
采用RGB−D的标准件语义分割方法
2023-08-18 06:37屈力刚杨英铎邢宇飞荆麒瑀
机械设计与制造 2023年8期
屈力刚,杨英铎,邢宇飞,荆麒瑀
(沈阳航空航天大学航空制造工艺数字化国防重点学科实验室,辽宁沈阳 110000)
1 引言
工业机器人作为工厂自动化生产线的重要组成部分,可以通过接受外部传感器信号获得目标的位置与姿态,并完成分拣、抓取、装配等各种任务。近年来,深度学习与图像的结合,使得计算机可以通过图像来计算任意摆放在世界坐标系中工件的姿态,而不再需要使用夹具固定在确定的位置,极大的提高了自动化的程度。而图像语义分割作为图像分析与处理的基础,是位姿估计的重要组成部分。如何精准的获得图像中目标的类别、位置和轮廓是图像语义分割的主要任务,也是研究的难点之一。在实际的工程应用过程中,有很多形状相似但是尺寸不同的零件,在语义分割的过程中很难区分这些不同尺寸零件的具体类别。在这些形状相似、尺寸不同的零件中,以具有代表性的标准件为例,结合深度图像提升对标准件进行语义分割的过程中分类的准确度,并自制标准件数据集进行验证方法的有效性。
2 相关工作
图像的语义分割(Image Semantic Segmentation)由文献[1]首次提出,并将图像语义分割定义为:为图像中的每一个像素分配一个预先定义好的表示其语义类别的标签。而卷积神经网络(Convolutional Neural Networks,CNN)的出现及快速发展,图像分割领域取得了巨大的突破。文献[2]提出了FCN(Fully Convolu⁃tional Networks),将CNN的全连接层用卷积层取代,适应任意尺寸的图像输入。同时使用上采样的反卷积层,可以输出更精确的结果。最后结合不同深度层结果的跳级结构,以确保鲁棒性和精确性。但FCN丢失了很多目标轮廓的细节特征,得到的边缘过于平滑。文献[3]在FCN的基础上提出了一种基于实例感知的语义分割任务的全卷积网络FCIS(Fully Convolutional Instance Seg⁃mentation),继承了FCN在语义分割和实例掩码上的所有优点,能够对目标同时进行检测和分割。但是FCIS对于重叠的目标很难将其准确的分割出来。文献[4]提出了ReSeg网络,使用RNN检索上下文信息以弥补FCN没有充分利用像素与像素之间的关系的不足。文献[5]提出了先分割候区域,再进行分类的方法,这种方法在准确度方面有所提升,但速度上并没有优势。文献[6]团队提出了MASK−RCNN网络结构,能够同时完成目标分类,目标检测与目标的像素级分割任务。同时使用ROI Align替代了ROI pool⁃ing,降低了ROI pooling过程中两次量化过程所带来的误差。
随着RGB−D相机的出现,深度图像所包含的空间信息可以帮助二维RGB图像进行更准确的图像分割。两个在普通RGB图像中有所重叠的目标在三维点云中可以很容易的得到两个目标的距离,并区分两者的类别。文献[7]将深度图像融入CNNs进行语义分割的FuseNet,同时提取出图像中的深度信息与彩色信息,并随着网络的深入将深度信息融入到彩色信息中。文献[8]提出了SCN网络,使用深度图像中提取出对象之间的几何关系来提升图像分割的精度。文献[9]设计了彩色图像与深度图像融合的双金字塔特征融合结构,证明了彩色图像与深度图像融合可以提升图像分割的精度。文献[10]提出了一种结合通道注意力机制的RefineNet网络,针对各个通道不同的重要性提供通道注意力,以增强网络对特征的学习与关注。
综上,这里提出一种通过深度图像获得尺度特征图来对相同形状不同尺寸目标的分类方法。首先通过深度图像与真实语义分割图相结合得到目标在图像上的区域,通过相机的内外参数计算出目标的点云。其次计算目标点云的重心位置并求出点云中每个点到重心的欧式距离。然后将得到的欧式距离作为衡量目标尺寸的尺度映射到一张灰度图像中,作为目标的尺度特征图。最后对尺度特征图进行图像分类,获得目标的精确类别。这里在MASK−RCNN的基础上设计了尺寸分类分支网络,在相同形状不同尺寸的物体中选取较有代表性的标准件制作数据集,以语义分割网络对目标分类的准确率验证方法的有效性,选取最优的参数并与原MASK−RCNN网络的结果进行对比。
3 图像分割网络
3.1 成像原理
如图1 所示,直径150mm 的轴承,如图1(a)所示。直径110mm的轴承,如图1(b)所示。两个轴承尺寸不同但在图像中呈现相同的特征,在没有背景和参照物的情况下很难依据轴承的尺寸辨别其类别。为能够准确的对其进行图像分类,从成像原理的角度出发找寻二者之间的差别。
成像原理,如图2所示。OC为相机坐标系原点,Xc,Yc,Zc分别为相机坐标系的坐标轴,o为图像坐标系原点,x,y分别为图像坐标系的坐标轴。目标中的一点P在相机坐标系与图像坐标系的转换关系为:
式中:K—相机的内参矩阵。
目标上有两点P1,Q1,当目标尺寸放大s倍,目标上的点P1,Q1在相机坐标系中的坐标值也扩大s倍时,放大后的两点P2,Q2在图像坐标系中与P1,Q1具有相同坐标值。所以同理可知形状相同,尺寸不同的物体在不同的摄像机视角下会呈现相同的图像。普通的RGB图像只能得到目标每个像素在图像中的x,y的坐标值,并不能得到Zc的值,所以通过普通的RGB图像无法得知目标在相机坐标系中点云的坐标,也就很难区分在没有参照物的情况下形状相同、尺寸不同的物体的类别。而RGB−D相机可以通过红外信号获得Zc的值,弥补了RGB图像的这一缺点。通过RGB−D相机,可以还原目标在世界坐标系下的点云,以点云中的点之间相互的位置关系可以辨别目标的尺寸大小。如图2所示,P1,Q1与P2,Q2在图像坐标系中具有相同的坐标,但是还原为点云之后通过比较P1Q1与P2Q2的距离就可以区分二者的类别。
3.2 图像的尺度特征图
当相机变换不同的视角时,目标中的点在相机坐标系中的坐标值也随之发生改变,但是因为目标的形状并没有改变,所以目标中的每个点相对目标中其他点的位置关系也没有改变。以目标中的每个点到目标重心位置的距离作为衡量目标尺寸大小的标准,称为目标的尺度特征。将尺度特征映射到一张灰度图像中,称为目标的尺度特征图,其中包含了每个像素的位置及对应点到重心的距离信息。通过RGB图像与尺度特征图的结合更容易区分不同尺寸标准件的类别。深度图结合真实语义分割图(Ground Truth)可以得到目标的每个像素位置和与相机坐标系原点的距离,并将除目标以外的背景像素值置为0。使用公式(1)可以得到目标在相机坐标系下的点云。然后使用公式(2)可以得到目标的重心坐标。
式中:M—目标点云的集合;
Pi—每个点的坐标;
l—点云中点的个数。
再使用式(3)计算目标点云中每个点到重心的距离。
式中:角标i= 0,1,2—x,y,z轴。
将得到的距离值作为尺度特征映射到一张灰度图像中,作为目标的尺度特征图。目标的尺寸越大,与重心的距离越远,尺度特征图中的值也就越大,相反尺寸越小,尺度特征图中的值就越小。直径150mm 和110mm 的轴承的尺度特征图,如图3 所示。从图像上较容易比较二者的尺寸大小。

图3 尺度特征图Fig.3 Scale Feature Map
3.3 结合尺度特征图进行图像语义分割
3.3.1 网络架构
语义分割指在图像中的每个像素进行分类,将同一目标的像素归为一类,并标注该目标的类别、位置及目标所在的所有像素。而在语义分割的过程中,形状相同、尺寸不同的目标因为特征相似常常会被归为同一类别,很对目标的尺寸进行判断并分为不同的类别。这里主要针对相同形状、不同尺寸的目标较难分类的问题,提出了结合深度图像的语义分割网络架构,如图4所示。该网络在MASK−RCNN 图像分割网络的基础上,添加了尺寸分类分支网络结构,对相同形状、不同尺寸的目标进行语义分割。
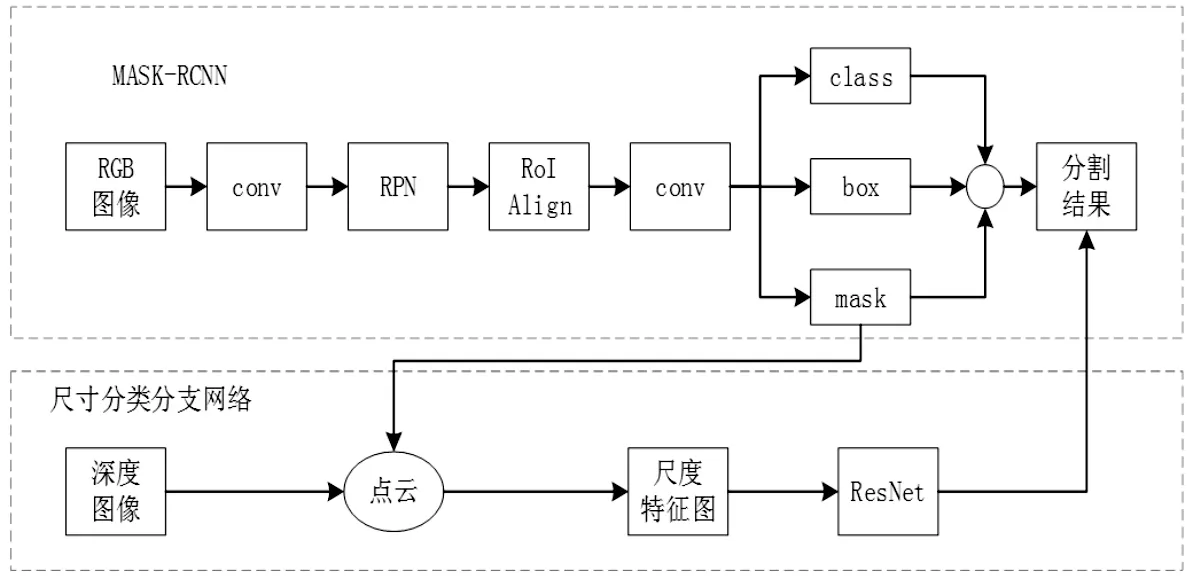
图4 网络结构Fig.4 Network Structure
网络中的骨干网络为ResNet−FPN,对输入图像进行多尺度的特征提取,并将提取出的特征根据预选框的位置坐标使用RoiAlign将相应区域池化为固定尺寸的特征图,以便进行后续的分类、包围盒和分割任务的回归操作。之后通过MASK−RCNN的box分支、class分支、mask分支分别预测目标的包围盒、类别和分割图。在进行数据集制作时先将有具有相同形状的不同尺寸性质的目标归为同一个类别,没有相同形状的目标自己归为一个类别,具有相同形状的不同尺寸性质的目标的类别下每个尺寸的目标再分为一个子类别。训练时使用真实语义分割图获得每个目标所在的像素位置,先对每个类别进行训练,获得每个类别的语义分割模型。再根据真实语义分割图在深度图上获得每个子类别的像素位置,并转化为尺度特征图,使用ResNet[11]训练分类模型。预测时若没有相同形状的目标则直接输出目标的类别,若有相同形状不同尺寸的目标则结合mask分支的结果与深度图转化为点云,进而得到目标的尺度特征图,通过尺度特征图的分类模型对目标进行再分类,得到目标的具体类别。
为简化运行过程,在训练的过程中并不需要真的生成尺度特征图像再读取进行分类,只需要在数据预处理的过程中得到目标的尺度矩阵,并送入ResNet网络进行分类。为增强特征提取效果,减少像素值为0的背景部分,截取包含目标在内的(100×100)像素进行训练。因为输入是单通道的,所以将ResNet的输入改为1。
3.3.2 损失函数
损失函数通常用来计算真实概率分布与预测概率分布之间的差异,得到的值越小代表训练的效果越好。在对目标的尺度特征图进行分类时,目标只占图像的一小部分,其余均为像素值为0的背景,这样很容易出现类别不平衡的问题。使用普通的交叉熵函数时,背景部分分错的概率很大,负样本占的比重太大,很难使loss降至最优。而Focal loss[12]可以通过调节调制系数控制正负样本的权重,使其更注重对目标样本的训练,所以选用Focal loss计算目标分类过程中的损失。
4 实验
4.1 实验环境与配置
实验基于Ubuntu16.04系统与pytorch1.0深度学习框架进行开发,使用显卡为GeForce1660。
为检测标准件在简单背景下的图像语义分割,制作标准件数据集,数据集包括三种常见的标准件:轴承,齿轮,轴,每类标准件有多个不同大小的零件。数据集使用KinectV2深度摄像头采集标准件的彩色图与深度图。制作数据集时设置图像尺寸为(424×512)像素,每张图像包括最少两个零件,最多五个零件,共采集600张图像。使用labelme标注工具制作数据集的标签作为标准的真实语义分割图,并给予每一种零件一个颜色通过像素值分辨其类别,每一种零件的标签像素值,如表1所示。将600张图像随机分配,400张作为训练集,200张作为验证集。

表1 真实语义分割图像素值Tab.1 Real Semantic Segmentation Image Prime Value
4.2 训练方法
在数据预处理时,根据标准的真实语义标签的像素值获得每一个目标的像素位置,并与深度图像相结合获取轴承与轴的尺度特征图。在训练模式下,先使用MASK−RCNN 对轴承、齿轮、轴这三个类别进行训练,获得语义分割模型。再在每个轴承与轴的类别下使用得到的尺度特征图送入再分类分支网络训练尺寸分类模型。在验证模式下,齿轮直接使用语义分割模型预测其类别,轴承和轴通过语义分割模型预测的mask与深度图像结合获得尺度特征信息,后再通过尺寸分类模型预测其具体类别。
图像输入为(424×512)像素,得到的尺度特征图尺寸较大且大多为像素值为0的背景,所以使用Opencv2中的boundingRect函数截取目标所在的位置的(100×100)像素的矩形,训练过程中的batch size为4。
初始学习率设置为0.001,使用随机梯度下降法进行梯度更新。每训练20个epoch进行一次验证,计算验证后的准确率,并更新最高的准确率。实验共迭代2000个epoch,保存最终的结果模型。
这里使用语义分割过程中的标签分类准确率作为评估标准。
4.3 实验结果分析
MASK−RCNN与这里添加了尺寸分类分支网络的语义分割网络的语义分割结果对比,如图5所示。

图5 语义分割结果对比Fig.5 Comparison of Semantic Segmentation Results
MASK−RCNN语义分割的结果,如图5(a)~图5(c)所示。通过结果可以看出对于标准件的语义标签输出为目标类别下的第一个子类别,也就是说MASK−RCNN将特征相同、尺寸不同的物体归为同一类物体,并不能依据目标的大小对其进行分类。在MASK−RCNN的基础上添加了尺寸分类分支网络的语义分割结果,如图5(d)~图5(f)所示。通过与深度图的结合,复杂背景下的多目标与无背景的可以正确的区分不同大小的标准件的类别。在深度学习的过程中,随着网络层数的增多虽然可以提取更多的特征信息以提高其泛化能力,但是网络层数过多往往会发生梯度消失或者梯度爆炸的问题。而ResNet残差网络通过残差块的跳跃连接,使上一层网络的信息之间流入下一层,提高了信息的流通,避免了梯度消失或者梯度爆炸的问题。
为了选取最适合这里所标注的标准件数据集的ResNet网络层数,分别使用ResNet18,ResNet50,ResNet101 三种深度的ResNet网络模型进行实验,语义分割的标签分类准确率结果,如表2 所示。从表中可以看出,以ResNet50 的网络模型准确率最高,而ResNet101在标准件数据集上发生了过拟合现象,准确率有所下降。因此将ResNet50网络模型作为后续实验的基准。
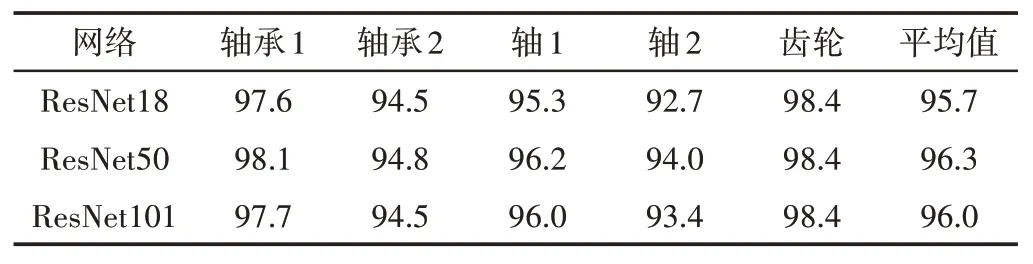
表2 分类准确率Tab.2 Classification Accuracy
为了验证focal loss 提升的准确率效果,使用交叉熵函数与focal loss分别进行训练,准确率的结果,如表3所示。可以看出使用focal loss对分类结果的准确率有一定的提升。

表3 不同损失函数的准确率Tab.3 Accuracy of Different Loss Functions
5 结论
相同形状、不同尺寸的物体在图像上会呈现相同的特征,仅使用RGB图像很难得到目标的正确的语义标签。这里提出了以尺度特征图区分相同形状、不同尺寸目标类别的方法,通过深度图像结合真实语义分割图获得目标的点云,求出点云的重心以及每个点到重心的距离,映射到灰度图像中得到尺度特征图。尺度特征图以每个点到重心的距离作为衡量目标大小的尺度,对目标进行分类,得到不同尺寸的目标的具体类别。基于尺度特征图的特点,在MASK−RCNN的基础上添加了尺寸分类分支网络,实现了对相同形状、不同尺寸物体的准确的语义分割,在自制的标准件数据集上讨论了最优参数的选取,达到了96.3%的分类准确率。但是在有遮挡的情况下计算的重心位置受到影响,导致分类准确率下降,还需要进一步研究。
猜你喜欢
机械工业标准化与质量(2022年4期)2022-08-12
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
太空探索(2016年5期)2016-07-12
新校长(2016年8期)2016-01-10
汽车零部件(2014年5期)2014-11-11
时代英语·高三(2014年5期)2014-08-26
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
组合机床与自动化加工技术(2014年12期)2014-03-01
中国质量与标准导报(2014年1期)2014-02-28
