
基于时空特征融合的SQL注入检测研究
2023-08-01 17:56:01王清宇王海瑞朱贵富孟顺建
化工自动化及仪表 2023年2期
关键词:注意力机制
王清宇 王海瑞 朱贵富 孟顺建

摘 要 针对深度学习方法检测SQL注入时特征提取效果欠佳的问题,提出一种基于时空特征融合的检测模型SFFM。首先使用BERT预训练模型进行词嵌入,使用TextCNN提取SQL样本中不同粒度下的局部空间特征,同时使用BiGRU在保证训练效率的同时提取SQL样本的时序特征;再把提取到的特征送入Attention层进行全局语义信息提取;最后将提取到的特征进行融合,连接全连接层后送入softmax分类器进行分类检测。对比实验结果表明:SFFM模型获得了高达99.95%的准确率和99.90%的召回率,相较于CNN、LSTM和BERT?base模型,具有更好的检测效果。
关键词 SQL注入检测 时空特征融合 SFFM模型 注意力机制 词嵌入
中图分类号 TP393.08;TP181 文献标识码 A 文章编号 1000?3932(2023)02?0207?09
随着互联网的飞速发展,网络安全逐步上升为我国安全领域的重要组成部分。从2013年至今的OWASP TOP 10报告中可以看到,注入攻击多年位居十大安全隐患排行榜前三的位置[1,2]。SQL注入作为注入攻击中的最大元凶,其危害性和破坏性极大,成为国内外安全人员持续关注的研究热点。传统的SQL注入检测方法可分为静态检测方法、动态检测方法和动静结合的检测方法[3]。静态检测是指在不运行程序的情况下通过对源码进行分析来判断是否存在SQL注入风险。GOULD C等开发的JDBC Checker工具,可以检测出部分类型的SQL注入攻击[4]。这种方法需要相当严谨的源码分析能力和对各种SQL注入非常敏锐的洞察力,静态检测方法具有较高的误报率,而且在某些情况下无法获得程序的源代码。动态检测是指在程序运行时通过动态测试来检测是否存在SQL注入风险。张慧琳等提出的基于敏感字符的SQL注入检测方法,通过对可信敏感字符进行积极污点标记来检测是否存在SQL注入[5]。动态检测方法虽然较为灵活,但是检测效果的好坏取决于测试用例的范围,而实际人工合成的测试用例非常有限,并且非常耗费系统资源,检测效率较低。动静结合的检测方法旨在结合静态方法与动态方法两者的优势,在静态分析阶段,构造安全的SQL语句模型,然后在动态分析阶段,解释提交的SQL语句,将其与静态SQL语句模型进行对比,判断是否存在SQL注入风险。HALFOND W G J和ORSO A提出的AMNESIA,先通过分析Web应用程序生成安全的SQL查询模型,然后动态监视提交的查询,若查询与静态模型不符,则判定为SQL注入攻击,并向开发人员或者管理员报告相关信息[6]。这种方法可能会因为静态模型创建时不变量提取不全面,导致发生大量的虚警和漏警。
近年来,机器学习方法越来越多地应用于安全检测领域,有望在SQL注入方面发挥巨大作用。但浅层机器学习依然需要人工提取复杂的注入样本特征,而且使用场景大幅受限。新的SQL注入攻击类型不断涌现,浅层机器学习应对较为乏力。深度学习因为节省了复杂的特征工程而颇受工程师和学者的青睐。肖泽力使用DNN分类器检测SQL注入,实验结果证明了深度学习模型的检测效果优于朴素贝叶斯、人工神经网络等机器学习模型[7]。虽然深度学习模型在SQL注入检测领域有了较多的应用,但是大多数方法只是针对单一的模型进行训练,这些模型很难同时在时间和空间维度上提取到有效的特征,如RNN、LSTM等模型只是针对样本的时序特征进行提取,CNN模型只是提取样本的空间特征。为此,笔者提出一种基于时空特征融合的SFFM模型,在尽可能保证网络参数不过于复杂的情况下,同时提取SQL样本的时序和空间特征、局部与全局特征,最后通过对比实验和消融实验验证笔者所提SFFM模型的有效性。
1 特征融合
SFFM模型融合了卷积神经网络、循环神经网络、注意力机制和BERT预训练模型,能够兼顾样本的局部和整体特征、空间与时序特征,从而更好地对SQL样本进行分类检测。
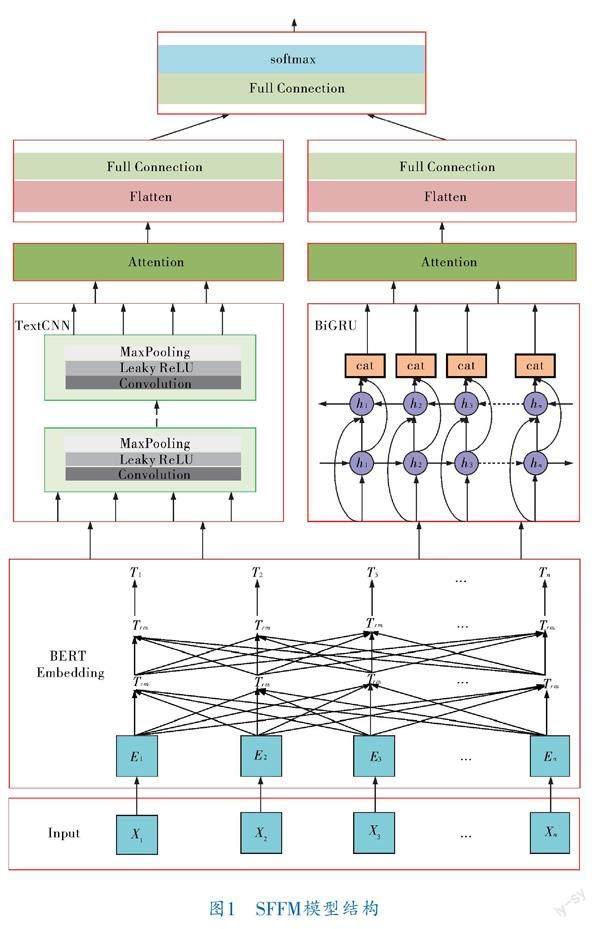
SFFM模型主要包括输入层、词嵌入层、TextCNN层、BiGRU层及注意力层等,具体结构如图1所示。
首先将所有数据进行预处理操作,包括解码处理、泛化处理和分词处理。解码处理主要针对ASCII编码、URL编码、UNICODE编码及JSON编码等常见编码进行解码。泛化处理是为了去除相似无用的冗余特征,主要包括大小写转换、统一日期格式和数字格式、排查重写过度。接着将预处理后得到的训练集数据Xi送入BERT Embedding层做词嵌入,再将得到的词向量Ti分别送入TextCNN层和BiGRU层进行空间特征和时序特征的提取。然后使用Attention层加强重要特征的权重,削弱噪声的影响。最后将特征展平后接入全连接层,送入softmax分类器进行分类检测。
1.1 BERT预训练模型
BERT的核心组件是双向Transformer编码器,相比于传统的单向语言模型或者多个浅层拼接后的单向语言模型,BERT能够学到更重要的单词或句子语义以及文本中不同级别的关系特征[8],同时使用上亿级别的无标注语料进行预训练,能够生成更加准确、更通用的词向量或者句向量表示[9]。很多下游任务只需在预训练模型的基础上添加一个额外的输出层进行微调,便可获得非常出色的任务表现。
BERT构建了两种预训练模型,分别是掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。MLM类似于完形填空,將一些词MASK掉,用剩余词对MASK掉的词进行预测,具体做法是随机MASK掉15%的单词,这些单词中有10%随机替换成其他单词,10%保持不变,还有80%真正MASK掉,即替换成[MASK]标志。此类任务能够使模型学习到深度的双向信息,具备更强的多义性学习能力。NSP的任务是判断给定的两个句子是否是连续的。此类任务能够让模型学习到连续文本之间的关系,使模型具备长距离语义捕捉能力。
BERT的输入结构如图2所示,主要包含3个部分:词向量、句子向量和位置向量。其中句子向量是为了刻画句子的全局语义信息,并与词向量信息相融合;位置向量是为了克服注意力机制不能编码位置信息的缺点。BERT的输出结构如图3所示,其中C是[CLS]对应最后一个transformer的输出,T代表其他token对应最后一个transformer的输出。对于字或词级别的任务,将T输入到额外的输出层继续处理,对于句子级别的任务,则把C输入到额外的输出层中处理。笔者利用BERT进行词嵌入,需要将T输送到TextCNN层和BiGRU层继续学习高级特征。
1.2 TextCNN网络
TextCNN网络将传统图像卷积神经网络应用于文本分类任务中,利用多个不同size的卷积核来提取句子中的关键信息,从而更好地捕捉局部相关性[10]。笔者利用TextCNN网络对SQL样本的局部空间特征进行提取。网络结构如图4所示,主要包含输入层(Input layer)、卷积层(Convolution layer)、激活层(Activation layer)、池化层(Pooling layer)和全连接层(Fully connected layer)。输入层是n×k的句子矩阵,其中n代表SQL样本长度,k代表每个单词对应的词向量维度。由于输入矩阵必须统一,所以需要对句子的长度进行padding,少于n的进行填充,多于n的进行截断。卷积层用来对输入数据进行特征提取,通过对句子矩阵和卷积核点乘的操作来抽象词语或句子之间的局部特征关系。与处理图像的卷积核不同,TextCNN中的卷积核的宽度一般和词向量的维度一致,以保证每次滑动卷积核都可以取到完整的词向量。本文中设置多个不同的卷积核来提取不同维度的上下文信息。激活层通过激活函数对卷积层提取到的特征进行激活,具体做法是在卷积层输出的基础上嵌套非线性函数,从而让输出特征具有非线性结构。池化层是对卷积层学到的特征进行有效筛选,避免参数过多导致运算效率降低和过拟合的产生。常见的池化方法有Average pooling、1?Max pooling及K?Max pooling等。全连接层负责对卷积神经网络学习提取到的特征进行汇总,整理成一个一维向量。本文在池化层后暂不进行全连接,而是接入到Attention层进行全局语义信息提取。
1.3 BiGRU网络
门控循环单元(Gated Recurrent Unit,GRU)是循环神经网络簇中的一个变体,相比于长短期记忆网络LSTM,GRU通常能够获得同等甚至更优的效果,但结构更加简单,训练速度明显更快[11]。GRU单元结构如图5所示。
图5中有两个重要的门:重置门Rt和更新门Zt。重置门决定了如何将新的输入信息与前面的记忆相结合,有助于捕获序列中的短期依赖关系,而更新门定义了旧的状态保存到当前时间步的量。其计算式如下:
其中,X是当前t时刻的输入;H是前一时刻的隐状态;W和W分别是R和Z对于当前输入X的权重参数;W和W分别是R和Z对于H的权重参数;b和b分别是R和Z的偏置参数;σ代表sigmoid函数将输入值映射到(0,1)区间。
新的隐状态需要旧的隐状态和更新门共同计算得到,计算式如下:
其中,[H][^]为候选隐状态;W是当前隐状态权重参数;W为前一时刻的隐状态权重参数;b是隐状态的偏置项。候选隐状态由三项求和得到,并使用tanh非线性激活函数将值映射到(-1,1)之间。GRU的隐状态信息是按照时间步顺序从前往后单向传递的,只关注了前文对后文的影响,为了克服此缺陷,笔者使用双向BiGRU,该模型由两个方向相反的GRU隐藏层共同组成神经网络,每个时刻的隐状态由当前时刻的前向隐状态和后向隐状态拼接而成,因而能学习到更加丰富的双向语义信息。
1.4 Attention机制
在深度学习领域,网络模型往往需要处理海量的数据,然而在某些时刻,可能只有少部分的信息是重要的,让模型能够通过自主学习将更多的注意力放在这些重要的信息上,有选择性地忽略其他不重要的信息,就是Attention机制需要做的事[12]。Attention机制通常可分为软注意力机制、硬注意力机制和自注意力机制。其中软注意力机制对每一个输入都有所考虑,重要信息分配权重大一些,不重要的信息分配权重小一些,相对来说计算量比较大。硬注意力机制对每个输入项分配的权重非0即1,也就是说关注的部分(重要)就分配权重为1,不关注的部分(不重要)直接舍弃。硬注意力机制虽然可以减少时间和计算成本,但可能导致许多本应关注的信息丢失,因此使用较少。自注意力机制对每一个输入项分配的权重取决于输入项之间的关系,即学习输入中不同部分的相关性,利用矩阵运算实现并行加速。笔者通过自注意力机制获取SQL样本的全局特征,其实现方式如图6所示。
图6中4个输入向量x分别对应4个输出向量o(i=1,2,3,4)。为了计算得到o,首先对每一个输入向量x分别点乘3个系数wq、wk和wv,得到q、k、v3个值,在实际应用场景中,为了提高计算速度,采用矩阵相乘的方式,公式如下:
Q、K、V由输入矩阵X点乘3个系数矩阵W、W、W所得,这3个系数矩阵是随机化初始的,并在学习过程中不断更新。然后将矩阵Q和矩阵K进行点乘操作来计算两个输入矩阵之间的相关性。为了使Attention得分不随着向量维度的变化而发生改变,将Q和K的点积进行归一化操作,即除以系数矩阵的第1个维度数dk的开方,并进行softmax操作,最后將得分矩阵A和真实值矩阵V点乘得到最终的输出矩阵O。
由以上计算过程可以看到,每个词看到的不仅是它前面的序列,而是整个输入序列,因此Attention可以学习到SQL样本的全局特征,并且矩阵运算可以实现并行加速。文中还使用了多头注意力机制,通过不同的头得到多个不同的特征,然后将所有特征拼接在一起,最后连接全连接层实现降维并使用softmax进行分类检测任务。
2 实验及结果
2.1 实验数据集
实验数据集一共有两部分来源:一部分从数据仓库[13]收集并筛选有效的SQL注入语句和正常SQL语句,另一部分数据通过在Windows10虚拟机中布署apache+php+mysql环境,搭建sqli?labs和bwapp靶场,使用SQLyog对MySQL进行正常访问,同时使用sqlmap、AWVS等测试工具和自定义tamper脚本对靶场进行攻击,使用wireshark、burpsuite等工具抓取正常SQL语句和具有攻击行为的SQL注入语句。总共得到50 000条SQL样本,其中包括25 000条正样本和25 000条负样本。
2.2 实验环境
实验在GPU环境下进行计算,使用Pytorch机器学习框架,开发平台为Pycharm,开发语言为Python。具体实验环境见表1。
2.3 实验设置
对数据集按照8∶2的比例划分训练集和测试集,即40 000条样本作为训练集,10 000条样本作为测试集,训练集与测试集中的正负样本比例均为1∶1。具体数据分布见表2。
首先对数据集进行预处理。因为数据集的质量决定了深度学习的上限,好的预处理能够充分发挥模型的学习能力。实验时在将数据输送至BERT层之前,对数据进行解码、泛化和分词处理:
a. 解码处理。解码是为了去除杂乱的编码信息,让模型学习到真正有效的SQL样本特征。具体做法是把ASCII编码、URL编码、UNICODE编码、JSON编码等常见编码统一解码成UTF?8编码。
b. 泛化处理。泛化是为了减少SQL样本中的冗余特征,让模型学习更加具有针对性。比如or 1=1#和or 2=2#本质上没有任何区别,无需将其学习成两种情况。为此笔者将所有十进制数转换成0;将所有十六进制数转换成0x12;将所有英文字母转换成小写(因为SQL语句不区分大小写);将日期和时间转换成固定字符“dtime”;排查重写过度的词语,只留下去除冗余后的字符或字符串,比如字符串“seunionleunionct”排除掉关键字union后,留下的字符串“select”依然是关键字。
c. 分词处理。分词是为了更准确地进行词嵌入。本实验不采用JOSHI A和GEETHA V的空白分割法[14],而是将包括空格在内的所有字符、关键字等全部进行分词。在分词时保留原始字符的含义,比如“--”可以起到单行注释的作用,如果拆成两个“-”字符,将会失去该字符的本来特征。
数据预处理后,使用不区分大小写的BERT?base?uncased模型进行词嵌入,词向量维度为768。TextCNN网络中使用了4种大小的卷积核,以便学到不同尺度的特征,其大小为2、3、4、5,每组卷积核数为200,卷积步长设置为1,激活函数使用Leaky RELU,池化采用1?Max pooling方法,dropout大小为0.15。BiGRU的隐藏层维度设置为300。使用Adam优化器优化模型参数,同时使用LambdaLR scheduler对学习率进行调整。以上参数设置均由手工调优后得出。
2.4 评价指标
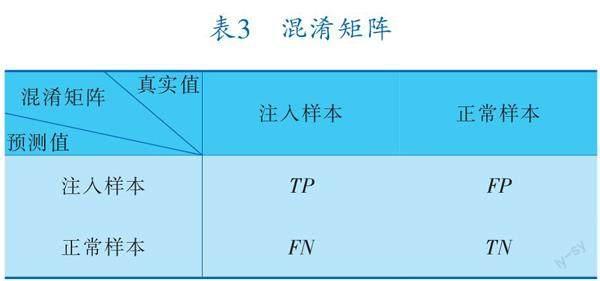
实验使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值对深度学习模型进行评估。其中准确率代表被正确分类的样本占总样本的比例,是模型评估中最常用的指标之一;精确率是指被正确分类的正样本占预测为正样本的比例;召回率代表被预测为正样本占实际为正样本的比例,是安全领域最为重要的评价指标之一;F1值是整体考虑精确率与召回率的综合指标。相关参数混淆矩阵见表3。
基于以上参数,得出准确率Acc、精确率P、召回率R和F1的计算式如下:
2.5 实验结果及分析
为了验证笔者所提基于时空特征融合的SQL注入检测模型的效果,设置一组对比实验和一组消融实验,分别对融合后的模型性能和特征融合的有效性进行检验。
2.5.1 对比实验
实验中将SFFM模型与几种常用于SQL注入检测的单一特征提取的深度学习模型进行对比,包括谢鑫等使用的CNN模型[15]、楚翔皓和刘震使用的LSTM模型[16]、DEVLIN J等提出的BERT?base模型[17],数据集划分如2.3节所述,实验结果见表4。
由表4可以看出,基于时空特征融合的SFFM模型在准确率、精确率、召回率和F1值4个指标上均优于其他3个模型,BERT?base次之,LSTM表现最差,说明BERT预训练模型在大量语料训练的基础上针对本文分类检测拥有较好的任務表现,而SFFM模型将BERT作为词嵌入进行更深一层的
特征提取后,分类表现更加出色,可见基于时空特征融合的分类模型较其他单一特征提取的分类模型具有更好的特征提取能力。
图7是4种模型的训练损失变化曲线,可以看出4种模型中SFFM模型收敛最快,在迭代4 000次左右便收敛到接近于0的值,BERT?base、CNN和LSTM收敛速度依次递减,说明基于时空特征融合的模型能够更有效地提取样本特征,收敛速度较单一特征提取的模型更快。
图8是测试集中不同模型的F1值对比曲线,每迭代500次记录一个值。从图8中可以看出,SFFM模型的F1值在迭代2 000次左右便收敛到最大值99.61%,且曲线波动较小。其他3种模型的F1值曲线收敛速度和最大值均不如SFFM模型,说明SFFM模型的综合表现优于其他3种模型。
2.5.2 消融实验
设置一组消融实验,以验证SFFM模型中不同组件对模型的真实增益。去掉SFFM中的Attention层和BiGRU层得到-BiGRU?att模型;去掉SFFM中的BiGRU层得到-BiGRU模型;去掉SFFM中的TextCNN层得到-TextCNN模型;去掉Attention层得到-Attention模型;将SFFM中的BERT词嵌入替换为Word2Vec词嵌入模型得到-BERT模型。依然使用对比实验中的数据划分方式进行训练和测试,得到实验结果见表5。
由表5实验数据可以看出,-BiGRU?att模型检测效果比BERT?base的召回率要高,说明TextCNN层可以进一步提取到有效的局部语义特征;-BiGRU模型、-TextCNN模型和-Attention模型的4个性能指标均低于SFFM模型,说明去掉这3个组件中的任意一个,其余两层均能有效提取到SQL样本特征;-BERT模型的结果明显比其他几组实验效果差,说明BERT词嵌入可以显著提升特征提取能力。可见,无论是BERT词嵌入层,还是其余的单个组件、两个组件或者三个组件,均能有效提高模型提取特征的能力。
3 结束语
笔者提出的基于时空特征融合的SQL注入檢测模型SFFM,使用BERT作为词嵌入层,并利用TextCNN层提取SQL样本不同粒度下的局部空间特征,BiGRU层提取SQL样本的时序特征,Attention层提取SQL样本的全局特征。对比实验结果表明,笔者提出的SFFM模型的准确率、精确率、召回率和F1值4个指标均比其他单一特征提取模型的高,证明了特征融合的有效性。同时通过消融实验证明了SFFM模型的每个组件均对模型的整体效果起到了积极作用。
实验涉及的SQL注入均为一阶注入,未来工作中将会对二阶SQL注入的检测开展进一步研究。
参 考 文 献
[1] OWASP.Top 10 Web Application Security Risks[EB/OL].(2021-09-24)[2022-08-10].https://owasp.org/www?project?top?ten.
[2] sslHello.OWASP TOP 10 from 2003 to 2021 Releases[EB/OL].(2021-10-03)[2022-08-10].https://github.com/OWASP/Top10.
[3] 王方.基于深度学习的SQL注入检测技术的研究与实现[D].北京:北京邮电大学,2020.
[4] GOULD C,SU Z,DEVANBU P T.JDBC checker:A static analysis tool for SQL/JDBC applications[C]//26th International Conference on Software Engineering(ICSE 2004).IEEE,2004:697-698.
[5] 张慧琳,丁羽,张利华,等.基于敏感字符的SQL注入攻击防御方法[J].计算机研究与发展,2016,53(10):2262-2276.
[6] HALFOND W G J,ORSO A.AMNESIA:analysis and monitoring for NEutralizing SQL?injection attacks[C]//Proceedings of the 20th IEEE/ACM International Conference on Automated Software Engineering.2005:174-183.
[7] 肖泽力.SQL注入攻击检测方法研究[D].长春:东北师范大学,2018.
[8] 林孟达,李书豪.融合BERT嵌入与注意力机制的方面情感分析[J].现代电子技术,2022,45(12):130-136.
[9] 邓维斌,朱坤,李云波,等.FMNN:融合多神经网络的文本分类模型[J].计算机科学,2022,49(3):281-287.
[10] KIM Y.Convolutional Neural Networks for Sentence Classification[EB/OL].(2014-09-03).https://arxiv.org/pdf/1408.5882.pdf.
[11] KYUNGHYUN CHO,BART VAN MERRIEENBOER,CAGLAR GULCEHRE,et al.Learning Phrase Representations Using RNN Encoder?Decoder for Statistical Machine Translation[C]//Conference on Empirical Methods in Natural Language Processing(EMNLP 2014).Doha,Qatar:Association for Computational Linguistics,2014:1724-1734.
[12] VASWANI A,SHAZEER N,PARMAR N,et al.Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems.2017:6000-6010.
[13] client9.SQL injection dataset[EB/OL].(2018-03-12 )[2022-08-10].https://github.com/client9/libinjection/.
[14] JOSHI A,GEETHA V.SQL injection detection using machine learning[C]//2014 International Conference on Control,Instrumentation,Communication and Com? putational Technologies(ICCICCT 2014).Kanyakum? ari,India:IEEE,2014:1111-1115.
[15] 谢鑫,任春辉,陈新宇.基于CNN的SQL注入检测[J].计算机与网络,2020,46(3):69-71.
[16] 楚翔皓,刘震.基于LSTM神经网络的SQL注入攻击检测研究[J].天津理工大学学报,2019,35(6):41-46.
[17] DEVLIN J,CHANG M W,LEE K,et al.BERT:Pretrai? ning of Deep Bidirectional Transformers for Language Understanding[EB/OL].(2019-05-24).https://arxiv.org/pdf/1810.04805.pdf.
(收稿日期:2022-09-22,修回日期:2023-02-22)
Research on SQL Injection Detection Based on Spatiotemporal Feature Fusion
WANG Qing?yu, WANG Hai?rui, ZHU Gui?fu, MENG Shun?jian
(Faculty of Information Engineering and Automation, Kunming University of Science and Technology)
Abstract Considering poor feature extraction effect in detecting SQL injection through employing the deep learning method,a SFFM(spatiotemporal feature fusion model)?based detection model was proposed. In which, having BERT pre?training model used for word embedding and TextCNN employed to extract local spatial features of SQL samples at different granularity; meanwhile, having BiGRU adopted to extract temporal features of the SQL samples while ensuring a training efficiency; then, having the extracted features sent to the attention layer for global semantic information extraction; finally, having the extracted features fused and connected to the full connection layer and sent to the softmax classifier for classification detection. A comparative experiment shows that, the SFFM?based detection model can achieve an accuracy rate of 99.95% and a recall rate of 99.90%, and the SFFM?based detection model, as compared to CNN,LSTM and BERT?base models with single or simple structure, has better detection effect.
Key words SQL injection detection, spatialtemporal feature fusion, SFFM model, attention mechanism, word embedding
基金项目:国家自然科学基金项目(61863016,61263023)。
作者简介:王清宇(1995-),硕士研究生,从事网络安全与机器学习的研究。
通讯作者:朱贵富(1984-),工程师,从事网络安全、教育大数据、机器学习的研究,zhuguifu@kust.edu.cn。
引用本文:王清宇,王海瑞,朱贵富,等.基于时空特征融合的SQL注入检测研究[J].化工自动化及仪表,2023,50(2):207-215.
猜你喜欢
计算机应用(2019年3期)2019-07-31 12:14:01
无线互联科技(2019年9期)2019-07-29 00:41:36
无线互联科技(2019年9期)2019-07-29 00:41:36
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
智能计算机与应用(2019年3期)2019-07-01 02:35:55
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
