
融合注意力机制的多尺度红外目标检测
2023-07-31 02:33:38李向荣孙立辉
红外技术 2023年7期
李向荣,孙立辉
〈图像处理与仿真〉
融合注意力机制的多尺度红外目标检测
李向荣,孙立辉
(河北经贸大学 信息技术学院,河北 石家庄 050061)
针对红外图像存在细节纹理特征差、对比度低、目标检测效果差等问题,基于YOLOv4(You Only Look Once version 4)架构提出了一种融合通道注意力机制的多尺度红外目标检测模型。该模型首先通过降低主干特征提取网络深度,减少了模型参数。其次,为补充浅层高分辨率特征信息,重新构建多尺度特征融合模块,提高了特征信息利用率。最后在多尺度加强特征图输出前,融入通道注意力机制,进一步提高红外特征提取能力,降低噪声干扰。实验结果表明,本文算法模型大小仅为YOLOv4的28.87%,对红外目标的检测精度得到了明显提升。
红外图像;目标检测;YOLOv4;通道注意力机制
0 引言
红外成像技术依据不同物体间的红外热辐射强度差异进行成像[1],具有受天气影响小、抗光线干扰能力强等优点,弥补了可见光成像受光线条件影响的缺陷,能够实现全天候获取检测目标。但与可见光成像相比,红外目标成像存在纹理特征少、对比度低、信噪比低、成像模糊等特点,这些特点的存在增大了红外目标检测难度,目标检测准确率较低。因此,开展红外目标检测算法研究,对提高红外目标检测效果有重要意义。
传统的红外目标检测[2-4]多采用模板匹配、阈值分割、统计学习等方法,通过抑制背景区域来突出目标区域实现目标检测,但这些方法鲁棒性差、对场景敏感,实际应用效果不理想。随着计算能力的提升,基于深度卷积神经网络(Convolutional Neural Networks, CNN)的目标检测技术在可见光图像领域中取得了巨大进展,将深度卷积神经网络运用到红外目标检测领域受到越来越多学者的关注,并开展了许多相关研究。如Hao等人[5]对RCNN[6](Regions with CNN features)进行改进,提出一种双层区域建议网络,并在主干网络中引入多尺度池模块,实现了多尺度红外目标检测;顾佼佼等人[7]在Faster RCNN[8]的基础上,通过拼接多尺度特征图得到具有更丰富语义信息特征向量,提高了红外目标检测精度;刘智嘉等人[9]在YOLOv3[10]基础上对主干特征提取网络进行轻量化操作,并减少特征金字塔结构的尺度,明显提升了检测速度,但检测准确率因此而下降。总体而言,基于深度卷积神经网络的红外目标检测的精确度和速度仍有待提高。
深度卷积神经网络利用色彩、纹理等信息进行特征提取,构建高层语义信息,但在处理红外图像时,红外目标像素占比少,深层网络中目标特征丢失严重,致使特征提取效果不理想。除此之外,红外图像缺少色彩信息,目标与背景特征差异小,深度卷积神经网络不能对有效信息和无效信息产生区分,致使红外目标检测难度增大,检测准确度低。
针对上述红外目标检测中存在的问题,本文提出一种融合通道注意力机制的多尺度红外目标检测模型SE-YOLOv4。该模型首先使用K-means算法对红外目标锚框尺寸进行调整,并在不影响特征提取能力的前提下,对主干特征提取网络作精简,减少网络计算量。其次,重新构建多尺度特征融合模块,补充浅层高分辨率特征信息,进而实现多尺度目标精确识别。最后,在路径聚合网络输出前融入通道注意力机制SE(Squeeze-and-Excitation Networks)[11],增强特征融合效果的同时加强网络对显著性特征的关注,从而整体提高红外目标检测性能。通过在自制红外数据集和FLIR公开红外数据集上对不同目标检测算法进行性能验证,实验结果表明,本文算法具有更好的红外目标检测效果。
1 模型设计
1.1 目标检测网络结构
深度卷积神经网络对红外目标进行特征提取时,由于目标信噪比低、像素占比低,经过多次卷积下采样操作后像素信息会随特征图尺寸变小逐渐消失,导致红外目标检测效果并不理想。为提高红外目标检出率,本文以YOLOv4[12]为基础网络,提出一种融合注意力机制的多尺度红外目标检测网络SE-YOLOv4。
SE-YOLOv4目标检测网络结构如图1所示,包含Backbone主干特征提取网络、Neck颈部网络和Head目标预测网络3部分。主干特征提取网络为CSPDarknet53改进后的CSPDarknet44,用于提取图像特征,采集多层特征图,以供后续检测使用。Neck颈部网络由空间金字塔池化结构(Spatial Pyramid Pooling,SPP)和多尺度特征融合网络组成。SPP结构包含4个不同尺度的最大池化层,将主干特征提取网络的最后一层特征层经3次卷积后进行最大池化处理,增大特征层感受野,分离出最显著的上下文特征。为充分利用浅层特征信息,本文重新构建多尺度特征融合网络,将有效特征层的选取由降32、16、8倍改为降16、8、4倍,并通过FPN[13]结构和PAN[14]结构实现深层、浅层语义信息充分融合,丰富目标特征信息。为了进一步增强特征融合效果,引入通道注意力机制SE,使网络自动学习特征图通道间相关性,缓解跨尺度融合中的混叠效应[15]。与此同时,通过重新分配特征图通道间权重,增强特征图中对有效信息关注,抑制冗余信息干扰。目标预测网络YOLO Head对获得的加强特征图进行特征整合,得到预测结果。
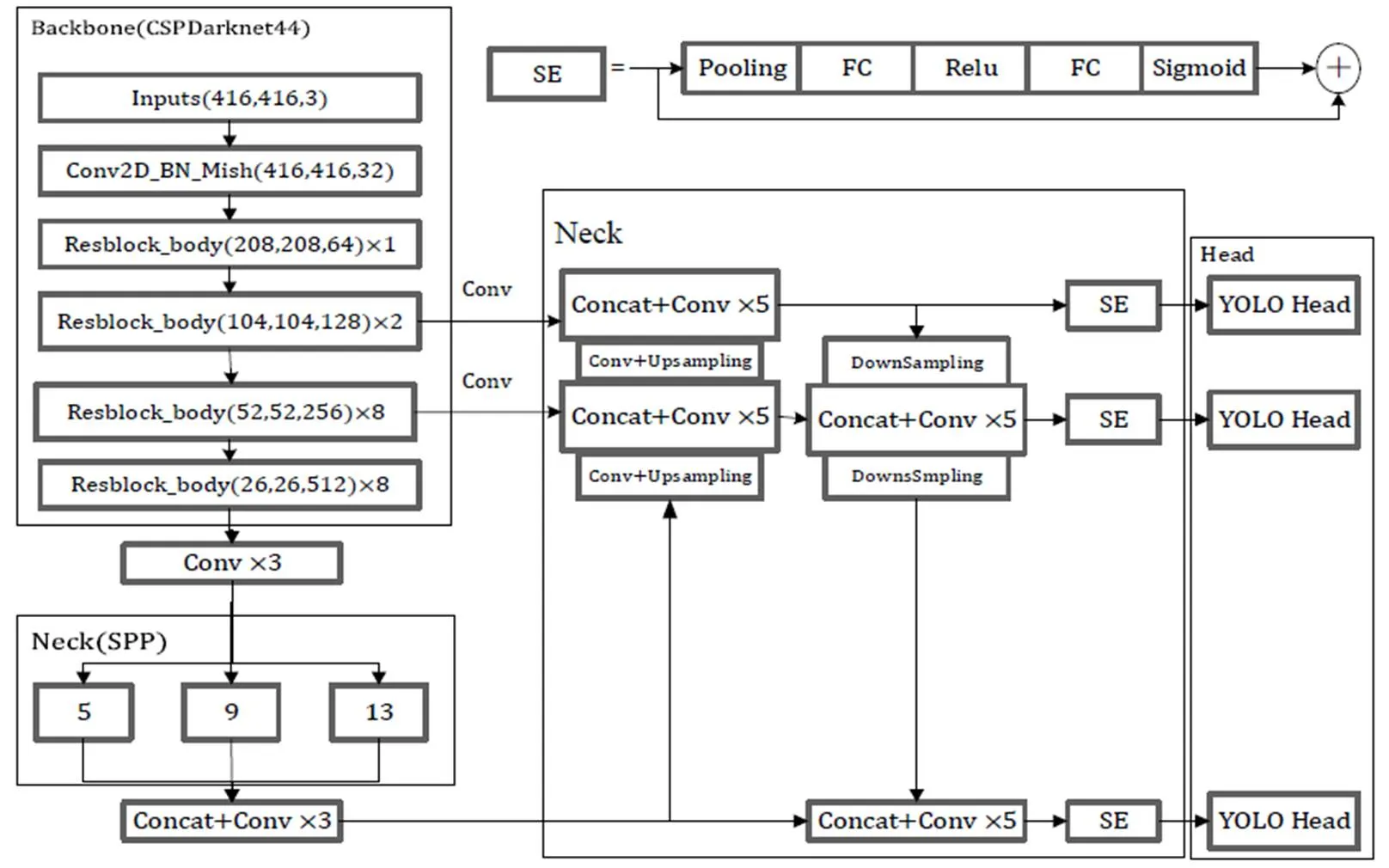
图1 SE-YOLOv4网络结构
1.2 目标先验框设计
合理的先验框(anchor)能有效提高目标检测性能[16]。YOLOv4原始设定的先验框是根据可见光coco数据集得来的,主要面向自然光场景下的目标检测。将原先验框直接应用于红外目标检测中,先验框与红外目标边框的重合度较低,不利于精准预测目标位置,从而影响目标检测效果。为了使先验框尺寸更加适用于红外数据集,增强先验框与目标边框重合度,本文对红外目标尺寸大小重新聚类,得到更适合的anchor参数。通过聚类使得anchor与聚类中心之间的重合度交并比IoU(Intersection over Union)值更大,距离更小。距离衡量公式如式(1)所示:
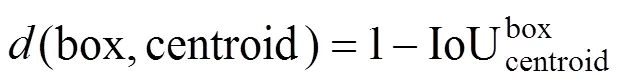
式中:box为目标标签框,centroid为聚类中心。
SE-YOLOv4结构输出3个尺度特征层,每层采用3个先验框,实现目标位置的预测。按照上述方法,采用Kmeans算法对红外数据集中的目标尺寸进行聚类分析得到尺寸更适合的anchor,并将得到的聚类结果分配到对应的3个输出特征层上,如表1所示。
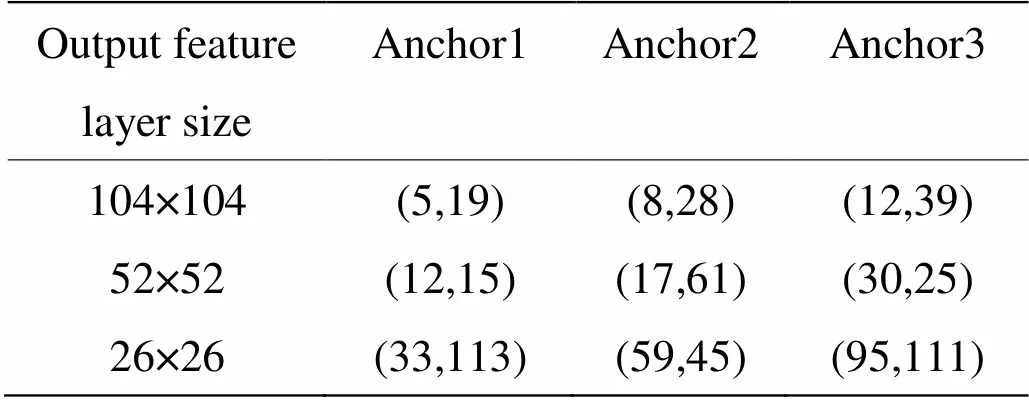
表1 本文红外数据集先验框尺寸表
1.3 主干特征提取网络模块
CSPDarknet53网络主要由CSPStage与残差块ResBlock相结合的Resblock_body构成,网络不同层之间使用跳跃连接,有效缓解了因网络过深造成梯度消失的问题,但由于网络层数较深,随着卷积和池化次数的增加,深层特征层包含的细节纹理信息越来越弱,目标特征丢失严重。因此,将CSPDarknet53的C5、C4、C3三层特征层替换成C4、C3、C2三层特征层作为有效特征层参与后续特征融合。C4、C3、C2中含有更丰富的浅层信息,可有效缓解红外图像特征丢失的问题。此时网络底层特征层C5未起到检测作用,增加了网络参数量,舍去CSPDarknet53最后一层Resblock_body结构,用CSPDarknet44作为主干特征提取网络,降低模型大小,提升训练速度。
CSPDarknet44网络结构如图2所示。网络输入图像尺寸为416×416,经3×3卷积核对输入图像进行卷积处理,激活函数选用泛化能力好的Mish函数。卷积后的图像经4个Resblock_body块继续深入提取特征,Reblock_body块主要包括主干和大残差边两部分,主干部分进行残差块的堆叠,另一部分将大残差边简单处理后与主干部分相连接。其中,4个Reblock_body块内部残差块堆叠个数分别为1、2、8、8,并将网络最后三层提取到的特征图供检测使用。
1.4 多尺度特征融合模块
1.4.1 融入通道注意力机制的特征融合
不同尺度的特征图经上采样或下采样操作完成尺度统一后,采用串联堆叠concat操作将不同尺度的特征信息融合。假设concat两路输入的通道数分别为1,2,…,X和1,2,…,Y,那么concat的单个输出通道如式(2)所示,其中*表示卷积。
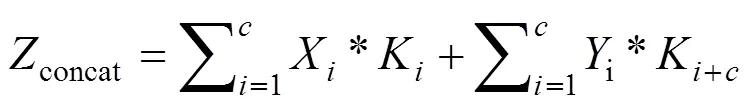
从上式可看出,concat操作只是实现通道维度上合并[17],并没有关注通道内在特征间的联系,易造成跨尺度融合中的混叠效应,使得融合过程中的信息衰减。受SENet的启发,将其引入到特征融合网络中,通过计算特征图每个通道与关键信息的相关度,对通道分配相应权重,增强特征图通道间的相关性。
图2 主干特征提取网络结构
Fig.2 Backbone feature extraction network structure
1.4.2 多尺度特征融合网络
将基于通道注意力机制的特征融合算法应用于多尺度特征融合网络中,网络结构如图3所示。整个网络主要流程:经CSPDarknet44网络特征提取后得到C2、C3、C4三个不同深度的特征层输入到多尺度特征融合网络,首先FPN结构使深层特征层信息融入到浅层中,将C4特征层上采样与中层特征层C3串联堆叠后,进行5次卷积生成特征图P3,P3再经上采样与浅层特征层C2融合,得到加强特征图P2。为了充分利用浅层特征信息,实现浅层特征层信息融入到深层中,PAN结构将浅层加强特征层P2经下采样与特征层P3融合,生成加强特征图N3,N3再经下采样与P4特征融合后,生成加强特征图N4。N2、N3、N4经通道注意力模块SE,对特征图每个通道上的权重进行显式建模,使得特征图能够自动学习通道间相关性,增强特征提取效果。
该网络结构设计有以下优点:①输入的有效特征层浅层信息更丰富,有利于红外特征信息保留,提高检测性能。②通道注意力机制SE的融入,避免了特征融合中信息衰减的问题。③输出的3个尺度加强特征图中因通道间权重关系得到优化,更加关注有效信息的存在,减少噪声信息干扰。
1.5 通道注意力机制SE模块
通道注意力SE可在增加少量参数量的情况下,分配特征图通道间的权重,加强对有用信息的关注的同时抑制噪声干扰,从而提升卷积神经网络性能。SENet网络结构如图4所示,给定一个输入特征图,高和宽分别为,,通道数为,通过全局平均池化global average pooling得到该输入层个feature map的通道权重数值分布情况,计算公式如式(3)所示:
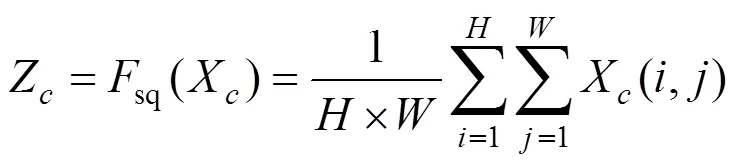
上式(3)将××的输入转换成1×1×的输出,对应图3中的sq操作。输出c表示为经过Squeeze压缩后得到的通道权重数组,长度为,X表示输入特征图,X(,)表示在输入特征图上坐标为(,)的点。
为了完全捕获通道间的相关性,将压缩得到的通道权重值Z经过一个全连接层操作1×Z,1的维度是/×,其中为缩放系数,在本文中取的是16,最终经过1全连接层后的结果是1×1×/,在经过一个Relu层其输出的维度不变;然后在经过一个全连接层操作2×Relu(1, Z),2的维度是×/,因此输出维度是1×1×,最后经过sigmoid函数激活,得到结果S,计算公式如式(4)所示:
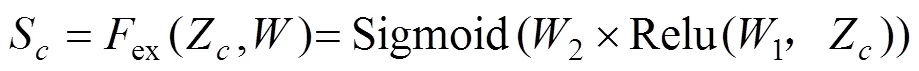
通过上述两个全连接操作得到了通道相关性,即通道注意力权重S。最后,加权调整输入特征图的通道,即把个通道都乘以相应的通道注意力权重,计算公式如式(5)所示:
X¢=scale(X,S)ÄS(5)
式中:¢为输入特征图经过通道注意力加权后的结果,符号“Ä”表示逐元素相乘,以上为通道注意力机制SENet模型的原理。
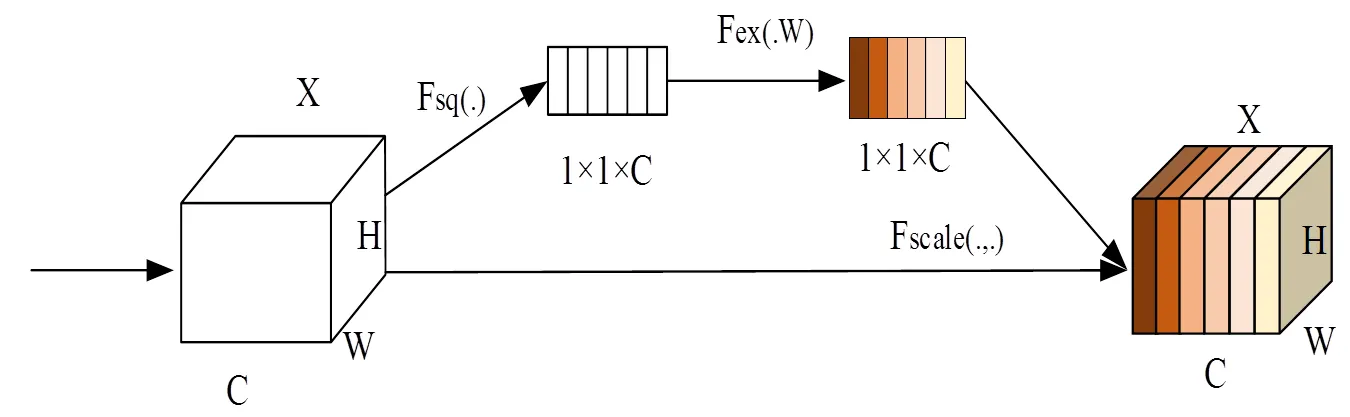
图4 SENet网络结构
2 实验结果与分析
2.1 数据集介绍
公开红外数据集的图像纹理特征更清晰,与实际中常用的红外摄像机成像差异较大。为使实验数据更加真实,切实解决现实问题,本文实验数据集采用自行采集的红外数据集,如图5所示。使用Xcore Micro Ⅱ系列非制冷红外摄像机拍摄全天不同时段、多个场景的户外街道上行驶的车辆、行人和自行车的视频,并将视频逐帧提取图片,经过筛选制作成红外数据集。该数据集中共4000张图片,分辨率大小为640×480,使用Labelme软件对车辆、行人、自行车3类红外目标进行PascalVOC格式人工标注。将数据集划分训练集:验证集:测试集=8:1:1,采用冻结训练的方式进行训练。

图5 红外数据集样本及人工标注示例
2.2 实验条件
本实验的计算机操作系统为Ubuntu 18.04,GPU型号为RTX 2080Ti,运行内存为16GB,CUDA版本为11.4。算法编写采用Pytorch框架,Python编程语言,Adam优化器动态优化网络参数进行训练。为加快训练速度,初始冻结主干网络并设置学习率r为0.001,batchsize为8,训练50个epoch;将主干网络解冻后,设置学习率r为0.0001,batchsize为4,训练150个epoch。
2.3 评价指标
本文通过平均准确率(Average Precision,AP)、(mean Average Precision,mAP)、参数量和模型大小等指标对目标检测网络的性能进行评价。其中AP、mAP值的计算与查准率Precision和召回率Recall有关,这两项计算公式如式(6)、(7)所示。
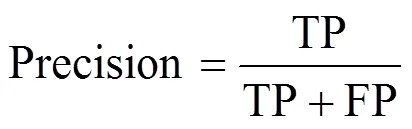
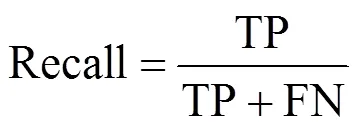
式中:TP(True Positives)为正确预测正样本的数量;FP(False Positives)为错误预测负样本的数量;FN(False Negatives)为错误预测正样本的数量。
以Recall为横轴,Precision为纵轴可以画出的一条-曲线,-曲线下的面积定义为AP值。AP与mAP计算公式如式(8)、(9)所示,其中代表目标检测类别数量。
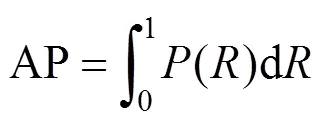
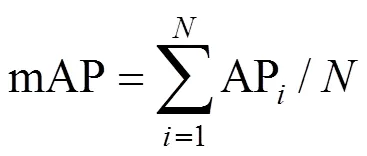
2.4 实验结果与分析
在自采的红外数据集上将本文SE-YOLOv4模型与多种目标检测模型进行实验对比,验证本文算法的有效性。
2.4.1 SE-YOLOv4与YOLOv4实验结果对比
将本文SE-YOLOv4算法与YOLOv4算法的检测实验结果进行对比,如图6所示。可以看出在SE-YOLOv4算法对3类目标的检测AP值均得到了提高,检测效果提升明显。其中,car目标AP值为93%,比YOLOv4的89%提升了4%;person目标AP值为90%,比YOLOv4的85%提升了5%;bicycle目标AP值为81%,比YOLOv4的70%提升了11%。
2.4.2 检测效果对比
本文SE-YOLOv4与YOLOv4算法在不同场景下进行的目标检测效果对比,如图7所示,其中(a)、(b)分别为YOLOv4和SE-YOLOv4算法的检测效果图。可以看出在多场景下进行红外目标检测,SE-YOLOv4检测效果得到很大提升。
图7展现了3组YOLOv4和SE-YOLOv4的检测效果实验对比图。在第一组图中,YOLOv4未检测到左侧车辆,SE-YOLOv4可对其精准检测。第二组图中,YOLOv4只检测到person,而SE-YOLOv4对不明显的bicycle也可以检测到。第三组图中,SE-YOLOv4对各目标检测精度均高于YOLOv4检测结果。
2.4.3 目标检测算法实验对比
为了进一步验证SE-YOLOv4算法的性能,将SE-YOLOv4与EfficientDet[18]、Faster R-CNN、SSD[19]、YOLO[10,12,20-21]系列算法进行实验对比,实验结果如表2所示。
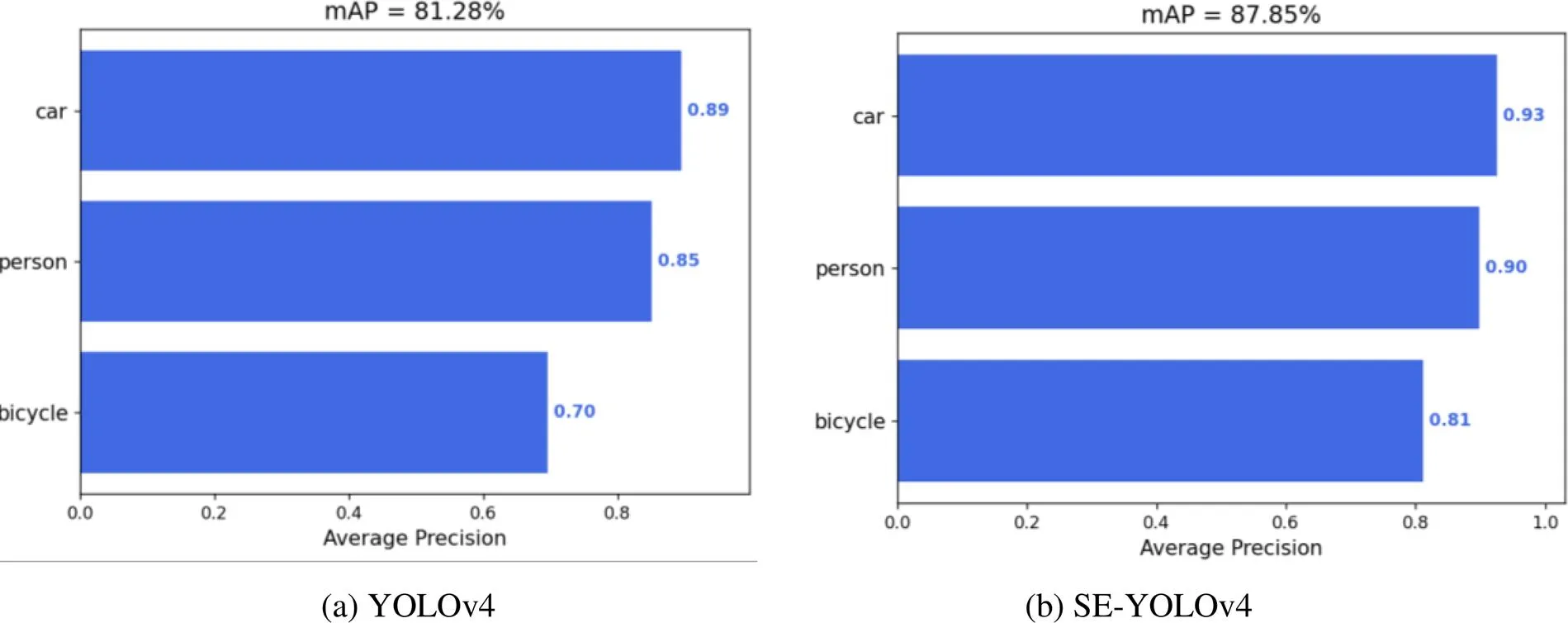
图6 YOLOv4和SE-YOLOv4检测精度对比

图7 SE-YOLOv4与YOLOv4检测效果对比
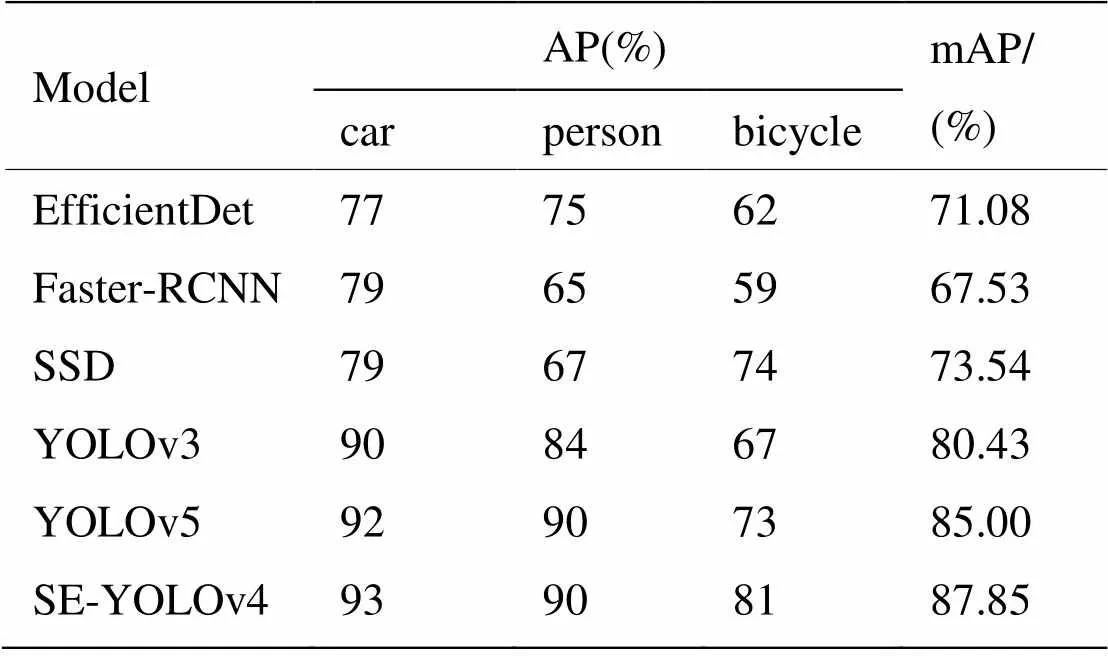
表2 相关目标检测模型实验结果
实验结果表明,本文算法SE-YOLOv4检测性能高于其他算法,mAP值为87.85%,比原YOLOv4算法的mAP值高6.57%,比EfficientDet、Faster-RCNN、SSD、YOLOv3、YOLOv5算法的mAP值分别高16.77%、20.32%、14.31%、7.42%、2.85%,说明本文SE-YOLOv4算法对于红外目标有更好的检测效果。
对比各类目标的AP值可以发现,YOLOv3、YOLOv4、YOLOv5算法在进行检测时对于低对比度的目标检测效果不好,bicycle表现的尤为明显,目标与背景差异小,相比于其他目标检测难度大。SE-YOLOv4算法通过重新设计多尺度特征融合策略,引入通道注意力机制的方式,增强网络对红外低对比度目标的特征提取能力。本文SE-YOLOv4算法实验结果中低对比度bicycle的AP值为81%,比YOLOv3高14%,比YOLOv4高11%,并且比目前性能最好的YOLOv5高7%,实验结果表明SE-YOLOv4算法大大提高了对红外目标的检测性能。
2.4.4 消融实验
为了分析每个模块对提高模型性能的作用进行了消融实验,实验结果如表3所示。消融实验共5组,分别是YOLOv4模型,重构多尺度特征融合的网络模型,加入改进主干网络后的模型,单独引入SE的模型以及本文SE-YOLOv4算法模型。
第二组实验通过改变多尺度特征融合网络中的有效特征层,充分利用浅层特征层信息进行多尺度特征融合,使得对3类目标的检测精度都得到了提升,尤其是针对低对比度目标bicycle的精度涨了10%,说明优化后网络选取的有效特征层在保持普通红外目标的检测精度的同时,有效提高了对红外低对比度目标的检测能力,并且网络参数量下降为YOLOv4的56.32%;第三组实验降低主干网络深度,在不影响特征提取能力的情况下减少了48.8%的网络参数量;第四组实验通过只引入SE通道注意力机制,提高网络抗干扰能力,对每一类目标的检测精度都有提升,mAP值提高了2.04%;最后一组实验即本文SE-YOLOv4算法,在主干网络和有效特征层改进后再引入SE,比第三组实验的mAP值高了1.9%。综上所述,本文SE-YOLOv4算法在检测精度上得到了很大的提升,网络模型大小仅为YOLOv4的28.87%,为红外目标检测提供了更好的性能。
2.5 在FLIR数据集上的实验对比
为了进一步验证本文SE-YOLOv4算法的检测性能,同时在FLIR公开红外数据集上进行实验对比,检测实验结果如表4所示。FLIR数据集由FLIR Black Fly热像仪拍摄,同样有行人、车辆、自行车3类目标,但与自行采集的红外数据集相比成像更加清晰,对比度更低,实验效果对比如图8所示。
表4中实验结果表明,与YOLOv3、YOLOv4、YOLOv5模型相比,SE-YOLOv4有更好的检测效果。SE-YOLOv4的mAP值比YOLOv4高了7.08%,比YOLOv3和YOLOv5分别高了21.42%、5.08%。其中,SE-YOLOv4算法对bicycle精度值提升最明显,比YOLOv4高20%,比YOLOv3和YOLOv5分别高37%、16%。
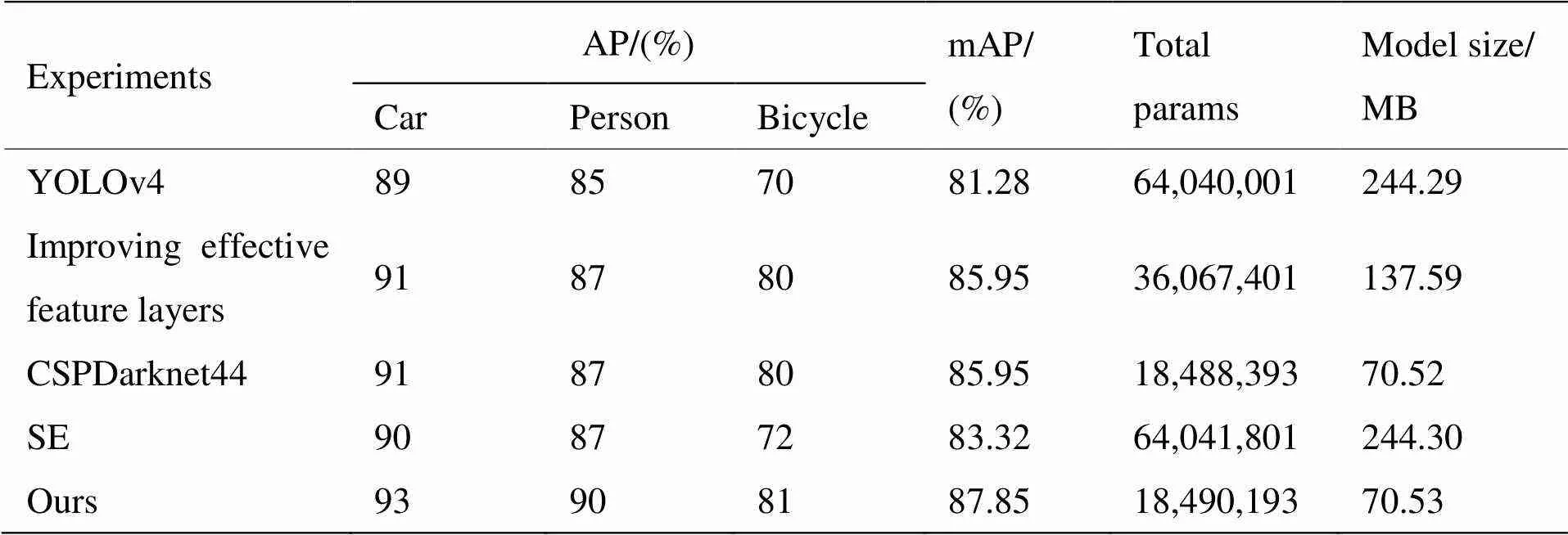
表3 消融实验
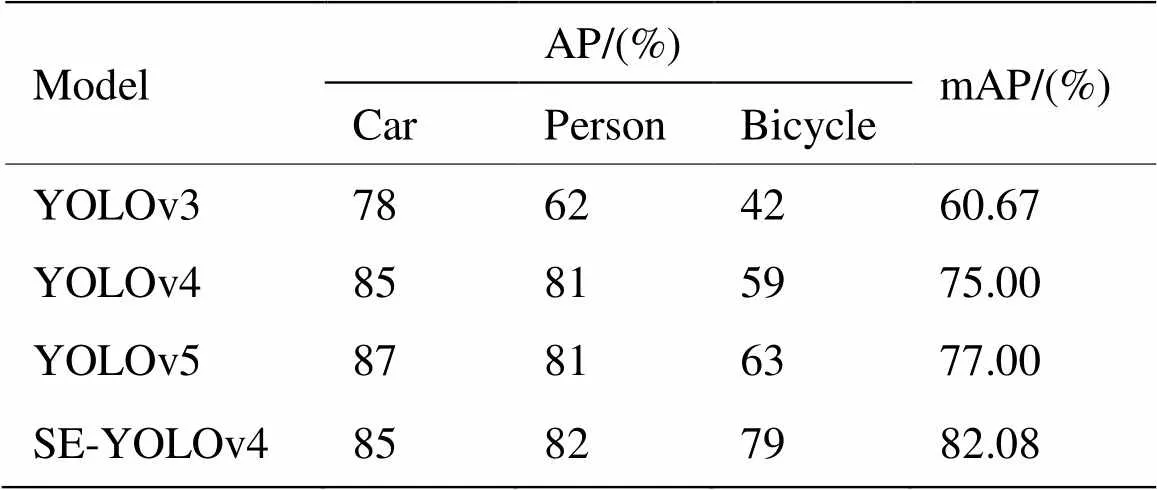
表4 相关目标检测模型实验结果
图8中展示了FLIR数据集在YOLOv4和SE-YOLOv4模型中的检测效果对比,左侧为YOLOv4检测图,右侧为SE-YOLOv4检测图。可明显看到对于对比度低、轮廓模糊的目标,本文算法检测性能更好。SE-YOLOv4通过充分利用浅层特征层信息,并融合注意力机制,以此加强红外目标特征提取能力,使得总体检测性能更强,准确度更高。
3 结语
针对红外目标特点,本文提出了融入注意力机制的多尺度红外目标检测模型,有效提高了红外目标检测精度,同时减少了网络冗余计算量。该模型重新构建了多尺度特征融合网络,网络中充分利用浅层特征层信息,有效缓解了因特征丢失导致检测准确度低的问题。其次,通过融入通道注意力让网络自动学习特征图通道间相关性,突出红外目标信息的同时提高了网络抗干扰能力。为了证明方法的有效性,在自采红外数据集和公开红外数据集中与相关目标检测算法进行对比测试,实验结果表明,本文算法模型大小仅为YOLOv4的28.87%,红外目标检测准确度得到了明显提升。但本文算法在检测中仍存在目标漏检现象,下一步工作将根据存在的问题继续研究,以达到更好的红外目标检测效果。
[1] 史泽林, 冯斌, 冯萍. 基于波前编码的无热化红外成像技术综述(特邀)[J]. 红外与激光工程, 2022, 51(1): 32-42.
SHI Zelin, FENG Bin, FENG Ping. An overview of non thermal infrared imaging technology based on wavefront coding (invited) [J]., 2022, 51(1): 32-42.
[2] CHEN C, LI H, WEI Y, et al. A local contrast method for small infrared target detection[J]., 2013, 52(1): 574-581.
[3] LIU R, LU Y, GONG C, et al. Infrared point target detection with improved template matching[J]., 2012, 55(4): 380-387.
[4] Teutsch M, Muller T, Huber M, et al. Low resolution person detection with a moving thermal infrared camera by hot spot classification[C]//, 2014: 209216.
[5] HAO Q, ZHANG L, WU X, et al. Multiscale object detection in infrared streetscape images based on deep learning and instance level data augmentation[J]., 2019, 9(3): 565.
[6] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//, 2014: 580-587.
[7] 顾佼佼, 李炳臻, 刘克, 等. 基于改进Faster R-CNN的红外舰船目标检测算法[J]. 红外技术, 2021, 43(2): 170-178.
GU Jiaojiao, LI Bingzhen, LIU Ke, et al Infrared ship target detection algorithm based on improved Faster R-CNN[J]., 2021, 43(2): 170-178.
[8] REN S, HE K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]., 2016, 39(6): 1137-1149.
[9] 刘智嘉, 汪璇, 赵金博, 等. 基于YOLO算法的红外图像目标检测的改进方法[J].激光与红外, 2020, 50(12): 1512-1520.
LIU Zhijia, WANG Xuan, ZHAO Jinbo, et al. An improved method of infrared image target detection based on YOLO algorithm[J]., 2020, 50(12): 1512-1520.
[10] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv: 1804.02767, 2018.
[11] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//, 2018: 7132-7141.
[12] Bochkovskiy A, Wang C Y, LIAO H Y M. Yolov4: Optimal speed and accuracy of object detection[J/OL].: 2004.10934, 2020.
[13] LIN T Y, Dollar P, Girshick R, et al. Feature pyramid networks for object detection[C]//(CVPR), 2017: 2117-2125.
[14] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//(CVPR), 2018: 8759-8768.
[15] LUO Y, CAO X, ZHANG J, et al. CE-FPN: enhancing channel information for object detection[J/OL].: 2103. 10643, 2021.
[16] 谢俊章, 彭辉, 唐健峰, 等. 改进YOLOv4的密集遥感目标检测[J]. 计算机工程与应用, 2021, 57(22): 247-256.
XIE Junzhang, PENG Hui, TANG Jianfeng, et al. Improved dense remote sensing target detection of YOLOv4[J]., 2021, 57(22): 247-256.
[17] 鞠默然, 罗江宁, 王仲博, 等. 融合注意力机制的多尺度目标检测算法[J].光学学报, 2020, 40(13): 132-140.
JU Muran, LUO Jiangning, WANG Zhongbo, et al. Multi scale target detection algorithm integrating attention mechanism[J]., 2020, 40(13): 132-140.
[18] TAN M, PANG R, LE Q V. Efficient det: Scalable and efficient object detection[C]//, 2020: 10781-10790.
[19] LIU W, Anguelov D, Erhan D, et al. SSD: Single shot multibox detector[C]//, 2016: 21-37.
[20] Redmon J, Divvala S, Girshick R, et al. You only look once: Unified, real-time object detection[C]//, 2016: 779-788.
[21] Redmon J, Farhadi A. YOLO9000: better, faster, stronger[C]//, 2017: 7263-727.
Multiscale Infrared Target Detection Based on Attention Mechanism
LI Xiangrong,SUN Lihui
(College of Information Technology, Hebei University of Economics and Business, Shijiazhuang 050061, China)
To address the problems of poor textural detail, low contrast, and poor target detection in infrared images, a multiscale infrared target detection model that integrates a channel attention mechanism is proposed based on Yolov4 (You Only Look Once version 4). First, the number of model parameters is reduced by reducing the depth of the backbone feature extraction network. Second, to supplement the shallow high-resolution feature information, the multiscale feature fusion module is reconstructed to improve the utilization of the feature information. Finally, before the multiscale feature map is generated, the channel attention mechanism is integrated to further improve the infrared feature extraction ability and reduce noise interference. The experimental results show that the size of the algorithm model in this study was only 28.87% of the Yolov4. The detection accuracy of the infrared targets also significantly improved.
infrared image, target detection, YOLOv4, attention mechanism
TN215
A
1001-8891(2023)07-0746-09
2022-04-10;
2022-07-20.
李向荣(1998-),女,硕士研究生,研究方向:图像处理、目标检测。E-mail: 243404315@qq.com。
孙立辉(1970-),男,博士,教授,研究领域:图像处理、数据分析。E-mail: Sun_lh@163.com。
河北省重点研发计划项目(20350801D)。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
金桥(2021年4期)2021-05-21 08:19:20
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
电子制作(2019年7期)2019-04-25 13:17:14
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
光学精密工程(2016年3期)2016-11-07 09:03:43
太空探索(2016年5期)2016-07-12 15:17:55
噪声与振动控制(2015年4期)2015-01-01 07:08:21
时代英语·高三(2014年5期)2014-08-26 17:01:17
