
基于VBA编程的全子集模型筛选算法
2023-07-11 11:11:40彭维湘
统计与决策 2023年11期
彭维湘
(广州工商学院 会计学院,广州 510507)
0 引言
建立多元回归模型时,若无既有理论模型,且相关影响因素较多,就需要对自变量进行筛选。
由于自变量之间、自变量与因变量之间的关系错综复杂,主观上难以准确判断哪些自变量更适合于模型,只能用统计方法或基于统计方法进行筛选。目前比较常用的模型筛选方法有:向前逐步回归、向后逐步回归、全子集回归。前两种方法计算快捷,比较常用;全子集筛选法计算量大,应用比较少。
从实际应用效果来看,在自变量较多的情况下,向前逐步回归的估计效果最差,向后逐步回归的效果好一些,但这些筛选方法得到的都是局部最优模型。而基于全子集回归的筛选方法是对全部子集模型进行估计和比较,不仅可以根据事先定义找出最优模型,还可以搜索到具有特殊意义的模型。
本文基于VBA for EXCEL编程技术,探讨如何通过全子集筛选法实现对回归模型的构建、估计、优化、应用。
1 全子集筛选原理
1.1 全子集模型
设多元回归模型有k个自变量x1,x2,…,xk,因变量为y,设置线性回归模型如下:
则含1 个自变量的子集为:{x1},{x2},…,{xk},共有k个子集。
含2个自变量的子集为:{x1,x2},{x1,x3},…,{xk-1,xk},共有k(k-1)/2 个子集。
含3个自变量的子集为:{x1,x2,x3},{x1,x2,x4},…,{xk-2,xk-1,xk},共有k(k-1)(k-2)/6 个子集。
…………
含k个自变量的子集只有一个:{x1,x2,…,xk}。
由k个自变量生成的全部子集模型个数是:k++…+。全子集筛选就是对所有子集模型进行估计、检验和筛选。
1.2 统计显著性模型
若模型中全部自变量的回归系数都通过了t 检验,则该模型就是统计显著性模型,即每个自变量t统计量的绝对值都要大于t统计量的临界值。如果任何一个自变量的t统计量不显著(常数项一般不进行t检验),那么该模型就要被舍弃。
用t1,t2,…,tk表示k个自变量的t 统计量,若最小的t统计量大于一定显著性水平下的临界值,该模型就是统计显著性模型,即min(|t1|,|t2|,…,|tk|)>t1-a/2(n-k-1),其中,n是样本容量。
在全部子集模型中,t 统计量显著的模型很多,但不同模型的回归效果不同,所以t统计量只能筛选出统计显著性模型,不能判断模型优劣。
1.3 最优显著性模型
判定回归模型最优的标准是什么?向前逐步回归、向后逐步回归侧重于回归系数的t检验,对模型优劣的判别标准定义不够明确。而全子集回归必须进行严格定义,否则无法进行筛选。
常用判别模型优劣的统计量有:R2、S、AIC、BIC,其中,R2越大或S、AIC、BIC 越小,模型就越好。特别是S,能直接反映因变量估计值与实际值之间误差的大小,S越小模型越优,是比较好的判断标准;AIC和BIC包含了自由度因素,更多侧重于避免出现维度灾害(自变量过多)和模型复杂度太高的问题。这些统计量的计算公式分别是:
通过大量计算可以发现,R2、S两个标准的判断差别不大,AIC、BIC 两个标准的差异也不大,但AIC、BIC 与R2、S相互间的判别结果差异较大。本文用S作为判断标准,借助AIC进行辅助判断。筛选原理是:从只有1个自变量的子集开始,对每个子集模型进行t检验,保留t统计量显著的模型,然后比较不同子集模型的S,S最小的模型即为最优显著性模型。
2 全子集模型筛选算法
2.1 一般全子集模型筛选法
一般全子集模型筛选法:在将所有子集模型全部估计、判断、比较完之后,找出全部显著性子集模型中S最小的那个子集模型。从包含1 个自变量的子集模型开始计算,直到计算完包含全部自变量的子集模型。理论上要进行k++…+1 次计算,但自变量很多的时候,可以提前终止计算。提前终止方法有三种:
方法1:人为规定模型中的自变量个数不超过某个值,达到则终止。筛选出来的虽然不是最优模型,但也能达到很好的拟合效果。
方法2:k个自变量形成的全部子集包括含1,…,k个自变量的子集,在自变量个数为m的子集模型中,只要至少存在一个统计显著性模型,就必然存在一个回归误差S(m)最小的模型。一般情况下,随着m增大,S(m)先由大变小,超过某个值后又开始变大。在S(m)由大变小然后又开始变大时停止计算,取S(m)最小的那个模型为最优模型,不计算其他子集模型。由于担心S(m)出现波浪形或纯递减变化,因此本文没有采用这种方法。
方法3:从只含1个自变量的子集模型开始筛选,当自变量个数超过某个值时,会出现所有子集模型都不能通过t 检验的情况,此时不再对更多自变量的子集模型进行筛选。本文采用的是方法3。详见图1。
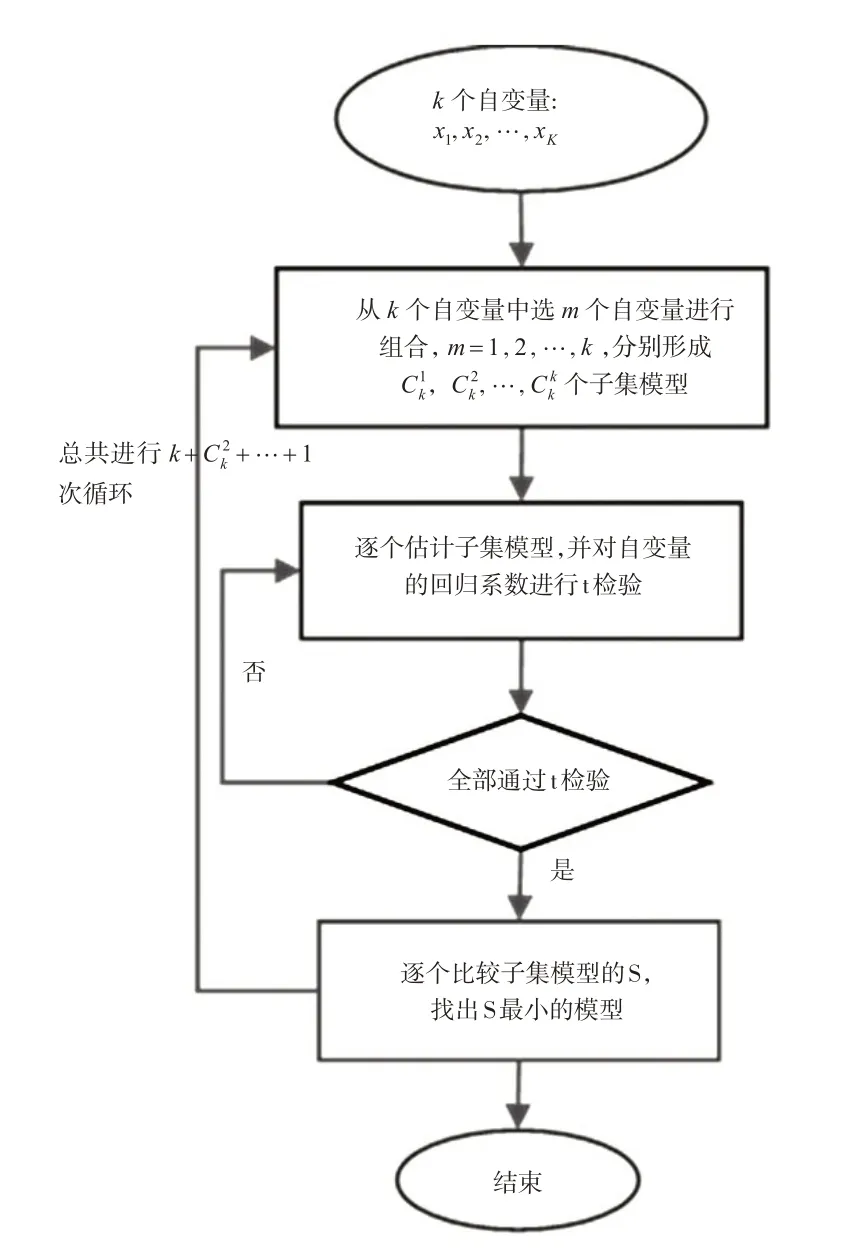
图1 一般全子集模型筛选流程图
2.2 多步全子集模型筛选法
进行全子集模型筛选时,在自变量个数不多的情况下,计算量不大。例如,当自变量个数为15 时,理论上要进行32767次回归和比较,实际上当子集模型中的自变量超过一定个数后,会因为无显著性模型而中止计算,计算次数通常不会达到最大值。但是,如果备选的自变量个数太多,则进行全子集模型筛选的计算量非常大,甚至大到无法计算。例如,30 个自变量的全子集个数是1073741823个。因此,本文设计了一种多步筛选法。
根据组合原理,从全部自变量(k个)中取1个、2个或取k个、k-1个自变量进行组合生成的子集模型个数最少,取k/2(或(k±1)/2)个自变量进行组合生成的子集模型个数最多。多步筛选法的原理是:不对全部子集模型进行计算和比较,只对包含1、2、k、k-1个自变量的子集模型进行显著性筛选,然后找出最优模型。分三步计算:
第一步:向前选择显著变量。
(1)筛选出含1个和2个自变量的初始最优模型,计算次数为+。筛选出的最优模型可能只有1 个自变量,也可能有2 个自变量。一般地,在自变量个数较多的情况下,初始筛选出来的2个自变量模型比1个自变量模型更优,计算时会自动识别,为简化叙述,后面假设第一次筛选的最优模型有2个自变量。
(2)从全部自变量中剔除这2 个自变量,再从不包含这2个自变量的其他自变量中取2个自变量进行组合,共有个子集;把每个子集中的2个自变量与已经筛选出来的2个自变量合并,共有4个自变量;然后对4个自变量的3个和4个自变量子集模型进行筛选。总共的计算次数是。
(3)假设已经筛选出m个自变量,重复前面的步骤:从k-m个自变量中取2 个自变量进行组合,形成个子集,每个子集的2个自变量与前面已经筛选出来的m个自变量合并,再在m+1、m+2 个自变量的子集中筛选最优模型,总共的计算次数是。如果筛选结果没有增加自变量,则停止计算;否则,按此方法继续筛选。
(4)经过多轮筛选后,假设筛选出了p个自变量,为了防止还有重要自变量被遗漏,再从被筛选掉的k-p个自变量中选择2 个自变量,形成个子集,并与原先筛选得到的p个自变量合并,得到p+2 个自变量,然后对自变量为p和p+1 个的子集进行筛选,总共的计算次数是,这次筛选可能会让新加入的2 个自变量替换原来p个变量中的1 个或2 个,得到S 更小的模型,筛选结果会得到进一步优化。
这种筛选自变量的方法看起来与向前回归方法类似,但原理完全不同:它的每一步计算都是已经筛选出来的自变量与未被筛选的自变量重新进行组合,形成新的子集模型并进行计算比较,如果发现更优的模型,则继续寻找,否则就终止。
计算中发现:有时候2个以上具有特殊关系的自变量一起进入模型可以使模型拟合效果更优,但计算量会大大增加。本文讨论的算法一般是每一轮筛选只添加2个或3个自变量(每一轮添加k个自变量进行筛选就是一般全子集模型筛选)。
第二步:向后删除不显著变量。
先用全部自变量回归,删除t统计量不显著且t统计量绝对值最小的自变量;再用剩余的自变量回归,用同样的方法删除不显著的自变量,直到模型中所有自变量的t统计量都显著。这种方法就是向后回归法,那些具有特殊关系的自变量会被一起保留下来。
第三步:合并显著变量并进行子集筛选。
把第一步和第二步筛选出来的显著变量合并在一起,假设第一步筛选出p1个自变量,第二步筛选出p2个自变量,合并在一起,删除相同的自变量后,自变量的个数是p3(p1+p2-重复个数)。
第三步:合并显著变量并进行子集筛选
把第一步和第二步筛选出来的显著变量合并在一起,假设第一步筛选出p1个自变量,第二步筛选出p2个自变量,合并在一起并删除重复的自变量后,自变量的个数是p3(p1+p2-重复个数),然后筛选p0,…,p3个自变量的子集,其中,p0=max(p1-2,p2-2,1)。p1-2,p2-2 的目的是看在增加了其他自变量后,自变量个数少于p1(或p2)是否存在更优模型。在多次试算中,p0=max(p1-2,p2-2,1)与p0=max(p1,p2,1)的计算结果无差别,前者计算量大些,但p0=max(p1-2,p2-2,1)可能会有更优(S 更小)的模型,所以VBA 计算程序中使用的是p0=max(p1-2,p2-2,1)。
例如:有30 个自变量,第一步筛选出来13 个,第二步筛选出来15 个,其中10 个相同,合并后的自变量个数是18个,则包含15、16、17、18个自变量的全部子集模型中至少有一个t统计量显著且S最小的模型。
多步筛选法的流程图如图2所示。
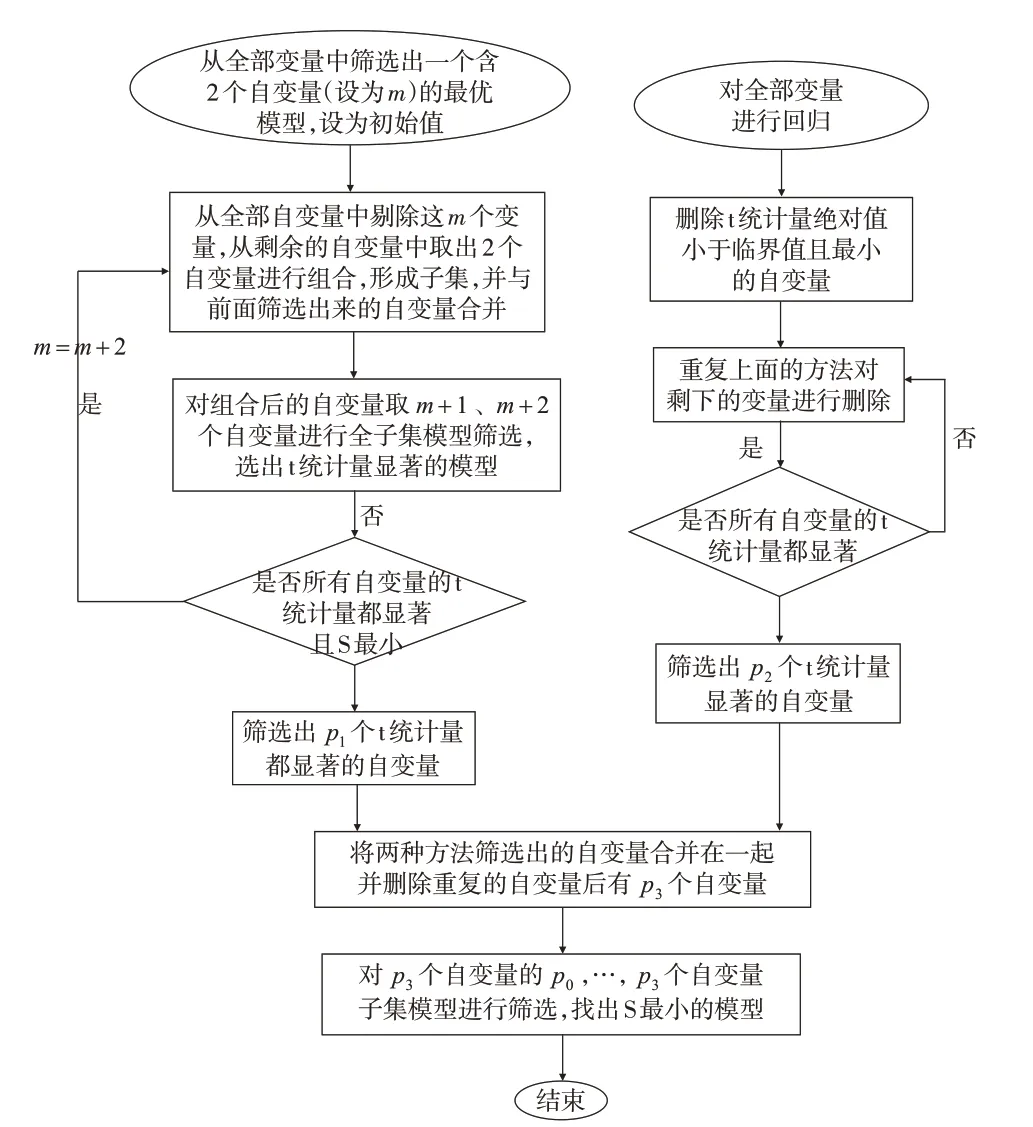
图2 多步全子集模型筛选流程图
2.3 VBA算法设计
(1)操作界面
图3所示的窗体是一个操作界面,通过窗体设置相关功能和进行操作。
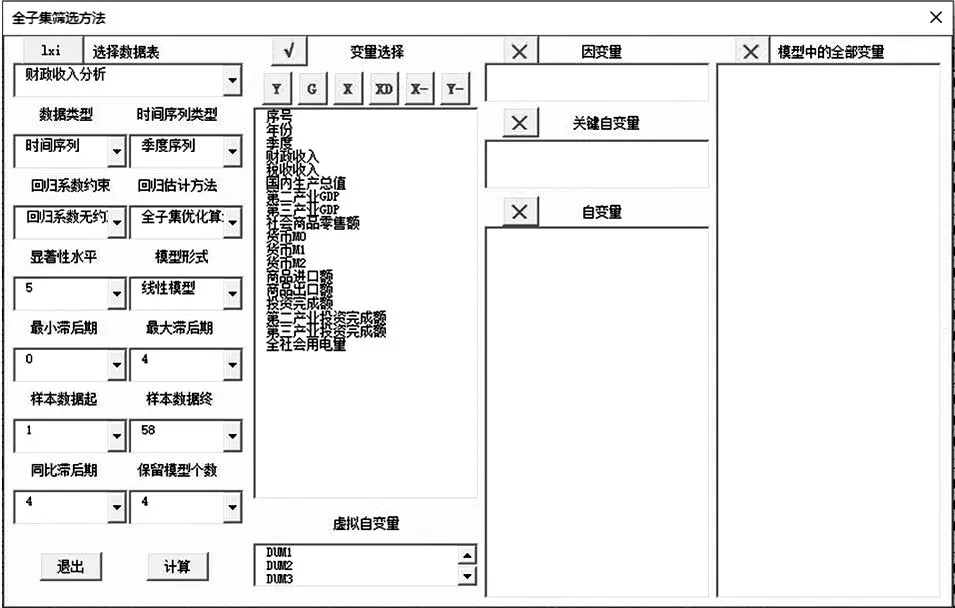
图3 全子集筛选方法操作界面
(2)参数设置
①数据表选择:将一个模型的数据存放在一个工作表中,不同模型的数据存放在不同工作表中,可以选择不同的工作表进行分析。
②数据类型包含时间序列数据和横截面数据,时间序列类型又分为年度、季度等。
③回归系数约束分为:回归系数无约束、全部回归系数大于0约束、全部回归系数小于0约束。
④回归估计方法分为:一般全子集模型筛选法、多步全子集模型筛选法、普通最小二乘法三种。
⑤模型形式分为:线性模型、对数模型、指数模型、倒数模型等十多种模型。
⑥显著性水平:1%~10%,也可以输入其他值,用于计算t统计量的临界值。
⑦滞后期:时间序列模型设置滞后期后可以派生出因变量和自变量的滞后变量。
⑧样本数据选择:可以设置样本数据起始点,截取中间一部分数据进行分析。
(3)VBA关键算法
①生成自变量子集函数:VBA 自定义函数,生成自变量子集的VBA 算法程序,输入自变量后生成自变量的全部子集。
②回归估计和检验:基于EXCEL中的LINEST函数计算回归系数、t统计量、R2、S、RSS、AIC、BIC统计量,并对回归系数进行t检验。
③模型筛选函数:VBA自定义函数,输入全部变量,输出最优模型,并保存全部统计显著性模型。
④预测和误差分析:筛选出最优模型后,在数据表最后一列插入以EXCEL 公式形式计算的回归值、误差值及其他重要统计信息,可以选择1~10个模型进行联合预测。
⑤过程保存:将所有t 检验显著的模型用文本文件的形式保存起来,可以对全部显著性子集模型进行统计分析,比较不同模型筛选方法的差异。
3 模型设置的几个问题
3.1 计量模型选择
选择线性回归模型的情况比较多,有时为了达到更好的拟合效果或实现特定的分析目的,需要选择其他形式的计量模型。本文研究的算法提供了多个可供选择的典型模型,包括:线性模型、双对数模型、自变量对数模型、因变量对数模型、双倒数模型、自变量倒数模型、因变量倒数模型、双指数模型、自变量指数模型、因变量指数模型、双差分模型、自变量差分模型、因变量差分模型、双速度模型、自变量速度模型、因变量速度模型等,以供在不同目的、不同情形下使用。
3.2 虚拟变量设置
回归模型引入虚拟变量,可以用加法原则(将虚拟变量视为普通变量加入模型)、乘法原则(将虚拟变量与所有普通变量相乘后加入模型)或混合原则(虚拟变量既作为普通变量加入模型,又与其他普通变量相乘后加入模型),构造新的回归模型。
加法原则影响模型截距,乘法原则影响斜率。进行模型筛选就是假设事先不能判定属于哪种情况,所以要用混合原则。一元回归模型加入一个虚拟变量时会变成三元回归模型。
如果时间序列模型中既有虚拟变量又有滞后变量,那么乘法原则只对当期自变量起作用,不影响自变量的滞后变量。例如:yt=a0+b1xt+b2xt-1+ut,采用混合原则引入虚拟变量D后变成yt=a0+a1D+b1xt+b2xt-1+b3xtD+ut。
3.3 滞后变量引入
时间序列模型中引入滞后变量主要是为了反映客观现象的滞后影响,加入滞后变量后可以改变模型形式和提高拟合效果。
以季度时间序列模型为例,设一个滞后变量(滞后期为4)派生出来的滞后变量模型有:
滞后变量模型一:
滞后变量模型二:
滞后变量模型三:
滞后变量模型四:
滞后变量模型三和模型四包含因变量的滞后变量,有自回归性质,但若因变量的变化趋势发生改变,则会增加预测误差;滞后变量模型一和模型三派生出的自变量很多,计算量很大,但模拟效果最好;用滞后若干期均值做滞后变量,派生出的自变量最少,计算量最小,在模型中可以反映时间序列的趋势性、季节波动性(滞后3 期平均就是为了保留时间序列的季节波动性),还可以在一定程度上减弱自变量异常值对后期预测结果的影响。
3.4 回归系数约束
在回归系数无约束条件下,全部子集模型中,S 最小的就是最优模型。如果要约束自变量的回归系数全部大于0(或全部小于0,或其他约束),就只能在约束条件下选择S 最小的模型。除了可以通过变换模型的数学形式达到设定目的外,用全子集模型搜索不失为最有效的方法。但约束模型系数后,拟合效果会降低。
3.5 关键自变量选择
有些自变量理论上是模型不可缺少的,为了保证它不被筛选掉,可以将它排斥在被筛选的子集之外(不放在任何一个子集中),然后再筛选最优模型。
根据本文设计的算法,只有当期自变量可以设置为关键自变量,滞后变量不能设置为关键自变量。关键自变量不能选择太多,一到两个即可,如果选择太多,关键变量之间、关键自变量与其他自变量之间存在的多重共线性问题会导致一些重要自变量不能被选入模型,从而降低模型的拟合效果。
4 结论
综合前文分析,本文得出如下结论:
(1)评价模型好坏的标准不是唯一的,从某种意义上讲,根本不存在理论上的最优模型,所以想找到一个最优模型是不可能的,即使用全子集筛选法找到了S最小的模型,其预测结果也未必是最好的。
(2)以S 最小为标准筛选模型只是方法之一,这个规则清晰且易于实现,是一个非常好的规则,但不能认为它是最好的规则,不同方法筛选出来的模型都有价值且不具有可比性。
(3)对于带滞后变量的模型,如果S相差不大,滞后变量和回归系数看似差异很大,但不同滞后期对因变量的影响平均之后的作用方向、影响程度差别其实并不大,不同模型之间没有本质上的区别。
(4)全子集筛选法可以筛选出很多有价值的模型,用于研究一些重要统计量的统计规律。例如,用多个优选出来的模型进行联合预测、边际效应分析、弹性系数分析等,可避免某个模型的偶然性。
(5)VBA 编程不仅用户界面友好,而且前期的资料准备和后期的计算分析、结果整理,以及与WORD、PPT、统计分析软件进行数据交换都极其方便。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
中国药房(2022年7期)2022-04-14 00:34:30
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
——与非适应性回归分析的比较
四川精神卫生(2019年2期)2019-06-18 02:45:00
统计与决策(2018年14期)2018-08-22 12:38:08
江苏农业科学(2017年10期)2017-07-21 17:09:52
文理导航(2017年20期)2017-07-10 23:21:03
华东师范大学学报(自然科学版)(2017年1期)2017-02-27 13:41:03
都市丽人(2015年4期)2015-03-20 13:33:22
