
基于特征学习的5G用户投诉根因定位方法
2023-08-08 10:22:38岳烈骥吕程程
信息通信技术 2023年3期
岳烈骥 孙 伟 侯 普 吕程程 陈 凯
1 中国移动通信集团北京有限公司 北京 100027
2 中国信息通信研究院 北京 100191
引言
5G时代随着用户和设备规模的持续上升,多网络融合、多设备互联、多业务并发,5G得到越来越广泛的应用[1]。与此同时,5G网络的复杂性也在持续增加,故障所造成的影响范围也越来越广。实际业务中,针对5G网络的运维,存在故障发现被动、根因定位困难等一系列问题,各专业运维支撑系统面临开发周期长、闭环流程自动化程度低的技术瓶颈,难以做到主动维护和根因自动定位。在日常网络运维中,依靠人工处理的传统方式,存在分析工作量大、投诉根因定位难、跨部门沟通成本高等问题,特别是复杂故障场景下往往需要多次上站排查才能找到故障根因,费时费力,对于VIP站点或重点保障站点,一旦发生故障容易引发关键用户投诉。由于5G投诉涉及终端、锚点、5G站点等各种因素,迫切需要形成一套统一标准的5G投诉定位流程,提高5G投诉分析效率,并最终基于5G投诉根因情况监控全网质量波动,持续提升移动网络的质量和端到端的运营能力[2]。
近年来,大数据、深度学习等技术的发展推动了人工智能产业的进步,人工智能在各行各业都取得了落地应用的成果。大数据分析和机器学习是实现人工智能的重要技术手段。本文利用大数据分析、特征工程和无监督机器学习算法,根据历史用户投诉信息、投诉地点周边站点状态、规划站点情况以及用户常驻站点、4/5G流量驻留比、异常事件、关键性能指标等数据,使用人工智能机器学习算法,构建特征指标和根因之间的关系模型,快速定位5G投诉的根因,实现5G用户投诉处理的自动化和智能化。
1 用户投诉关键性能指标筛选
1.1 5G投诉关联基站匹配
在业务系统中收集历史5G用户投诉工单,对于每份投诉工单,提取投诉的时间和地点信息,其中地点信息包含投诉时刻经度和纬度的坐标值。根据包含所有基站经纬度坐标、方位角信息的工参数据,基于距离和方位角两个维度,定位出每份投诉工单关联的基站。距离阈值设置为500米,方位角阈值设置为正负30度。用户投诉位置和基站之间的距离使用Haversine公式[3]进行计算:
用户投诉位置和基站之间的方位角计算方式为
1.2 5G投诉关键特征筛选
针对每份5G投诉,基于距离和方位角两个维度查找出投诉时刻的关联基站,进一步地,对于每个关联基站,提取基站的特征指标数据,构建5G投诉特征指标候选集合,如图1所示。
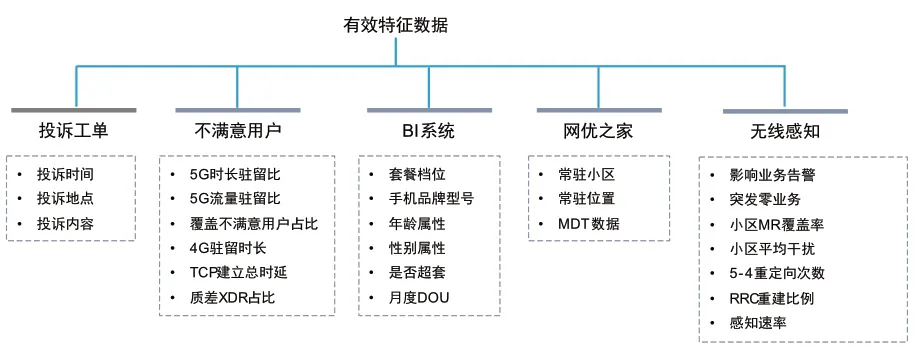
图1 特征指标候选集合示例
特征指标候选集合具体包括投诉工单265个特征、5G不满意用户22个特征、5G BI系统313个特征和无线感知540个特征。
结合常驻地点数据、业务专家经验以及统计科学中的信息增益准则和皮尔逊自相关分析算法[4],从5G投诉特征指标候选集合中筛选出指标候选子集。
信息增益准则基于信息熵的概念,随机变量的信息熵定义为:
熵的大小只依赖随机变量X的分布,而与的取值无关,随机变量的不确定性越大,其计算出的熵值越大。信息增益表示得知特征的信息而使得基站类别信息的不确定性减少的程度,根据特征和基站类型的信息增益值进行排序,筛选出信息增益大的特征指标。
皮尔逊相关系数是用来检测两个连续型变量之间线性相关的程度,计算公式为:
根据上述筛选准则,筛选出相关性高的128个特征指标,构成特征指标候选子集。进一步地,使用随机森林算法模型[5]收集关键性能指标集合。具体地,收集1 000个投诉关联基站和1 000个正常基站的指标数据,构建出包含128项特征维度的2 000例样本,构建随机森林模型,预测数据集中的每个样本的类别,判定该样本属于正常基站还是投诉关联基站。训练随机森林模型直至模型收敛。模型训练结束后,将128项性能指标按照随机森林模型给出的特征重要性得分进行排序,最终筛选出和5G投诉强相关的34项性能指标。筛选出的性能指标以及各自的权重值,如图2所示。

图2 5G投诉关键特征指标示例
2 异常指标定位模型构建
对于每条5G投诉关联的基站,从业务系统数据库中收集投诉时刻的34项关键性能指标数据,并从中定位出异常指标集合,结合业务专家经验,得出投诉的根因。对于异常指标的定位,在综合评估比较各个算法模型的性能之后,选择采用无监督[6]的孤立森林[7]机器学习算法模型。
收集5 000条投诉关联基站在投诉当天的34项特征指标数据,另外再收集5 000条其它正常基站在任意某天的34项特征指标数据,构建出包含10 000个元素的数据集S。在数据预处理上,对于数据集中的缺失值,采用正常基站的均值进行填充。
基于数据集S,随机构建100棵独立的二叉树。对于每颗二叉树,在10 000个训练样本中随机选择1 000个样本,放入树的根节点中。在34项特征指标集合中,随机选择一个特征指标F,在F的数值范围中,随机产生一个切割点p,如果某个样本在F特征指标上的值小于p,则将该样本分配到节点左子树中,反之,分配到节点右子树中。递归重复上述过程,直至无法再进行切割,或者达到二叉树预设的20的高度。100棵二叉树构建完毕后,即构建出检测异常指标的孤立森林模型M[8]。图3给出了模型构建的整体算法流程。

图3 异常指标定位模型算法流程
对于每个样本X,将X输入进孤立森林模型M,计算X的得分,计算公式为:
其中E(h(X)) 表示样本X在孤立森林模型M中的平均高度,n表示构建每颗树的样本数量也即1 000,c(n)的计算方式为:
其中H代表谐波函数[9]。如果S(X)的得分大于0.8,判定X为异常基站指标数据,反之判定X为正常基站指标数据。对于异常基站指标数据X,计算所有100棵树的平均高度EM,并筛选出路径长度低于0.2×EM的叶子节点,这些叶子对应的特征指标,即为X中的异常指标集合。
3 用户投诉根因定位流程构建
对于每条5G用户投诉,基于距离和方位角两个维度查找出投诉时刻的关联基站,提取出关联基站的34项特征指标数值,输入进异常指标定位模型M,预测得出异常指标集合。对于模型预测出的异常特征指标,根据业务专家规则,转换得出5G投诉的根因。图4给出了根据异常指标定位5G根因的规则流程。
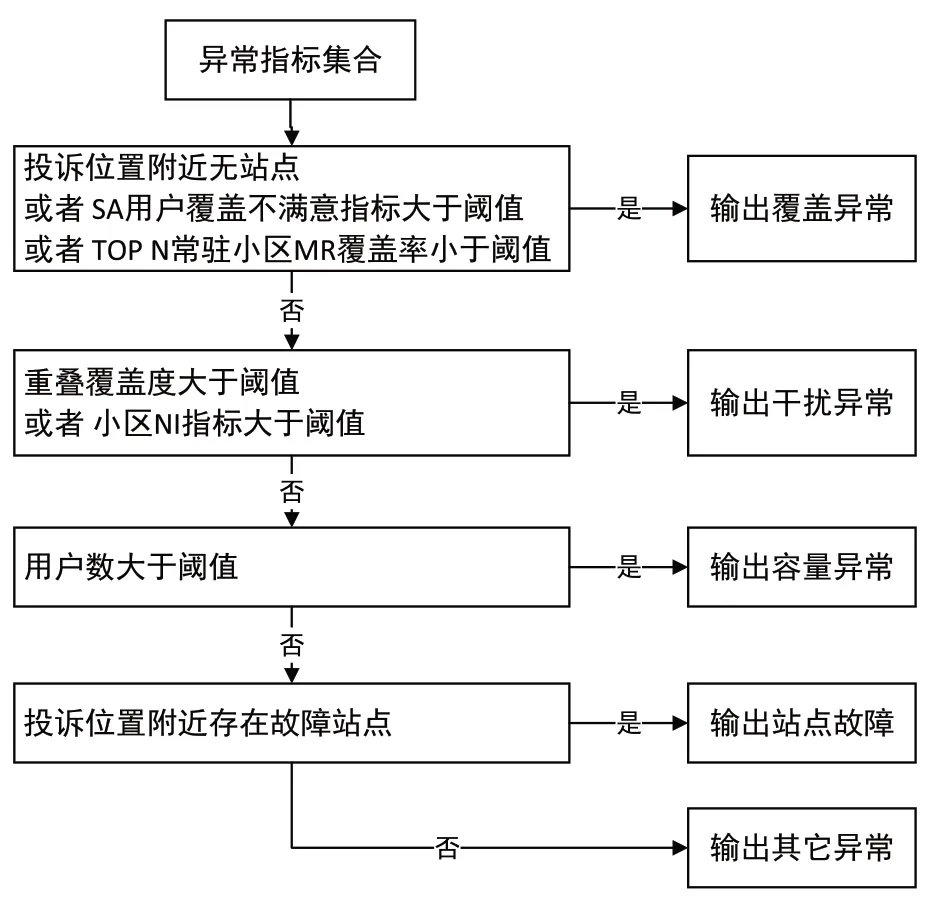
图4 异常指标和投诉根因关联规则
对于覆盖异常根因,基于投诉位置附近有无站点、SA用户覆盖不满意指标和Top n常驻小区MR覆盖率三个因素进行判定。对于投诉位置附近是否存在站点,根据用户投诉的经纬度位置和工参表中所有5G站点的经纬度位置,计算用户投诉一定距离范围内是否存在站点,如果投诉位置附近不存在站点,则判定为覆盖异常根因。对于SA用户覆盖不满意指标,计算SA用户覆盖不满意指标是否大于阈值,其中阈值由数据集S中正常基站的SA用户覆盖不满意指标的均值计算得出。对于Top n常驻小区MR覆盖率,计算Top n常驻小区MR覆盖率是否小于阈值hmr,阈值hmr由数据集S中正常基站的MR覆盖率指标的均值计算得出。满足上述三者中任何一项,判定5G投诉根因是覆盖异常。
对于干扰异常根因,基于重叠覆盖度和小区NI指标两个因素进行判定。对于重叠覆盖度,判断异常特征集合中重叠覆盖度指标是否大于阈值hoverlap,阈值hoverlap由数据集S中正常基站的重叠覆盖度指标的均值计算得出。对于小区NI指标,判断小区NI指标是否大于阈值,阈值由数据集S中正常基站的NI指标的均值计算得出。满足上述两者中任何一项,判定5G投诉根因是干扰异常。
对于容量异常根因,判断异常特征集合用户数指标是否大于阈值hnum,阈值hnum由数据集S中正常基站的用户数指标的均值计算得出。如果大于阈值,判定5G投诉根因是容量异常。
对于站点故障根因,根据故障站点表中的站点经纬度位置,判断投诉位置附近是否存在距离小于500米的故障站点,如果存在,判定5G投诉根因是站点故障。
上述四个条件均不满足,判定5G投诉根因是其它异常。
4 结束语
文章给出了5G用户投诉根因定位方法,方法包括5G投诉关键指标集合筛选、异常指标定位模型构建、异常指标和投诉根因转换规则构建等流程。验证阶段,选取6 564个5G投诉工单,5 384个正常的模拟工单,构建出11 948个测试工单集合。对于每个工单,根据工单中的经纬度信息,按照方法流程预测得出5G投诉根因,并以人工定位的结果作为基准,进行准确率的验证,其中10 428单和人工定位的结果一致,定位准确率为87.3%。表1展示了模型在各个根因类别上的预测结果。

表1 用户投诉根因定位各个类别准确率
该方法上线投入实际应用之后,通过对接网优基础数据库,对于每条5G投诉拉取关联基站指标数据输入进模型,并基于模型的预测结果和转换规则得出用户的投诉根因,将结果输出进EMOS平台派发工单流转至分公司优化解决,同时基于5G投诉感知根因情况监控全网质量波动,持续提升了5G的服务质量。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23 00:30:46
电子测试(2022年7期)2022-04-22 00:13:16
高技术通讯(2021年6期)2021-07-28 07:39:20
电子制作(2019年14期)2019-08-20 05:43:42
国际呼吸杂志(2019年1期)2019-01-28 09:37:02
电子技术与软件工程(2017年18期)2018-01-28 21:57:03
中国卫生产业(2017年16期)2017-07-20 10:22:21
中国核电(2017年1期)2017-05-17 06:09:55
中国自行车(2017年1期)2017-04-16 02:53:52
故事会(2016年21期)2016-11-10 21:15:15
