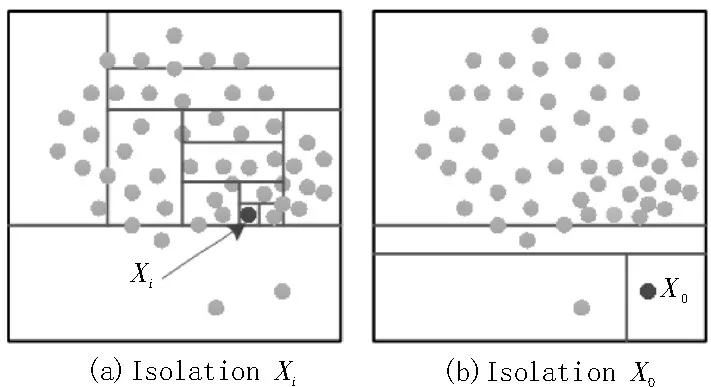
图2 数据集中样本点的孤立
ISF 检测异常值包括两个步骤:训练阶段与评估阶段。
1)训练阶段
孤立二叉树建立对数据集D的递归分割,直至所有样本点被孤立,或者达到了树的指定高度。
2)评估阶段
计算数据集中每个样本的得分。该分数是样本与其他样本之间的相似性程度。根据样本的路径长度h(d),计算样本d的异常分数,如式(2)所示:
其中,n是数据集D的样本总数,E(h(d))是样本d的多颗树的路径长度平均值。C(n)用来对样本d的路径长度进行标准化。H(i)=ln(i)+0.577 215 664 9为调和数。E(h(d))值越小,则样本的异常分数越接近于1,此时,样本被认定为异常样本。
2 MARAIF算法实现
该文提出的MARAIF 算法的原理:首先,将不平衡数据集分为多数类与少数类,对少数类样本,采用改进的MAHAKIL 算法合成新样本。将合成的新样本采用孤立森林算法去除噪声因子。最终重组多数类与少数类样本。
MAHAKIL 算法在合成子代样本时,取亲代样本二者的平均值,忽视了合成新样本的多样性问题。笔者认为,使用随机数替换单一取平均值的方法,继承亲代不同比例的特征,不仅使生成的样本有更多的特性,又能够保留亲代的特点。改进的MAHAKIL算法描述如算法1 所示。
过采样技术合成的新样本往往伴随着生成噪声样本,以干扰分类性能。为避免噪声的影响,提高合成样本的有效率,该研究采用ISF 异常检测技术,检测出的异常值即噪声因子。
算法1:MAHARA(MAHAKIL Random)
1)将数据集D分为多数类数组Dmaj和少数类数组Dmin,计算需要生成的样本数T=Dmaj-Dmin;
2)Dnew:生成样本数组,初始化为0;Dnewnum:统计生成样本的数量;
3)计算Dmin中样本的马氏距离,按照顺序递减排列并保存到Dminmaha;
4)找到Dmin的中心点,即Dmid=T/2,将Dminmaha分为两个部分:
Dpar1={d1,d2,…,dmid},Dpar2={dmid+1,dmid+2,…,dt},其中di∈Dminmaha。对于da∈Dpar1,db∈Dpar2,分配唯一的标签li,i=1,2,…,mid;
5)fori=1,2,…,mid
从Dpar1、Dpar2分别选取样本da、db,其 中,da(li)==db(li)
生成新的样本:
将d添加到Dnew;Dnewnum+1
6)end for
7)如果Dnewnum<T,则将Dnew中的样本与Dpar中的样本结合,并重复步骤5)-6)生成Dnew[j](j=1,2);如果仍然Dnewnum<T,将当前Dnew与它的直系父代配对,然后与前任父代配对,并重复步骤5)-6);
8)直至Dnewnum>=T,Dnew中的所有样本即为生成的少数类样本。
被识别的噪声仅来源于MAHARA 产生的合成少数类样本,而不是原始样本。剔除识别为噪声的样本,然后重组多数类与少数类样本,使用机器学习分类器将最终所得的平衡数据集进行分类。MARAIF 过采样算法流程图如图3 所示。

图3 MARAIF算法流程图
3 实验及结果分析
3.1 评价指标
传统的二分类评价标准由表1 所示的混淆矩阵[14]元素组成。

表1 混淆矩阵元素
在不平衡数据集中,少数类样本被称为正类,多数类样本被称为负类。实验选取F1-measure、AUC(ROC 曲线下的面积)评估分类性能,计算公式如式(4)-(5)所示:
3.2 数据集
实验选用的公共数据集的信息如表2 所示,包括数据集(Datasets)、样本数量(Amounts)、属性个数(Attributes)以及数据集的不平衡率(Imbalance Rate,IR)。随机选取数据集的80%作为训练集,20%作为测试集。

表2 公共数据集
该文采用的脑卒中发病风险预测数据集从国内某医院神经内科脑卒中筛查病例数据库中获取,经过数据清洗等预处理后,整理得到数据集Stroke。该数据集包含41 个属性,诊断类别为八类。实验选取两种类别:脑出血(251 例)和颈动脉狭窄或闭塞(33 例),不平衡率为7.61。
3.3 实验设计
为了比较MARAIF 算法的性能,实验采用了SMOTE[15]、MAHAKIL、ADASYN[16]进行对比实验。另外,为了分析MARAIF 算法结合不同分类算法的分类效果,实验选择了五种常用的分类算法:逻辑回归(Logistic Regression,LR)、决策树(Decision Tree,DT)、随机森林(Random Forest,RF)、支持向量机(Support Vector Machine,SVM)以及K 近邻(K-Nearest Neighbor,KNN)。实验采用了5-fold 交叉验证网格寻优法搜索分类器的最优参数,使用AUC 作为寻优的目标参数。
3.4 公共数据集的实验结果与分析
表3 显示了公共数据集在每种过采样方法下AUC、F1-measure 评价指标的实验结果。当使用AUC 为评价指标时,所提算法MARAIF 与其他方法的比较结果如表3 左侧所示,可以看出除了数据集Churn_ prediction 外,MARAIF 算法可以在三个数据集上获得更好的分类性能,其中Glass-1-2-7_vs_3取得的效果最为明显,在决策树分类器上,相较于SMOTE、ADASYN、MAHAKIL 分别提高了25.50%、21.74%、20.95%。而在Churn_ prediction 数据集上,MARAIF 算法相较于MAHAKIL,除了在决策树分类器取得了相同的分类性能,在其他分类器上均表现更好,验证了MARAIF 算法提高不平衡样本集分类能力的有效性。

表3 公共数据集MARAIF算法与已有过采样技术AUC值、F1-measure结果对比
表3 右侧呈现了MARAIF 算法与其他算法的F1-measure 结果,可以看出,在Glass-1-2-7_vs_3 数据集上,除了决策树分类器,较之SMOTE 有0.1%的降低外,其他均有提高,且分类性能均优于MAHAKIL 算法;此外,在Churn_ prediction 数据集上,该文所提出的MARAIF 算法在LR、DT、SVM、KNN 分类器的性能均低于SMOTE,但与MAHAKIL进行比较,均优于MAHAKIL 算法,验证了该文提出的基于MAHAKIL 的改进算法的有效性。
从数据集层面分析,该文算法更适用于低失衡率的数据集,优于其他对比的过采样技术。在高失衡数据集(Churn_ prediction)中,MARAIF 算法性能较MAHAKIL 更为优越。在F1-measure 评价指标方面,与SMOTE 还有些许差距。
3.5 脑卒中数据集的实验结果与分析
图4、图5 显示了脑卒中筛查数据集与已有过采样技术在AUC 值、F1-measure 值的实验对比结果。
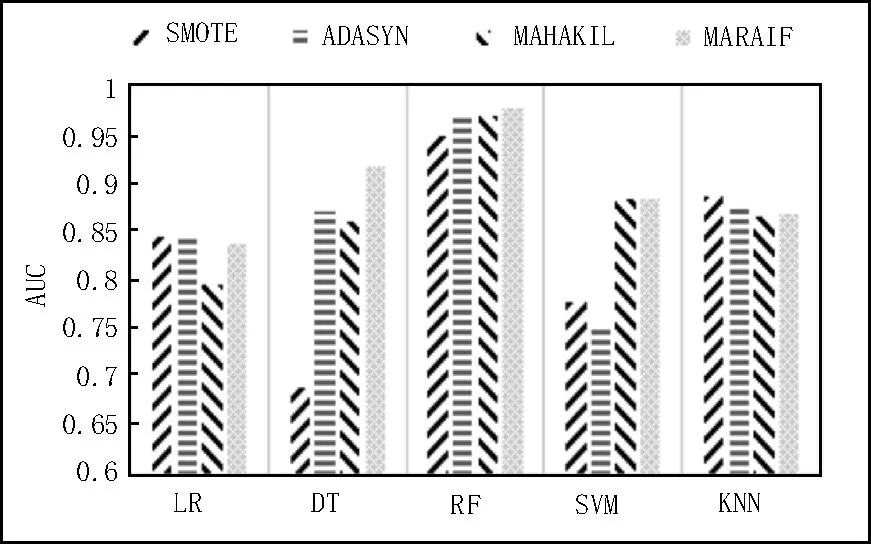
图4 算法在脑卒中筛查数据集中AUC结果对比

图5 算法在脑卒中筛查数据集中F1-measure结果对比
由图4 可以看出,MARAIF 算法在DT、RF、SVM分类器均取得了最好的结果,其中,决策树分类器的效果最为明显,较之SMOTE、ADASYN、MAHAKIL 过采样技术,AUC 分别提高了32.61%、5.17%、6.64%。此外,在LR、KNN 分类器上,虽实验结果不是最好的,但性能均优于MAHAKIL 算法。
从图5结果可知,在决策树分类器、KNN分类器上,MARAIF 算法均取得了最好的F1-measure 值;此外,除逻辑回归分类器以外,MARAIF 算法的效果均优于MAHAKIL算法,验证了该文所提出算法的有效性。
综合结果表明,该文算法具有比SMOTE、ADASYN、MAHAKIL 三种过采样技术更优越的分类性能。MARAIF 算法适用于多种类型的分类器,特别是决策树分类器,可获得更好的分类性能。此外,对于较低失衡率的数据集[17-18],该文所提出的算法更能体现其优越性。
4 结论
为了解决脑卒中筛查数据集的类别不平衡问题,该文基于MAHAKIL 与孤立森林提出一种MARAIF 过采样算法,该算法采用随机数克服了MAHAKIL 合成新样本单一的缺点。针对过采样生成新样本容易生成噪声样本,影响分类性能的缺陷,对新生成的样本该文采用孤立森林算法对噪声样本进行过滤,得到更具识别率的新样本。通过在不同机器学习分类器进行实验,与SMOTE、ADASYN、MAHAKIL 过采样技术进行对比,实验结果表明,MARAIF 算法综合表现优于其他三种过采样技术,且适用于多种类型的分类器。但是,对于高失衡的样本数据集,分类效果略低于SMOTE,下一步将研究如何更有效地提高对高失衡数据集的分类性能。
猜你喜欢
数学年刊A辑(中文版)(2020年3期)2020-10-27
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子测试(2018年1期)2018-04-18
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
