
基于两阶段数据驱动模型的双馈发电机异常运行状态检测方法
2023-06-28 02:27黄鹤鸣
直升机技术 2023年2期
黄鹤鸣
(中国直升机设计研究所,江西 景德镇 333001)
0 引言
直升机机电系统结构复杂,因而其产品可靠性差、使用寿命短。其中发电机是机电系统中故障率较高的关键设备,发电机的运行状态直接影响直升机的飞行安全。机电系统可靠性提升方法研究面临的一大挑战是如何检测双馈发电机的运行状态并进一步诊断双馈发电机的故障。通常,早发的部件松动等不健康状态会逐渐造成双馈发电机的故障,从而导致机电系统的运行和维护成本增加[1-3]。检测和诊断双馈发电机的健康状态有助于运行维护人员及时做出决策,以保持直升机发电的可靠性和可用性。
在20年的双馈发电机设计寿命中不可避免地会出现组件故障或运行不正常的情况[4-5]。为了保证双馈发电机的安全运行,需要对双馈发电机进行两种类型的维护,即基于时间的维护(Time-Based Maintenance, TBM)和基于状态的维护(Condition-Based Maintenance, CBM)[6]。与TBM相比,CBM在某些情况下成本更低。状态检测在CBM中扮演着最重要的角色,例如故障诊断和不健康状态检测,因此本文旨在研究异常状态检测系统的开发。传统的状态检测方法主要分为两类:基于模型的方法和基于数据的方法。基于模型的方法依托实际的物理模型,主要是对从各个双馈发电机子系统收集的振动信号进行频谱分析[7]。这类方法在诊断不同子系统[8-9]中的机械故障方面具有优势,例如变速箱和轴承,发电机,电力电子设备,转子等。为了检测特定故障,通常使用信号变换,例如傅里叶变换,希尔伯特-黄(Hilbert-Huang)变换,小波变换等[10-16]。这些方法在实时故障诊断中也很有效,但是在分析具有复杂动态响应的组件或系统时会受到一定限制。而基于各种非线性算法的数据驱动方法可以克服这一不足。另一方面,由于双馈发电机的健康状况涉及多个因素,例如环境,电力系统,负载,双馈发电机组件,因此在状态监测(Condition Monitoring, CM)和健康监测(Health Monitoring, HM)中数据驱动方法比信号处理分析方法更有效[17]。例如,在文献[18]中使用了分层神经网络结构来诊断轴承状态;在文献[19],[20]中讨论了几种数据驱动模型用以检测旋翼和齿轮箱中的故障状态;在文献[21]- [23]中,许多其他先进的方法也用于故障诊断和状态检测。但是,在CM中应注意一个限制数据驱动模型准确性的问题,即不均衡数据问题。众所周知,不均衡数据始终是分类中的重点话题,而双馈发电机状态的检测则由数据驱动模型中的分类器来实现。尤其是在健康和不健康状态检测中,有大量健康数据和一些处于不健康状态的数据。为了有效地区分不健康数据中的不同故障,不均衡数据问题始终是数据驱动建模过程中需要解决的主要障碍。
基于以上概述的问题,本文提出了一种数据驱动方法和组合方案,以检测双馈发电机的异常运行状态。该方法设计了一个两阶段的数据驱动模型。在第一阶段,提出利用支持向量数据描述(SVDD)来区分健康数据和不健康数据。由于SVDD是单分类方法[24],在将异常数据与正常数据分开方面具备优势,因此可用于从大量健康数据中提取双馈发电机的不健康数据。在第二阶段,提出使用极限学习机(ELM)对不同的不健康状态进行分类,区分出那些通常会导致双馈发电机停止工作的非运行状态。由于这些非运行状态会导致双馈发电机降低或停止输出功率,所以提前进行检测可以帮助制定最佳的电能分配计划并确保供电的稳定性。因此,检测双馈发电机的非运行状态是本文的主要目标。ELM是一种简单的免调谐算法,具有良好的泛化性能和极高的学习速度[25],因此广泛用于故障诊断和分类问题,例如在机械组件、液压管测试仪、串联补偿、传输线中的应用等[26-27]。在案例分析时,采用了工业数据来检测双馈发电机的不健康状态。对六个模型的检测结果进行对比,验证了所提出的模型是可行的,并且在检测双馈发电机异常运行状态方面优于其他模型。
1 所提方法框架和数据处理
预先检测不健康状态,尤其是非运行状态,有助于防止双馈发电机异常运行。因此,本文提出了一种数据驱动的方法来检测不同类型的非运行状态,并指导制定合适的检修和能量调控决策。
1.1 所提方法框架
通常,机械设备的CM和HM的实现需要基于对从双馈发电机收集的时间序列数据进行模式识别。检测双馈发电机的非运行状态涉及五个因素(环境因素,电力系统因素,制造商因素,异常停机和设备因素),所以其复杂度很高。为此,本文提出了一种针对HM的数据驱动方法,并分两个阶段应用两种数据挖掘算法来实现有效的双馈发电机异常运行状态检测。该方法的框架如图1所示。
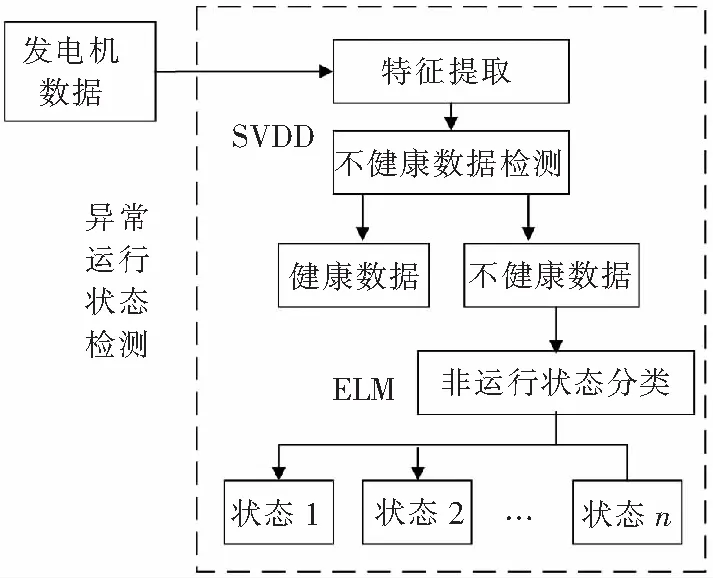
图1 两阶段双馈发电机异常运行状态检测方法框架
如图1所示,该方法首先从传感器(包含环境传感器和双馈发电机内部传感器)中获得双馈发电机运行数据。这些数据包含大量参数,因此必须选取包含必要模式的特征以构建有效的模型。其次,不健康数据与健康数据不均衡,这给不健康状态的分类带来了巨大挑战。SVDD是一种旨在处理单分类问题的分类算法[28],用以分离不健康数据。由于不健康数据通常涉及多种非运行状态,因此提取特定非运行状态的数据以构成均衡数据集。然后,基于此均衡数据集,通过ELM[29]构建有效的分类器以检测双馈发电机异常运行状态。通过这种两阶段数据驱动模型,可以检测出不健康数据和特定的非运行状态。它们可以作为双馈发电机控制策略和维护计划的重要决策指南。
根据前文对所提方法的描述,可以将本文创新性归纳为以下三个方面:
1)针对不健康状态进行预先检测,而不是进行故障诊断,有利于事前预警,降低维护成本。由于这种应用环境涉及分类和预测,因此构建了数据驱动模型来检测双馈发电机异常运行状态,而不是通过对振动信号进行频谱分析来检测双馈发电机故障。数据驱动模型的优点是可以从数据中找出异常运行状态信息,尤其是在双馈发电机仍处于非运行状态的预警期且振动信号频率变化不明显的情况下。
2)提出了一个两阶段模型来解决双馈发电机异常运行状态检测问题。该模型分步实现了不健康数据检测和非运行状态检测。以此方式,如果在第一阶段下以健康状态测试数据,则不需要对非运行状态进行分类计算。同样,只有在检测到不健康数据时,才会激活第二阶段。
3)提出利用SVDD处理不均衡数据问题,并通过ELM建立有效的分类器。SVDD是一种单分类算法,因此适合分离不均衡数据,即不健康数据和健康数据。ELM具有较快的学习速度和良好的泛化能力,可以构建一个有效的分类器来检测由不同因素引起的双馈发电机非运行状态。
1.2 特征选择
为了构建有效的数据驱动模型,数据预处理是必要的。双馈发电机的CM和HM数据非常庞大,有必要在建模中选择最重要的参数并降低特征空间的维度。本文提出了三个用于特征选择的指标,即基尼系数、信息值和Cramer’sV[30]。
1)基尼系数(Gini Index,GI)
在特征选择中,GI通常用于在决策树中拆分变量[31]。 基于GI的分类树避免了在标准不纯度测量时的特征选择偏差,因此可以实现较高的分类精度。对测量特征的不纯度进行分类,重要特征将具有较小的不纯度。如果使用具体数值来衡量各参数的分类能力,则基础二分类问题的最大值为0.5。因此可以看出,具有较小GI值的参数更相关。
假设S是具有k个类别 {Li,i=1, 2,…,k} 的测试数据集,则根据分类,将属于类别Li的样本分组为子集Si。假设si是子集Si中的样本,则集合S的基尼系数定义为公式(1)。

(1)
式中,pi是子集Si的概率,由si/s估计;GI的最小值为0,这意味着集合S中的所有样本都属于同一类,并且获得了最大的有用信息。当所有样本均等地分配给各个类别时,GI的值最大,这意味着获得的有用信息最少。
2)信息值(Information Value,IV)
信息值(IV)统计量是一种流行的度量标准,用于在特征选择中筛选重要参数。假设参数x及其二进制目标y,IV的计算如公式(2)所示。
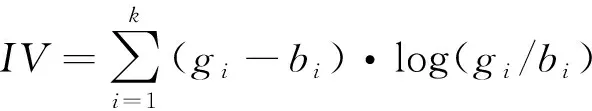
(2)
式中,k是x中的分区级别数,应在[2,20]内适当设置。在计算过程中,必须先对连续参数进行初步分箱,首个分箱不包含零单元格,第k个分箱表示为Xk。gi和bi分别代表对应x∈X的“好”和“坏”的百分比。通常,log(gi/bi) 表示g和b的分布之间的偏差,而(gi-bi) 表示偏差的重要度。
3)Cramer’sV
Cramer’sV是基于卡方检验的特征选择指标,是在维度大于2×2的表中关联度的度量。相关性的强度由Cramer’sV计算得出,其返回值在 0和1。较强的关联被认为Cramer’sV值更接近1。因此,它在预测相关性和统计独立性之间具有很好的区分能力。Cramer’sV的计算公式如公式(3)所示。

(3)
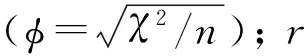
τ=min(r-1,c-1)
(4)
当Cramer’sV的值为0时,参数之间不存在相关性。仅当两个参数的边距相等时,其值才达到1。考虑到直接比较具有不同维度的表很困难,Cramer’sV通过使用维度信息进行关联度量来纠正此问题。然后可以比较任意两个交叉分类表之间的关联强度。Cramer’sV值较大的表格被认为具有很强的相关参数。反之,较小的值表示弱相关的参数。
从上面的描述可以看出,所有这些指标都考虑了数据的模式,因此它们的值可以合理地反映变量对模式识别的影响。
2 利用数据驱动模型检测双馈发电机异常运行状态
从图1中可以看出,所提方法主要包含两个阶段,以实现对双馈发电机状态的检测。第一阶段是分离健康数据和不健康数据;第二阶段是对不同的不健康状态进行分类,即双馈发电机的各种非运行状态。
2.1 利用SVDD检测不健康数据
在第一阶段,利用SVDD将不健康数据与大量健康数据分开。SVDD是从支持向量机(SVM)理论[24]发展而来的单分类算法。首先将原始数据映射到一个高维超球体中,该球体用于描述数据点的空间分布。预期大多数数据点或整个数据集位于超球体内部,而少数奇异点则位于超球体外部(如图2所示)。由于此属性,它可以有效地用于离群值检测。在双馈发电机的CM中,不健康的数据很少,因为大多数数据点都是在正常运行状态下测量的。同时包含健康和不健康数据的双馈发电机数据是典型的不均衡数据集,这会给有效分类带来困难。SVDD适用于提取不健康数据以构成均衡数据集,从而避免非运行状态分类时的数据淹没问题。

图2 SVDD原理图
1)SVDD算法
假设数据序列为{x1,x2,… ,xN},xi∈Rn,N是训练样本的数量,n是特征选择后特征空间的维数。SVDD的目标是最大程度地减少包含一个类别的所有数据点的超球的体积,因此目标函数定义如下:
minr2

(5)
式中,r和c分别代表超球体的半径和中心。 通常,引入松弛变量ξ和惩罚因子C以增加对奇异点的容忍度,然后将目标函数重新定义如下:
i=1,2,…,N;ξi≥0;
(6)
式中,ξi允许对一些训练样本进行错误分类,例如不健康数据;C表示数据量和误差之间的权衡。考虑到原始数据点的分布不是超球面,使用非线性变换将原始数据映射到更高维的特征空间,如下所示:
Φ:Rn→H
(7)
式中,Rn代表原始空间;H代表高维空间;Φ是通常被选作核函数的非线性变换。引入核函数和拉格朗日乘数后,上述目标函数的对偶公式如下:

(8)
式中,α是拉格朗日乘数,K(x,y) 表示核函数。根据Karush-Kuhn-Tucker(KKT)条件[32],从上述对偶公式获得了公式(9)中的三种情况:
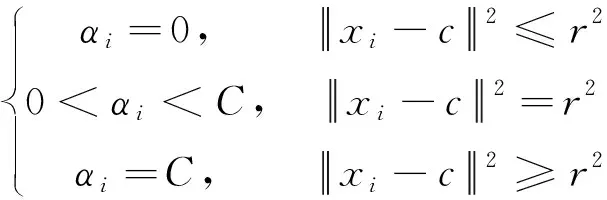
(9)
由于仅需要具有非零αi的样本,因此将它们称为支持向量。使用选定的支持向量,超球体的半径r0计算如下:
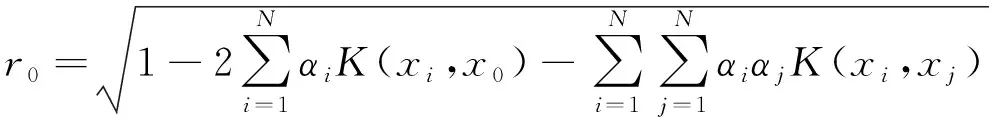
(10)
式中,x0是选定的支持向量。类似地,任何测试数据点xt与超球面中心c之间的距离rt也可以根据公式(10)计算。如果rt>r0,则意味着xt在超球面之外,xt被检测为不健康数据。
2)SVDD参数优化
根据以上SVDD算法的描述,需要核函数来描述超球体。然而,对于具有核函数的非线性变换,存在一些不确定的参数(例如,所选核函数的参数和惩罚因子C)影响其性能。在建模中选择最佳参数有助于实现不健康数据检测的高精度。在许多参考资料中,基于粒子群优化(Particle Swarm Optimization,PSO)算法的框架都用于支持向量机(Support Vector Machine,SVM)的参数选择。考虑到SVDD和SVM都基于结构风险最小(Structural Risk Minimum,SRM)准则,本文采用PSO优化SVDD参数。
PSO是一种进化计算方法,通过信息的社会共享来开发该模型,以构建基于种群的搜索技术,该技术最初是基于鸟群模拟[33]。PSO中的个体称为粒子,它们在超维空间中飞行,并且所有粒子组成了一个群。粒子的位置变化基于每个个体模仿其他个体的社会心理趋势。变化后每个粒子的位置取决于对经验、知识及其邻居的考虑。因此可以看出,对这种社会搜索行为进行建模需要考虑群体中的其他粒子,并且搜索过程的最终结果是粒子随机返回搜索空间中以前成功的区域。
在PSO算法中,有大量的粒子,每个粒子代表一个可能的解决方案。每个粒子都在位置变化时保持其坐标的轨迹,并且还跟踪了群中的最佳坐标。这些坐标的解分别称为每个粒子的最佳适应度和全局适应度。在优化的迭代中,每个粒子都会改变其速度,并朝其最佳适应度和全局适应度位置移动。生成独立的随机项并对其加权,以朝着这两个位置加速。更新第i个粒子的速度和位置的公式如下:
vi(t+1)=λ[vi(t)+c1rand1(pbesti-pi(t))+
c2rand2(gbest-xi(t))]
(11)
pi(t+1)=pi(t)+vi(t+1)
(12)
φ=c1+c2,φ>4
(13)
式中,pi= [pi1,pi2,… ,pin]T和vi= [vi1,vi2,… ,vin]T分别是第i个粒子在n维搜索空间中的位置和速度;pbesti是第i个粒子的最佳位置;gbest是所有粒子中的最佳位置;λ是收缩因子;t是迭代步骤;c1和c2是两个正的常数;r1和r2是在[0,1]内通过均匀概率分布生成的两个随机数。
2.2 利用ELM对异常运行状态进行分类
不健康的数据通常包含由不同不确定因素引起的各种双馈发电机非运行状态。为了根据特定状态有针对性地制定双馈发电机的能量调控策略和运维计划,在异常状态检测中需要对非运行状态进行分类。在本文中,提出用ELM来对双馈发电机的异常运行状态进行分类和检测。
1)基础ELM算法
ELM是一种高级的单隐层前馈神经网络(Single-hidden-Layer Feedforward Neural Networks,SLFN)[25]。ELM由于不需要调整隐层神经元,因此学习速度很快,可广泛用于分类和回归。ELM旨在获得最小的训练误差和最小的输出权重范数,其基本结构如图3所示。

图3 ELM的结构图
根据图3的描述,ELM算法由三层组成:输入层、隐层和输出层。假设训练集为(xi,yi),则输入xi∈Rn,输出yi∈Rm。单个输出节点的输出可以如下计算:
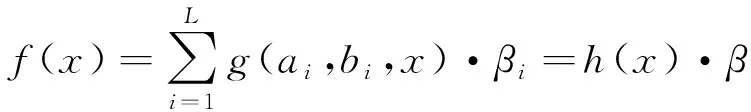
(14)
式中,L是隐层节点的数量;g(ai,bi,x)是激励函数;βi是第i个隐层节点连接到输出节点的权重;对于L个隐层节点,隐层输出h(x) = [g(a1,b1,x),…,g(aL,bL,x)],β= [β1,β2,… ,βL]T。g(*) 中的两个参数分别是隐层与输入层之间的权重向量a和隐层神经元偏差b。
假设N个样本的模型输出与期望目标之间的误差为零,则ELM可以表示为矩阵格式:
Hβ=T
(15)

(16)
式中,H是由g(a,b,x) 组成的激励函数矩阵;T是表示为[y1,y2,… ,yn]T的目标矩阵。
在获得上述模型后,我们可以通过以下步骤获得最终的ELM模型:
步骤1:随机分配隐层节点参数a和b;
步骤2:通过式(16)计算隐层输出矩阵H;
步骤3:基于式(15),可以计算输出权重β为β=H+T,其中H+是H的Moore-Penrose广义逆。
2)用于分类的ELM算法
假设对二分类问题进行建模,则m=1且y∈[0,1]。然后将式(14)中的ELM输出函数重写如下:
f(x)=sign(h(x)·β)
(17)
为了获得良好的ELM泛化性能,需要小的训练误差和权重范数。因此,可以将使训练误差最小化的目标函数描述如下:

(18)

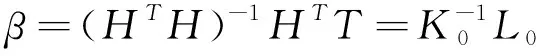
(19)
其中,K0=HTH,L0=HTT。如果H是一个奇异矩阵,则添加一个常数对角线矩阵以使其非奇异,因为K0=HTH+λI,其中λ是一个很小的常数。
对于多分类问题(m≥2),输出yi表示为yi=[yi,1,yi,2,…,yi,m]。因此,目标矩阵T的维数为N×m,表示为TN×m=[T1,T2,…,Tm]。类似地,权重矩阵β被扩展为βL×m=[β1,β2,……,βm]。式(18)中的目标函数可以如下详细表示:

(20)
根据以上描述可以看出,多分类ELM模型与多分类中的“一对全”(One-vs-All,OVA)方法[34]相似,它们都由多个ELM二分类器组成。同时,ELM在式(20)目标函数的构建中考虑了聚合策略。
2.3 评估指标
根据以上描述,不健康数据检测和非运行状态检测都涉及分类。因此,为了评估所提方法的性能,提出了混淆矩阵(表1)进行量化35]。

表1 混淆矩阵
表1给出了混淆矩阵中相关事件的定义。TP(True Positive)代表真阳性事件;FN(False Negative)代表假阴性事件;FP(False Positive)代表假阳性事件;TN(True Negative)代表真阴性事件;NN代表所有事件。基于这些事件,定义了一系列指标,例如,查全率Recall(R),查准率Precision(P),准确率Accuracy(Acc),误差率Error(Err),F度量等。通常将前四个指标作为分类的评价指标,其定义如下:

(21)
式中,card(*)是计数函数;R描述了在所有观察到的阳性事件中真阳性事件的百分比;P描述了所有预测的阳性事件中真阳性事件的百分比;Acc描述了所有事件中真事件的百分比。因此,在具有良好性能的系统中,要求这三个指标的值较大,而代表预测误差的Err值则应较小。
从以上定义可以看出,这四个指标是根据通用二分类定义的。为了评估检测多个双馈发电机非运行状态的性能,仍然采用OVA方法的思想作为标准,即在每个评估中将一个测试类别设置为阳性类别,将其他类别设置为阴性类别。通过这种方式,可以计算出每个双馈发电机状态的四个指标。
3 算例分析
为了检测双馈发电机的异常运行状态,本文以双馈发电机工业数据为研究案例。数据集中总共有52,560个样本,采样间隔为10 min。我们将数据集的70%作为训练集,其余作为测试集。
3.1 特征选取
原始的数据集巨大,总共有235个参数。这些参数主要分为五类:计数器数据,电力系统数据(例如电压、电流、频率等),环境数据,双馈发电机状态数据(例如部件压力、警报代码、位置数据)和温度数据。可以看出,某些参数与CM和HM无关,如计数器数据。因此,特征选择在数据预处理中对于降低维度是必要的,并且对于确定最重要的建模参数也很有用。本文将公式(1)、公式(3)中的三个指标用于特征选择,并以区分健康数据和不健康数据的模式作为HM所需的参考标准。表2列出了不同变量上的三个指标值。
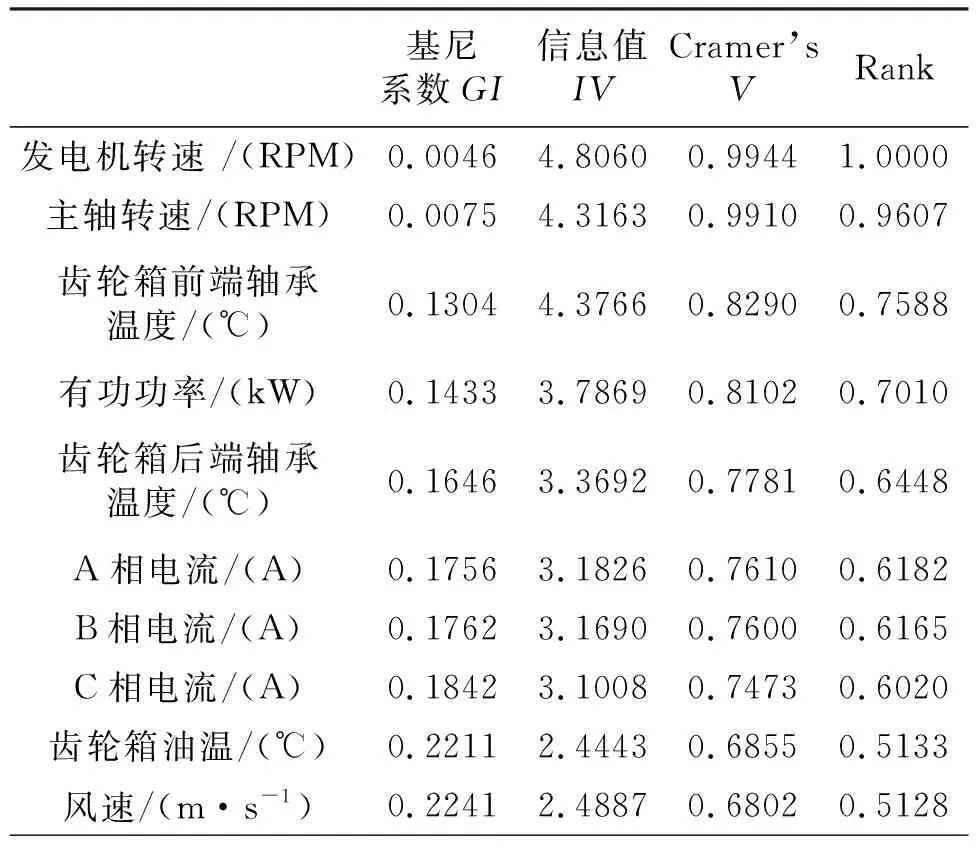
表2 特征选取中的三个指标值
表2展示了10个最重要参数的三个特征指标值。可以看出,不同类型的参数对检测不健康数据和检测非运行状态有影响。例如,发电机转速和转子转速代表与双馈发电机制造商有关的因素;风速是环境因素;A、B、C三相的有功功率和电流是影响不健康状态的电网因素;齿轮箱轴承和齿轮箱油的温度是与双馈发电机的运行状态有关的因素。
为了在建模中进一步选择必要的参数,我们需要对这些参数的重要性进行排序。根据本文第1节,如果参数相关且重要,则其GI值将在[0,0.5]之间,而IV和CramerV的值将在[0,1]之间。但不难理解的是,参数不能始终获得三个指标的最佳值。因此,我们给出了考虑这三个指标的公式,以综合评估参数的重要性,如下所示:
RImportance=(exp(-α·GI)+IV/Nb+
Cramer’sV)/3
(22)
式中,RImportance是综合指标;α是不确定的参数,此处可以设置为5;Nb是计算IV时的分箱数,设置为5。
参数重要性等级Rank可以通过RImportance的值与RImportance的最大值之比来计算,计算结果如表2所示。基于这些度量的前十个最重要的参数被计算出来如图4所示。

图4 特征选取
图4展示了三个指标的值,并按重要性对给定的10个参数进行了排名。可以看出,这10个参数的重要性等级大于0.5。如果在特征选择中将等级阈值设置为0.5,则可以从235个双馈发电机参数中选择表2中的前8个参数,这对于检测双馈发电机的不健康状态非常有用。
3.2 不健康数据检测
以8个最重要的参数为输入,SVDD算法首先用于从双馈发电机的所有运行数据中检测不健康数据。如本文第1节中的描述,输入数据被映射到更高维度的空间中以描述其非线性特征。映射函数考虑使用高斯核函数,其定义如式(23)所示:

(23)
式中,x和y代表两个变量;σ是核函数参数。
包括公式(8)中的惩罚因子C在内,共有两个不确定的参数会影响SVDD模型的性能。假设这两个参数组成矢量V=[C,σ],则应用PSO算法优化这些参数。根据对PSO的描述,选择粒子群中每个粒子的位置作为对这两个参数值进行编码的向量V。由于第一阶段的目标是将健康和不健康的数据分开,因此可以基于区分健康和不健康的数据的模式将适应度函数[36]设置为SVDD的分类精度。具有高分类精度的颗粒将产生高适应度值。将粒子总数设置为20,将最大迭代次数选择为200,并将迭代终止条件设置为误差达到10-3。使用PSO算法优化SVDD参数的步骤如下:
步骤1:(初始化)随机生成Np=20个初始粒子及其位置pi,i=1,2,…,Np。
步骤2:(适应度)计算粒子群中每个粒子的适应度。
步骤3:(更新)基于公式(11)、公式(13),计算每个粒子的速度vi。
步骤4:(构建)对于每个粒子,移动到新位置并计算新适应度。
步骤5:(终止)如果满足给定的终止条件,则停止;如果不是,则返回步骤2。当迭代达到给定的最大迭代次数时,也会停止迭代。
图5展示了PSO的迭代过程以及优化SVDD参数的适应度结果。根据图5的结果,将最佳参数设定为V=[C,σ]=[0.7726,0.01]。然后,构建具有选定最佳参数的SVDD模型以检测不健康的数据。不健康数据检测的结果如图6所示。
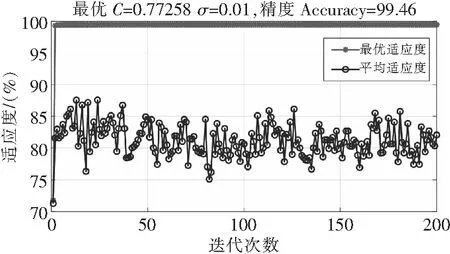
图5 SVDD参数优化结果

图6 训练集中的不健康数据检测
图6展示了训练集2,000个数据点的检测结果。图中的红实线表示SVDD模型中超球体的半径;y轴表示每个数据点到超球体中心的距离。位于红线下方和上方的数据点分别是健康数据和不健康数据。可以看出,健康数据和不健康数据被SVDD分开,并且数据明显是不均衡的(含有大量的健康数据和少数不健康数据),验证了在对双馈发电机的非运行状态进行分类之前检测不健康数据的必要性。
3.3 非运行状态检测
本文中的不健康数据几乎都是从双馈发电机非运行状态收集的数据。这些非运行状态背后的原因主要可以从警报代码中反映出来。因此,为了保持电力系统功率平衡,应诊断出不同的非运行状态从而进行控制和调节。根据SVDD的结果,在图6中可以区分出不健康数据和健康数据,但是由不同因素引起的非运行状态并没有明显分开,如图7所示。
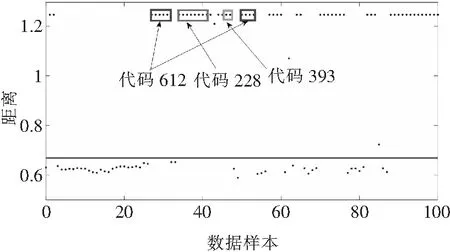
图7 不健康数据中的各种非运行状态
在图7中,我们选择了100个数据点,并通过警报代码标记了一些典型的非运行状态。可以看出,图中的数据没有区分出三种警报代码所表示的非运行状态。其中,代码228反映了由于过速而将双馈发电机切断以进行保护;代码393反映了双馈发电机由于策略性空气控制(Tactical Air Control,TAC84)振动保护模块检测到异常振动而停止工作;代码612反映出由于发电能力过剩或发电削减,双馈发电机被远程控制而降额运行或停机。因此,为了检测特定的非运行状态从而有针对性地做出决策,需要建立一个分类模型。
本文利用ELM算法建立分类器模型。考虑到整个数据集中存在多种报警代码,为方便起见,在建模中仅选择两个通用代码(代码393和612)以及部分健康数据组成一个均衡数据集。因此,本文中训练好的模型仅用于检测给定的两个非运行状态。基于构造的ELM分类器,表3给出了算法对不同的非运行状态进行分类的性能。

表3 ELM在训练数据上的分类性能
表3列出了SVDD检测完不健康数据之后,在均衡数据集上ELM对不健康状态进行分类的性能。性能由公式(20)中的四个指标的值反映。从超过0.97的R,P,Acc值可以看出,ELM在检测不同的非运行状态方面表现出了出色的性能。三种状态(健康状态、代码393和代码612)的分类结果如图8所示。考虑到输入空间是高维的,因此图8选择两个参数以方便展示,展示了三种状态的分布。

图8 健康数据、代码612和代码393三种状态的分类结果
3.4 仿真结果分析
为了分析所提出的方法在检测双馈发电机非运行状态时的性能,将该方法与众多参考文献中提出的模型进行了比较。例如,在故障诊断中使用主成分分析(PCA)方法来减小特征维度[37]。支持向量机(SVM)则是一种有用的分类算法,已广泛应用于状态检测和故障诊断[38]。因此,本文选用PCA和SVM分别与SVDD和ELM进行比较。在测试过程中,测试数据也由提出的两阶段模型进行处理,并且仅讨论与三个给定状态关联的数据以进行性能评估。
首先,我们比较状态检测中SVM和ELM的性能。当直接使用不均衡数据作为输入时,无需SVDD检测,因此可以构造两个分类器来检测不同的非运行状态。表4和表5中展示了三种状态(健康数据、代码393和代码612)的四个性能指标。

表4 SVM在异常状态检测上的性能

表5 ELM在异常状态检测上的性能
从表4和表5可以看出,当SVDD未检测到不健康数据时,除了代码393上的R值,ELM的分类性能要优于SVM。
其次,为了比较所提出的方法中的SVDD的性能,构建了四个模型(PCA-SVM,PCA-ELM,SVDD-SVM,SVDD-ELM)。表6显示了各种模型检测非运行状态的性能。表中黑体加粗的数据表示最佳的检测性能。
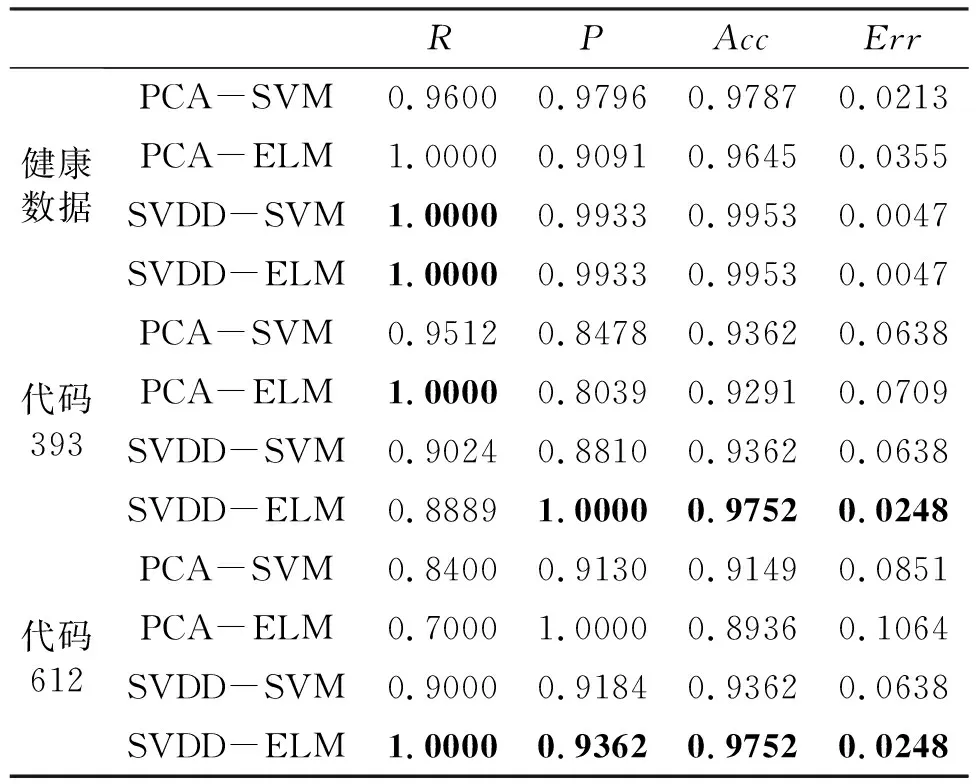
表6 异常状态检测性能
为了进一步分析所提方法检测双馈发电机中非运行状态的性能,研究了具有更多状态的新情况。该数据集来自另一台双馈发电机。考虑了两个额外的非运行状态,例如反映未扭转警报的代码205和代表高转速警报的代码228。然后,根据所提方法实施相同的检测过程。四个评价指标的结果如表7所示。表中黑体加粗的数据表示最佳的检测性能。

表7 新算例的异常状态检测性能
对比表6和表7的结果,可以得出以下几点结论:
1)通过检测不健康的数据来处理不均衡数据问题,提高了对健康数据和非运行状态进行分类的准确性,指标P上的少数情况除外。
2)通过在建模中比较ELM和SVM的性能,可以看出ELM作为分类器在非运行状态分类中的性能优于SVM。
3)通过对这两张表的综合分析,可以看出使用SVDD检测不健康数据有利于状态检测,并且ELM算法可以在检测不同的非运行状态时取得良好的性能。
4)这些算例成功验证了基于两阶段数据驱动模型(SVDD-ELM)的双馈发电机异常运行状态检测方法的有效性,并且可以同时检测不健康数据和双馈发电机的非运行状态。
4 结论
为了降低双馈发电机的维护成本,保证双馈发电机的运行,本文提出了基于数据驱动的SVDD和ELM方法来检测双馈发电机的异常运行状态。首先,从235个双馈发电机参数中选择十个最重要的参数,以减小建模的维度。其次,构建由PSO优化参数的SVDD模型。该模型可在检测特定的非运行状态之前实现对不健康数据的检测。第三,通过将健康状态数据和四个特定的非运行状态数据组成均衡数据集,可以构建有效的ELM分类器。最后与结合了SVM,ELM,PCA和SVDD的六个模型进行比较,工业数据的案例研究验证了该方法的优越性。因此,使用该方法来检测双馈发电机的不正常状态是可行的,同时该方法的结果将为预先制定合理的故障控制策略和维护计划提供指导。虽然这里仅讨论了四种特定的非运行状态,本文的结果在实际的工业应用中受到一定限制,但可以肯定的是,未来可以针对实际应用环境,将所提方法扩展到检测双馈发电机的更多非运行状态中。
猜你喜欢
大电机技术(2022年3期)2022-08-06
防爆电机(2021年6期)2022-01-17
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
大电机技术(2017年3期)2017-06-05
军事文摘(2016年16期)2016-09-13
智能建筑电气技术(2015年5期)2015-12-10
电测与仪表(2015年16期)2015-04-12
