
基于循环神经网络的交易量预测问题的研究
2023-07-03 08:52温伍正宏
计算机仿真 2023年5期
温伍正宏,潘 甦,张 坤
(南京邮电大学,江苏 南京210009)
1 引言
深度学习在语音识别[1,2]、图像识别[3,4]以及自然语言处理[5,6]等领域不断取得突破性的进展,表现出巨大的潜力。随着 AI 技术在各个应用领域的落地及实践,金融科技也将迎来一个智能化的新时代,银行系统的交易平台拥有海量的数据,运用深度学习算法发现交易量的渐变趋势并进行预测,提前通知业务人员和系统运维人员可能的流量变化,并为领导者提供精准的决策支持,越来越受到关注。


图1 网银用户增长曲线
本文的主要研究内容和贡献如下:
1)研究历史交易量数据的周期性的变化趋势和特征,包括:分钟级别、小时级别、日级别、邻近时间截面、邻近时间区域、特殊日等;
2)通过特征工程对241天的历史数据进行处理,生成的特征向量维度为[347040, 20];
3)基于长短期记忆网络LSTM设计并实现了交易量预测模型LSTM-WP;
训练模型,超参数调优并进行预测结果对比分析,结果表明LSTM-WP模型在节假日的准确度比线性算法提高了约8%。
2 相关技术说明
2.1 循环神经网络
循环神经网络(RNN:Recurrent Neural Network)[8]是一类用于处理序列数据的神经网络。它通过每层之间节点(也称为RNN cell)的连接结构来记忆之前的信息,并利用这些信息来影响后面节点的输出。RNN可充分挖掘序列数据中的时序信息以及语义信息,它在处理时序数据时比全连接神经网络和卷积神经网络更具有深度表达能力,这使得RNN已广泛应用于语音识别、语言模型、机器翻译和时序分析等各个领域。
RNN的设计原理如图2所示,RNN网络在时间维度上展开,输入xt(t时刻的特征向量),并经过输入层到隐藏层连接的有权重矩阵U参数化后,结合上一时刻该节点的状态h(t-1)计算出该时刻的h(t),计算公式如式(1)所示,其中,隐藏到隐藏的循环连接由权重矩阵W参数化,函数f表示神经网络中的激活函数。

图2 RNN设计原理
h(t)=f(U×xt+W×h(t-1))
(1)
隐藏到输出的连接由权重矩阵V参数化,之后便得到了由x值得输入序列映射后的输出值o的对应序列,损失函数L衡量每个o与相应的训练目标y的距离,再利用反向传播算法和梯度下降算法训练模型,由于每个时刻的节点都有一个输出,所以通常情况下,RNN的总损失为所有时刻(或部分时刻)上的损失和。然而,如果时间序列过长,RNN并不能够很好的将这些上下文信息关联起来,产生“长期依赖”的问题,这是因为经过许多阶段传播后的梯度倾向于消失(大部分情况)或爆炸(很少,但对优化过程影响很大)[9]。
2.2 长短期记忆网络
长短期记忆网络(LSTM:Long Short Term Memory Network)是一种特殊的RNN,它由Hochreiter等人在1997年提出[10],主要解决了上面提到的RNN的“长期依赖”问题。它将原始的RNN cell替换成了LSTM cell,原始RNN cell仅适用单一tanh循环体,但LSTM cell使用三个“门(Gate)”结构来控制不同时刻的状态和输出[11],分别为“遗忘门”、“输入门”和“输出门”,对比如图3图4所示。这里的“门”结构可以实现有选择性地让信息通过,它使用了sigmoid激活函数的全连接神经网络和一个按位做乘法的操作来实现。

图3 RNN cell内部结构
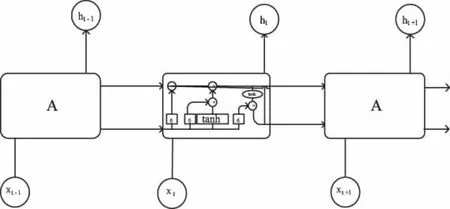
图4 LSTM cell内部结构
“遗忘门”的计算公式如式(2)所示,它使得LSTM cell可以决定让哪些信息通过,它的输入是ht-1和xt,输出是一个向量长度与Ct相同的、数值都在0和1之间的向量,表示让Ct-1的各部分信息通过的比重,其中,0表示不让任何信息通过,1表示让所有信息通过。
ft=σ(Wf·[ht-1,xt]+bf)
(2)
“输入门”使得LSTM可以决定当前t时刻的输入数据中哪些信息留下来,它的操作分为两步:①选取更新信息内容(计算公式如式(3)所示)与更新量(计算公式如式(4)所示);②更新cell状态,计算公式如式(5)所示。
(3)
it=σ(Wi·[ht-1,xt]+bi)
(4)

(5)
通过“输入门”的第二步操作,首先将不想保留的信息删除掉,再加入需要保留的新添加的信息。在得到最新的节点状态Ct后,“输出门”结合上一时刻节点的输出ht-1和当前时刻节点的输入xt来决定当前时刻节点的输出,具体计算公式如式(6)和式(7)所示。
ot=σ(Wo·[ht-1,xt]+bo)
(6)
ht=ot×tanh(Ct)
(7)
3 交易量预测
3.1 数据集与数据预处理
原始数据集共包含241个文本文件,每个文本文件记录了关于中银开放平台当天每分钟的用户交易量,即每个文本文件是由1440条记录构成,因此共有347040条记录。
每条记录格式为:
日期(date)时间(time)交易量(count)
在这241个文本文件中,有若干文件的记录是异常的,如交易量为0或交易量与其它相同时间段内的记录显著不同,因此首先通过删除替换的方法对离异样本点进行了处理。
3.2 特征工程
分析原始数据发现交易量有如下特征:
1)分钟级别和小时级别的周期性变化特征:通常情况下,每天的每分钟和每小时的交易量的变化趋势大致相同,如图5所示。

图5 分钟和小时级别的交易量变化趋势
2)日级别的周期性变化特征:通常情况下,周一到周五每一天的交易量的变化趋势大致相同,如图6中“—”线所示,周六和周日的交易量的变化趋势大致相同,如图6中“:”线所示,这里将周一到周五定义为工作日,周六和周日定义为休息日。
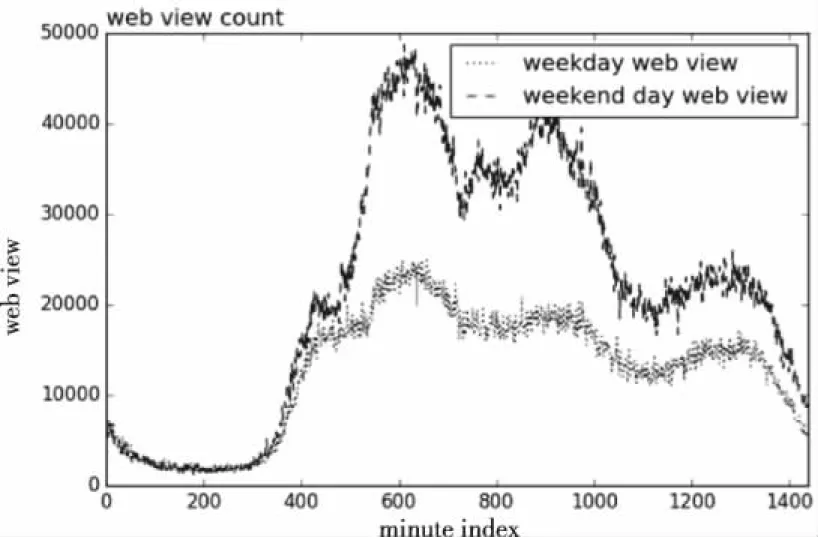
图6 日级别交易量变化趋势
3)邻近时间截面交易量的变化特征:通常情况下,如果当天是工作日,那么其交易量与上周5天工作日的交易量的均值以及和上周该天的交易量大致相同;如果当天是休息日,那么其交易量与上周2天休息日的交易量的均值以及和上周该天的交易量大致相同。
4)邻近时间区域交易量的变化特征:当前时刻的瞬时交易量与该时刻之前一段时间范围内的交易量变化存在关系。
5)特殊日的变化特征:特殊日包括节假日(比如:春节、国庆等)、重要日(比如:重大促销日等)以及这些天前后的日期,特殊日的变化往往与日级别的周期性变化特征相反,比如,如果当天是工作日,但同时又是节假日,那么当天的交易量通常要比其它工作日要低很多,如图7所示,“—”线代表正常的工作日交易量,“:”线代表特殊的工作日的交易量,可以看出,特殊的工作日由于该天实际上是假期,所以导致其交易量比正常的工作日要低;如果当天是休息日,但同时又是实际上需要工作的日期,那么当天的交易量通常要比其它休息日高很多,如图8所示,“—”线代表正常的休息日交易量,“:”线代表特殊的休息日的交易量,可以看出,特殊的休息日由于该天实际上是工作日,所以导致其交易量比正常的休息日要高很多。

图7 特殊工作日交易量变化趋势

图8 特殊休息日交易量变化趋势
综合以上分析,在特征工程阶段,将每条记录扩展为20维(feature_size=20)的特征向量,这里将第i条记录记为Xi,Xi={fj,j=1,…,feature_size-1},其中,第2个特征即交易量是重点关注的,记为Yi。具体每一维的含义如表1所示。

表1 特征向量的特征含义
数据量共有241天×1440分钟-time_step=346980条,这里time_step取60,表示每连续60条分钟级别的记录作为1个样本Si,即Si是由[X0,X1,X2,…X59]组成,因此Si的维度为[time_step,feature_size]=[60, 20],样本Si的组成如图9所示,Y0为下一时刻的交易量值,以此来生成训练集和测试集,这里将其中的90%作为训练集(312282条),其余数据作为测试集(34698条),具体如图10所示。

图9 样本Si的组成

图10 训练集与测试集的Si、Yi
由于LSTM对数据尺度敏感,所以根据特征的性质将20维特征的每一维进行标准化:
1)对于f6、f7特征,使用one-hot编码取值为0或1;
2)对于其它特征使用z-score标准化使其符合标准正态分布。
3.3 模型结构
本文设计的LSTM-WP(LSTM-WebPredict)模型使用6层神经网络,包括输入转换层(Input Layer)、处理层(LSTM Layer)与输出转换层(Output Layer),如图11所示。其中,输入转换层由1层全连接层(FCN:Fully Connected Network)构成,负责将每一时刻的训练样本数据Xi由原始维度[batch_size:64, time_step:60, feature_size:20]转换成与LSTM cell的num_units具有相同的维度[batch_size:64, time_step:60, num_units:128],如图12所示;处理层由3层LSTM构成,每一层由1个LSTM cell在60个时间步长上(time_step)展开,加入dropout过程防止模型过拟合,如图13所示;输出转换层由2层全连接层构成,负责将最后一个时间维度的LSTM cell的输出转换成预测的交易量,数据维度的变化过程为:[batch_size:64, num_units:128]-> [batch_size:64, output_layer1_size:64]-> [batch_size:64, output_layer2_size:1],如图14所示。

图11 LSTM-WP 模型设计

图12 Input Layer
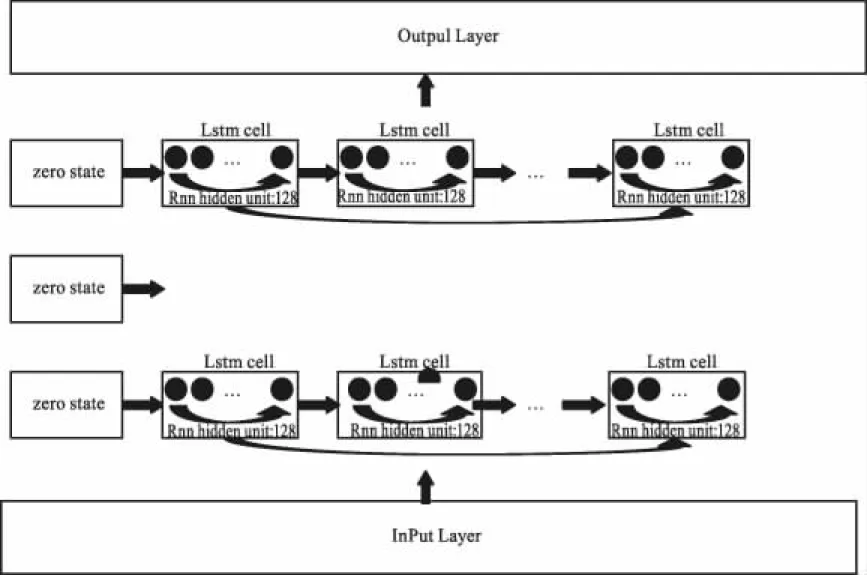
图13 LSTM Layer
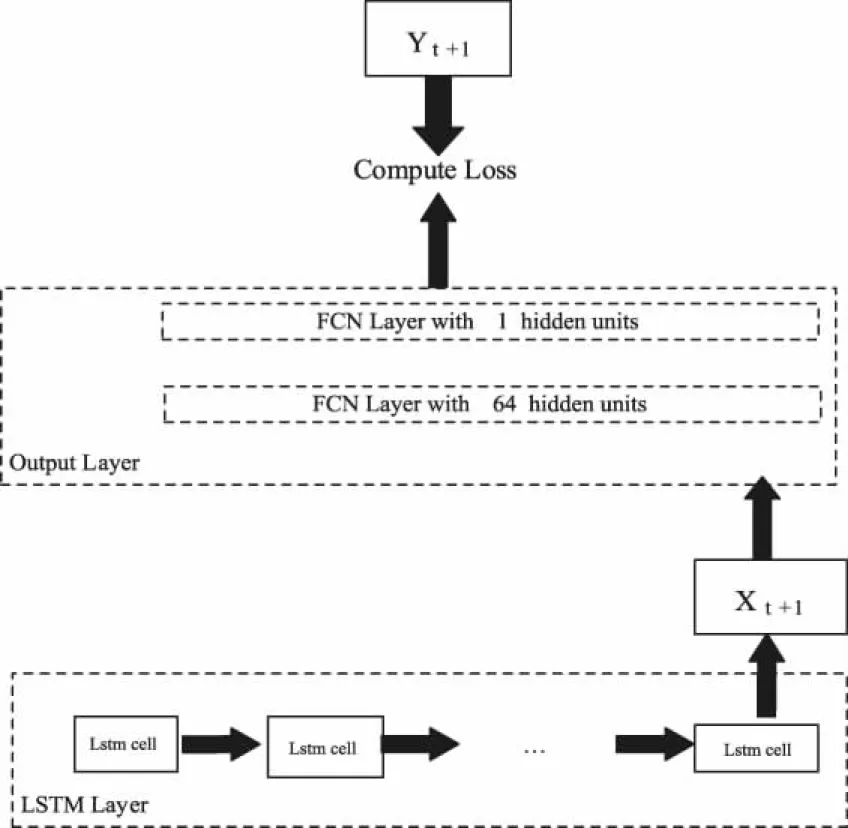
图14 Output Layer
3.4 训练与预测
在训练过程中,模型使用平方误差来刻画损失,使用L2正则化来防止模型过拟合,损失函数的定义参见式(8)所示,L2正则化公式见式(9),其中,y_t表示第t分钟的实际交易量,y_pre表示第t分钟的预测交易量,γ表示正则项系数,Wi表示第i个参数,模型共有m个参数。
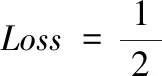
(8)

(9)
在评价过程中,模型使用均方误差(RMSE:root mean squared error)来评价模型的好坏,它反映了预测值对观测值的平均偏离程度,取值大于或等于零,预测无误差时等于零,均方误差的计算公式参见式(10)所示,其中,n为1440,表示预测当天的1440分钟,y_t表示第t分钟的实际交易量,y_pre表示第t分钟的预测交易量。

(10)
在预测过程中,本文使用滑动窗口方法,在每一天的凌晨0点5分触发预测过程,根据上一日的引导数据并以此不断更新引导数据来预测当天1440个分钟的交易量。具体方法如下,算法伪代码1给出了具体过程。
1)生成引导数据:取前一天最后60分钟的交易量数据,即从23:00:00时刻到23:59:00时刻的实际交易量,生成维度为[time_step, feature_size]的特征向量;
2)喂进已训练好的模型中:模型输出下一时刻的交易量的预测值,如第一次触发即生成00:00:00时刻的预测交易量Y0;
3)更新引导数据:利用该交易量的预测值生成下一时刻维度为[1, feature_size]特征向量,即00:00:00时刻的特征向量,并将其添加到引导数据中的最后,再删除最早时刻的特征向量,保证引导数据维度仍为[time_step, feature_size];
4)上述2)、3)步不断迭代运行,直到预测出当天全部1440个分钟的交易量,即当天的00:00:00到23:59:00。
算法伪代码 1:基于滑动窗口预测交易量

算法变量定义:
1)lead_data表示用于计算当天00:00:00时刻交易量的引导数据
2)fv表示根据引导数据生成的特征向量
3)nfv表示标准化后的特征向量
4)next_predict_count表示根据引导数据计算的下一时刻交易量的预测值
5)predict_count表示当天1440个交易量预测序列
6)next_minute_fv表示下一时刻分钟的特征向量
7)lstm()表示训练好的模型
8)time_from, time_to表示引导数据的开始时刻与结束时刻
输入:time_from, time_to
输出:predict_count
算法开始:
1)lead_data=create_lead_data(time_from=23:00:00, time_to=23:59:00)
2)fv=create_feature_vector(lead_data)
3). nfv=normalizied(fv)
4)for i in range(1440):
5)next_predict_count=lstm(nfv)
6)predict_count.append(next_predict_count)
7)next_minute_fv=create_next_minute
_feature_vector(next_predict_count)
8)fv=update_feature_vector(fv,
next_minute_fv)
9)nfv=normalizied(fv)
10)Return predict_count.
3.5 结果分析
本文使用LSTM-WP模型的预测结果与加权平均算法的预测结果在2020年劳动节节假日期间的表现进行了对比。劳动节节假日的时间信息如表2所示。

表2 2020年劳动节节假日信息
五天相应的预测对比结果如表3所示,可以看出,在节假日期间LSTM-WP模型的均方误差要低于加权平均算法的均方误差,平均降低了约8.63%,即LSTM-WP的预测准确率更高。
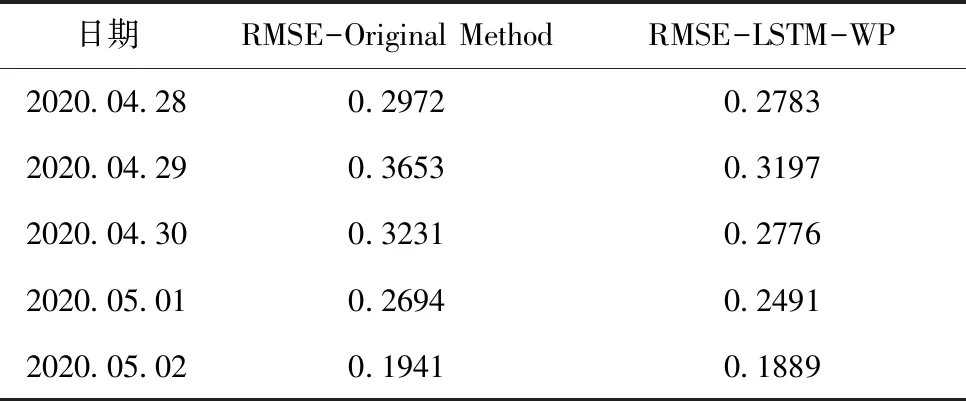
表3 预测对比结果
4 总结与展望
利用机器学习和深度学习算法助力金融科技中的趋势预测等应用场景越来越成为一种趋势。本文在分析交易量历史数据特征的基础上,基于长短期记忆网络LSTM设计并实现了一种用于交易量预测的模型LSTM-WP,并与基于统计学的加权平均算法进行对比,结果表明,在对于特殊日这一类重要日期的预测上,LSTM-WP模型的准确率提高了约8%,同时,随着训练数据的不断增多,模型的学习能力会逐渐增强;不仅如此,该算法的研究对于将AI技术应用于其它时间序列问题的业务场景,比如异常检测、容量评估等也提供了相应的技术积累。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
小学阅读指南·高年级版(2014年2期)2014-05-27
IT经理世界(2014年9期)2014-05-22
