
基于YOLOv5s改进的口罩佩戴检测算法
2023-07-21 01:15葛延良李德鑫王冬梅董太极
黑龙江大学自然科学学报 2023年3期
葛延良, 李德鑫, 王冬梅, 董太极, 贺 敏
(1.东北石油大学 电气信息工程学院, 大庆 163000; 2.中国移动通信集团黑龙江有限公司 大庆分公司, 大庆 163000)
0 引 言
根据世界卫生组织的通告,戴口罩是预防新型冠状病毒等空气传播传染病最有效的措施之一。疫情期间,为了有效减少新型冠状病毒的传播,在公共场所或室内工作时,应当佩戴口罩。采用人工监督和检测方法不仅耗费人力,还会存在与被检查人员接触从而感染病毒的风险。因此,对于企业和商场等公共场所来说,能够实时的进行口罩佩戴检测是非常有必要的。
随着深度学习技术的飞速发展,使得计算机视觉领域取得巨大进展。目标检测属于计算机视觉中非常重要的研究方向,目前主要有基于双阶段的目标检测算法和基于单阶段的目标检测算法两类。其中,基于双阶段的目标检测算法的典型代表主要有区域卷积神经网络(Region-convolutional neural network, R-CNN)[1]、快速的区域卷积神经网络(Fast Region-convolutional neural network, Fast R-CNN)[2]、更快的区域卷积神经网络(Faster Region-convolutional neural network, Faster R-CNN)[3]、基于掩码分割的区域卷积神经网络(Mask Region-convolutional neural network, Mask R-CNN)[4]、特征金字塔网络(Feature pyramid network, FPN)[5]等,此类算法对目标进行检测时分为两个步骤:首先生成一系列候选框,再用卷积神经网络进行分类和边框回归。基于单阶段的目标检测算法把生成候选框和分类回归这两个步骤合并在一个网络中进行,常见的基于单阶段目标检测算法有OverFeat[6]、单阶段多锚框目标检测器(Single shot multibox detector, SSMD)[7]、你只需看一次(You only look once, YOLO)[8-11]系列等。考虑到在实际监控任务中需要达到实时检测的目的,而单阶段的目标检测算法在检测速度上可以达到实时的效果。
近年来,为了解决口罩佩戴检测的精度与速度问题,许多学者都已经将YOLO系列目标检测算法应用到了口罩佩戴检测应用中。张烈平等使用MobileNetV2作为特征提取网络与YOLOv2相结合构成口罩佩戴检测网络模型,使其均值平均精度(mean average precision,mAP)达到91.3%[12]。张鑫等将在特征提取网络中引入空间金字塔池化,并结合GIoU损失函数,在其使用的数据集上对比原始YOLOv3将mAP提高到90.1%[13]。王艺皓等提出在YOLOv3算法中引入改进的空间金字塔池化结构,从而实现特征增强,在其使用的数据集上mAP达到90.2%[14]。谈世磊等基于YOLOv5网络模型,在原数据集基础上进行扩充,采用翻转和旋转两种方式得到30 000张图片来用于训练,使mAP达到92.4%[15]。Yang等采用将GIoU与Center Loss相结合的方式来提升口罩识别精度,在其数据集上mAP达到97.9%[16]。Popescu等通过将YOLOv5与ResNet相结合,使得在其数据集上mAP达到87%[17-18]。因此,本文选择YOLOv5s算法为基础进行口罩佩戴检测。
为了解决错检和漏检等问题,Hou等提出协调注意力机制(Coordinate attention, CA)模块来提高检测性能[19]。本文通过在YOLOv5s网络模型中融入改进的CA注意力机制模块CA-A来增强网络的特征提取能力,并引入改进的CIoU损失函数AD-CIoU来提高边界框的定位准确度。实验表明所提出的口罩佩戴检测算法精度相较于YOLOv5s有所提升。
1 口罩佩戴检测模型设计
1.1 改进的YOLOv5s模型设计
YOLOv5s的网络结构由四部分组成,分别为输入端、主干网络Backbone、Neck和输出端,其网络结构如图1所示。YOLOv5s所使用的主干特征提取网络为跨阶段局部网络(Cross stage partial dark network, CSPDarknet),其中包含了CBS模块、C3模块[20]和空间金字塔池化模块(Spatial pyramid pooling, SPP)[21]。CBS模块可以在图像进行下采样,其中第一个CBS模块的卷积核尺寸为6×6用于替换Focus结构,以达到提高运算速度、减少内存开销的目的。C3模块主要功能为图像特征的提取,SPP模块主要解决了卷积神经网络对图像进行重复特征提取的问题,既提高了产生候选框的速度又节约了计算成本。但是小目标特征信息在C3模块多次作用下,容易造成丢失现象,从而引起错检与漏检问题。为了提高检测的精确度,在C3模块后引入改进的CA-A注意力机制模块来增强网络特征提取能力,达到提升检测精度的目的。改进后的Backbone 如图2所示。
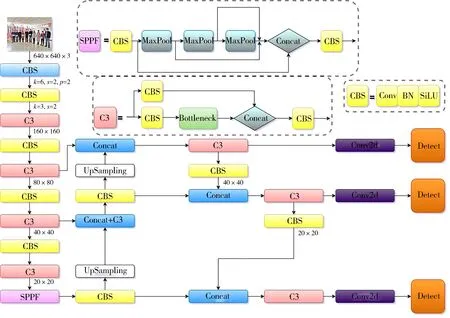
图1 YOLOv5s网络
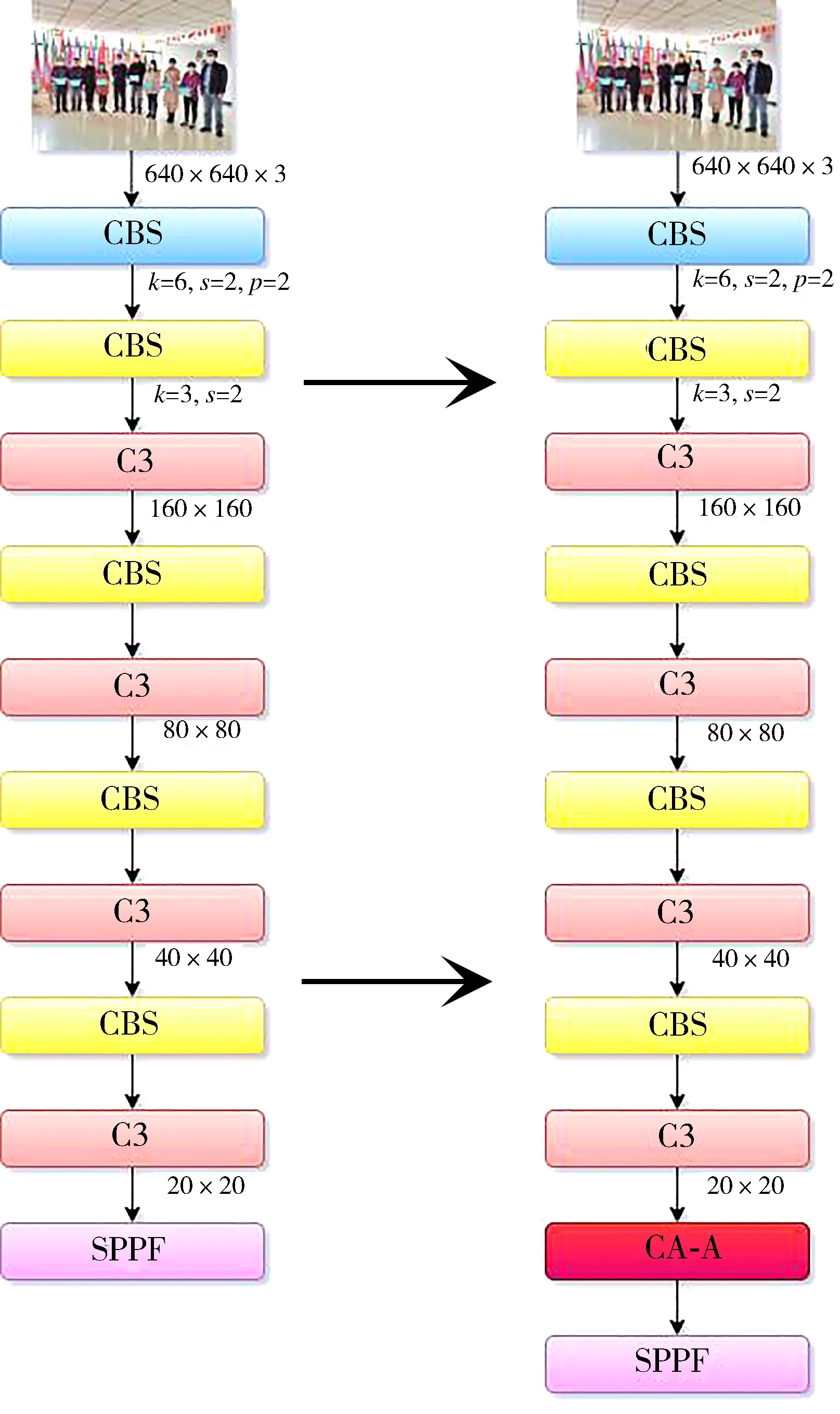
图2 改进的主干网络
1.2 注意力机制的创新
CA注意力机制模块使用的是Sigmoid归一化,但是Sigmoid函数会存在梯度饱和现象,即在当X>>0或X<<0时,梯度接近于0,导致训练缓慢和梯度消失。因此,提出了一个改进注意力机制模块CA-A,将ACON激活函数与CA注意力机制模块相融合的方法。与通过二维全局池化将特征张量转换为单个特征向量的通道注意力不同,CA-A注意力模块可以看作一个计算单元,其目的是增强网络模型的特征表达能力。CA-A注意力机制通过坐标信息嵌入和坐标注意力生成两个步骤来进行编码,这种编码过程可以提升坐标注意力的准确度,从而帮助模型更好识别特征信息。ACON激活函数可以学习并决定是否要激活神经元,从而提高检测精度。CA-A注意力机制模块的水平与垂直的特征信息由XAvg Pool和YAvg Pool沿着x与y轴做平均池化提取,随后进行特征信息的聚合并使用 ACON 激活函数进行归一化,具体如图3所示。

图3 CA-A注意力机制模块
1.3 损失函数的改进
原YOLOv5s网络模型中采用了CIoU作为Bounding Box的损失函数,其公式定义为:
(1)
由于CIoU采用的是预测框与真实框的宽和高的比值,所以会存在一定的模糊性,即一旦收敛到预测框与真实框的宽和高的比值呈线性比例状态时,会导致预测框回归时宽和高不可以同时增加或减少。为解决上述问题,提出了AD-CIoU,将CIoU结合角度损失与距离损失来提升边界框定位的精确度。角度损失公式定义为:
(2)
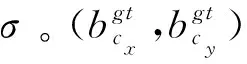
(3)
(4)
(5)
距离损失的定义和具体参数公式为:
(6)
(7)
(8)
γ=2-Λ
(9)
改进后的YOLOv5s网络模型的回归损失函数AD-CIoU公式为:
(10)
2 实验过程及结果分析
2.1 模型训练
采用Kaggle的Face mask detection数据集进行训练,此数据集一共5 049张图片,其中训练集含有3 390张图片,验证集与测试集分别为699张和960张图片。
具体的测试环境:CPU采用12核 Intel(R) Xeon(R) Silver 4110 CPU @ 2.10GHz,GPU为Nvidia GeForce RTX 2080ti。深度学习框架为PyTorch1.8.1,编译语言Python3.8,Cuda版本为11.1。
在目标检测领域,性能评价指标常用精准率P(Precision)、召回率R(Recall)和均值平均精度mAP(mean average precision)来进行衡量检测效果。其具体计算公式为:
(11)
(12)
(13)
采用官方预训练权重,输入图像的尺寸大小为640×640,训练的批量大小Batchsize为16,迭代次数Epoch为300次。
2.2 实验结果
原YOLOv5s与改进的YOLOv5s的mAP数据对比如图4所示。图中YOLOv5s的map@0.5达到了0.944,改进后的YOLOv5s的map@0.5达到了0.961,提升了1.7%。

图4 数据对比图
2.3 YOLOv5s消融实验
为验证本研究提出的改进方案,在相同的实验环境与数据集下,进行消融实验。实验结果如表1所示。可以看出,在引入CA注意力机制时,检测均值平均精度mAP达到了0.957。CA注意力融合AD-CIoU损失函数时,召回率Recall提升到0.929。仅使用CA-A注意力机制时,mAP提升到了0.959。CA-A结合AD-CIoU损失函数在精度Precision和均值平均精度mAP上均有提升,可见改进的方案相比原YOLOv5s有明显优势。

表1 YOLOv5s消融实验
2.4 对比实验
为了验证本研究提出的改进算法具有更好的检测效果,选择YOLOv3-tiny、YOLOv4-tiny、YOLOv5s以及YOLOv5s结合SENet和CBAM注意力机制在相同配置下进行对比实验,结果如表2所示。
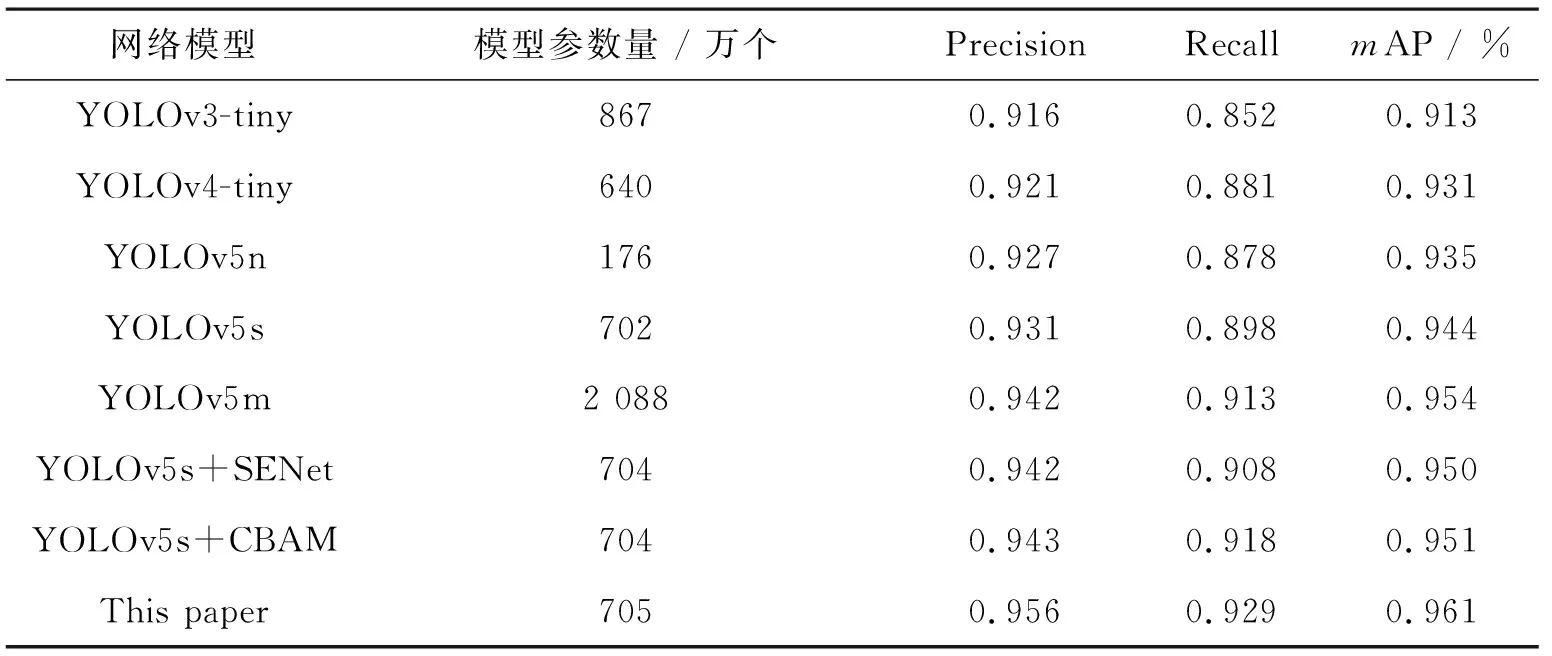
表2 不同网络对比数据
为了展示改进的YOLOv5s网络模型的检测效果,从测试集中随机选取图片进行测试,原YOLOv5s网络模型与改进后的YOLOv5s网络模型的对比数据如图5和图6所示。原始YOLOv5s在图中的平均检测精度达到了0.85和0.83,改进的YOLOv5s在图中的平均检测精度可以达到0.95和0.91,可见在多人密集的情况下,改进后的YOLOv5s网络模型具有更高的检测精度。

图5 YOLOv5s检测效果

图6 改进的YOLOv5s检测效果
3 结 论
为了提升口罩佩戴检测的精度,提出了一种基于YOLOv5s改进的口罩佩戴检测算法。原CA注意力机制模块使用Sigmoid归一化会存在梯度消失和训练缓慢等问题,所以将ACON激活函数融合CA注意力机制模块构成新的CA-A注意力机制模块,并结合在原始YOLOv5s的主干网络部分,通过坐标信息嵌入和坐标注意力生成两个步骤来提升坐标注意力的准确度,从而达到增强网络的特征提取能力;CIoU损失函数一旦收敛到预测框与真实框的宽和高的比值呈线性比例状态时,会导致预测框回归时宽和高不可以同时增加或减少,为了改善其定位的模糊性,将CIoU通过结合角度损失和距离损失来构建新的AD-CIoU损失函数,以达到提升回归精度的目的。经过实验结果证明,改进后的算法相比原始YOLOv5s网络模型mAP提升了1.7%,达到了96.1%,同时与其他算法对比明显具有更高的精确度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
作文大王·笑话大王(2019年3期)2019-04-22
电子制作(2018年11期)2018-08-04
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
河南科技(2014年14期)2014-02-27
