
基于遗传优化算法的井底钻压智能预测模型
2023-08-07 11:48吴泽兵谷亚冰姜雯张文溪胡诗尧
石油钻采工艺 2023年2期
吴泽兵 谷亚冰 姜雯 张文溪 胡诗尧
西安石油大学机械工程学院
0 引言
随着现代油气钻探技术的发展,水平井钻井成为提高油气开采效率的关键手段[1]。众所周知,钻柱在弯曲段和水平段与井筒接触,由于钻柱与井筒间会产生摩擦,因此,从地面到井底会产生扭矩与摩阻损失[2]。同时钻井效率主要取决于钻头的性能,钻头性能主要通过机械钻速来评定,而井底钻压是影响机械钻速的主要参数。摩阻损失意味着难以准确地施加钻压,事实上,井底钻压的精确值与近似值都是未知的,但油气的开发需要大量的大位移井、大斜度井,而摩阻损失已成为大位移井、大斜度井钻井的制约因素。
对于水平井、大位移井等比较复杂的结构井,尤其是大斜度井段以及长水平段摩阻较大,不易施加准确的井底钻压[3-6],若钻压太小,则导致破岩效率较低,钻压太大,钻头牙齿及轴承会受到强烈的冲击破坏,影响岩石破碎,并且钻压还会影响机械钻速,增加钻井难度[7-9]。因此准确又快速地预测井底钻压非常有必要。精确的钻压值不仅对钻头工作性能与钻井成本有影响,而且还有利于钻井的可行性评估、实时钻井分析、钻井作业优化,最大限度的减少钻柱的突发故障,实现自动钻井[10]。
目前国内外学者已经对井底钻压预测进行了大量的分析与研究[11-12]。邵冬冬等[13]通过水平井的井底钻压波动实验,得出真实的井底钻压与名义钻压值近似,且水平井的井底钻压呈正弦波动趋势。吴泽兵等[14]开发C#程序,结合Johancsik 模型与Aadnoy 3D 模型并且考虑了管柱刚度,建立了新型摩阻扭矩模型计算摩擦因数与井底钻压。Awadalla 等[15]采用径向基函数神经网络来预测井底压力,并用前馈神经网络等进行模拟实验与定性比较。Wu 等[16]建立了水平井的三维解析模型预测井底钻压,并且为提高计算速度还建立了井底钻压与地面钻压之间关系的最小二乘拟合(LSF)模型。朱硕等[17]结合摩阻的刚杆模型用二分法反演摩阻系数,利用神经网络模型计算井底钻压与扭矩,选取最优预测模型的平均相对误差为12.8%。孟卓然等[18]提出了使用综合多性能指标的控压钻井的非线性模型的预测方法。Zhu 等[19]结合反向传播(BP)、长短期记忆(LSTM)模型等建立混合神经网络模型预测井底压力。虽然上述方法使用神经网络算法取得了不错的预测结果,但是由于没有使用优化算法可能会使网络在训练过程中陷入局部最优解。
近年来,随着人工智能在各领域的应用和发展,将深度学习应用于钻井作业已成为关注的焦点。笔者选用BP 神经网络[20]与LSTM 智能预测模型[21-22],并加入遗传优化算法[23-24],建立GABP[25]与GA-LSTM[26]网络模型,构建基于各项钻井参数的井底钻压实时预测模型,并与单一的BP 模型和LSTM 模型井底钻压的预测结果对比,从中选取最优模型,可将其用于钻井分析、井底钻压实时监控、增强自动送钻功能等。
1 神经网络原理
1.1 BP 神经网络
BP 网络由正向传递和反向传递两个过程组成,在输入层与输出层之间添加若干个隐藏层以及非线性激活函数,每个隐藏层有多个神经元细胞,其学习过程通过不断训练,根据损失函数计算网络中所有节点的梯度信息,根据计算出的梯度信息更新权重值,由若干个输入向量与其对应的输出变量从而训练一个逼近于期望值的网络。BP 网络模型的计算公式为
式中,yt为当前输出;f为激活函数;wh为隐藏层间的权重;xt为当前序列的输入数据;bh为偏置矩阵。
BP 神经网络通常会根据问题选择特定的损失函数,通过计算模型预测值与真实标签之间的误差来反映模型的拟合程度,然后通过反向传播来更新模型中每个节点的权重值,从而更新模型参数使模型趋于收敛。其模型的最大优势在于灵活的网络结构和强大的非线性拟合能力、容错能力,能很好地适应内部结构较为复杂的问题。
1.2 LSTM 网络
LSTM 模型属于一种特殊的循环神经网络(RNN),通常用于解决深度学习领域中的时序问题。通常RNN 模型可以理解成一种特殊的前馈神经网络,由于其拓扑结构较为简单且不具备长期记忆的特点,所以很难学习到具有长期特征的信息。而LSTM 中包含了一种特殊的隐式单元使得模型具备长期记忆功能,从而使模型可以将短期记忆与长期记忆相结合,同时还能避免因模型参数量过大而引起的梯度消失和梯度爆炸等问题,有效弥补了经典RNN 模型的不足。
LSTM 模型单元中采用了一种门控制机制来控制特征的流通和损失,同时将多个LSTM 单元串联组成一个具有长期记忆的链式网络结构。通过一系列的门控制器来决定特征信息的流通状态,从而实现特征信息的长期记忆功能。一个LSTM 单元中包括3 个门结构,即遗忘门ft、输入门it和输出门ot以及当前时刻记忆单元状态Ct。
遗忘门ft是一个包含多个元素的特征向量,其中每个元素值均位于[0,1]范围内,使用sigmoid 函数对上一个神经元的输出ht-1与本单元输入值xt-1进行激活,通过判断sigmoid 函数的输出结果来决定上一个神经单元Ct-1中丢失的信息量。ft的计算公式为
式中,σ为sigmoid 激活函数;Wf和bf分别为线性变换关系的权重系数和偏移值;ht-1为上一序列的隐藏状态;xt为当前序列的输入数据。
输入门it与tanh 函数结合可以控制新信息的加入。输入门通过一个[0,1]内的值来控制信息被加入的程度,同时产生了一个新的记忆单元Ct。输入门it和信息候选状态的计算公式为
式中,Wi、bi为输入门的权重系数和偏移值;Wc、bc为当前记忆单元的权重系数和偏移值。
输出门ot是为了控制当前记忆单元信息过滤掉了多少信息。输出一个[0,1]之间的值,判断信息过滤的程度。输出门ot的计算公式为
式中,Wo、bo分别为输出门的权重系数和偏移值。
最后,单元细胞通过门控机制控制信息的传递路径。
式中,Ct-1为上一阶段的输出结果;ht为当前部分的隐藏状态。
1.3 GA 算法
遗传算法模拟了基因的遗传与进化过程,其核心是生物在自然环境中不断遗传与进化中挑选出更优秀的染色体群落,在整个优化过程中根据目标函数为基准,设计出相应的适应度函数,通过使染色体的适应度值不断地升高直至收敛,形成一种自适应搜索全局最优解的优化算法。适应度函数表达式为
式中,yi是真实数据;ai是通过神经网络模型预测的结果;abs 为绝对值函数;n为单一批次中样本个数。
基于遗传算法建立井底钻压预测模型,依据种群遗传与进化的重组、变异、迭代进化过程,对钻井参数进行编码重组,创建初始种群,并采用二进制把创建的初始种群进行编码。如图1 遗传进化模式图所示,引入神经网络预测机制,多次循环迭代计算适应度值并进行排序,根据排序结果优化种群个体,从基因重组中的新染色体中选取适应度高的“父母”样本组,将其影响参数基因遗传给子女,从而得到全局最优解。
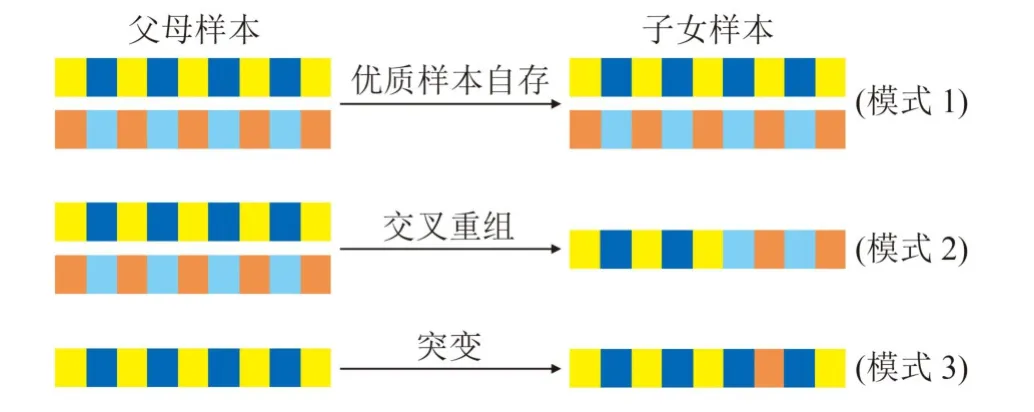
图1 遗传进化模式Fig. 1 Genetic evolution pattern
2 智能模型结构设计及优化算法
2.1 数据预处理
2.1.1 数据集
采用钻速参数、大钩载荷参数、转速参数、扭矩参数、立管压力参数、井底钻压等各项钻井数据作为智能预测模型的数据集,并把钻井参数的数据集按照9∶1 的比例划分成训练集与测试集,列举部分数据,如表1 所示。
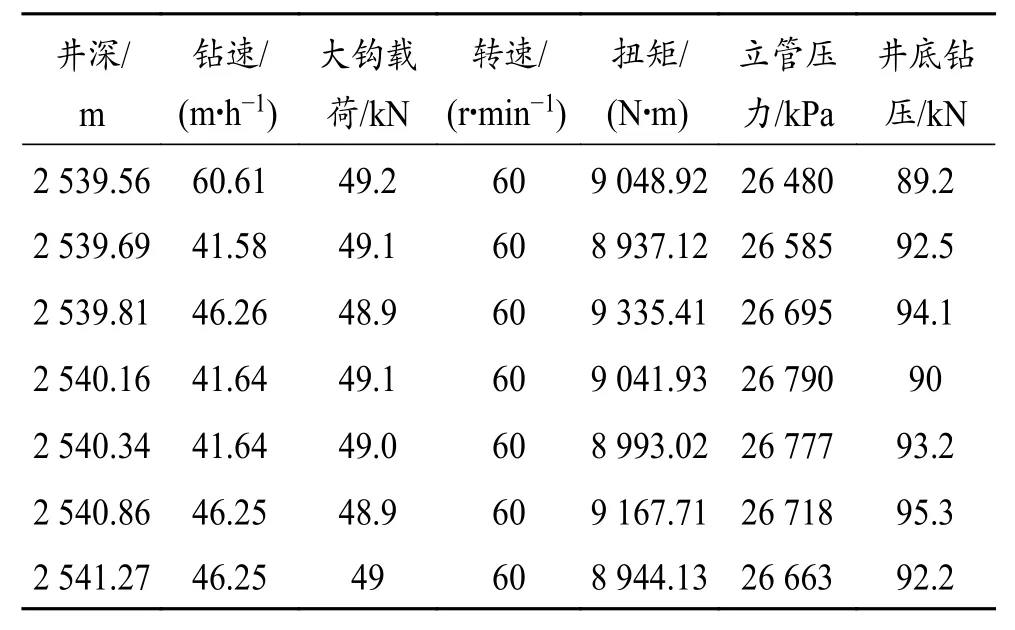
表1 数据样本示例Table 1 Data samples
2.1.2 小波滤波处理
由于复杂的井身结构,在钻井过程中,会产生各种噪声干扰,这些噪声会影响模型的泛化能力,导致各项钻井参数的测量值与实际值间会存在一定误差,必然会对井底钻压的预测结果产生不利影响,因此使用小波滤波方法进行信号转换,尽可能地避免干扰信号。
小波滤波保留并发展了Fourier 变换局部化的思想,通过对多分辨率频域信息进行分析,可以根据待解决的问题灵活地选取不同的小波核,从而克服了Fourier 变换对局部分析能力不足和窗口大小不随频率变化等缺点,能够提供一个随频率改变的“时间-频率”窗口,是进行信号时间-频率分析的理想工具。
分析信号X(t)进行小波基变换为
式中,a为尺度因子且a>0,实现对波基函数φ(t)进行伸缩变换;τ为平移因子,实现对小波在时间轴上的平移变换。
采用软阈值函数进行降噪处理,根据样本数据集的数量,将滑动窗口的尺寸范围设置为3~9,每一个采样单元间隔进行一次测试,最终确定滑动窗口长度为5。选用biorNr.Nd 小波基[27],提取第4 层的分解结果作为降噪的输出结果。输入参数有钻速、大钩载荷、转速、扭矩、立管压力,输出参数为井底钻压的测量值。由图2 可以看出数据降噪前曲线有许多尖峰和突变,降噪处理后曲线变得更加平滑,并且与原曲线趋势一致,保持了原数据的变化特征。
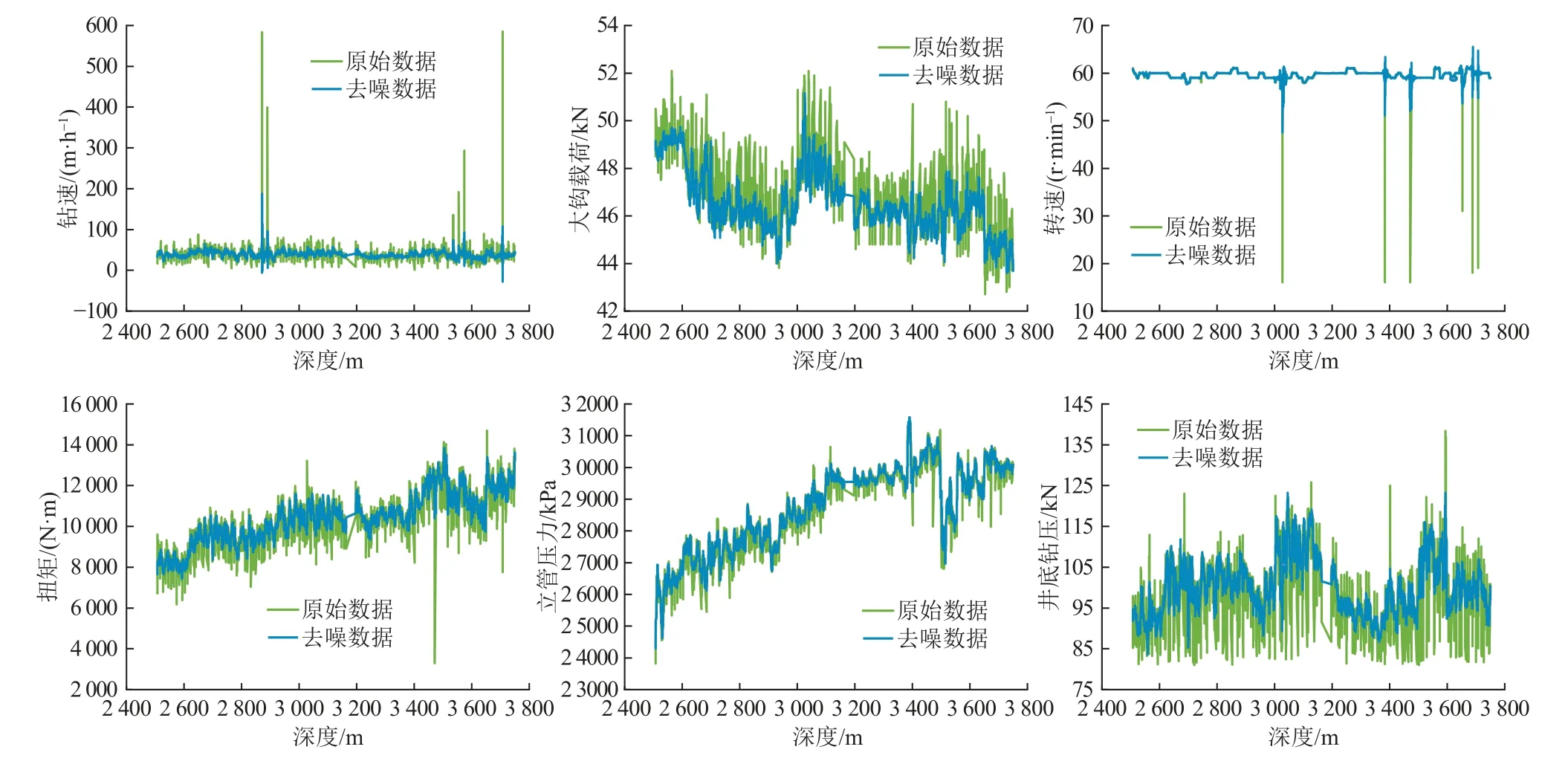
图2 小波滤波Fig. 2 Wavelet filtering
2.1.3 数据归一化
为了消除不同输入指标之间量纲和奇异样本带来的影响,避免训练时因为数值过大而引起的问题,同时为了提高模型处理数据的泛化能力,在数据降噪后,采用均值法对目标数据集统一进行归一化处理。均值归一化计算公式为
式中,x为样本数据值;xm为样本数据的均值;S为样本数据方差。
2.1.4 评价指标
分别选取平均相对误差(MRE)、均方根误差(RMSE)、平均绝对误差(MAE)作为4 种井底钻压智能预测模型的评价指标。
2.2 GA-BP 模型
虽然BP 网络具有比较强的学习能力,但传统的BP 神经网络存在收敛速度慢且容易陷入局部最优解等问题,为了避免网络自身缺陷,结合使用GA 优化算法,优化BP 神经网络的权值和阈值,该方法不仅能够加快收敛速度,同时又可避免模型陷入局部极限最小值。图3 为结合GA 算法的BP 网络流程,具体步骤如下:(1)确定BP 网络的拓扑结构;(2)设置BP 模型及遗传算法的参数,参数如表2 所示;(3)依据GA 算法基因的复制、交叉、变异过程,不断地优化网络模型的权值阈值;(4)判断迭代次数是否达到设置值T,即网络的权值阈值是否已达到最优,若不满足条件,重复步骤4,直至达到最优解;(5)代入BP 模型进行训练。
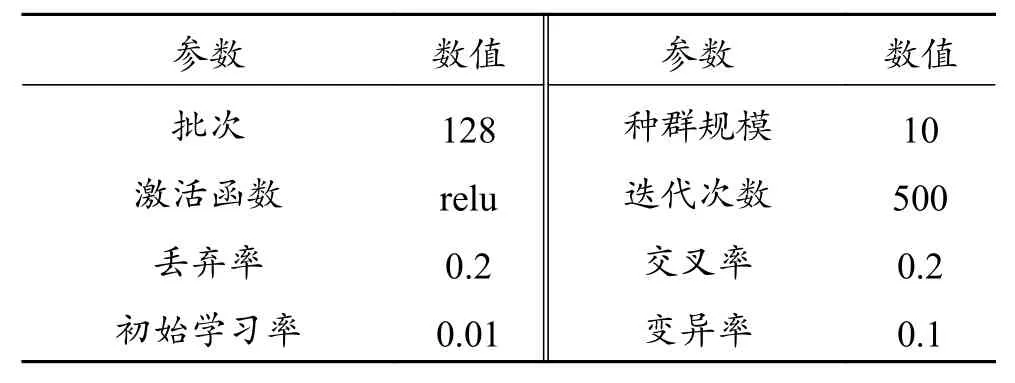
表2 BP 模型参数Table 2 Parameters of BP model
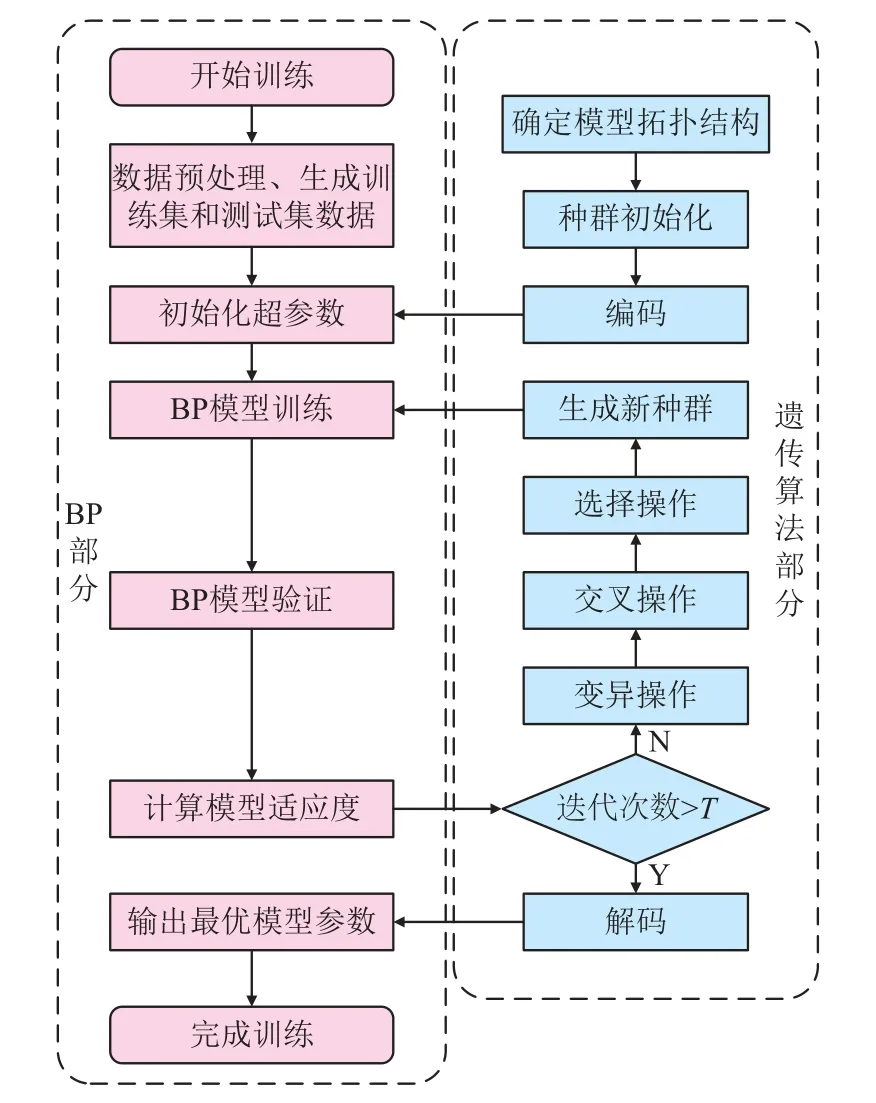
图3 基于遗传优化算法的BP 网络流程Fig. 3 Workflow of GA-BP
2.3 GA-LSTM 模型
遗传算法是模仿生物进化发展而来的一种高效的全局搜索与优化方法,通过选择、交叉、变异,进行基因重组,在迭代搜索的过程中,逐渐向最优适应度种群靠拢,即最优解,并将其代入LSTM 网络模型进行训练。图4 为基于遗传优化算法的LSTM 网络流程,具体步骤如下:(1)确定LSTM 网络的拓扑结构;(2)设置LSTM 模型及遗传算法的参数,参数如表3 所示;(3)其余步骤参照GA-BP 模型,与其第3、4、5 步骤相同。

表3 LSTM 模型参数Table 3 Parameters of LSTM model
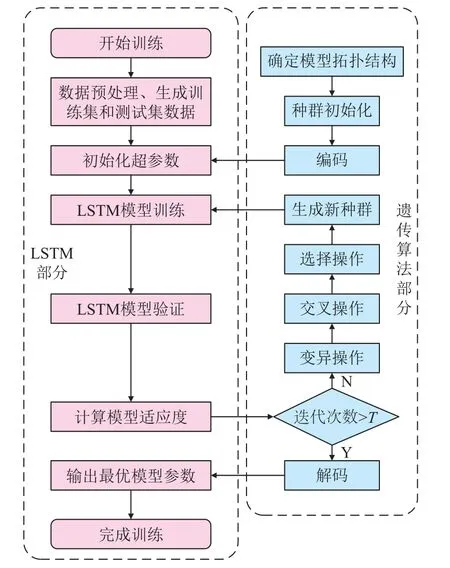
图4 基于遗传优化算法的LSTM 网络流程Fig. 4 Workflow of GA-LSTM
2.4 动态学习率
通常神经网络模型在进行训练时,首先经过正向传播,其次计算梯度,最后进行反向传播从而优化模型参数。学习率在深度学习中是网络模型优化时的重要参数,一般来说,学习率越大,神经网络模型训练速度越快,反之越慢,但当学习率过大时,有可能造成模型收敛困难或者跳出最优极值点。若学习率太小模型收敛速度较慢,降低运行效率,增加训练时间。因此为避免这一问题,采用动态学习率策略,在训练初期采用较大的学习率来保证模型的收敛速度,随着训练过程的不断推进,当模型收敛到接近最优解附近时动态地减小学习率,防止模型在最低点附近震荡,避免陷入局部最优解。
在反向传播算法中,梯度下降法通过计算损失对网络神经元的权重w和偏置值b进行更新,更新的计算公式为
式中,Wi+1和Wi分别为更新参数时第i+1次和第i次迭代时的权重值;η为学习率;Li为损失函数。
选取重构误差损失函数作为评判学习率调整的依据,确定了lr_scheduler ExponentialLR 动态调整学习率策略,其计算原理为
式中,lt+1和lt分别为迭代次数为t+1次和t次时的学习率;γ为学习率衰减的乘法因子;e为训练周期。
首先采用固定学习率与动态学习率策略进行对比。经过反复实验分析,最终采用学习率为0.1、0.03、0.06 三组固定学习率作为对照组实验,将动态学习率的初始值设置为0.1,其他的网络模型参数不变进行实验,重构误差曲线如图5 所示。
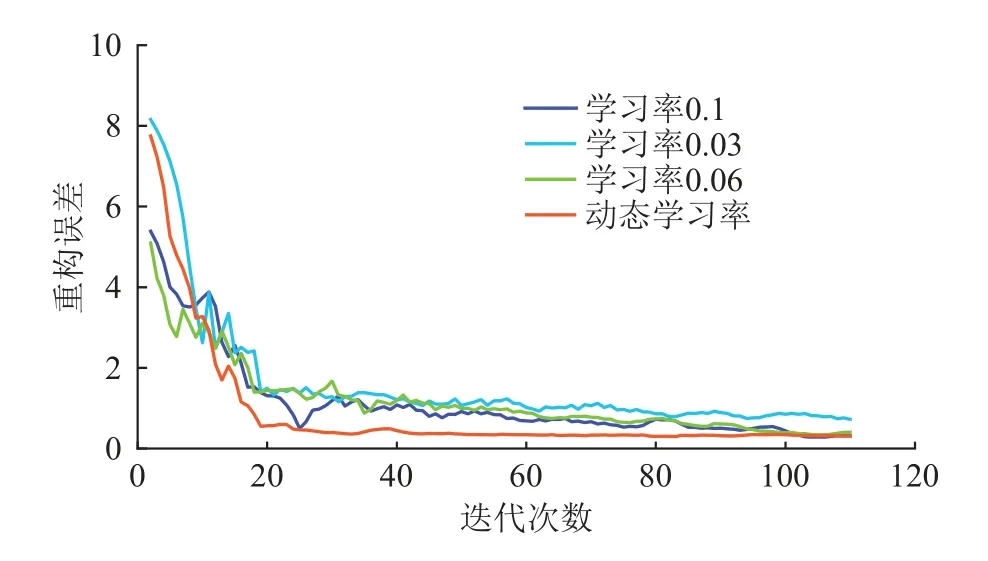
图5 固定学习率与动态学习率Fig. 5 Fixed learning rate vs. dynamic learning rate
由图5 可知,3 种固定学习率与动态学习率策略在经过一定次数的迭代后重构误差曲线基本趋于稳定(收敛)状态,其中动态学习率的重构误差稳定值最小,其次是0.1 的固定学习率,0.06 的固定学习率,0.03 的固定学习率。从重构误差曲线的下降速度来看,在起初阶段,采用固定学习率为0.03 与动态学习率时的重构误差值下降的速度最快,达到收敛值时所用的迭代次数最少。动态学习率的重构误差最先达到收敛状态,且收敛速度最快。
3 实验结果与分析
3.1 GA 优化过程
在进行数据预处理后的10 432 组数据中,每次随机选取90%的数据分别对GA-BP、GA-LSTM 模型进行训练,剩余10%的数据用于测试集,其训练的算法适应度曲线如图6、7 所示。随着种群迭代次数的增加,基于GA 算法的2 种模型的适应度曲线逐渐升高,种群在不断地进化过程中,GA-BP 模型迭代到80 代后,适应度值达到最优值(最大值),并逐渐趋于稳定状态,而GA-LSTM 模型迭代到20 代后,就达到了其最优个体适应度值,并收敛,因此GA-LSTM 模型比GA-BP 模型种群进化得快,模型的训练速度更快。
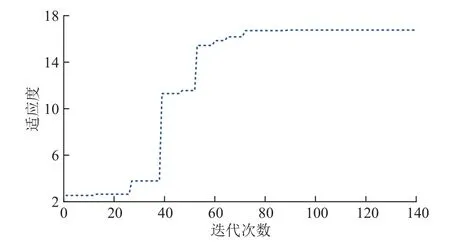
图6 GA-BP 优化曲线Fig. 6 GA-BP optimization curve
3.2 GA 优化结果及智能模型性能比对
为验证加入遗传优化算法的BP、LSTM 模型与单一的BP 与LSTM 模型的预测结果,对比4 种智能预测模型在测试集上的性能,通过对每个模型分别进行多次实验对比分析,最终选取和评估最佳智能预测模型。4 种智能预测模型的预测结果如表4 所示,可以看出,单一模型在同等参数设置下的预测结果都表现出相似的波动性,其中LSTM 模型的平均相对误差为0.069 5,而BP 模型的平均相对误差为0.086 4,模型的稳定性与鲁棒性表现较差。

表4 预测评价结果Table 4 Prediction evaluation results
由表4 和图8 进一步分析表明,与单一网络模型相比,加入GA 算法后的模型各项指标都有所下降,预测精度更高,稳定性更好。GA-BP 与GALSTM 预测图表明,加入GA 算法的模型在预测趋势方面表现的更加明显,其中GA-LSTM预测趋势与真实值更加吻合,且预测精度最高,平均相对误差为0.041 6,其次是GA-BP,平均相对误差为0.045 7,相比而言,2 个加入遗传算法的网络模型比单一的BP 与LSTM 模型其平均相对误差分别降低了47.11%和40.13%。从计算时间上分析,加入遗传优化算法后2 个模型的测试时间有显著优势,对比单一的BP 与LSTM 模型,计算时间分别降低了9.3 倍与12.6 倍,在钻井现场,当有庞大数据集的情况下,使用单一的BP 与LSTM 模型预测井底钻压会消耗大量的时间,影响钻井效率,为满足现场需求,可选用遗传优化算法的网络预测模型用于钻井,但由图6、图7 可知,同等条件下,在迭代训练的过程中GA-LSTM 模型比GA-BP 最先达到最优个体适应度值,模型训练快,所用时间更少。为了更直观对比各个智能模型的预测精度,表4 中每个模型的评价指标结果如图9 所示。由图可知,GA-LSTM 模型的误差更低,精度最高,并且综合考虑图9 与表4 可知,GA-LSTM 的预测趋势与真实值更加接近,并且计算时间更快,因此可选取GA-LSTM 作为井底钻压的最优智能预测模型。
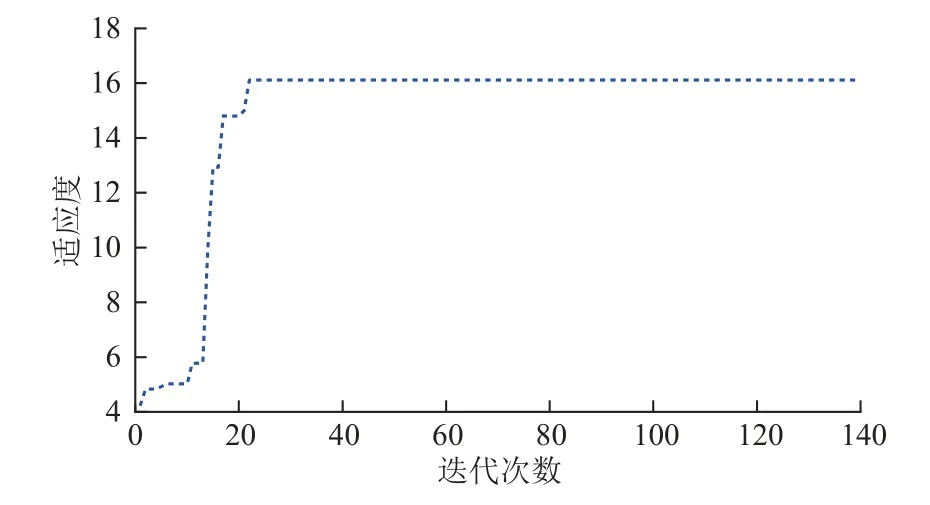
图7 GA-LSTM 优化曲线Fig. 7 GA-LSTM optimization curve
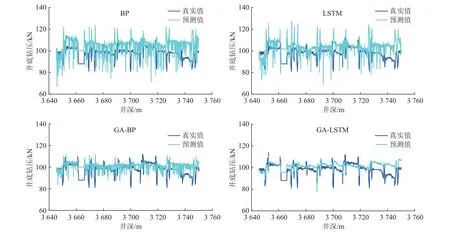
图8 预测结果Fig. 8 Prediction results
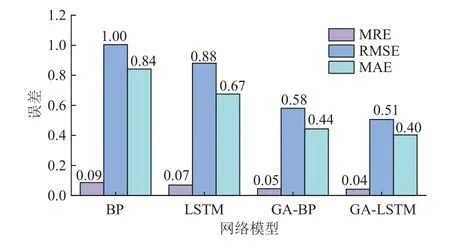
图9 模型评价指标结果Fig. 9 Results of model evaluation indexes
4 结论
(1)根据钻井数据的特征,设计了BP 和LSTM模型对井底钻压进行实时预测,同时为了改善模型参数优化过程,避免出现局部最优解问题,还结合了遗传算法设计出GA-BP 模型与GA-LSTM 模型,通过对比4 种模型对井底钻压预测结果可知,GALSTM 与GA-BP 智能预测模型比单一的LSTM 与BP 模型的MRE 分别降低了40.13%和47.11%。
(2)各模型在加入遗传优化算法后,起到了一定程度的优化作用,可帮助单一的BP 与LSTM 模型快速获取最优权值和阈值,计算时间分别降低了9.3 倍和12.6 倍,当有庞大的钻井数据时,可将GA 算法应用其中,提高钻井效率。
(3)综合各方面考虑,尤其是GA-LSTM 模型在各个方面都表现出良好的性能且模型更加稳定,因此可选作井底钻压的最优智能预测模型,并将其应用于井底钻压实时监控,实时预测和分析井底钻压,同时又可用于常规的自动送钻系统,从而实现自动送钻过程中对井底钻压的准确控制,提高钻头的性能和钻井效率,降低整个钻井工程的成本。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
海洋石油(2021年3期)2021-11-05
石油研究(2020年5期)2020-07-23
中国化工贸易·下旬刊(2019年5期)2019-10-21
小哥白尼(趣味科学)(2019年5期)2019-08-27
科学与财富(2016年37期)2017-07-13
中国塑料(2016年11期)2016-04-16
西南石油大学学报(自然科学版)(2015年5期)2015-04-16
天然气与石油(2015年2期)2015-02-28
教育与职业(2014年16期)2014-01-19
