
PCA-LDA法结合近红外光谱用于酵母水解物真假判别及产地溯源
2023-07-20 11:39谢嘉刘健秦磊磊薛刚李亚茹刘静怡赖衍清
化学分析计量 2023年6期
谢嘉,刘健,秦磊磊,薛刚,李亚茹,刘静怡,赖衍清
[1.酵母功能湖北省重点实验室,湖北 宜昌 443000;2.三峡公共检验检测中心,湖北 宜昌 443000;3.珀金埃尔默企业管理(上海)有限公司,上海 200000]
酵母水解物广泛应用于水产业[1‒2]与家畜业[3‒4],它可以有效增强动物体的免疫力,改善动物体内的肠道环境,促进细胞的修复与再生,从而加快动物体的生长速度。不同工厂、不同工艺生产的酵母水解物,其营养价值存在明显差异。目前研究农产品溯源以及真假判别主要有稳定同位素分析技术[5‒6]、矿物元素指纹分析技术[7‒8]、氨基酸与脂肪酸指纹分析技术[9]以及近红外光谱分析技术[10‒11]。前三种分析技术对实验人员要求较高、耗时耗力,而近红外光谱分析技术具有方便快捷、无须任何预处理、信息量丰富、光谱特性稳定、重现性佳等诸多优点,在真假判别以及产地溯源方面具有很好的应用前景。
利用近红外光谱法对酵母水解物溯源分析以及真假判别目前还没见报道,笔者采用主成分分析(PCA)法对预处理后的不同工厂、不同工艺的酵母水解物光谱进行分类,提取最佳主因子数,再结合线性判别分析(LDA)法,建立了酵母水解物产地溯源以及真假判别模型,所有样品识别准确率均超过85%,为近红外光谱分析技术在酵母水解物产地溯源以及真假判别方面的研究提供理论依据。
1 实验部分
1.1 主要仪器与试剂
近红外光谱仪:FT9700型傅里叶近红外变换光谱,美国珀金埃尔默公司。
酵母水解物样品:在3 个酵母工厂的生产线直接取样,根据不同工厂、不同工艺、不同时间段,共采集样品500 个,其中NA-Y 系列59 个、NA-L 系列108个、NA-C系列101个、NX-C系列122个、NX-L系列110 个,市场随机选取伪劣样品MF 10 个。训练(建模)样本集与预测样本集见表1。
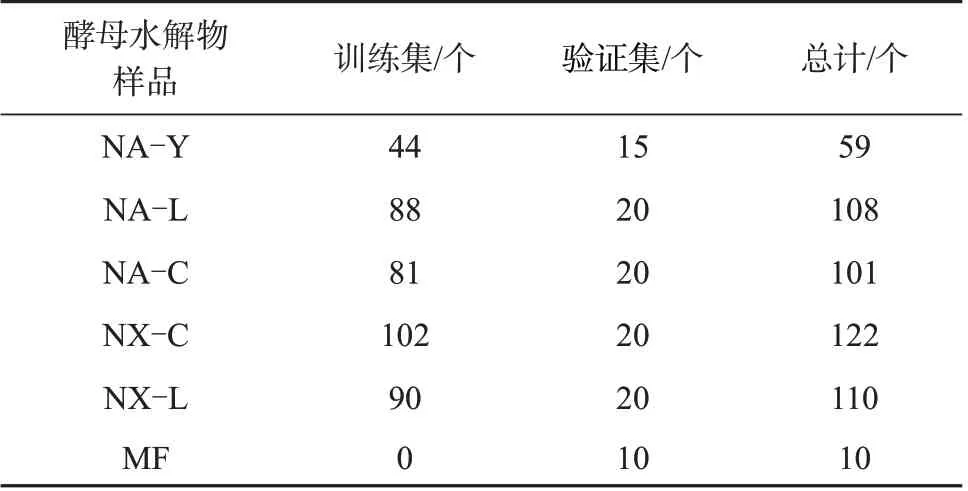
表1 训练(建模)样本集与预测样本集
1.2 近红外光谱仪参数
干涉仪:Michelson 干涉仪;光源:卤钨灯光源;样品杯:蓝宝石材质,主要成分为三氧化二铝;分束器:宽范围多镀层CaF2;光谱扫描次数:64 次;分辨率:8 cm-1;光谱范围:14 304~3 856 cm-1;漫反射采样附件:电磁驱动旋转样品盘,保证光谱数据的均一性。
1.3 光谱采集
使用漫反射模式采集光谱,考虑到酵母水解物可能会吸潮,扫描之前要保持干燥、恒温的环境,室温为25 ℃、相对湿度为45%左右时最佳。每个样品扫描3次,取其平均值作为样品的典型光谱。
2 结果与讨论
2.1 主成分分析(PCA)
光谱数据采集软件为Results Plus (Perkin Elmer,版本号:3.19.21170),建模训练集的原始图谱如图1所示。
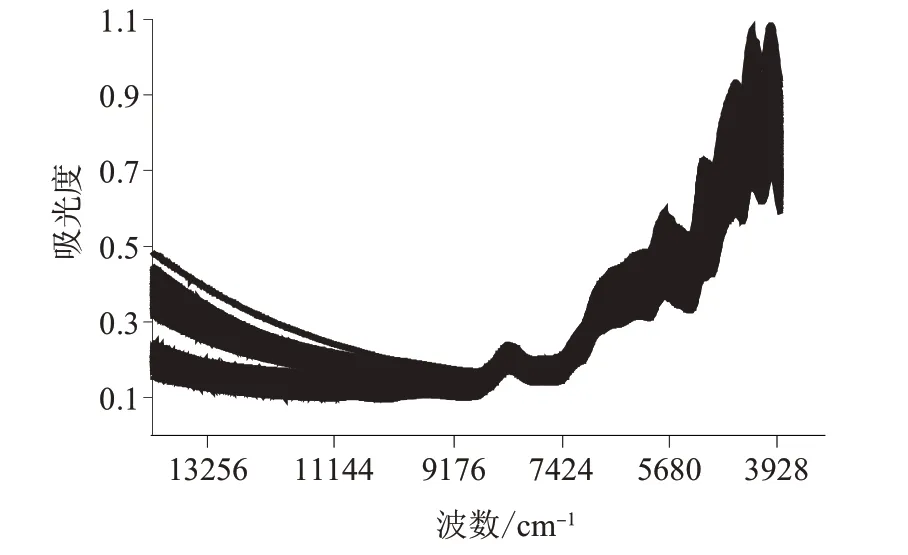
图1 酵母水解物(训练集)原始图谱
采用非线性迭代偏最小二乘法进行主成分分析[12‒13]。考虑到酵母水解物属于生物样品,近红外光谱信息量丰富,遂使用14 304~3 856 cm-1全波数光谱进行预处理:采用一阶求导法、平滑滤波法[14]可有效消除基线以及其它背景的干扰,进而提高分辨率和灵敏度;采用标准正态变量转换消除样品表面散射、固体颗粒大小以及光程的变化对近红外漫反射光谱的影响;采用多元散射校正消除颗粒大小以及颗粒分布不均匀产生的散射影响;采用去趋势算法消除漫反射光谱的基线漂移。
将上述光谱预处理方法进行不同的结合[15‒16],并对预处理后的光谱进行主成分分析,根据不同主因子数的特征值,选择最佳光谱预处理方法。特征值的大小代表矩阵正交化后所对应特征向量对整个矩阵的贡献程度。某主因子数所对应的特征值越大,则说明该主因子数所包含的样品信息量越丰富。如果某主因子数所对应的特征值为0,则说明该主因子数不包含任何信息,变量为常数。当变量与矩阵X之间存在一定程度的线性相关时,X的变化将体现在最前面几个载和向量(主因子数)方向上,X在最后几个载和向量(主因子数)的投影很小,可以认为它们是由测量噪声所引起的。
不同预处理方法光谱主成分分析的各主因子数特征值见表2。由表2可知,使用多元散射校正对全光谱进行预处理,对处理后的光谱进行主成分分析,各主因子数所对应的特征值几乎都为0,变量与矩阵X没有线性关系,说明多元散射校正光谱预处理无法用于酵母水解物产地分类;使用平滑滤波法联合一阶求导法,各主因子数所对应的特征值也几乎都为0,不适用于酵母水解物产地分类。使用平滑滤波法、一阶求导法、标准正态变量转换法,三者联合用于近红外光谱预处理时,各主因子数所对应的特征值最大,变量与矩阵X有明显的线性关系,可用于酵母水解物的产地分类,光谱预处理后的谱图如图2所示。
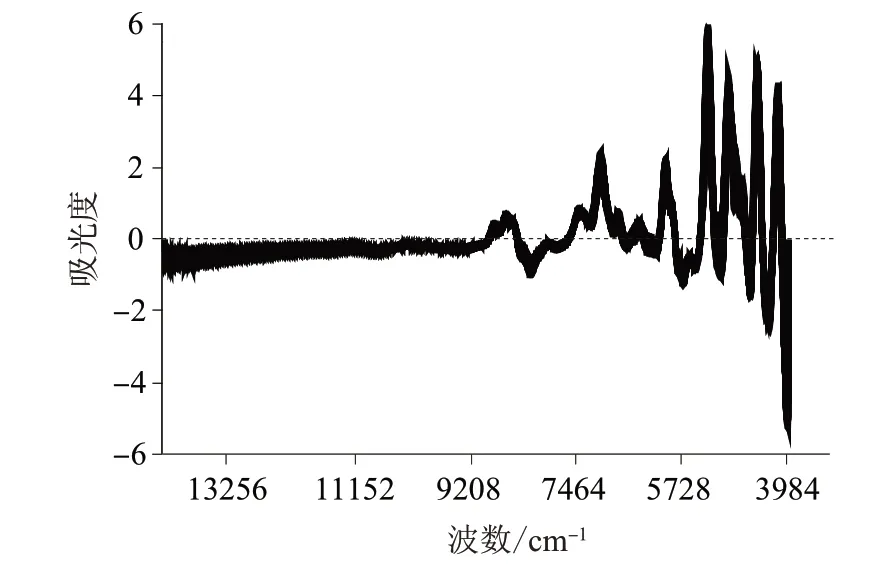
图2 酵母水解物(训练集)预处理后光谱

表2 不同预处理方法光谱主成分分析的各主因子数特征值
上述分析结果表明,6 个主因子数的累计方差贡献率为67.80%、22.53%、5.09%、2.63%、1.28%、0.68%,其中前5 个主因子数的累积方差贡献率为99.32%,确定主因子数为5。
3家工厂的酵母水解物样品不同成分得分分布分别如图3~图6 所示。由图3~图6 可知,利用前三个主因子数基本可以区分不同工厂、不同工艺的5种酵母水解物样品,但有少部分的样品有重叠,利用其它主成分的投影时,重叠情况会更严重。
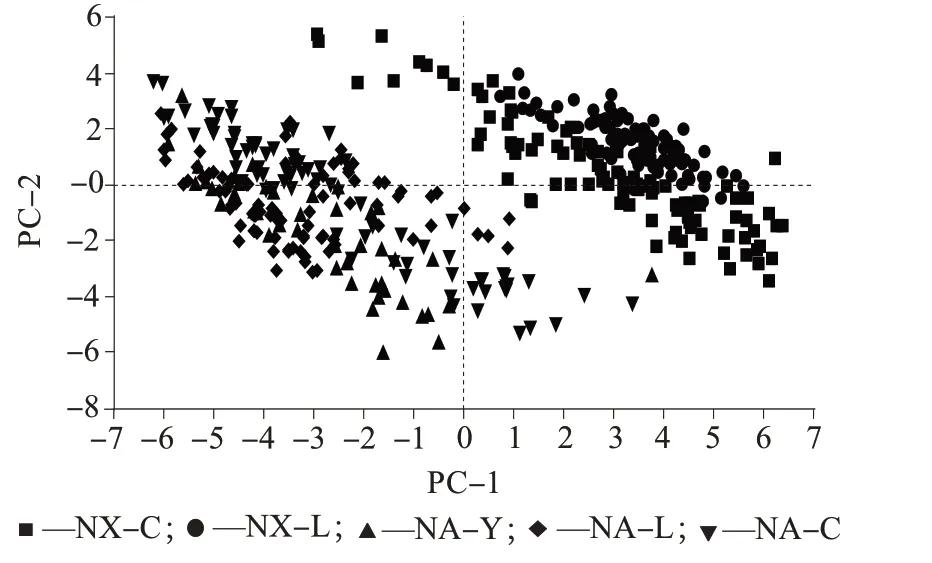
图3 酵母水解物样品主成分1(PC-1)与主成分2(PC-2)得分分布
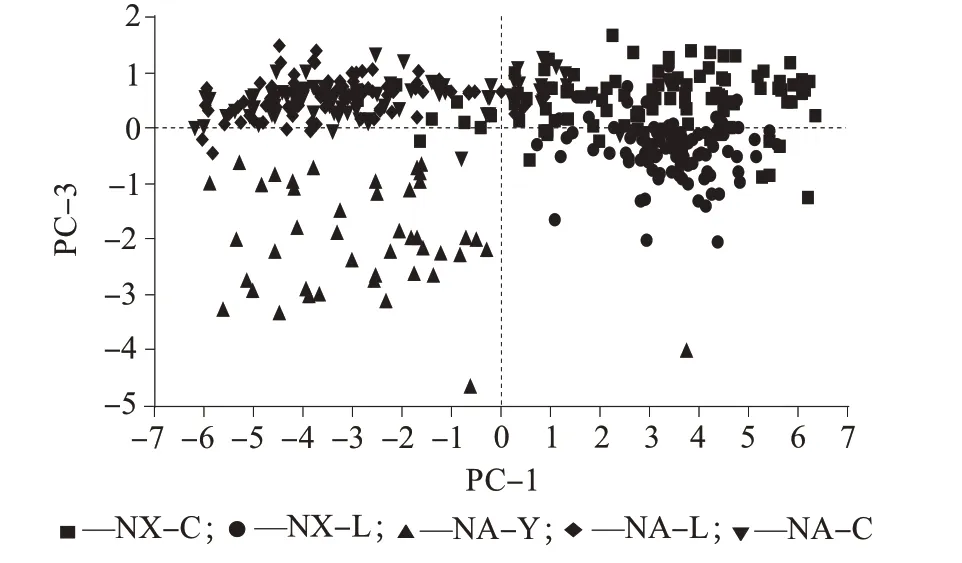
图4 酵母水解物样品主成分1(PC-1)与主成分3(PC-3)得分分布
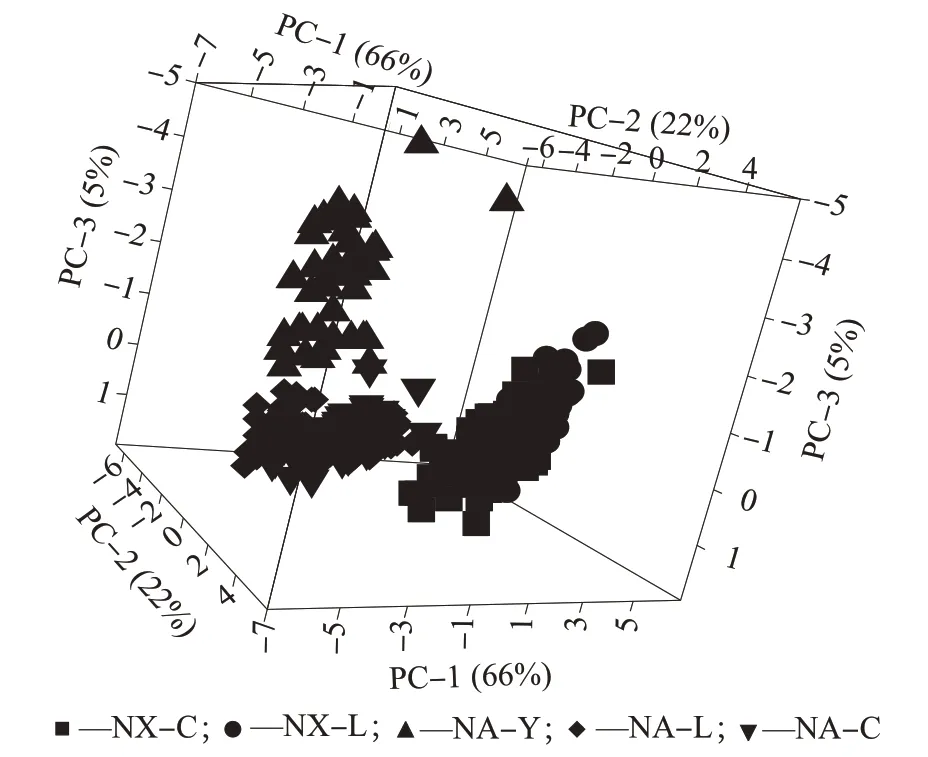
图6 酵母水解物样品主成分1(PC-1)、主成分2(PC-2)及主成分3(PC-3)得分分布3D图
2.2 线性判别分析(LDA)
主成分分析法属于无监督的模式识别方法,它可以通过光谱的特异性区分各类物质。线性判别分析(LDA)属于有监督的模式识别方法[17‒18],它首先需要对各光谱进行定义,区分出光谱所对应的样品种类,让计算机向这些被预先区分出的样本“学习”。LDA算法的目的是使降维后的数据类间方差最大,类内方差最小,LDA就是求解SB/SW(SW为类内协方差矩阵,SB为类间协方差矩阵)的特征值与特征向量,该算法能够把彼此关联的多变量数据,简化为少数几个互相独立的新变量数据,而且简化之后的数据不会出现信息量丢失,依旧能保持原来数据的绝大部分信息。根据上述主成分分析的结论,该数据的主因子数为5,因此,使用LDA法对前5个主因子数进行分析、建模,使用马氏距离[19‒20]来判断异常值。
LDA 算法样品分类如图7 所示。由图7 可知,LDA 算法的训练集所有样品的识别准确率达到94.81%,训练集混淆矩阵见表3。
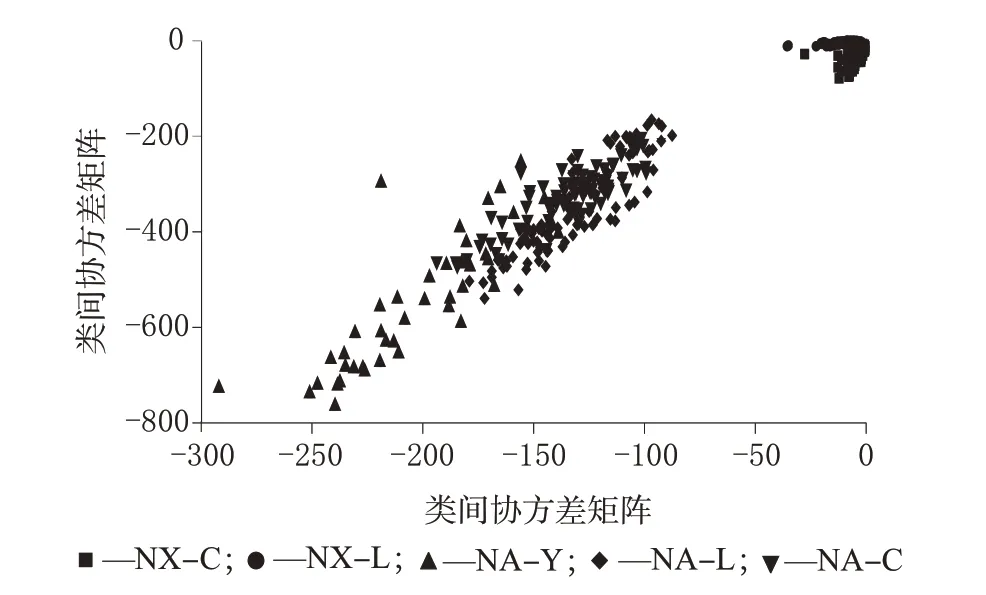
图7 LDA算法样品分类图
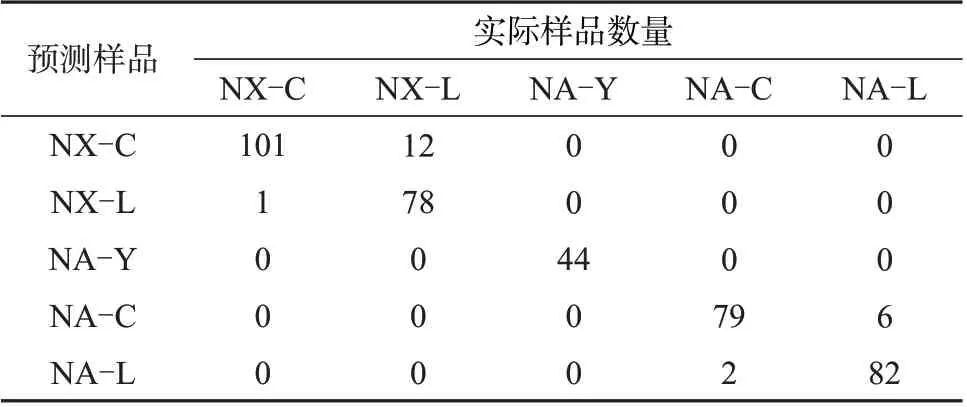
表3 训练集混淆矩阵
训练集中NX-C 系列样品识别率为99.02%,NX-L 系列样品识别率为86.67%,NA-Y 系列样品识别率为100%,NA-C 系列样品识别率为97.53%,NA-L系列样品识别率为93.18%。将验证集代入建好的PCA-LDA模型中,其混淆矩阵见表4。
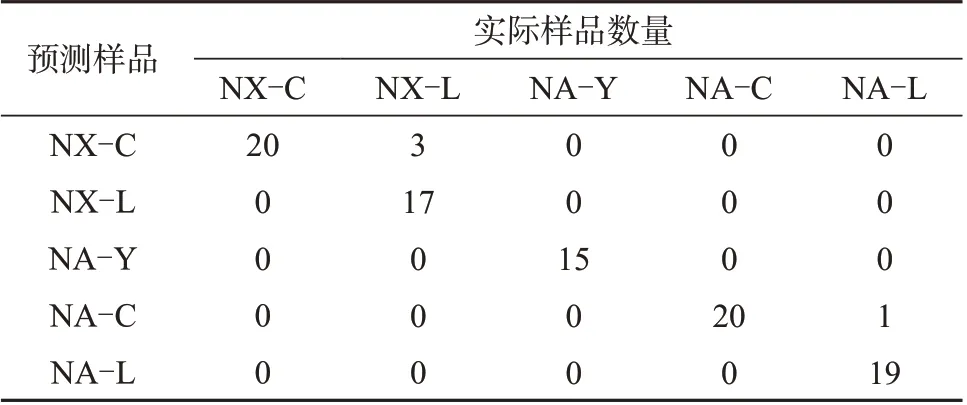
表4 验证集混淆矩阵
验证集中NX-C系列样品识别率为100%,NXL系列样品识别率为85%,NA-Y系列样品识别率为100%,NA-C 系列样品识别率为100%,NA-L 系列样品识别率为95%。
找出训练集样品中的误判样品,列出各样品的马氏距离,如图8所示。
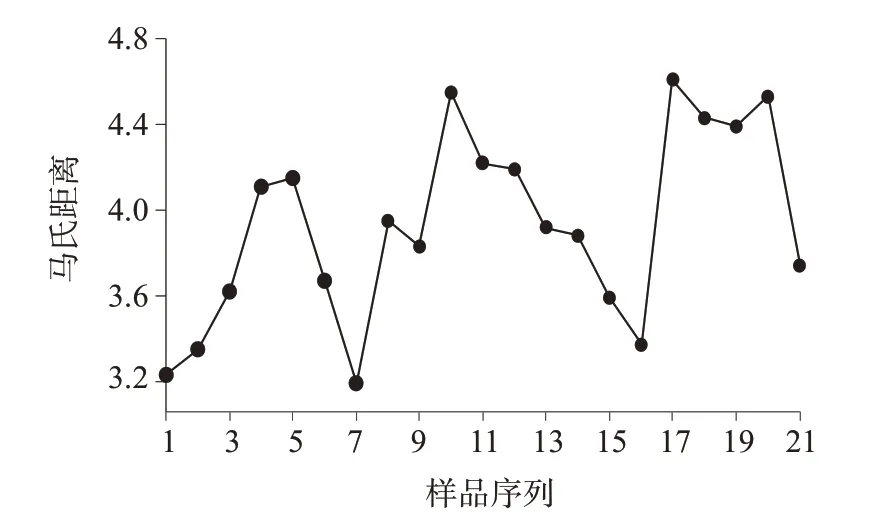
图8 训练集误判样品的马氏距离
误判样品的马氏距离基本位于3~5之间,将马氏距离报警值设为5,即可有效区分伪劣样品。对10个市场上流通的伪劣样品进行近红外光谱扫描,并用已建好的模型预测,拒绝率达到100%,伪劣样品的马氏距离如图9所示。
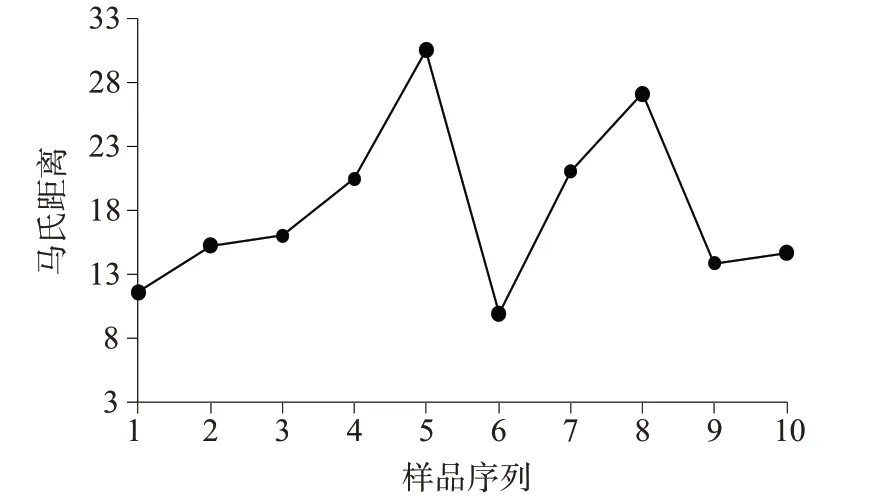
图9 伪劣样品的马氏距离
使用PCA-LDA 模型预测伪劣样品时,各样品的马氏距离均远大于5,该模型可有效用于酵母水解物的真假判别分析。
3 结语
使用平滑滤波法结合一阶求导法以及标准正态变量转化法对酵母水解物原始光谱进行预处理,去除光谱所产生的噪声和散射的干扰,对预处理后的光谱进行主成分分析确定主因子数,再结合线性判别分析,对三个产地、两种不同工艺的酵母水解物进行产地溯源分析,主成分分析法基本可以区分酵母水解物的产地,但有部分重叠,而PCA-LDA联用法可更有效区分酵母水解物产地,所有样品的识别率都在85%以上。根据误判样品设置马氏距离阈值,伪劣样品的识别率达到100%。因此基于PCALDA 法结合近红外光谱用于酵母水解物产地溯源及真假判别分析具有一定的可行性与实用价值。
猜你喜欢
数学物理学报(2021年5期)2021-11-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
中国调味品(2017年2期)2017-03-20
创新作文(小学版)(2016年16期)2016-11-11
现代检验医学杂志(2016年5期)2016-08-20
中国交通信息化(2016年2期)2016-06-06
中国科技信息(2015年2期)2015-11-16
