
基于U-Net的田间小麦收获边界图像分割方法研究
2023-06-28 01:32建瑞博蔡智勇杨自尚王万章刘源陈劲帆王妙林
河南农业大学学报 2023年3期
建瑞博, 蔡智勇, 杨自尚, 王万章, 刘源, 陈劲帆, 王妙林
(1.河南农业大学机电工程学院,河南 郑州 450002;2.漯河市农业科学院,河南 漯河 462000)
随着科技的发展,农业全程机械化[1]正在向智能化方向发展。将图像处理[2]和机器学习[3]应用在农业上,对农业的发展有很大的帮助。将已收获后的麦茬区域和未收获麦穗和植株进行分割识别,可以对谷物联合收获机起到辅助导航的作用,有效减少高强度劳动对机手的影响,也有助于提高收获机的收获效率。传统图像分割方法容易受到复杂作业环境条件限制,难以大规模地布置和实施,而且容易受到光照的影响,出现少分割或者过分割的情况,准确率低且浪费时间。因此,做到高效及精准分割一直是图像分割领域的难题。
近年来,传统的图像分割算法包括直方图阈值分割法[4]、Canny边缘检测法[5]、分水岭法[6-7]等在农业领域得到了广泛的应用。传统的图像分割算法,是将人工提取的图片根据形状、颜色、纹理等特征将图像进行划分区域,找出各区域间的差异性和相似性。GEE等[8]使用双霍夫变换(DHT)与斑点着色分析法来对区域内的作物和杂草进行区分;SAINZ等[9]提出宽行农田映射方法,使用图像序列中某些裁剪行的中心作为要跟踪的特征,以此对农田作物图像进行水平行检测;赵腾等[10]使用阈值分割的方法实现对小麦已收获区域和待收获区域的分割,但是这些方法都需要图像复杂处理,还需要人工的干预,而且无法对复杂环境下拍摄的图像进行处理。随着人工智能的发展,深度学习[11-12]领域中各种模型被提出,有较强的特征提取能力的卷积[13-15]神经网络在图像处理方面得到了极大的应用。SHELHAMER等[16]最早提出了全卷积网络(FCN),FCN对图像进行像素级的分类,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生一个预测。之后,以FCN模型为基础的算法被大量提出,应用在各个行业,各个领域。吴伟斌等[17]利用改进的PSP-Net模型对茶、果园道路进行识别,可以有效分辨硬化道路与非硬化道路为农业机械提供路线引导;金伦等[18]使用fine-tune FCN模型实现了对青菜病虫害区域的有效识别;王美娟等[19]使用多尺度卷积神经网络VGG-16,对玉米叶片病害症状进行识别,为玉米病害检测和病斑提取提供参考;饶秀琴等[20]提出Fast-U-Net模型,实现了对玉米、棉花、甘蔗等作物导航路径的提取,并确保了很高的识别精度;曾镜源等[21]使用Mask-R-CNN与YOLOv3模型,实现了对柚子姿态的识别与定位。
传统的图像分割方法容易受到外界光照,风以及噪声影响,同时用颜色和形状等特征对麦茬和麦穗进行分割图像,往往没有考虑像素与像素之间的关系,缺乏空间一致性等问题,从而难以对颜色相近的麦茬麦穗进行有效分割。RONNEBERGER等[22]在2015年提出U-Net模型,最早是为了解决医学图像分割的问题,与其他语义分割模型相比,该模型不仅支持少量的数据训练模型,而且对图像的分割准确率更高,分割速率更快。因此,本研究采用U-Net语义分割模型对小麦收获麦田图像进行深度学习训练,实现快速高效识别已收获后的麦茬地和未收获的麦穗与植株区域。从而可以为机手驾驶作业提供辅助导航信息,保证了机手作业的安全性,同时也为自动导航提供新的路径和参考依据。
1 材料与方法
1.1 小麦收获图像数据采集
本试验以完熟期小麦作为研究对象,于2022-06-08—2022-06-09(时间段为09:00—13:00、14:00—19:00)在河南省濮阳市清丰县尚村进行数据采集,当地小麦植株高度均值为67 cm,割茬高度均值为17 cm。采集设备选取200万像素工业相机,图像分辨率为1 920×1 080像素,帧率30 f·s-1,镜头选用可变焦镜头,型号为HW2812,可变焦距为2.8~12.0 mm,方便采集数据时实时调整焦距,优化拍摄效果。经过多次试验测试,将相机固定在联合收获机右侧后视镜支架上,如图1所示相机距离地面高度为3 m,相机与水平方向夹角为30°。保证采集的数据清楚地包含收获后的区域和未收获的区域。方便后期的数据集制作与模型的训练。从采集的视频和照片中共筛选出2 000张图片,按照训练集与测试集4∶1的比例进行划分,得到1 600张测试集,400张训练集;通过使用Labelme标定软件对图像进行标定,得到已收获的麦茬区域和未收获的麦穗与植株区域。
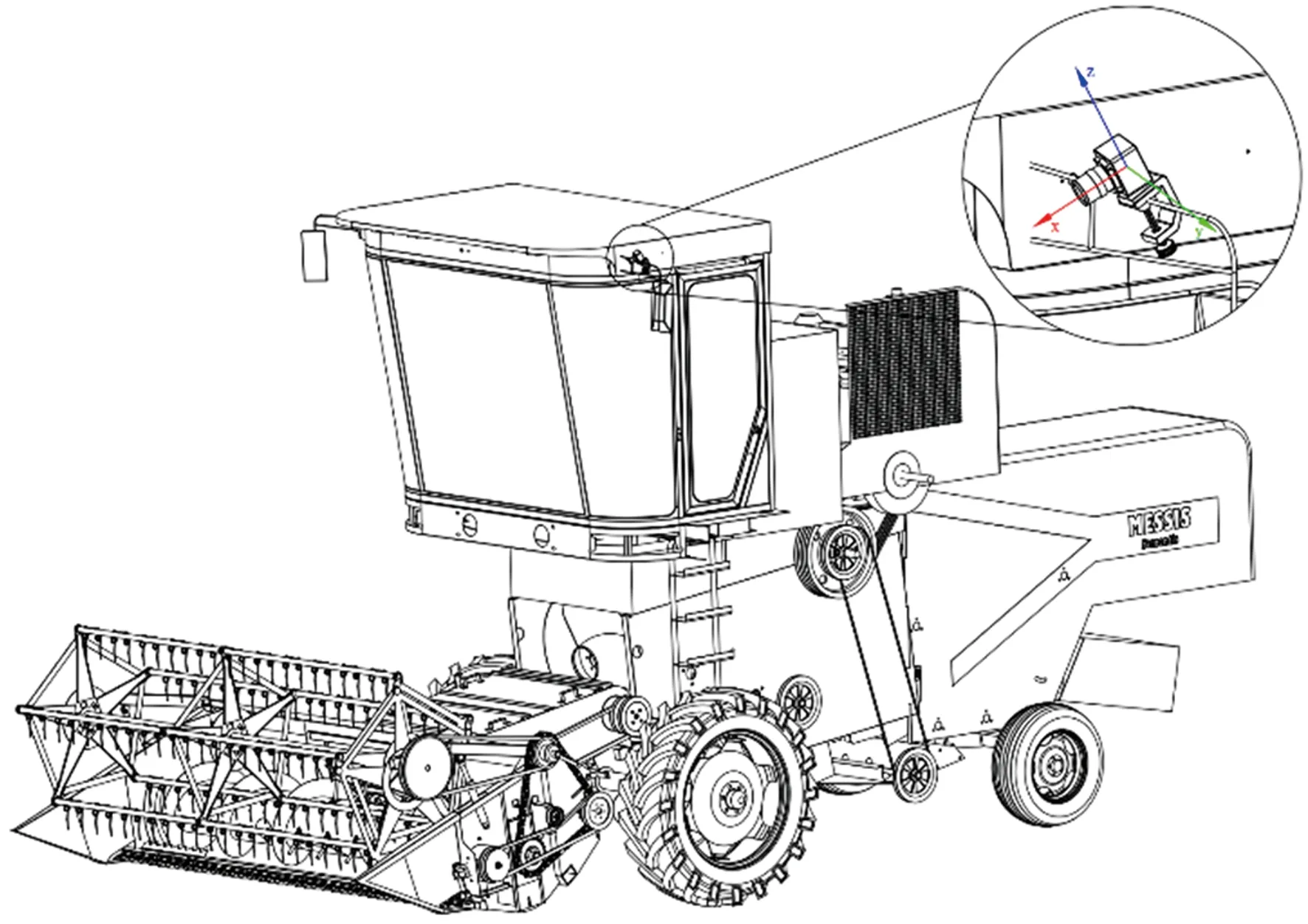
图1 相机安装位置图
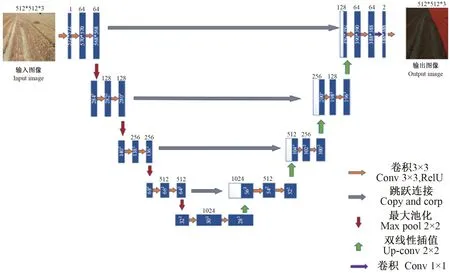
图2 U-Net网络结构图
1.2 U-Net网络结构和主要算法
1.2.1 U-Net网络结构 本研究所采用的U-Net模型,是一个经典的全卷积网络[23]。包括左侧主干特征提取编码与右侧加强特征解码两部分。输入小麦收获边界图像尺寸为512×512像素,经过主干特征提取部分的5个有效特征层,每个特征层都会进行2次3×3的卷积和1次2×2池化,然后经过4次下采样,最终获取到图像中的详细特征信息。第2部分为加强特征解码部分,对解码后的5个有效特征层进行上采样,并进行特征融合,最终获得一个融合所有特征的有效特征层,解码部分每层网络先进行2×2的上采样,然后进行2次3×3的卷积,以此类推,最后一层经过卷积后,使用1×1的卷积进行网络通道调整,最后通过RELU函数对小麦未收获麦穗与植株区域和收获后的割茬区域进行二分类,输出分割结果。
1.2.2 主要理论介绍
1.编码器(encoder)-解码器(decoder)框架是指整个网络中存在一个主要的编码器块和解码器块。编码器块主要用来从输入中提取特征图谱,而解码器块主要是将经过编码器处理的输入所得到的特征进行进一步的特征优化和任务处理。具体来说,编码器的任务是在给定输入图像后,通过神经网络学习得到输入图像的特征图谱;而解码器则在编码器提供特征图后,逐步实现每个像素的类别标注,从而实现分割。
2.卷积与反卷积
对于卷积,其主要处理的是空间信息,从一维卷积可以推论二维卷积核的信息可视为一种图像,通常是对图像进行压缩,它的大小刚好描述了空间中色彩或者其他值的高低。反卷积可视为一种上采样,是一种特殊的正向卷积,先按照一定的比例通过给矩阵补0来扩大输入图像的尺寸,接着旋转卷积核,再进行正向卷积,目的是基于正向卷积核以及卷积后的图像恢复原图像大小,由于使用的是转置矩阵而非逆矩阵,所以反卷积也称为转置卷积,从而提高图像的恢复效率。
3.正向传播与反向传播
正向传播是指对神经网络沿着输入层到输出层的顺序,依次计算并存储模型的中间变量。反向传播是一种计算神经网络参数梯度的方法,是按照从输出层到输入层的顺序,依据链式法则,依次计算并存储目标函数有关神经网络各层的中间变量以及参数的梯度。在深度学习模型中,正向传播和反向传播相互依赖[24],正向传播的计算可能依赖于模型参数的当前值,而这些模型参数是在反向传播梯度计算后通过优化算法迭代的;反向传播的梯度计算可能依赖于各变量的当前值,而这些变量的当前值是通过正向传播计算得到的。因此,在参数初始化完成后,需要交替进行正向传播和反向传播。
4.跳跃连接
在训练深度神经网络时,模型的性能随着架构深度的增加而下降,也就是模型退化问题,这是由于过度拟合和梯度消失造成的。跳跃连接(skip connection)可以跳跃神经[25]网络中的某些层,使得网络在每一级的上采样过程中,将编码器对应的特征图在通道上融合,通过底层特征与高层特征的融合,网络能够保存更多高层特征图蕴含的高分辨率细节信息,可以解决梯度消失的问题,为后期图像分割提供多尺度多层次信息,从而有效地训练网络层参数,得到更精细的分割效果。
5.激活函数
本研究采用RELU函数作为激活函数,RELU函数又称为修正线性单元,是一种分段线性函数。当它的输入为正时,不存在饱和梯度只存在线性关系而且计算速率快。目前在深度神经网络被广泛应用。它本质上是一个斜坡(ramp)函数,其公式如下:
6.损失函数
本研究的损失函数取自交叉熵损失函数与Dissloss的平均值,其中交叉熵损失函数(crossentropyloss)公式如下:
式中:N为总的样本数量;yic为样本i和标签c如果相同就取值1,否则为0;yp为样本i属于c的预测概率。
Diceloss是一种集合度度量函数,用来计算2个样本相似度,取值范围在[0,1],通常Loss值越小越好。所以用1-DiceLoss的值来表示Diceloss。其公式如下:
式中:X为预测值的合集;Y为真实值的合集。
2 结果与分析
2.1 试验环境
本试验的硬件环境:CPU为Intel Core i7-12700KF、内存为32 G、GPU为NVIDIA GeForce GTX3080Ti、显存12 G;软件环境:在Windows 11操作系统中的PyCharm 2021.1.2 IDE下使用Python 3.8语言版本,基于Pytorch 1.7.1深度学习框架。
2.2 评价指标
2.2.1 像素准确率 像素准确率是(pixel accuracy,PA)是图像分割中最常用的一种评价指标,它表示预测类别正确的像素数占总像素数的比例,公式如下:
式中:FN表示将未收获的麦穗和植株区域预测为收获后的麦茬区域;FP表示将收获后的麦茬区域预测为未收获的麦穗和植株区域;TN表示正确预测收获后的麦茬地。
2.2.2 均交并比 均交并比(mean intersection over union,MIOU)是模型对每一类预测的结果和真实值的交集与并集的比值,求和再平均的结果。公式如下:
式中:k表示分类的类别;i表示真实值;TP表示正确预测未收获的麦穗和植株区域;FN表示将未收获的麦穗和植株区域预测为收获后的麦茬区域;FP表示将收获后的麦茬区域预测为未收获的麦穗和植株区域;TN表示正确预测收获后的麦茬地。
2.3 试验步骤
使用U-Net模型进行收获区与未收区识别,可以分为3个步骤,如图3依次是:数据集制作、模型训练、结果预测。首先需要制作数据集,从采集好的图片中进行挑选,去除掉模糊、杂乱的图片,然后挑选出2 000张作为数据总集,挑出1 600张图片作为训练集,400张作为测试集,使用Labelme软件对其进行标定。然后在U-Net主干结构下开始对训练集中1 600张图片进行训练。本试验初始学习率设置为0.000 5 ,训练周期设置为100,考虑到存储空间因素,取得样本数为4。采用RELU函数为激活函数、Diss loss函数作为损失函数,采用Adam优化算法优化网络参数。并且在训练过程中,通过不断观察损失函数收敛情况,可以调节网络相关参数来达到所期望的结果。最后,通过不断地迭代训练,获得最优的模型迭代结果,将最优的输出结果进行保存,对测试集图片来进行测试。
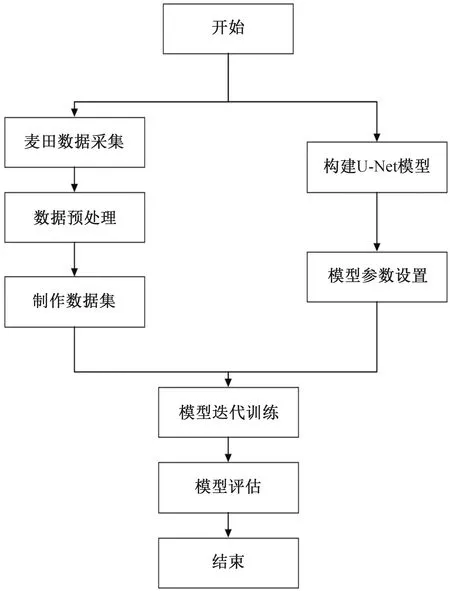
图3 基于U-Net模型的小麦收获边界识别流程
2.4 结果分析
对于本次试验所采集的数据集,将图像标定分类训练后,得到训练损失函数图。由图4可以看出,该模型在训练过程中的损失函数变化图,随着训练次数增加,训练集和测试集的损失函数逐渐减小,收敛速率较快且稳定收敛在0.02附近,而且两个训练集的函数线条误差也一直减小且逐渐稳定,说明在梯度计算过程中,U-Net模型有良好的学习效果,性能稳定。同时训练集和测试集变化趋势相同,说明网络训练逐步收敛。
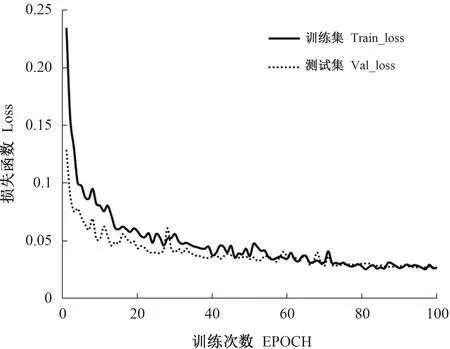
图4 损失函数变化图
试验中将未收获的小麦与植株区域作为类别1,将收获后的麦茬地作为类别2,分别经过U-Net模型运算结果如表1所示,分割效果如图5、图6所示。
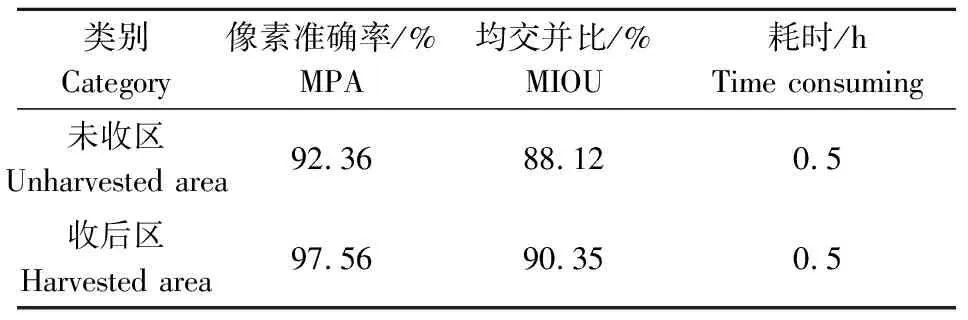
表1 模型评价指标

图5 U-Net分割前后比较图

图6 分割效果比较
3 结论与讨论
本研究提出了一种基于U-Net模型的田间小麦收获边界图像分割方法,实现了评价指标MPA 94.96%、MIOU 89.24%的高精度结果,实现了对已收获的麦茬区域和未收获的麦穗与植株区域的精准分割,识别准确率显著优于传统方法。在本研究的方法之外,分别使用阈值分割算法,分水岭算法,Canny边缘检测算法对小麦收获区域进行分割识别,然后与U-Net模型分割效果对比。从中可以看出阈值分割算法、分水岭算法、Canny边缘检测算法对已收获的麦茬地区和未收获植株区域的分割效果较差。由于麦穗和麦茬两者颜色相近,因而很难被区分开来。而且田间环境复杂,作业时间多为白天,在数据采集过程中多伴随强光和噪声;使用传统方法在进行图像处理时必须去除掉图像中的杂点和噪声点;即使使用灰度化、二值化、滤波等方法也不可能去除所有杂点和噪声点,进行分割时还会受到影响。但是使用U-Net模型不需要考虑外界情况,该模型的分割效果不会受到外界光照、噪声所产生的杂点和噪声点的影响,因而能够将已收获的麦茬区域和未收获的麦穗与植株区域进行精准分割识别。
总的来说,U-Net模型分割方法与传统的图像分割方法相比,对于风、光照、噪声等外界环境的干扰有较强的鲁棒性和泛化能力。与赵腾等[10]使用阈值分割方法来对小麦收获边界进行识别相比,本文方法对小麦收获边界分割效果更好,精度更好,速率更快,可以更好地为机手驾驶作业提供辅助作用。但是,由于小麦收获场景复杂,该算法在对倒伏麦地和种植稀疏麦地存在分割不准确情况,因此对完善不同场景数据集,提高算法准确率,仍需进一步优化研究。
猜你喜欢
轻音乐(2022年11期)2022-11-22
作物学报(2022年2期)2022-11-06
北京航空航天大学学报(2021年9期)2021-11-02
阅读(低年级)(2021年4期)2021-06-15
椰城(2019年9期)2019-10-08
电子制作(2019年11期)2019-07-04
民族音乐(2018年5期)2018-11-17
趣味(语文)(2018年7期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
含笑花(2017年2期)2017-03-29
