
基于多智能体强化学习的露天矿车辆调度方法
2023-07-01 06:49李新华
西安邮电大学学报 2023年1期
李新华
(国家能源集团 神东煤炭集团有限责任公司,陕西 榆林 719315)
近年来,无人驾驶作为结合人工智能与工程技术的最新技术,在各种露天矿山得到广泛应用,实现了对露天矿区的智能化控制和管理,从而提高了生产效率和安全性。研究应用于露天矿的无人驾驶卡车的运输调度,不仅有助于企业提高经济效益,降低资源消耗,而且对于实现露天矿的自动化和智能化开采具有重要意义[1-3]。随着露天矿无人驾驶技术的不断发展,基于遗传算法、模拟退火等元启发式算法以及基于线性规划、整数规划等传统优化方法已经不能满足露天矿车辆实时调度、高能耗比和提高调度智能化水平等新需求[4-6]。因此,将工程技术手段和人工智能技术结合,提高车辆调度的精确度和智能化水平、实现自动化控制和优化管理已成为智慧矿山建设过程中亟待解决的问题[7]。
露天矿车辆调度问题本质上是一个运输成本最小化的优化问题,一般采用传统优化方法或元启发式算法。随着无人驾驶技术的发展,针对露天矿车辆调度问题,相关研究主要从排队论、线性规划及多目标优化等3个方面开展了研究。排队论算法是将卡车视作运输队列中等待装矿/卸载服务的个体,并建立排队论模型明确卡车运输目的地,即装矿/卸载点。虽然可以配置卡车的最佳方案,但存在车辆同质性的约束[8]。线性规划方法目前已经被广泛应用于露天矿卡车调度模型,但随着卡车数量的增加,存在组合爆炸的风险[9]。多目标优化模型是国内外露天矿车辆调度从业者研究的重点,这是由于在露天矿调度问题上不能只考虑单个经济指标作为车辆调度的目标[10]。张明[11]等以矿车运输总成本和等待时间作为优化目标,运用多目标遗传算法求解了露天矿车辆调度问题。此外,阮顺领[12]等除了考虑卡车运输成本和等待时间外,还将卸矿站品位偏差率作为优化目标,最终结合历史调度数据使用改进的人工鱼群算法求解。程平[10]等综合考虑电池电量、车铲生产能力及矿石品位等多种影响因素,构建了基于碳排放成本的露天矿新能源纯电动卡车多目标调度优化模型。基于多目标优化模型的露天矿调度方法虽然能够考虑多重因素,从而求解出较优的解,但存在模型参数多及求解耗时的问题。现有研究方法在一定程度上改善了露天矿车辆调度问题,但存在难以兼顾调度精度和调度效率的问题。
随着强化学习(Reinforcement Learning,RL)算法的兴起,也有一些基于强化学习的调度方法。叶则芳[13]等提出了一种改进的强化学习调度算法,在Spark调度模型中取得了良好的调度性能,有效解决了计算集群调度问题。朱家政[14]等针对传统调度算法实时性较差而难以应对复杂多变的实际生产调度环境的问题,提出了一种长短期记忆的近端策略优化算法,用于解决复杂条件下的作业车间调度问题。强化学习模型能够在短时间内较好地给出复杂调度问题,是一个较优的调度方法。
为实现对露天矿车辆的实时调度,拟提出基于多智能体强化学习的露天矿车辆调度方法。该方法基于集中式训练分布式执行的范式构建了一个多智能体强化学习模型,用于处理露天矿车辆调度问题。通过对露天矿车辆调度、装矿点及卸矿点特征的分析,设计露天矿车辆调度仿真环境。构建一个演员评论家框架的多智能体强化学习模型,用于对露天矿车辆调度。同时,对比分析所构建的基于社交感知的多智能体深度确定性策略梯度(Socially aware-Multi-Agent Deep Deterministic Policy Gradient,S-MADDPG)模型与多智能体深度确定性策略梯度(Multi-Agent Deep Deterministic Policy Gradient,MADDPG)模型及深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)模型等两个典型模型的调度效率。最后,验证所提方法的可行性。
1 相关理论基础
1.1 强化学习
强化学习研究的是智能体在复杂环境下采取怎样的动作最终获取最大的奖励。强化学习由智能体和环境两部分组成。智能体通过对从环境中观测到的状态进行分析后做出动作,然后环境会给出执行动作后的下一个状态和该动作在复杂环境下获得的奖励。
在随机过程中,马尔科夫性[15]是指一个随机过程在给定现在状态st和过去状态ht的情况下,未来状态st+1的概率分布p仅依赖于当前状态的性质,其表达式为
p(st+1|st)=p(st+1|ht)
(1)
因此,智能体与环境的交互过程可以通过马尔科夫决策过程(Markov Decision Process,MDP)表示。
通常情况下,智能体能观测到的状态都是部分信息,这种部分可观测MDP通常被用一个七元组描述[S,A,T,R,Ω,O,γ][16]。其中:S表示状态空间;A为动作空间;T(s′|s,a)表示状态转移概率;R为奖励函数;Ω(o,|s,a)表示观测概率;O为观测空间;γ为折扣因子。强化学习的状态价值函数Vπ和动作价值函数Qπ可以分为即时奖励和后续状态折扣价值两部分,分别定义为
Vπ(s)=
(2)

(3)
式中,π表示策略矩阵。
1.2 多智能体强化学习
多智能体强化学习是强化学习和多智能体体系结合而成的新领域。多智能体的核心是把系统分成若干智能体及自治的子系统,在物理和地理上既可以分散且可以独立执行任务,多智能体之间又可以相互通信、相互协调及共同完成任务。多智能体强化学习目前有集中式学习、独立式学习和集中式训练分布式执行等3种通用范式。集中式学习是将整个系统视为一个整体,与单智能体强化学习模型类似;独立式学习是让每个智能体独立训练自己的策略,其建模简单,但忽视了多智能体之间的联系;集中式训练分布式执行作为前两者的折中选择,在训练时利用全局视角,执行过程中各自独立。多智能体强化学习系统描述为
[N,E,a1,a2,…,aN,T,γ,r1,…,rN]
(4)
式中:N为智能体个数;E为系统状态,一般指多智能体的联合状态,例如可以是(x1,y1),(x2,y2),…,(xN,yN),即表示运输卡车的位置坐标;a1,a2,…,aN表示智能体的动作合集;T表示状态转移函数,可以根据当前系统状态和联合动作给出下一状态的概率分布;r1,…,rN表示智能体在多智能体采取联合动作后各智能体分别获得的奖励。多智能体强化学习架构示意图如图1所示。

图1 多智能体强化学习架构示意图
2 露天矿车辆调度问题
在露天矿的实际开采过程中,系统需要协调多个装矿点和卸载点之间的工作。矿车将矿物从装矿点运输到一个或多个卸载点进行作业[17]。装矿点到卸载点距离不同,矿车产生的运输成本也不同。因此,这里将露天矿车辆调度问题看作是求解矿车最小运输成本的问题。
在露天矿车辆运输过程中,矿车状态可简单地分为空载、待载、载入、运输、带卸、卸载及故障7种状态。假设矿车从第i个装矿点Mi载入到第i个装矿点装车再到第j个卸载点卸载,再回到Mi为一次完整的运输调度过程,则该过程中产生的运输成本为燃油成本、启动成本及故障维修成本之和。其中:i=1,2,…,I,I为装矿点数量;j=1,2,…,J,J为卸载点数量。
2.1 燃油成本
在一次调度过程中产生的燃油成本z1为矿车空载、运输及卸载时所消耗的成本之和,其表达式为

(5)

2.2 启动成本
矿车一次完整调度运输过程中的启动成本的表达式为
(6)
式中,P2表示每辆矿车的启动成本。
2.3 故障维修成本
故障维修费用为
(7)
式中,P3表示每辆矿车的平均故障维修成本。因此,露天矿车辆运输调度优化模型为
minZ=min(z1+z2+z3)
(8)
式中:Vk表示第k辆矿车的装载量;Qi表示对应装矿点的总矿量;S表示一次生产计划中总调度次数;gi表示对应卸载点的卸载总量。
3 S-MADDPG模型构建
3.1 强化学习环境
结合露天矿车辆调度的特点,设计了强化学习仿真环境,具体如图2所示。其中,实心方框为装载点,空心方框为卸载点。

图2 露天矿强化学习仿真环境
为简化强化学习模型,将随时间的连续变化转换为按时间片逐帧变化。也就是说,环境中的所有信息都会在每个时间片更新一次,时间片是环境的一个超参数,可以进行调节。露天矿车辆调度环境可分为奖励设置、装载点矿量变化、车辆位置及车辆可选择的路径变化。
对于复杂问题而言,强化学习的奖励设置通常都是较为稀疏的。为削弱强化学习模型奖励的稀疏性,设置当矿车装有矿物并执行卸矿操作时,进行一次奖励。这样可激励智能体执行装矿和卸矿操作,而不是进行无用的调度。在实际的露天矿生产过程中装载点的矿量会实时发生变化,这种变化与装矿点产矿能力相关。因此,需要对每个装矿点的产矿速度进行设置,而不是将装矿点的矿量假设为无限。
车辆的位置在该环境中用二维x-y坐标表示。考虑到当所有智能体走的路径都是最优的条件下矿车不会走回头路,因此假设所有矿车类型相同,都不走回头路,即只有当矿车走到卸载点或者装载点的时候才能选择路径,当走到路中间时不可回头。此时,装矿和卸矿时间各消耗一个时间片。
3.2 强化学习智能体
强化学习智能体是一种能够通过与环境进行交互来学习最优决策的人工智能系统,其多智能体训练网络如图3所示[18]。其中,Q表示Q-学习模型。每个智能体网络的输入为当前矿车的位置、装货状态及所有装矿点的矿量输出矿车的行驶方向,评论家网络的输入为所有矿车的位置、装货情况及所有装矿点的矿量。

图3 多智能体训练网络
4 实验结果及分析
4.1 仿真环境
编程环境设置为Python3.9、Pytorch1.13,显卡为Rtx3090,电脑环境为I9-12900k,搭建一个基于Tkinter0.1.0框架的仿真环境。
4.2 强化学习仿真环境
根据强化学习方法构建强化学习仿真环境,为后续智能体网络训练做准备。基于多智能体强化学习的露天矿无人车调度实验仿真过程如图4所示。环境中实心圆点为装有矿物的矿车,空心圆点为没有矿物的矿车。

图4 露天矿无人车调度实验仿真过程

(续)图4 露天矿无人车调度实验仿真过程
4.3 模型训练过程分析
MADDPG模型是集中式学习的代表,其训练过程奖励变化情况如图5所示。该模型权重多、信息冗余,难以收敛。将整个系统视为一个整体,采用单智能体强化学习算法训练,解决了环境非平稳问题,但需要全局通信,不可扩展,且在解决无通信、大规模和大动作空间方面存在不足。

图5 MADDPG模型训练过程奖励变化情况
DDPG模型是独立式学习的代表,其训练过程奖励变化情况如图6所示。由图6可以看出,平均奖励随着交互次数的增加波动较为明显,但整体呈现出稳定趋势。但是,DDPG模型的独立式学习策略忽视了多个智能体之间的联系,这对于一些合作任务会增加学习过程的不稳定性。

图6 DDPG模型训练过程奖励变化情况
S-MADDPG模型训练过程奖励变化情况如图7所示。作为折中,训练时拥有全局通信,提高学习效率,执行时各自独立决策,这在一定程度上改善了多智能体学习问题。S-MADDPG模型在改善环境非平稳问题的同时,在合作任务中可以更好地适应于协作的情况,通过训练智能体之间的合作和协调实现了较优的运输策略。
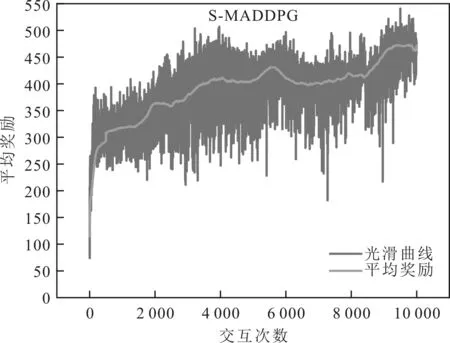
图7 S-MADDPG模型训练过程奖励变化情况
4.4 模型测试过程分析
不同模型测试过程奖励变化情况如图8所示。由图8可以看出,所构建的S-MADDPG模型的范式模型较其他模型效果更优。该模型能够在合作任务中通过协作、竞争和协调等机制,使得多个智能体能够相互合作,有效地完成任务。

图8 不同模型测试过程奖励变化情况
4.5 多智能体矿车调度的实时性和能耗比分析
基于多智能体强化学习构建的露天矿车辆调度方法能够根据车辆自身信息和所有装载点信息对车辆的路径进行导引。在实验过程中,计算出车辆路径过程只需1 s,因此理论上完全能够达到实时调度。
在强化学习的环境中车辆除了在装载和卸载过程中是处于停车状态外,其他状态都保持在行进状态中。可以通过总的时间片减去装载和卸载消耗的时间片得到车辆运行的时间片,表达式为
T=Tsum-Tstop
在每个时间片中,研究人员记录了每辆车的位置、速度和油量等信息。通过计算每个时间片中每辆车消耗的油量,并将其与总时间片相乘,得出了测试过程中所有车辆的总耗油量。此外,在奖励分析中,每卸矿一次进行一次奖励,对每辆车在卸煤时进行了记录和统计,并据此计算出每辆车的总装载量和运矿量。由此可以发现,通过该多智能体强化学习模型的应用,不仅可以优化车辆调度系统,还可以提高运输效率并降低成本。
5 结语
针对露天矿车辆调度问题,提出了一种基于多智能体强化学习的露天矿车辆调度方法,旨在通过协同决策和资源共享提高车辆调度效率和成本效益。该方法的核心是将多个智能体进行耦合,并使其在任务执行中实现协调和协作,从而能够更好地应对复杂的调度环境和动态变化的任务需求。为了验证所提方法的有效性,将所构建的S-MADDPG模型与MADDOG模型、DDPG模型等两个经典模型在实时性和能耗比等方面进行对比。验证结果表明,所提方法能够改善卡车调度的实时性问题,并能提高露天矿车辆调度能耗比。通过该多智能体强化学习模型的应用,可以实现车辆的自主调度、多智能体协同决策、动态资源分配和成本优化等功能。
猜你喜欢
有色金属(矿山部分)(2021年4期)2021-08-30
电子乐园·上旬刊(2021年8期)2021-05-16
桂林理工大学学报(2020年2期)2020-08-18
作文大王·低年级(2020年2期)2020-03-13
机械管理开发(2020年1期)2020-02-17
中国矿业(2019年7期)2019-07-26
幽默大师(2019年5期)2019-05-14
现代矿业(2018年1期)2018-03-15
中国煤炭(2016年9期)2016-06-15
河北地质(2016年1期)2016-03-20
