
基于位姿插值的相机和激光外参在线标定
2023-08-19 09:59周媛媛
电子设计工程 2023年16期
周媛媛,易 鹏,马 力
(广州市城市规划勘测设计研究院,广东 广州 510000)
近几年来,自动驾驶技术发展迅速,通过多传感器融合方案来保证自动驾驶场景下的稳定感知是主流趋势,其中激光雷达与摄像头可以提供互补信息,是目前常用的融合方案。激光雷达和相机融合的基础就是精确的外参标定,即对两个传感器相对刚体变换的精确估计。
一些早期的校准工作使用人工标靶(例如棋盘和特定标定板)来标定LiDAR 和相机[1-6]。然而,大多数基于标靶的校准算法耗时、费力且离线,需要经常重新校准。一些针对激光雷达和相机的标定方法开始侧重于实现全自动且无人工标靶的在线标定[7-12]。然而,目前大多数在线自标定方法对标定场景有严格的要求,且需要事先完成两个传感器的时间同步,才可以利用时间同步好的两种传感器信息进行标定。
针对以上难点,文中提出了一种基于位姿插值和自然平面目标的相机与激光雷达外参在线标定方法,仅通过车辆在线获取的图像和激光雷达点云数据进行在线标定,在无标靶和传感器未时间同步情况下依然可以获取精确的外参数据。
1 外参在线标定方法流程
图1 所示为整个算法的流程图,在车辆运行过程中,激光和图像数据会分别通过各自的SLAM 算法估计其对应的位姿。当传感器未完成时间同步时,该方法首先通过B 样条曲线拟合进行位姿插值,实现LiDAR 和相机位姿的时间对齐,并以此利用位姿图优化计算外参变换初值。接着通过图像的语义分割获得场景中的平面物体的掩膜,之后利用变换初值计算2D 掩膜对应激光雷达中的3D 点云锥,并基于点云生长优化对应点云锥结果;最后构造基于2D 物体掩膜和对应3D 点云锥的投影残差损失函数,通过非线性优化获得精准的外参标定结果。
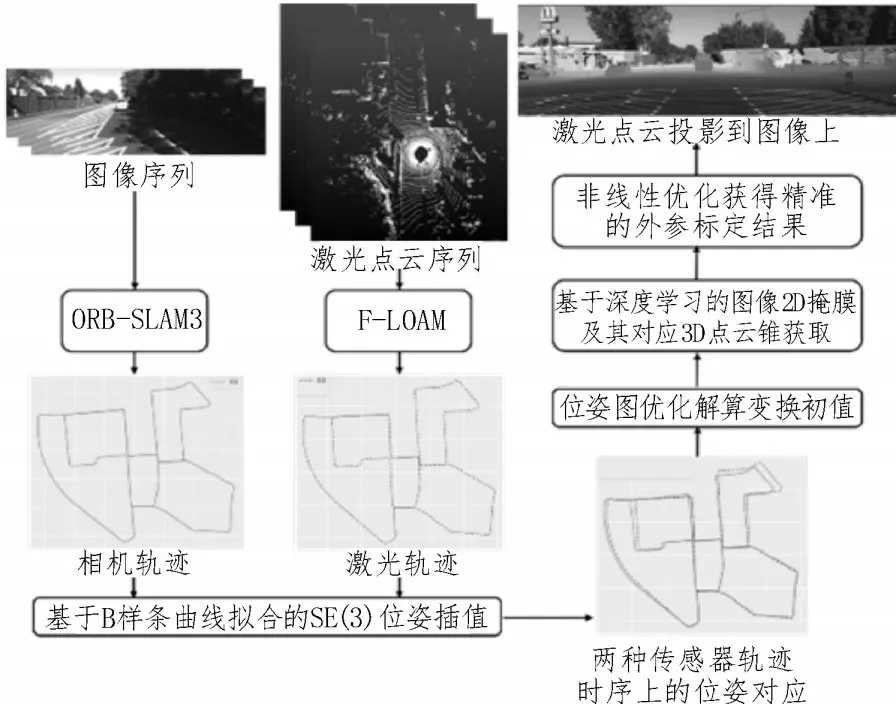
图1 在线标定算法流程图
2 基于B 样条曲线拟合的SE(3)位姿插值
对于车辆在线获取的两种传感器数据,首先会各自利用该传感器数据进行SLAM 的位姿估计,估计出每个时刻该传感器的位姿信息,相机基于ORBSLAM3[13]的单目方法进行位姿估计,3D 激光雷达则利用F-LOAM[14]方法进行位姿估计。但是当两种传感器未事先完成时间同步时,这两种传感器的位姿无法在时间上同步,即无法知道同一时刻下这两个传感器分别对应的位姿信息,位姿无法完成对应。因此,该方法首先基于B 样条曲线拟合,以激光雷达轨迹估计结果作为基准,对相机估计轨迹中的SE(3)位姿进行插值,获得密集对应的位姿结果,完成两种传感器在时序上的位姿对应。再利用对应好的位姿,进行投影误差函数的构建。最后,通过位姿图优化解算获得两种传感器各自估计轨迹的相对变换矩阵,作为激光雷达和相机外参的变换初值。下面将介绍B 样条曲线拟合的位姿插值原理。
时间连续位姿T(t)由转动分量R(t)和平移分量p(t)组成:
这是在每个B 样条窗口内对组进行线性插值的混合。待插值的位姿定义为从体坐标系到全局坐标系的变换,即:
其中,p是全局坐标系中的样条位置,R是从体坐标系到全局坐标系的旋转。一个转动用于表示两个姿势之间的移动:
转动ε=(υ,ω)∈SE(3)由平移v(有方向和尺度)和轴角向量ω组成。通过将转动与一个标量θ相乘,可以得到SE(3)中的一个元素,其解析表达式如下:
3 基于深度学习的图像2D 掩膜及其对应3D点云锥获取
该方法使用语义分割方法[15]分割出图像中的语义2D 掩膜,在将感兴趣的平面目标掩膜分割出之后,利用上节获得的变换初参,可以从2D 掩模区域进行逆锥投影来搜索该2D 框对应的激光雷达3D 点云区域,实现在小范围内提取平面目标点。然而,因为初参不精准等原因,对应的3D 空间点云可能只有部分在投影锥中,因此通过引入点云生长的方法来补齐3D 平面目标点云。首先将图像2D 的掩膜区域按照2 倍比例扩大,逆锥投影区域也相应地进行扩大,之后根据激光雷达点云位置构建无向图。对不同的子类选取随机的图上顶点作为种子点,以种子点为基础进行生长,从而完成对3D 平面目标点云的补齐。最后构造基于2D 物体掩膜和对应3D 点云锥的投影残差损失函数,通过非线性优化获得精准的外参标定结果。
4 实 验
文中实验所用的数据集是公开的自动驾驶数据集-KITTI 数据集[16],KITTI 数据集是目前最常使用的自动驾驶数据集之一。KITTI 数据集包含有彩色摄像机和一个Velodyne 64 线激光雷达的数据,彩色摄像机为全局曝光的CCD 相机,文中在KITTI 数据集中的Odometry 数据集进行实验,采用彩色相机和激光雷达的数据进行实验。KIITI 数据集中示例图像及其对应的激光点云如图2 所示。

图2 KITTI数据集中示例图像及其对应的激光点云
两种传感器分别估计得到的轨迹结果如图3 所示,其中下方的实线轨迹为未处理的相机估计轨迹,虚线轨迹为激光估计的轨迹,因为相机估计方法采用的是ORB-SLAM3 的单目方式,相机估计轨迹与真实世界存在一个尺度偏差,因此实线轨迹的尺度与虚线轨迹的尺度相差较大。
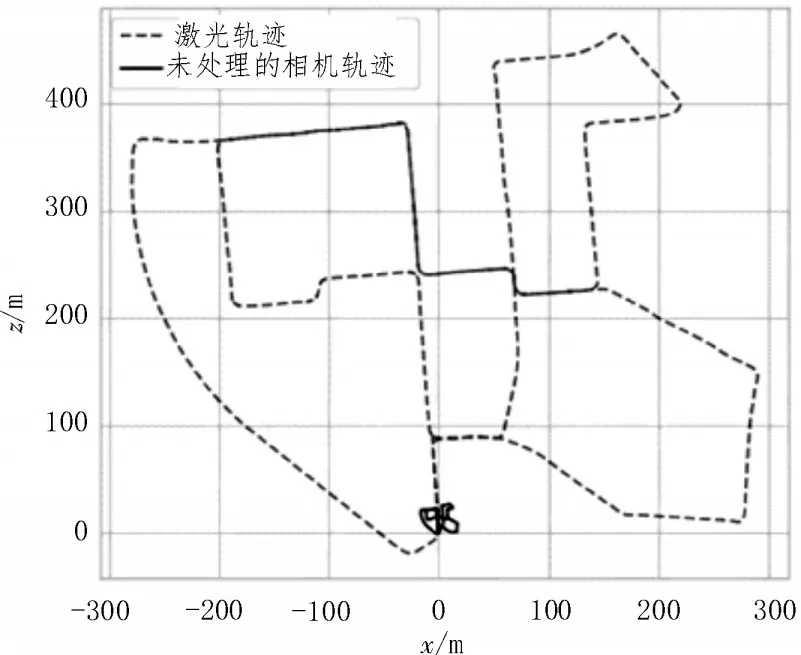
图3 两种传感器的估计轨迹
图4 所示为利用基于B 样条曲线拟合的SE(3)位姿插值,实现两种传感器轨迹时序上的位姿对应后的结果,其中实线轨迹为插值后对应完成的相机轨迹,虚线轨迹为激光轨迹。可以看出,文中方法不仅将两个轨迹的尺度对齐,而且完成了位姿时序上的对应。

图4 时序上位姿对齐后的结果
基于初参的结果,构造基于2D 物体掩膜和对应3D 点云锥的投影残差损失函数,最后通过非线性优化获得精准的外参标定结果。获得精确外参后可以将激光雷达点云投影到图像上,结果如图5 所示,可以看出文中方法很好地将激光点云投影到对应的物体上[17]。

图5 示例投影结果
5 结论
文中针对自动驾驶场景中相机和激光雷达在无靶标和传感器时间未同步情况下的在线标定问题,研究了利用SE(3)位姿插值和自然平面目标的外参在线标定方法,并通过在通用公开数据集进行实验验证了提出方法的高效性,利用文中方法在线标定出的外参结果,可以较精确地将激光点云投影到图像中。文中方法无需事先完成传感器时间同步和进行复杂的环境设置,在车辆运行过程中进行自动标定,大大降低了激光和相机外参标定的复杂性,具有很高的实用价值和意义。
猜你喜欢
北京测绘(2022年5期)2022-11-22
导航定位学报(2022年5期)2022-10-13
中国体视学与图像分析(2021年3期)2021-11-24
汽车观察(2021年8期)2021-09-01
中国交通信息化(2019年1期)2019-03-26
电子制作(2018年16期)2018-09-26
制造技术与机床(2017年10期)2017-11-28
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
科技资讯(2016年21期)2016-05-30
