
基于混合神经网络的非法集资风险预测模型*
2023-07-11 07:30陈钢
计算机与数字工程 2023年3期
陈 钢
(长三角信息智能创新研究院 芜湖 241000)
1 引言
近年来,以互联网金融为代表的新型金融业态蓬勃发展,提高了资金配置效率。由于互联网具有不分地域、快速传播、涉众面广等特性,通过线上平台进行的非法集资活动影响面更广危害更大,表现为参与人数众多,涉及金额巨大,涉及地域广等方面。2020 年全国共查处非法集资案件6800 余起,涉案金额1100 余亿元,不但涉及财富管理、私募基金、保险代理、房地产等传统领域,还涉及到养老服务、涉农互助、线上教育、区块链及虚拟货币等多种新形态[1]。
对于非法集资企业的识别,主要基于从业人员根据工作经验从该企业的财务报表中判断出财务异常,从而判断该企业是否有非法集资的嫌疑。在对企业是否在进行非法集资的判断过程中,往往依赖历史经验对大量的财务报表进行数字逻辑分析以及统计分析,识别准确率和效率均较低。在互联网背景下,非法集资案件通常具有很强的隐蔽性和突发性,传统监管手段难以及时发现[2]。为解决上述难题,本文提出了一种基于混合神经网络的非法集资预测模型。首先,将文本信息序列(如业务范围、产品描述等)输入到预训练模型中,并将输出的特征向量作为输入到下一层网络的语义表示向量输入;然后,构建基于GRU 的候选集生成网络用以增强非法集资的预测能力。与此同时,提高引入跳层连接机制来解决深度网络训练中信息丢失以及网络退化问题;最后,通过引入结合双向门限循环神经网络(BiGRU)和注意力(Attention)机制的非法集资风险特征知识嵌入,有效提升预测模型的理解层次,提升企业非法集资预测的准确性。
2 相关工作
学术界对非法集资的研究大多集中在法律和机制层面,使用大数据和人工智能技术预测非法集资的研究相对较少。基于龙信企业大数据,北京工商局构建了基于指标体系的企业非法集资预警模型[3]。单丹等指出可以利用大数据监测预警功能及时发现和管理企业早期的非法集资风险,利用大数据关联分析技术侦查集团企业的自融、自担保行为并快速锁定核心企业、核心人员[4]。石笑川以企业公开信息为基础建立了一套风险评价指标体系,通过层次分析法为指标赋值将这些特征量化,建立了一个定量与定性相结合的非法集资监测体系[5]。业内也有一些公司研发了金融监管系统。蚁盾系统[6]可以为金融监管人员呈现辖区内的金融机构企业以及企业的风险预警情况(企业相关的法院判决、工商变更、股权和投资关系变动、互联网负面舆情等),然而并不能呈现该企业是否有疑似非法集资的风险。灵鲲金融安全大数据平台[7]通过监测社交网络系统的聊天信息,来抓取疑似非法集资的线索;很多非法集资活动为了规避监管,都不在微信或者QQ 群中讨论,所以通过聊天信息抓取非法集资线索越来越困难。
为预测企业是否具有非法集资风险,通常的做法是在人工提取特征的基础上利用机器学习方法训练一个预测模型。这类方法可能导致花费大量精力去构思出来的特征可能与指定的任务不相关。更进一步,可以使用神经网络模型,如卷积神经网络(CNN)[8]、循环神经网络(RNN)[9]、基于长短期记忆的循环神经网络(LSTM)[10],实现自动特征提取和风险预测。一般而言,类似word2vec等模型将预处理后相关文本实行向量化表示。但上下文之间的联系无法被此类模型捕捉到,此时有歧意的特征词便可能错误表征[11],预训练语言模型能够有效处理此类问题。Liu 等[12]利用对BERT 超参数和强化训练集大小的研究内容,提出不断增强BERT训练方案,通过采用动态遮掩策略获得的RoBERTa模型较以往此类型的post-BERT方法相比,它能够获得同等或更好的质量和性能。而针对中文相关任务上,Cui 等[13]对RoBERTa 模型实行改进,采取使用Whole Word Masking(WWM)的训练策略,在保留强化训练的其他作战策略的基础的情况下,改进了RoBERTa 模型,进而提高了实验效果。葛霓琳等[14]对评论文本实行词向量模型进行表示,并选用PCA算法对训练样本进行降维,选取了两种不同的分类方法朴素贝叶斯和支持向量机在京东等电商平台的用户评论实现文本情感分析。Wang等[15]采用双向GRU 模型对结构化的知识库进行编码,以指针网络和两个注意力机制生成关于结构化知识库的自然语言描述。
3 预测模型
本文提出的预测企业非法集资的混合神经网络模型主要由两部分组成:基于预训练语言模型的风险等级预测网络以及基于GRU 和注意力机制的风险特征知识嵌入网络,模型的具体结构如图1 所示。在企业非法集资预测任务中,需要处理大量企业相关的文本信息,本文使用RoBERTa 预训练语言模型提取文本语义信息。为了更好地适应中文文本,本文将预处理后的企业文本信息输入Ro-BERTa-wwm-ext。处理后得到的语义表征向量和经过编码的其他类型特征向量被输入到风险等级预测网络,产生风险候选等级以及风险候选特征向量。非法集资风险特征知识库作为外部知识在使用BiGRU 和attention 机制后与风险特征候选向量进行拼接,得到融合特征向量并输入分类器,最终完成企业非法集资预测。

图1 基于混合神经网络的预测模型
3.1 基于RoBERTa的风险等级预测网络
风险等级预测网络中对RoBERTa 得到的语义表征向量使用GRU 网络处理得到风险等级结果(高风险、中高风险、中低风险和低风险)以及对应的隐藏状态向量,共同参与非法集资的预测。风险等级预测模型结构如图2 所示。经过RoBERTa 编码后的语义向量结果xt构成集合X={xt|t=1,2,…,n},把X 作为模块的输入部分。通过输入向量xt与上一步隐藏状态ht-1进行线性组合,再经过sigmoid激活函数非线性化处理后得到更新门zt和重置门rt,计算公式如式(1)和(2)所示。

图2 风险等级预测网络
与传统的RNN 的计算方式类似,首先将重置门rt与隐藏状态ht-1的哈达玛积和输入向量xt进行线性组合,再通过tanh激活函数非线性化处理即可得到候选状态ht,如式(3)所示。共同计算更新门zt,隐藏状态ht-1和候选状态ht就可得到新的隐藏状态ht,如式(4)所示。
将不同时间节点隐藏状态ht构成集合H={ht|t=1,2,…,n,n+1,…,n+m},经由全连接层以及softmax 函数后得到风险等级预测向量C={ci|i=1,2,…,m}。 对向量C使用全连接层进行维度转换,输出结果的维度与RoBERTa 预训练语言模型相同。为了避免训练过程中网络可能存在的网络退化和信息丢失问题,本文在风险预测结构中添加跳层连接[16]和对GRU 隐藏状态的连接处理。主要过程是使用门控机制将网络的输入部分、GRU 隐藏状态与输出结果进行相加,即可得到最终网络输出结果Vout,如式(5)所示。
其中f 是风险预测网络,h 是GRU 隐藏状态和维度变换结构。
3.2 非法集资风险知识库嵌入
除经营范围描述以外,企业一般还会包含大量其他存在关联性的标签(如成立年限、注册资本、违法记录等),而仅仅利用其中的某一类标签,可能存在对某些模糊描述的情况难以理解,导致模型的理解层次偏低。为此,除风险等级预测网络外,本文还构建了一个非法集资风险特征的知识库,有效提高模型的理解层次,提升预测准确性。虚假宣传、虚增注册资本、大量雇用与经营范围不相符的理财产品推销人员等,都是非法集资企业普遍存在的行为。综合这些行为,本文从基本风险(基本信息、行政许可、变更信息等)、遵从风险(投诉举报、案件信息、法院诉讼等)、经营风险(行政处罚、产品信息、招聘信息等)、族群风险(和非法集资企业的关联关系)和舆情风险(互联网负面信息)这五类风险构建企业非法集资风险特征知识库。将企业其他标签信息结合非法集资风险特征知识在预测模型中引入,外部知识用键值对(key-value)的形式进行结构化构建。输入到模型中的结构化知识库用如下的键值对列表表示:
其中si用来表示企业标签(例如:企业名称、企业类型、注册资本),vi表示标签详细内容(例如:安徽XXX 投资管理公司、国有企业、5000 万元人民币)。在非法集资风险特征知识库里,根据企业名称、企业类型等标签自动过滤掉不存在非法集资可能性的企业,例如国有企业、事业单位、商业银行、证券公司等。
在单向的神经网络结构中,因为状态是从前往后输出的形式,所以难以抓取整个风险特征知识库中的上下文信息。但由于前一时刻的状态和后一时刻的状态都可能与当前时刻的输出存在相关性,因此使用BiGRU 网络作为本文的信息提取网络,BiGRU 网络为输出层提供输入序列中每一个点的完整上下文信息。鉴于注意力机制可以选择性的筛选额外信息并聚焦到有效信息上,因此本文利用注意力机制来补充增强非法集资风险知识库后的预测效果。非法集资风险知识库嵌入模块分为Bi-GRU 部分和注意力机制部分,具体结构如图3 所示。

图3 风险特征知识嵌入
根据所描述的五类风险给定一个结构化的非法集资风险知识库L=[(s1,v1),(s2,v2),…,(sn,vn)],将L 经过嵌入后得到向量L=[I1,I2,…,In]。通过对向量L 中的元素Ii分别输入前向GRU 和反向GRU 即可得到前向隐藏状态和反向隐藏状态,BiGRU 的隐藏状态可由前向和反向隐藏状态进行拼接得到。对BiGRU 的隐藏状态hi应用注意力机制之后,再利用知识库上下文向量u来衡量知识的重要性,进而得到有利于增强预测的额外知识向量V。最后,将额外知识向量V 的维度用全连接网络转换为与主干网络相同维度的结果向量。具体算法流程如下所示。
算法风险特征知识库嵌入算法
输入:结构化风险知识库L=[(s1,v1),(s2,v2),…,(sn,vn)]。
1)随机初始化GRU和attention参数W,b,u
2)si,vi随机Embedding为si,vi
3)for i in{1,2,…,n}do
4)使用双向GRU 迭代更新得到隐藏状态hi,使用一层MLP网络计算得到ui
5)引入知识库上下文向量u并结合注意力机制衡量知识的重要性,通过计算得到额外知识向量V
6)end for
7)V oeut=FC(V)
3.3 损失函数
风险等级预测网络是对经过GRU 网络处理后的结果使用softmax 函数进行非法集资风险等级预测,如式(6)所示。本文使用多分类交叉熵损失函数作为风险等级预测损失函数,如式(7)所示。
Vconcat由非法集资风险知识特征和经营范围特征Vout进行拼接而得到,再将Vconcat输入分类器中,由此实现非法集资风险预测,如式(8)和式(9)所示。
本文使用二分类交叉熵损失函数作为非法集资预测的损失函数,如式(10)所示。
其中pi是企业的非法集资预测概率,yi是非法集资变量。
最终,采用联合损失函数进行模型训练,式(11)所示。
4 实验结果与分析
4.1 实验环境
本文构造的深度学习环境采用的是CUDA 11.0,对应的PyTorch 版本是1.7.1,基于的LINUX 系统软件是Ubuntu 18.04,使用64 GB 内存,中央处理器是Intel(R)Xeon(R)Silver 4210R CPU @ 2.40GHz,图形处理器为NVIDIA GeForce RTX 3090。
4.2 数据集
为证明模型的预测性能,本文采集了27000 家企业数据来创建实验数据集。数据集中包含了企业不同维度的各种信息,如司法和知识产权等照面信息、年报和纳税等经营信息、变更和处罚等信用信息、网评和投诉等舆情信息。本文根据训练集∶验证集∶测试集=6∶1∶1 的大致比例,随机划分20000、3500、3500 条数据分别用于训练、验证和测试。
4.3 实验设置
本文获取语义表征向量的方式是利用结合预训练和全词掩码优势的RoBERTa-wwm-ext 模型。在训练之前的参数选取中,采用的是768 维的语言嵌入(Embedding)模型和建立12 个源的多源注意力机制(Multi-head attention)。神经网络中为768维的隐藏层维度和12 层的隐藏层级数,构建的词表单元为21128个。风险预测网络中选择的是128个经过GRU 模型构建的神经网络隐藏层,知识嵌入网络中选择的是128 个BiGRU 模型构建的神经网络隐藏层。
模型训练过程中,采取的批量抓取规模(batch size)是32,批量抓取规模的单位是token,数据文本的抓取规模选定为200个token。模型搭配的Adam优化器选定的学习率为1e-5,每经过两轮训练之后学习率设定为原来的80%来优化模型的学习率,其中训练轮数选定为10。
4.4 基线模型对比
本文采用四种模型评价指标来验证模型性能,分别是准确率(acc)、精确率(precision)、召回率(recall)和F1 值。通过和多种基线模型的对照实验,来验证本文提出方法的优越性。基线模型选择如下:
1)机器学习方法
使用经典的特征工程流程来处理数据,其中对文本数据使用TF-IDF 和N-grams 方法做特征工程,处理完成之后用机器学习相关的算法,多项式朴素贝叶斯(MultinomialNB)、XGBoost[17]、LightGBM[18]和支持向量机(SVM)[19]做分类预测。
2)深度学习方法
CNN:使 用 卷 积 核 大 小 分 别 为2、3、4 的TextCNN[20]模型提取文本特征,其他特征进行特征编码与文本特征进行拼接,最终使用全连接网络与Sigmod函数进行分类预测。
RNN:使用TextRCNN[21]模型提取文本特征,其他特征进行特征编码与文本特征进行拼接,最终使用全连接网络与Sigmod函数进行分类预测。
Attention-based:使用多层次注意力机制的HAN[22]模型提取文本特征,其他特征进行特征编码与文本特征进行拼接,最终使用全连接网络与Sigmod函数进行分类预测。
本文提出的预测模型(RRP-EKB模型)和基线模型的对比结果如表1所示。可以看出,RRP-EKB模型取得了比其他基线模型更好的预测效果。通过实验结果表明,深度学习模型在评价指标上取得了比传统机器学习模型更好的分数,从算法原理上来看,机器学习方法对文本数据的处理局限在对转换后的词向量做简单平均,挖掘不到文本数据中更有效的语义特征,深度学习方法采用CNN 和RNN方法来提取特征,可以获得相对更有效的深层语义特征,所以在评价指标上取得了更高的得分。通过Attention-based 和CNN、RNN 的对比结果可以发现,使用Attention机制的模型拥有更高的预测准确率,因为Attention机制可以让模型更加关注那些对预测贡献较大的特征。
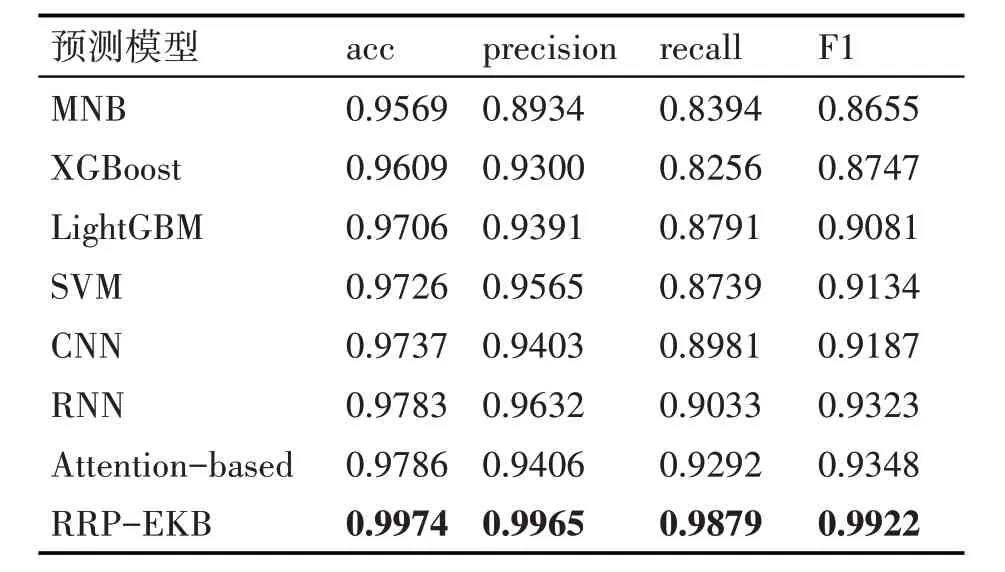
表1 基线模型对比实验结果
4.5 消融实验
1)风险等级预测网络的有效性
为了说明风险等级预测网络的有效性,本文比较了是否使用风险等级预测网络的实验结果。为方便起见,将未使用风险等级预测网络的结果命名为RoBERTa-EKB,对比结果如表2 所示。可以看出,在本文构建的数据集上RRP-EKB 模型的各项评价指标均优于RoBERTa-EKB 模型,这表明加入了风险等级预测网络的模型拥有更好的预测效果。

表2 风险等级预测网络消融实验结果
图4 显示的是风险等级预测网络的消融实验中,ACC 的值随着迭代次数的变化曲线图。超过200 次迭代后RRP-EKB 曲线就一直处于RoBERTa-EKB曲线的上方。这表明加入风险等级预测网络的模型ACC 会比没有加入风险等级预测网络的模型更好,从而证明了风险等级预测网络的有效性,能够提高模型在风险预测上的性能。
2)嵌入风险特征知识模块的有效性
本文通过实验比较嵌入风险特征知识和没有嵌入风险特征知识两种方法的评价指标,来验证嵌入风险特征知识对模型性能提升的作用。为了方便记录,将没有嵌入风险特征知识的方法记录为RRP,评价指标的得分显示在表3 中。从中能够看到,在本文构建的数据集上RRP-EKB 模型的各项评价指标均优于RRP 模型,这表明加入了风险特征知识嵌入的模型拥有更好的预测效果。

表3 风险特征知识嵌入消融实验结果
图5 显示的是嵌入风险特征知识的消融实验中,ACC 的值随着迭代次数的变化曲线图。超过200 次迭代之后RRP-EKB 曲线就一直处于RRP 曲线的上方。这表明嵌入风险特征知识模型的ACC会比没有嵌入风险特征知识模型更好,从而证明了嵌入风险特征知识的有效性,能够提高模型在风险预测上的性能。
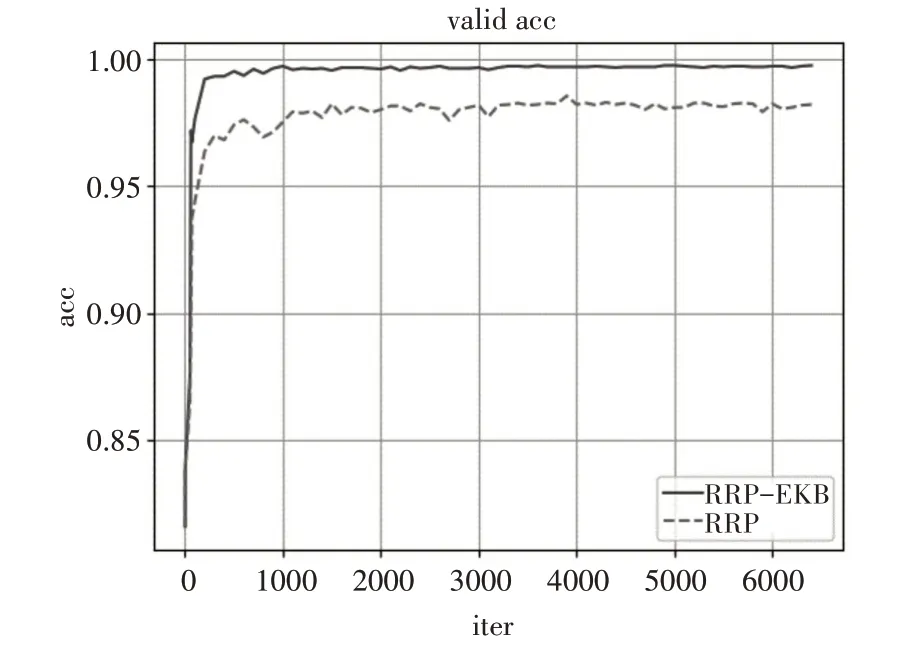
图5 风险特征知识嵌入网络消融实验acc对比
5 结语
为提升企业非法集资的监管效率,本文提出了一种基于混合神经网络的预测模型。该模型构建了基于RoBERTa 的风险等级预测网络并产生风险等级类别以及风险候选特征向量,利用GRU 模型生成用于预测的备用数据集来提升预测性能,同时结合跳层连接方法来弥补深度网络在训练中伴随的信息丢失和网络退化的缺陷。此外,本文模型利用BiGRU 和注意力机制嵌入风险特征知识到模型中,使预测模型的分析层次得到升级,提高了模型对企业非法集资的预测性能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
今日农业(2020年18期)2020-10-27
制造技术与机床(2019年6期)2019-06-25
知识经济·中国直销(2018年6期)2018-06-29
知识经济·中国直销(2017年6期)2017-06-13
知识经济·中国直销(2016年6期)2016-11-07
中国交通信息化(2016年9期)2016-06-06
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
