
基于LightGBM算法的5G用户预测及5G网络规划
2023-08-08 10:22:40李海昕张娇娇
信息通信技术 2023年3期
李海昕 张娇娇 王 雨 王 一
中国联通研究院 北京 100176
引言
运营商在进行网络规划及部署方面,终端分布是一个不可或缺的重要因素。随着5G的正式商用,5G终端的相关数据也得到一定的积累。深入挖掘终端数据背后的信息,利用大数据技术和手段指导规划工作是大势所趋,也是数字化转型时代的要求。大数据处理和分析为网络规划提供了新的维度,也为精准网络规划提供了新的可能。通过对终端相关的业务数据进行地理化分析,合理评估站点规划的优先级,对于有效触达亟待5G网络部署的区域,引导资源的准确投放有一定的指导意义。因此,在5G网络规划部署中,如何精准预测潜在5G终端用户、准确聚焦其分布的高流量、高语音区域具有重要意义。在此背景下,潜在5G终端用户的预测对存量用户经营以及端、网、业协同规划发展具有重要的作用。
本文使用用户侧B域、O域、终端更换以及用户行为等数据,筛选对5G终端迁转影响较大的特征,进行二分类建模,确定最优模型。将现网待预测用户输入至最优模型中,获取潜在5G终端用户列表,作为目标5G终端用户,根据潜在5G用户的详单数据统计在不同微网格、基站等地理维度的业务分布以及人口密度情况,为5G网络的规划建设提供数据支撑。
1 现有的潜在5G终端用户预测方法
5G商用初期,5G终端用户样本较少,不足以支撑模型构建,文献[1]利用趋势外推的方法对5G用户及业务量进行预测。文献[2]开始考虑5G用户特征,但只能基于专家经验下的数据分析得到。随着用户渗透率的增加,5G终端用户的业务特征有所变化,同时考虑到千元机上市等因素,在文献[2]的基础上,将潜在5G用户的判定门限进行如下调整:1)用户ARPU≥70元;2)用户终端价格≥2 000元;3)用户到达换机周期。
本文采用中国联通某地市2019年12月的部分4G、5G终端用户数据,对半年后即2020年6月5G终端用户进行预测,在此期间共新增15.2万5G终端用户。为了便于与后文中模型法相比较,本文采用二分类模型评价指标Recall(预测效果)和Precision(预测效率)。在表1中,Recall代表真实正例样本中,预测为真的样本比例,即1.9/15.2=12.5%;Precision为精确率,指的是从预测的角度看有多少样本是预测准确的,即为1.9/24.8=7.6%。

表1 专家经验预测混淆矩阵结果
若采用当前结果做网络规划,12.5%的准确率偏低,地理分布的偏差较大,无法精准地引导投资。随着后期样本量的增加,5G终端的数据可以支撑LightGBM算法建模的方法,本文提出基于LightGBM算法的模型搭建,对潜在5G终端用户预测进行研究。
2 基于LightGBM算法的4G、5G终端用户二分类模型
本文对用户是否迁转5G终端进行研究,属于监督学习中典型的二分类问题。本章节就分类算法、建模过程以及建模结果进行介绍。
2.1 相关分类算法介绍
在当前流行的分类算法中,LightGBM算法是预测准确率较高且训练速度较快的算法。其他分类算法有Bagging算法中的随机森林(Random Forest)、Boosting算法中的梯度提升树(Gradient Boosting Decision Tree,GBDT)、XGBoost算法等。这些算法都是以决策树模型为基础。GBDT算法是被公认的泛化能力较强的算法,核心就在于每一轮的迭代都是在上一轮迭代产生的残差基础上进行。在GBDT算法的基础上,对损失函数进行改进就有了XGBoost算法,它可以支持并行运算,用于加速和减小内存消耗。在XGBoost之后,微软公司又提出了LightGBM算法。它使用了带有深度限制的按叶子生长算法,可以加速训练过程,减少计算量。此外,LightGBM算法支持高效率的并行运算,支持分布式海量数据处理,能够降低内存消耗,拥有更高的准确率。因此,这里选择基于LightGBM的机器学习算法预测用户半年后是否迁转5G终端,图1是LightGBM部分算法过程示意。关于分类算法更为详细的介绍可见文献[3-6]。

图1 LightGBM部分算法过程示意
2.2 建模过程
本文整个建模的流程框架如图2所示,整个算法主要分为三个模块:数据处理模块、模型构建模块以及预测应用模块。
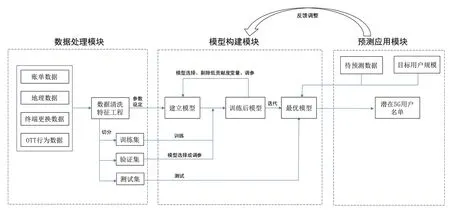
图2 潜在5G用户预测建模流程
数据处理模块主要分为基本数据源、对基本数据进行数据清洗和特征工程两个内容。基于专家经验法同样的数据,筛选2019年12月存量4G、5G终端用户作为模型的Y结果,选定这些用户在2019年4月、5月、6月的数据,作为模型的因变量X,预测用户在半年之后是否会迁转5G终端。自变量的数据主要包括:1)账单数据,含有用户流量、语音、消费等业务使用数据;2)地理数据,含有用户常住地等地理分布相关数据;3)终端数据,含用户使用终端及更换情况的数据;4)OTT数据,指用户使用各类APP业务情况数据,这些数据是建模的基本数据。
在基本数据的基础上,进行数据预处理。对单一值数据的特征剔除,删除缺失值超过70%的特征,针对缺失值较少的数据用常数或者聚合值进行填充等。为了充分挖掘数据的信息,使用特征工程将原始数据转化为能更好地表达问题本质的特征。针对数值型特征进行统计计算。对分类特征进行独热编码转换,最后对数据进行特征筛选等处理。
数据处理完成之后,为了进行模型训练以及模型泛化能力的评估,需要对数据进行拆分。随机选取80%的数据作为训练集,用于模型训练,10%数据作为验证集,用于模型的超参调优和迭代,剩下10%的数据作为测试集,用于验证模型的泛化能力。
模型构建模块其实是一个根据训练集和验证集反复进行超参调优、不断迭代构建最优模型的过程。选择训练集数据,设置初始参数,模型根据自变量X和因变量Y学习,得到训练模型,剔除低贡献度变量,再次训练,得到训练后的模型。利用验证集数据和网格搜索的方法反复修正参数,不断迭代,找到一套对输入数据高度识别的最优配置参数和具有一定泛化能力的最优模型。
在模型预测中,会输出这个样本成为正例即成为潜在5G终端用户的可能性。在实际操作中大多为不平衡的样本,需要设定一个确定的阈值,来判断用户是否会迁转5G终端。在模型评价指标中,Recall表征真实5G用户中被正确找到的比例,值越大说明预测效果越好。Precision值可以表征所有区域或者站点中覆盖到的真实用户的比例,同等建设规模的情况下,值越大说明建设区域覆盖到真实的5G用户越多,预测效率越高。这两个值均越大越好,但实际应用中二者关系是遵循P-R曲线的。根据阈值可以找到某一点平衡,该点的Precision和Recall值即为网络规划方案预计将达到的预测效率和预测效果。
2.3 模型结果
图2中的模型应用模块,主要是利用在模型构建模块建立好的最优模型,输入待预测的数据和目标用户规模,获得在一定时间段内可能迁转为5G终端用户的列表。
2.3.1 建模法结果
基于专家经验法同样的数据,对比2020年6月真实5G终端用户,从表2的结果中可以得到,预测结果的Recall值为67%,Precision值为7%,在精确率一致的情况下,预测效果大有提升。

表2 建模法预测混淆矩阵结果
2.3.2 建模法与专家经验法对比
通过表3可知,LightGBM算法建模法与专家经验法相比有诸多优势。直观表现在建模法使用较多的特征,从而充分挖掘数据对于判断用户更换5G终端的影响,预测效果大幅提升。此外,建模法会通过学习,灵活确定不同特征的判断门限,针对不同的用户有不同的判定路径,最终根据多棵决策树进行判定。专家法对所有户的判定方法都是一致的,且判断的门限都是固定的一刀切方法。在预测用户规模方面,专家经验法的预测规模是固定的,而建模法由于输出结果是用户成为潜在5G终端用户概率,在选取判断阈值时则可以根据倾向预测效果和预测效率的不同机动选取用户规模。

表3 专家经验法与建模法的对比表
2.3.3 预测结果跟踪
在确定LightGBM算法方法之后,本文对该地市的潜在5G终端用户进行了更深一步地预测分析。以2020年8月的4G、5G终端用户为目标群体,提取上述用户在一年之前(即2019年8月)的自变量数据,基于LightGBM算法进行二分类建模,经过数据预处理、模型建立、超参调优等过程获取最优模型。将待预测的2020年8月4G终端用户数据输入至最优模型,预测一年之后可能迁转为5G终端的用户。本文对得到的潜在5G用户进行了为期一年的跟踪,在一年时间点时(即2021年8月)与当时的真实5G终端用户数据进行了对比。
同样采用预测效果和预测效率两个评价指标,这里只针对模型预测得到潜在5G用户群体进行跟踪,即不考虑时间段内新增的5G终端用户以及当前已有的5G终端用户的影响。在表4中,以一年时间点时真实的5G终端用户为基准,对标Recall来看,模型的预测效果为67.4%,与2.3.1节中的67%持平。在表5中,以模型预测得到的203万潜在5G用户为基准,对标Precision来看,预测效率为30%。对比2.3.1节中的7%有了较为明显的提升,在用户渗透率提升的情况下,预测效率会有一定提升。

表4 跟踪数据预测效果

表5 跟踪数据预测效率
3 模型应用
基于预测得到的潜在5G用户群体,考虑其工作常住和住宅常住的微网格分布,可以得到用户的总常住微网格分布。根据用户在常住微网格的地理业务分布数据,例如考虑用户数分布数据,对微网格的建设优先级进行排序判断,得到不同优先级的网络建设区域,从而指导网络规划。图3是按照用户在常住微网格上的分布聚集程度,将用户聚集最多的前25%微网格价值评级记为1,前50%用户聚集的微网格价值评级记为2,前80%用户聚集的微网格价值评级记为3,剩下的微网格价值评级记为4。分别对应图中的红色、黄色、绿色和蓝色区域。从地图中可以清晰地看到,建模法得到的潜在5G用户微网格评级结果与真实的5G用户总常住微网格评级结果更一致。

图3 建模法(左)、真实5G用户(中)、专家经验法(右)常住地评级结果
同样地,也可以根据业务需求,汇总每个微网格下的地理业务分布数据,如流量、总业务次数等,按照倒序排列,基于上述同样的评级方法得到不同指标下的微网格评级结果。表6对比了建模预测得到的潜在5G用户以及真实5G用户两类用户群体在不同指标下微网格评级一致性,两类用户群体在流量、业务次数、工作常住和总常住的分布评级一致性都在90%以上。在应用过程中,可以根据实际需求,对多种维度地理分布数据计算不同权重得到微网格价值评级的估计值,此处的微网格也可以替换为基站等。

表6 真实5G用户与建模预测的潜在5G用户分布评级一致性结果
4 总结与展望
本文提出了一种基于大数据分析和LightGBM算法的潜在5G用户预测方法,基于B域数据、O域数据、终端更换数据以及用户行为数据建立用户是否更换5G终端的二分类模型。此方法能充分挖掘特征数据对用户更换5G终端的影响,预测准确率较高。将现网待预测用户输入模型中,筛选出潜在5G终端用户列表,一方面根据预测得到的潜在5G用户的业务分布及常住地等确定5G网络需建设的重点区域,应用于5G网络的规划,另一方面可以根据现阶段的用户规模,为精准营销提供数据支撑。
在后续的研究中,可以继续增加数据,比如影响用户网络感知的数据或者与5G业务相关的数据等,增加数据的多样性。在数据预处理、参数调优等方面持续优化算法,例如交互特征、奇异值分解、主成分分析降维等,一方面是为模型“瘦身”,提取对结果影响较大的特征,另一方面提升预测的准确度。本文提出的方法也可应用其他的专题分析,比如用户对5G套餐、5G升级包的多分类预测模型等其他电信业务场景。除此以外,针对海量数据,可以考虑利用神经网络等深度学习算法建模,充分挖掘隐藏在海量数据背后的“有益”信息,推进终端、网络、业务的协同发展。
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11 03:18:56
现代装饰(2020年8期)2020-08-24 08:22:58
铁道通信信号(2019年9期)2019-11-25 01:44:58
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:40
北京航空航天大学学报(2017年6期)2017-11-23 05:57:36
电子制作(2016年15期)2017-01-15 13:39:14
浙江大学学报(工学版)(2016年10期)2016-06-05 09:20:56
中国市场(2016年14期)2016-04-28 09:25:26
中国新通信(2016年2期)2016-03-11 08:17:48
电子技术应用(2015年9期)2015-12-14 06:10:26
