
基于深度学习的视听多模态情感识别研究*
2023-07-11 07:30李倩倩王卫星陈治灸
计算机与数字工程 2023年3期
李倩倩 王卫星 杨 勤 陈治灸 秦 晴
(贵州大学机械工程学院 贵阳 550025)
1 引言
随着移动设备的发展,图像和视频数据近年来呈爆炸式增长,这种现象使视觉媒体内容的计算理解成为一个热门话题。在传统的研究中,研究者往往侧重于对象检测和场景识别等方向的研究。近年来,越来越多的研究者开始关注视频中情感的识别,这是因为情感能够引起观众强烈的共鸣,在观看过程中起着至关重要的作用[1]。虽然近几年视频的情感识别研究取得了一些成果,但由于情感的复杂性和多样性,以及视频数据的异构性,国内外在视频情感识别方面的研究成果还是相对较少且识别率不高。传统的情绪识别方法是基于某一时刻的静态图像手工设计的特征进行识别[2~4],缺点较为明显,仅使用某一时刻的静态图像进行情感识别缺乏动态时域信息且准确率低。随着大数据集的可用性,深度学习已经成为机器学习的一种通用方法,在许多计算机视觉和自然语言处理任务中产生了最先进的结果[5]。早期深度学习技术在情感识别领域的研究主要集中在人脸表情识别方向[6~10]。近年来,一些研究开始将深度学习应用于视听情感识别。Zhang S 等[11]提出了基于多模态深度卷积神经网络(DCNN)方法,在深度模型中融合语音和人脸数据进行视听情感识别。D.S.Ortega 等[12]提出了一种基于迁移学习和多模态融合的视频情感识别方法。通过预训练的CNN 从视频帧中提取面部特征,并将这些特征与从受试者的声音中提取的特征相融合识别视频情感。Zhang S[13]采用混合深度模型来进行情感识别任务,该模型首先利用CNN和3D-CNN 分别学习音频和视觉特征,然后将视听片段特征融合到深度信念网络(DBNs)中进行视听情感识别。Ma Y[14]提出了一种基于深度加权融合的多模态情感识别模型。用2DCNN 和3DCNN 分别提取语音和面部表情图像的情感特征,然后利用DBN 对上述两个特征提取器学习到的情感特征进行融合,最后利用支持向量机进行情感分类。Zhang Y[15]等引入因子分解双线性池(FBP)来深度融合音频和视频的特征。通过嵌入的注意机制从不同的模式中选择特征,得到音频和视频的情感相关特征。然后提取的特征融合到一个FBP块中,预测最终的情感。
尽管通过深度学习挖掘视听情感信息已经取得了重大进展,但是现有的方法在视频情感建模中表达的时间关系仍然不够有效,并且大多视听情感识别研究都是融合人脸和语音数据,忽略了姿态的作用。因此本文采用多模型融合的混合神经网络来预测视频情感,框架如图1 所示。该模型可以概括为预处理、特征提取、特征融合和分类器四个部分。将视频进行分离音频、提取视频帧等预处理后,使用VGG-LSTM 分别对预处理后的人脸序列图像和姿态序列图像的视觉特征与时序进行提取,使用opensmile 提取音频特征,然后将提取的人脸、姿态和语音特征拼接并输入DNN,由DNN 网络进行多特征的拼接融合以及情感分类。利用GEMEP三模态情感数据集和Video Blooper 数据集测试该模型识别的准确率,以验证其在情感识别任务中的性能。
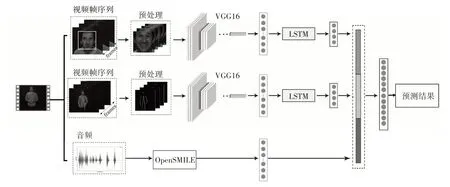
图1 VGG-LSTM多模态深度学习模型
2 方法描述
2.1 预处理
在提取特征之前,通常需要对视频进行一些预处理。常见的视频预处理任务包括分离音频、提取帧、识别人脸和姿态、裁剪人脸和姿态图像、删除背景等。
2.1.1 表情预处理
使用OpenCV 工具将视频样本转变为视频帧序列,检测人脸并将图像进行灰度化处理,最后使用Dlib 工具进行面部图像尺寸归一化到224×224大小。处理过程及结果如图2所示。
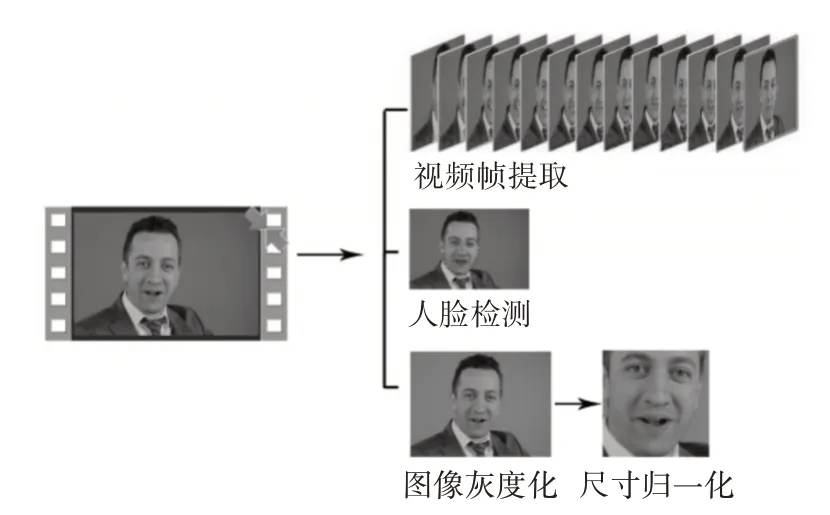
图2 人脸预处理处理
2.1.2 姿势预处理
由于数据集的限制,本文姿态特征部分只使用两个数据集都能可见的鼻子,耳朵,眼睛,脖子,肩膀和手臂关节。使用OpenPose 识别并输出人体上半身骨骼点,然后以颈部关节为中心在过滤后的关节中绘制一个骨架,并将此骨架插入尺寸为224×224的黑色背景框架中。处理过程及结果如图3所示。
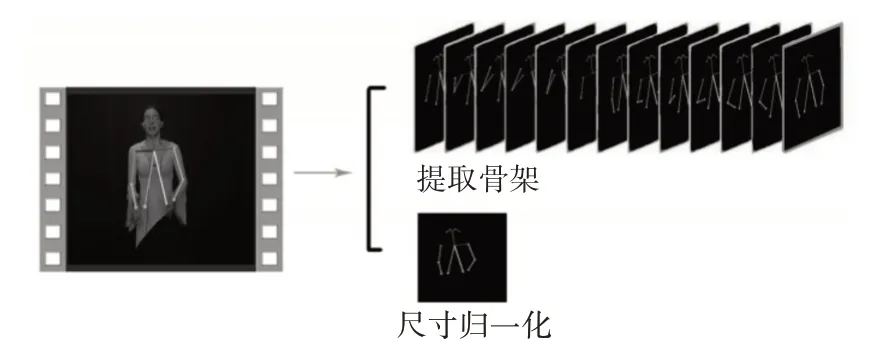
图3 姿态图像预处理
2.1.3 语音预处理
要识别视频中语音的情感,首先将视频中的音频提取出来进行预处理,对音频信号的预处理包含以下步骤:预加重、分帧、加窗等。然后利用开源工具opensmile 从音频中提取音频特征,如响度、音高、基音频率、基音范围、共振峰、梅尔频率倒谱系数、语音强度和语音速率等特征。
2.2 VGG-LSTM特征提取模型
由于神经网络对不同类型数据的良好适用性,因此选择VGG 网络来实现图像视觉特征的提取。为了更有效地提取人脸和姿态的视觉特征,设置了两种VGG 网络模型。针对人脸的特征提取,使用了VGGface 模型,此模型是在VGG16 的基础上通过人脸数据集LFW(Labeled Faces In the Wild)训练得到的,适用于人脸识别[16]。针对姿态特征提取使用了VGG16 网络。VGG 模型只用于提取图像的视觉特征,因此去掉了softmax 层。将经过VGG 网络提取的视频图像视觉特征按时间顺序输入到LSTM中以提取图像序列的时序特征。
LSTM 在处理时序相关的输入时,有着很大的优势[17]。LSTM 采用双向循环卷积网络的架构,对特征图在时间轴前后的依赖关系进行建模。LSTM中引入三个门:输入门it,输出门ot,遗忘门ft。对输入的信息做保留和筛选,具体式如下所示:
其中,xt、ht-1分别是指t 时刻的输入和输出,Ct-1是上一时间步的神经元状态,C是输入的中间状态,Ct表示利用Ct-1与C更新的得到的当前神经元状态信息。Wf、Wc、Wi、Wo、Uf、Uc、Ui、Uo分别指不同控制门的权重矩阵,σ指代sigmoid激活函数;tanh指代双曲正切激活函数。
2.3 特征融合
深度神经网络(Deep Neural Network,DNN)数据融合领域已经有了较为广泛的应用[18]。本文使用DNN 网络进行多特征的拼接融合以及情感分类,图4 给出了特征融合的网络结构。将提取的人脸、姿态和语音特征进行拼接处理,输入到DNN 网络中进行预测。DNN 网络有3层,包含两个隐藏层和一个输出层。分别含有1024、128、5 个神经元。最后一层由softmax激活,其他层由Relu激活。
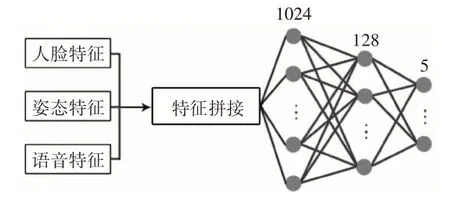
图4 DNN特征融合网络结构
3 实验及分析
3.1 实验数据集
1)GEMEP三模态情感数据集
该数据集是Automatic Face&Gesture Recognition and Workshops 在2011 年 的IEEE International Conference上提供的一个数据集[19]。整个集中包含有145 段长度为1s~2s 的视频,每段视频中都包含有表情、肢体动作、语音三个模态的信息。该数据集包含17种情感。手动将这17种情感类别归类成了5种:高兴、悲伤、害怕、厌恶、生气。
2)Video Blooper 数据集
该数据集是通过使用诸如“bloopers”、“green screen”等关键字从YouTube 视频中选择包含视频bloopers 的视频构建的[20]。数据集分为训练、测试和验证集。
由于GEMEP三模态情感数据集视频片段多在1s~2s,而Video Blooper 数据集中视频的长度在1s~4s,因此将超过2s 的视频剪辑为两段,合并两个数据集。最终得到的数据集有560 例,其中高兴132例,悲伤111 例,害怕95 例,生气117 例,厌恶105例。
3.2 实验环境配置
本文模型在NVIDIA GTX 1080 ti 平台上进行训练及测试。在我们的实验中,70%的样本用作训练集,15%的样本用作验证集,其余15%的样本则用作测试集。在训练过程中,模型的训练采用Adam优化器进行优化,MSE设置为loss函数。偏置初始化为零,学习率设置为0.001,Dropout设置为0.5。
3.3 评价指标
以准确率(Accuracy Rate,AR)作为深度学习网络的视听多模态情感识别模型的评价指标,表达式如下:
其中,TP 为被模型正确预测为正例的样本数量。TN 为被模型正确预测为负例的样本数量,FP 为被模型错误预测为正例的样本数量,FN 为被模型错误预测为负例的样本数量。
3.4 实验结果及分析
为了验证本文模型的有效性,将本文模型与前人的研究以及几种多模态融合模型进行对比,结果见表1。从实验结果可以看出,只融合人脸图像特征和语音特征进行视听情感识别时,本文方法与文献[21]、[15]、[23]相比,准确率有了一定的提升。与传统学习模型SVM 相比,基于深度学习模型准确率更高。与LSTM-DNN 模型和CNN-DNN 模型相比,本文模型准确率最高,说明经过VGG-LSTM提取人脸图像的视觉特征和时序特征后融合语音特征进行视听情感识别能获得更高的识别准确率。最终,融合人脸图像特征、姿态特征和语音特征后,SVM 模型、CNN-DNN 模型、LSTM-DNN 模型还有本文模型,准确率都分别提高了5.1%、4.7%、5.2%和6.1%,说明姿态在视听情感识别中是有作用的。综上所述,可以说明本文模型能够有效地进行视听情感识别分类,同时也说明了跨模态、跨时间的信息整合是提高视听情感识别性能的一种有效方法。
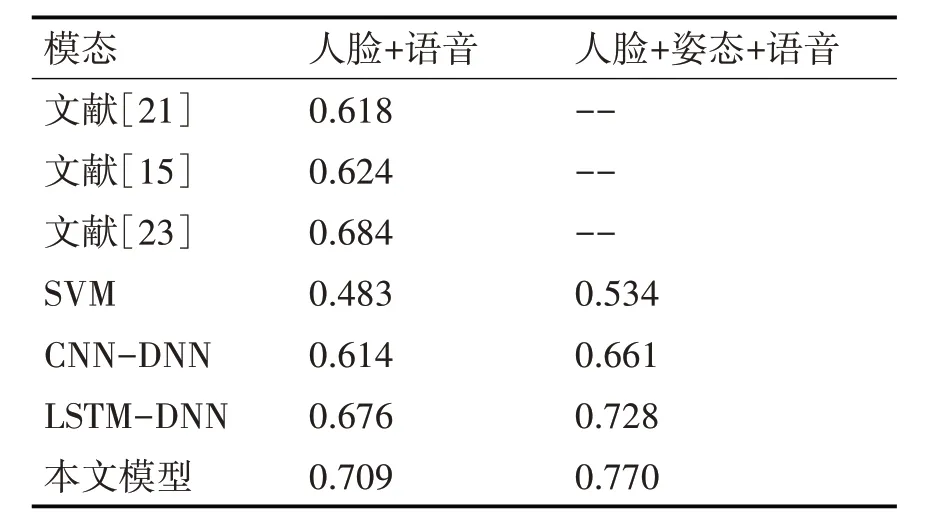
表1 不同模型的分类精度
图5 显示了本文模型的混淆矩阵。该分类器的准确率为77.10%,高兴和悲伤在五种情绪中的识别准确率最高,分别为87%和81%。而害怕的识别准确率较低,只达到65%。这可能是由于数据集中“害怕”样本数量较少,导致模型无法充分学习害怕的特征进行情绪分类。但召回率基本都在60%以上。可以说明本文模型在视听情感识别方面的有效性。
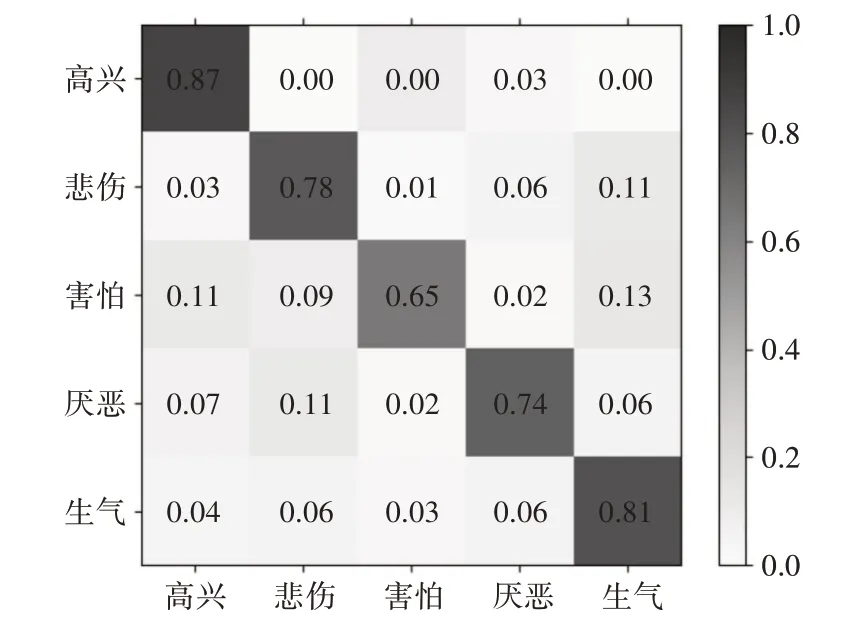
图5 多模态深度学习模型混淆矩阵
4 结语
本文从人脸表情、姿态和语音三个模态分析和识别了视频的情感,强调了动态情感识别的重要性。与目前大部分视听情感识别研究不同,本文还考虑了姿态的作用。未来的工作将考虑融合文字、生理信号等更多的模态来提高视频情感识别模型的性能,以及调查视听信息之间的相互关系。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
动漫星空(2018年9期)2018-10-26
制导与引信(2017年3期)2017-11-02
工业设计(2016年11期)2016-04-16
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
环境科技(2015年6期)2015-11-08
电网与清洁能源(2015年2期)2015-02-28
上海电机学院学报(2015年4期)2015-02-28
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
