
深度学习在无人机遥感城市行道树提取中的应用
2023-07-26 06:15曹明兰李亚昆张力小武俊喜李亚东
中南林业科技大学学报 2023年6期
曹明兰,李亚昆,张力小,武俊喜,李亚东
(1.北京工业职业技术学院,北京 100042;2.北京市城市空间信息工程重点实验室,北京 100042;3.内蒙古乌兰坝国家级自然保护区管理局,内蒙古 赤峰 735499;4.北京师范大学 环境学院 环境模拟与污染控制国家重点联合实验室,北京 100875;5.中国科学院地理科学与资源研究所,北京 100101)
城市行道树作为城市生态系统的重要组成部分,对改善城市环境、净化空气、降噪遮阴等方面具有重要意义[1]。传统的城市行道树调查主要采用人员实地测量、仪器设备测量等方法手段,其工作量大、费时费力、效率低,无法满足管理部门高效监测的需求[2-3]。无人机数据采集具有成本低、周期短、影像分辨率高、操作简单、机动灵活等优点[4],已成为新的资源调查技术手段。无人机遥感进行城市行道树信息提取可以在很大程度上提高外业效率,降低外业工作成本。但由于内业处理需要空三加密、人工编辑DEM 和生成正射影像等流程,需要人工进行作业,内业成本较高,整体效率提升不大。深度学习的实例分割方法使自动从无人机影像中识别不同类型树种和分割树冠成为可能。
树冠是反映林分生长状况的重要参数[5],利用树冠参数可建立模型估测城市绿化树的生长量等情况。近年来,主要采用的树冠分割算法有局部最大值法[6]、梯度分割法[7]、面向对象分割法[8]、区域增长分割法[9]、分水岭分割法[10]和水平集分割法[11]等,虽积累了一定研究基础,但由于树冠影像纹理的复杂性和树冠边缘的不规则性等原因,这些方法对树冠分割结果的精确度仍有待提高。随着计算机视觉和人工智能算法的日渐成熟,越来越多的学者开始关注深度学习在城市行道树调查方面的应用[12]。深度学习领域的语义分割方法通过建立深层卷积神经网络并训练,可自动学习图像的特征,进行端到端的分类学习,大大提升了语义分割的精确度[13]。将语义分割的代表性模型U-Net 引入无人机影像树冠分割,可有效减少传统方法难以区分的地表绿色植被影响[14-15]。但语义分割是像素级的图像分类,只能分割同一类对象,无法分割不同树种。
本研究基于深度学习的实例分割代表性算法Mask R-CNN 模型,对无人机遥感城市行道树影像进行树冠分割,试图改善U-net 与分水岭等方法受树冠间局部灰度值差异影响而难以分割的问题。
1 材料与方法
掩膜区域卷积神经网络(Mask regionconvolutional neural network,Mask RCNN) 是较先进的深度学习模型,本研究尝试将计算机视觉和深度学习领域的先进算法应用于树冠分割领域。采用无人机搭载光学相机获得大比例尺高分影像和POS 数据,通过摄影测量软件结合地面控制点将影像处理为具有CGCS 2000 高斯3°带投影坐标的快拼正射影像(Digital orthophoto map,DOM)。借助深度学习的实例分割Mask R-CNN模型训练,构建单树树冠和树种预测模型。利用验证数据对模型训练的学习状况进行监测和评价,选出最优模型。再用测试数据对构建的学习模型做适应性评价,评估其树冠分割效果。技术路线如图1 所示。
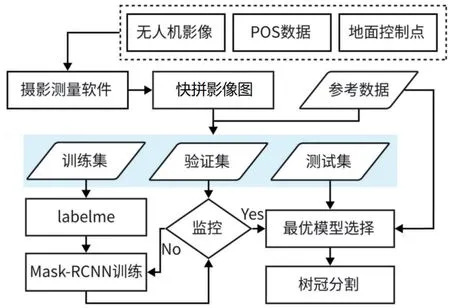
图1 技术路线Fig.1 Flow chart
1.1 研究区数据集构建
研究区位于云南省昆明市(102°10'~103°40'E,24°23'~26°22'N),研究区内行道树包括香樟1 446 株、法国梧桐417 株和银桦114 株。于2019 年6 月25 日和2019 年7 月3 日利用大疆无人机DJI Phantom 4pro,搭载DJI FC6310 相机,焦距9 mm,以航高200 m、航向重叠度90%、旁向重叠度75%,共获取1 200 张航摄像片,图像分辨率为5 472×3 648。在研究区内设置了多个GCP,生成空间分辨率为5.0 cm 的快拼影像图。将第一次获取的数据以7∶3 的比例构建训练集和验证集,将训练集用于训练模型以达到最佳估计精度,验证集则用于监测模型的学习进度和训练数据的过度学习。将第2次获取的数据作为测试集,用于测试模型的估计结果,并基于参照数据作精度评价。参照数据的株数为实地调查获得,单树树冠多边形通过皮尺测量树冠南北冠幅a和东西冠幅b,再根据树冠多边形面积S=πab公式计算获得。
1.2 MaskR-CNN 原理
基于深度学习的实例分割是对每个目标进行像素级的分类,将所有目标都区别开作为不同的目标,兼具语义分割和目标检测的特性。掩膜区域卷积神经网络Mask-RCNN(Mask regionconvolutional neural network) 是在Faster_RCNN基础上提出网络结构,主要实现目标检测和实例分割。MaskR-CNN 思想是将Faster R-CNN 和FCN 结合起来,首先利用卷积神经网络提取特征,然后区域生成网络(Region Propasal Network,RPN)得到可能存在目标的候选框( Region of interest,RoI),RoIAlign 将RoI 映射成固定尺寸的特征图(Fixed size feature map),特征图通过检测分支的全连接层(Fully connected layers)进行目标分类(Classification)和边界框回归(Box regression),通过分割分支的FCN 进行采样得到分割图,如图2 所示。
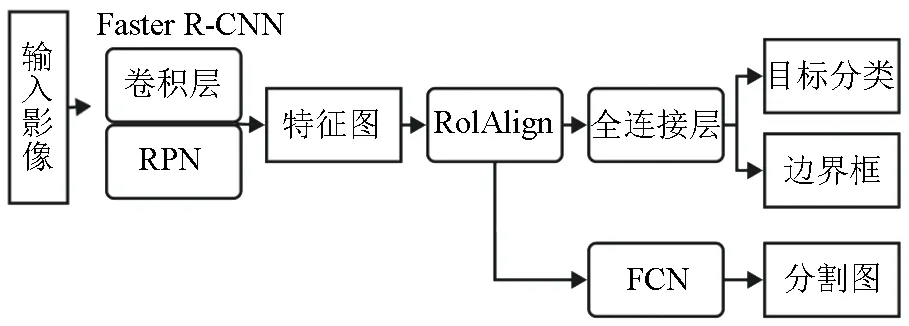
图2 Mask R-CNN 网络模型Fig.2 Mask R-CNN network model
RoIAlign 在将特征图中的RoI 池化为固定大小的特征图时,将每个单元的像素由原图四周真实像素利用双线性插值法获得该点像素,特征图的像素完整保留了原图像素和精确的空间位置,实现了像素到像素的匹配。实例分割是对RoIAlign输出的特征图进行分类、回归和分割,检测每个ROI 的类别和边界框坐标,对每个类别独立预测一个二值掩膜。如果把整个网络看作多任务操作,则损失函数是多任务的相加。在训练期间,采样RoI 多任务损失函数为L,则:
L=Lcls+Lbox+Lmask。
式中:Lcls为分类损失函数;Lbox为边界框损失函数;Lmask为掩膜损失函数。
1.3 深度学习算法改进
MaskR-CNN 对每一类具有重叠的多个检测物利用非极大值抑制NMS(Non-maximum suppression)算法来抑制同一物体被重复检测。NMS 对同一类型的两个重叠检测物的边界框超过阈值IoU(Intersection of union)时,仅保留得分最高的边界框。对城市行道树普遍存在的树冠粘连情况,强制去掉得分低的预测框会导致漏检,不适用于树木类物体的检测,而且速度慢,算法涉及多重循环,在进行大量预测框的计算时耗时较长。本研究先不考虑类别,而对所有检测树进行NMS。由于城市行道树影像的边界框中存在大量无行道树的空白部分,会影响取舍选择的准确性。因此,在模型建立后的估计阶段不强制丢弃得分低的预测框,但降低NMS 估计结果的得分,使检测密集树冠目标时不至于漏检,有效提高了准确率。在结果输出后添加掩模处理:先在所有检测物中得分高的认定为检测树,然后计算已检测的树冠区域和待检测掩模的重叠区域占待检测掩模面积的比例。如果该比例超过阈值0.5,则判断重复检测;如果比例小于阈值0.5,则只将未重叠区域认定为新的检测树区域。
本研究采用检测率DR(正确检测的数量比参照树的数量)、误检率FDR(错误检测的数量比参照树的数量)、漏检率LDR(未被检测树的数量比所有检测树的数量)、分类精度CA(检测树中被分类正确的数量比所有检测树的数量)和总体精度TA(检测率与分类精度的乘积)等指标作为精度评价指标。按照以下步骤判断树冠检测是否正确。1)计算所有参照树和检测树的重心间距;2)根据重心间最短距离确认对应关系;3)去除已确认对应关系的参照树与检测树,重复第二步直至确认全部。将参照数据出现的余数视为未检测树,将检测树产生的余数视为错误检测;4)确认对应关系后,参照数据和检测树的树冠多边形有重叠才视为正确检测,没有重叠则视为错误检测。
2 结果与分析
2.1 深度学习框架与模型训练
本研究中的数据训练和测试均采用Windows系统GTX1080TI 显卡(12 GB 显存)的同一台服务器。开发环境为Ubuntu 16.04、Python 3.5.2、TensorFlow 1.9.0 和Keras 2.2.4 等。利用VIA 图像标注工具进行行道树树冠范围的标绘和树种的标注,并保存在Json 文件。选取可移植性高、支持多种深度学习模型的人工智能学习系统TensorFlow 机器学习框架,同时选取了在深度学习应用方面具有多线程计算、简易和快速原型设计等优点的Keras 人工神经网络库。选用ResNet-101作为主干网络,使用COCO 数据集根据事先学习过的权重进行精细调整(Fine-tuning),以适应单树冠和树种分类问题。此外,使用随机梯度下降法(Stochastic gradient descent;SGD)作为网络中权重的优化算法,设置反复训练数epoch 为500、初始学习率为0.001,Moments 系数为0.9,权重衰减系数为0.000 1。
2.2 模型性能分析
在模型训练阶段,使用训练数据和验证数据计算的掩膜损失值,进行学习状况监测和测试数据的模型筛选。模型筛选时,随着模型训练迭代次数的增加,训练数据和验证数据的网络掩膜损失值均逐渐减小并趋于稳定,且在训练100 次以内下降速度很快。当模型训练次数在300~500 时,总体精度均值与损失值趋于稳定,网络达到收敛状态,掩膜损失值最终减少到1.4左右,如图3所示。

图3 模型训练损失值与总体精度Fig.3 Model training loss and total accuracy
本研究改进Mask R-CNN 模型在431epoch 时,模型的整体精度值最高,选择其作为最佳模型。最佳模型的总体精度TA 平均值为0.839(DR=0.858,CA=0.978),误检率平均值为0.130。
2.3 改进Mask R-CNN 模型验证
本研究基于相同的数据源,利用验证集建立的最佳模型估计测试集数据,并将本方法与人工提取方法进行对比分析。人工提取方法利用GIS软件,人工采集单木树冠和目视判断树种类型。图4 展示了不同方法对3 种行道树的分割效果,同时在本方法提取结果的基础上,对识别率低的数据进行人工修正作为第3 种方式进行对比分析。测试数据的每棵树都被分割出树冠边界,同时赋予了树种信息,结合参照数据计算3 种方法的精度评价指标,结果如表1 所示。

表1 不同方法精度对比Table 1 Comparison of precision between different methods

图4 检测与分割结果Fig.4 Detection and segmentation results
图4 分别展示了原图、本方法分割和人工提取树冠多边形的示例。作为行道树,法国梧桐一行、香樟树一行同时栽植在道路两侧,而银桦则在道路两侧同时栽植2 行。图4a 的左图中有香樟树和法国梧桐,右图则分布2 行银桦行道树。其中香樟树的冠形呈椭圆、边缘规则,法国梧桐树由于树龄较小,叶片稀疏,树叶呈深棕色。银桦树的树龄也较小,刚刚发出数层树叶,还未形成银桦典型树冠形状,树冠冠幅较小,呈不规则形。图4b 为本方法对3 种行道树树冠的分割效果,对树冠边缘清晰、树冠形状规则的香樟树分割效果与图4c 中人工提取效果最接近。本方法的法国梧桐树冠边界提取较平滑、树冠范围提取比人工提取稍大,包含一些空白部分,没有人工提取精细。
本方法中,3 种行道树的平均总体精度能达到0.865,而在此基础上对识别率低的数据经过人工参与简单修正后至少提高了8.3%。而本方法的平均检测率和分类精度也达到了0.887 和0.974,再经人工修正后,行道树的平均检测率提高了7.8%。本方法能够降低树冠粘连的密集树冠目标的漏检率,统计结果表明,本方法的平均漏检率仅为0.089,再经过人工修正后,漏检率大幅降低至0.017。本方法不论是检测率还是分类精度,均能够满足城市行道树的调查要求,而且识别率低的数据经过针对性人工修正后数据精度显著提高(DR=0.965,CA=0.982),与纯人工提取方法的精度(DR=0.978,CA=0.992)无较大差别,但能够节省大量的外业实地调查时间和内业人工提取工作量。
3 种行道树在本方法的树冠检测与分割中,香樟树的总体精度最高,为0.922(DR=0.941,CA=0.980),银桦为0.852(DR=0.877,CA=0.971),法国梧桐最低,为0.821(DR=0.844,CA=0.972)。香樟树的树冠形状规则而且训练数据量相对较多,因此其检测率最高,比银桦高6.4%,比法国梧桐高9.7%。而分类精度CA 虽然在3 种行道树之间存在偏差,但总体结果良好,未发现较大差异。由于树龄较小的香樟树的树冠和银桦树冠之间比较相似,导致出现一定的误检测,但误检测水平较低,且3 种行道树之间无较大差异。本方法对不同行道树的整体检测效果较好,但仍有一些漏检情况出现。法国梧桐树的漏检率(LDR=0.132)稍高于香樟和银桦,是因为数据采集时法国梧桐树叶呈浅棕色,与影像中背景马路的颜色非常接近导致边缘不清晰,加上其冠形不规则、树叶较稀疏,导致出现一定的漏检情况。
3 结论与讨论
3.1 结 论
本研究使用无人机系统采集了高空间分辨率行道树影像,基于深度学习的Mask R-CNN 实例分割模型实现了城市行道树树冠的自动检测与分割,并与本方法人工参与修正和人工提取方法进行了对比分析。结果表明,本方法的行道树树冠自动分割平均总体精度为0.865、平均检测率为0.887,如果再经过人工简单修正,则行道树树冠分割平均总体精度能达到0.948、平均检测率能达到0.965。
1)本研究中,城市行道树的树冠检测与分割方法采用非极大值抑制NMS 算法对所有检测树进行非极大值抑制,在模型估计阶段不强制丢弃得分低的预测框,而是将其保留但降低NMS 估计结果的得分,从而降低了粘连树冠目标检测时的漏检率,有效地提高了准确率。
2)本方法可面向单株树冠进行实例分割,不需要采用形态学处理粘连树冠,自动化程度较高。该方法不仅能检测株数,还能分割不同树种类别,进而判断树种组成,对城市行道树调查具有现实意义。
本方法的检测率和分类精度受行道树的树冠形状和树龄影响。冠形规则、颜色均匀、树叶茂密树种的检测率和分类精度均高于冠形不规则、颜色接近背景色、树叶稀疏的树种。树冠大小与树龄成正比,不同树龄的树冠形状有所变化,从而影响分类精度。一般,对于冠形不规则、树叶稀疏的目标,均衡考虑样本数量可降低冠形和树龄对精度的影响。行道树分布稀疏,树木附近往往有道路、围栏等障碍物,外业人工调查成本高、效率低。无人机可非接触式快速高效地采集行道树数据,结合深度学习的Mask R-CNN 实例分割算法能自动提取较准确的树冠检测与轮廓分割信息,可节省大量外业调查和内业数据处理时间,对提升城市行道树监测效率和自动化水平具有重要意义。
3.2 讨 论
随着计算机数据处理能力和深度学习方法的快速发展,能够全自动获取单树级信息的方法也不断出现创新型探索,因此面向实际需求需要解决的问题也很多。为了提高模型的实际可用性,有必要建立一个不受林分条件限制的模型,因此不能忽视以下几个方面:
1)探索针对单株树冠和树种估计的最佳方法。本研究采用了实例分割的Mask R-CNN 方法,但相继又出现了TensorMask、SOLOv2 等实例分割的新方法,可在其中选择针对单株树冠分割的最佳方法。
2)数据轻量化和学习效率的提高。与机器学习方法相比,基于深度学习的实例分割Mask R-CNN方法需要更多的训练数据进行充分的学习,适合较大范围的无人机数据采集,不适合小规模、小范围的临时性任务。因此,能否利用更少的数据构建更高精度的模型仍然是今后研究和探索的方向。本方法中参考数据的制作需要一定的经验和时间,因此,探索最佳的数据扩展方法和数据输入模式等方面需要进一步深入研究。
3)构建数据收集系统。要想提高树种分类和泛化性能,则需要各地区各时期的不同数据构建训练数据集,可通过联合各地区林业管理部门共建共享联合数据库,以提高制作参考数据的效率。
猜你喜欢
公民与法治(2022年11期)2022-12-06
军事文摘(2022年8期)2022-11-03
小学科学(学生版)(2021年3期)2021-04-13
哈哈画报(2021年11期)2021-02-28
家教世界·创新阅读(2021年12期)2021-01-13
东方企业家(2020年5期)2020-05-29
山西文学(2019年8期)2019-11-01
文学港(2019年5期)2019-05-24
现代园艺(2017年22期)2018-01-19
中华老年口腔医学杂志(2016年1期)2017-01-15
