
基于指数平方损失的纵向多折点回归模型的稳健估计与统计推断①
2023-06-25 05:16唐铭李婷婷
西南师范大学学报(自然科学版) 2023年6期
唐铭, 李婷婷
西南大学 数学与统计学院,重庆 400715
折点回归模型主要研究响应变量与协变量间的分阶段连续变化特征, 在金融、 经济、 工业、 医学等领域有着重要应用. 文献[1]首次提出单折点回归模型, 并基于似然函数提出折点参数估计的网格搜索法. 文献[2]基于累积和统计量及似然比统计量提出折点效应的假设检验方法. 值得一提的是, 文献[1]所提的网格搜索法虽然可以生成合理的估计, 但计算成本却很高. 文献[3]基于泰勒展开提出了一种局部线性平滑的参数估计方法, 在保证估计准确性的同时极大提高计算效率. 文献[4]首次将单折点回归模型拓展到多折点回归模型, 基于局部线性平滑法提出了分位数损失函数下的参数估计、 变点存在性检验统计量, 及折点个数确定的贝叶斯信息准则, 并研究了所提估计及统计量的大样本性质.
以上文献的研究大多讨论的是独立同分布数据的折点模型. 然而, 随着应用领域的不断拓展, 所处理的数据类型越来越复杂, 纵向数据便是复杂的数据类型之一. 针对纵向折点回归模型, 文献[5]在独立工作矩阵下考虑了纵向单折点分位数回归模型的估计与检验; 文献[6]考虑了纵向数据的多折点分位数回归模型. 为融合纵向数据同一个个体内部的相关性, 文献[6]基于文献[7]提出的二次推断函数方法(quadratic inference function, QIF)研究了相关结构下纵向多折点分位数回归模型的估计与统计推断, 但其所能刻画的仍是等相关和AR(1)等特殊结构的矩阵. 文献[8]提出修正的Cholesky分解方法, 该方法不局限于特殊相关结构, 且能保证估计的协方差阵的正定性, 具有更广泛的适用性.
众所周知, 基于经典平方损失的估计对异常值非常敏感. 为处理包含大量异常值的数据, 众多稳健估计的方法被相继提出, 如Huber损失函数法[9]、 秩回归[10]及分位数回归方法[11]等. 文献[12]提出一种新的稳健估计方法, 即基于指数平方损失函数的参数估计方法. 该方法的显著特征是引入一个额外的调谐参数, 可通过选择合适的调谐参数实现模型参数的自适应稳健估计. 文献[13-15]关于指数平方损失函数的相关研究均表明, 基于该损失的参数估计相对于经典的稳健方法有着更好的表现, 能够获得更好的鲁棒性和有效性.
本文基于指数平方损失和修正的Cholesky分解方法研究纵向多折点回归模型的参数估计及统计推断.
1 模型与估计算法
1.1 纵向多折点回归模型
考虑折点个数K及折点位置τ=(τ1, …,τK)T均未知的纵向多折点回归模型:
(1)
其中:n为个体数,mi为第i个个体的重复观测次数, (a)+=a·I(a≥0),I为示性函数,Yij为响应变量观测值,Zij为p维协变量观测值,Xij为有界门限变量,eij为随机误差, 记ei=(ei1, …,eimi)T. 由模型(1)可知, 变量Xij的回归系数在折点τ=(τ1, …,τK)T处会发生变化. 记b=(b1, …,bK)T, ϑ= (a0,a1,bT,βT)T, 以及参数向量θ= (ϑT,τT)T, 其中ϑ∈G⊂R2+K+p,τ∈T⊂DK.G,T均为紧集,D为Xij的支撑集. 下面, 首先对假设折点个数K已知后的参数估计算法进行介绍, 随后给出用于确定折点个数K的模型选择方法.
1.2 基于指数平方损失的纵向多折点回归模型的参数估计算法

(2)
进而有如下的近似回归模型
(3)

(4)

(5)
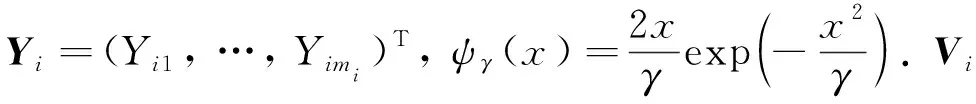
(6)
其中Φi是主对角线元素全为1的下三角矩阵, 第(j,k)个元素是如下自回归方程系数φijk,γ的相反数


(7)

(8)
其中

本文使用Newton-Raphson迭代算法求解方程组(8)以保证估计的精度. 下面给出在指定调谐参数γ下, 基于指数平方损失的纵向多折点回归模型的参数估计算法:
步骤1给定初始折点位置τ(0), 计算模型(3)的普通最小二乘估计作为η的初始值η(0).
步骤2基于τ(s)及η(s), 应用修正的Cholesky分解法估计协方差阵Vi, 使用Newton-Raphson算法迭代求解方程组(8)获得η(s+1), 具体步骤如下:

步骤2.2.3根据(6)式及(7)式, 可得Vi, r+1. 通过下式迭代至收敛得到η(s+1, r+1):

步骤2.3重复步骤2.2直至参数收敛, 可得η(s+1).
步骤3更新折点位置τ(s+1). 通过
(9)
步骤4重复步骤2-步骤3直至参数收敛.
注1当Vi为单位阵时, 方程(5)和最小化目标函数(4)的解等价. 因此, 在上述步骤中省略步骤2.2.1及步骤2.2.2, 设置步骤2.2.3中Vi, r+1为单位阵, 即可获得独立工作矩阵情况的参数估计.
1.3 最佳调谐参数γopt的选择
1.4 折点个数K的确定
1.2节给出了当折点个数给定的时候模型参数的估计算法. 然而实际问题中, 折点个数真值K0通常是未知的. 参考文献[4], 提出如下基于指数平方损失的贝叶斯准则以确定折点个数:
(10)

2 大样本性质
(11)

给出如下条件:
(ⅰ) E(ψγ(eij))=0, E(ψ′γ(eij))>0, 且对于任意γ>0, E(ψγ(eij)2)有界.
(ⅱ) 折点的真值K0及协变量Zij的维数p是固定的, 个体的观测次数mi一致有界, 且个体数n趋于无穷.


(ⅵ) 参数空间Θ∈R2+p+2K是紧集, 参数真值η0是参数空间Θ的内点,Sn(η)在η0处唯一取得全局最小值.



(12)
其中
(13)
(14)
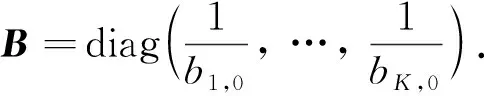
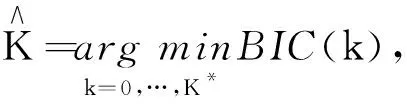
3 折点的存在性检验
对于多折点回归模型的折点存在性检验, 文献[4]基于无折点的原假设H0:bk=0,k=1, …,K提出CUSUM(cumulative summation)型统计量. 本文沿用文献[4]所提方法, 提出基于指数平方损失的纵向折点回归模型的折点存在性检验方法, 具体步骤如下:
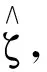

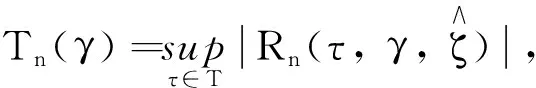


步骤4重复步骤3L次, 计算


4 模拟研究
根据如下模型生成数据
(15)


情形2 考虑门限变量不为时间, 且数据存在异常值的情况. 设置Xij~U(-5, 5),tij={1, 2, …, 10}, 随后每个观测以20%的概率缺失以生成不平衡数据.ei服从自由度为3, 协方差阵为情形1中Σi的多元t分布, 随后随机选取10%的eij服从标准柯西分布.

每种情形均考虑3种折线效应, 对于情形1, 设定: ①K=1,τ=7, ϑ=(-2, 1, -3, 1)T; ②K=2,τ=(5, 7)T, ϑ=(2, 1, -4, 5, 1)T; ③K=3,τ=(2, 5, 7)T, ϑ=(0 , 1 , -3 , 2 , -6 , 1)T. 对于情形2、 3, 系数ϑ设置与情形1相同, 折点个数和位置设置为: ①K=1,τ=-1; ②K=2,τ=(-1, 1)T; ③K=3,τ=(-4 , -1 , 4)T. 设定样本量n=400, 重复模拟次数为100次. 使用1.2节所提算法求解最小化目标函数(4)及方程组(8), 分别记为“ESL.IND”和“ESL.CHO”, 即独立工作矩阵结构及基于Cholesky分解的模型参数的估计方法.
4.1 最优调谐参数γopt的选择
表1给出3种情形下所有模拟中选择的最优参数γopt的均值. 可以看到, 无异常值的情形下,γopt均值较大; 情形2,3的γopt较小, 以降低异常值产生的影响. 这说明在指数平方损失函数中, 可以通过选择合适的调谐参数实现回归系数的自适应稳健估计.

表1 最优调谐参数γopt的均值
4.2 选择相合性及参数估计
表2给出了真实折点个数为2时, 不同Cn在3种情形下的折点个数的正确选择率. 可以看到, 所有情形下, 本文所提出的折点个数选择方法均具有较高的正确选择率, 并且“ESL.CHO”能够实现更高的选择正确率. 而且样本量不变时, 较大的Cn能略微提高正确选择折点数的概率.

表2 K=2, Cn=1, log(log n), log n, 2log n时的折点个数正确选择率
为说明所提方法优势, 与以下估计量进行比较:
1) 方程(5)的工作协方差矩阵Vi为等相关及AR(1)的特定结构, 利用文献[7]提出的QIF方法对(5)式进行求解, 同时分别考虑指数平方损失及经典的平方损失两种损失函数, 记所得估计量分别为“ESL.EXCH”“OLS.EXCH”“ESL.AR1”“OLS.AR1”;
2) 文献[4]提出的基于分位数回归的纵向多折点模型的估计量, 指定分位水平为0.5, 记为“MKQR”, 使用R程序包MultiKink实现;
3) 文献[3]提出的多折点模型的最小二乘估计量, 记为“SEG”, 使用R程序包segmented实现.
表3展示了情形2在K=2时的参数估计结果, 汇总了100次模拟中估计量的平均偏差、 标准差及均方误差. 其余情形的参数估计的结果已上传至Github(https: //github.com/Tangming-hub). 可以发现:

表3 情形2, K=2的模拟结果
1) 当残差向量服从正态分布时(情形1), 几种方法所得到的估计量的估计效果相近. 然而当数据中存在异常值时(情形2和情形3), 基于指数平方损失和分位数回归的估计量“ESL.IND”“ESL.CHO”“ESL.EXCH”“ESL.AR1”和“MKQR”均能提供回归参数的有效估计, 其中相对于分位数回归方法, 基于指数平方损失函数的估计量表现更佳, 而基于经典的平方损失函数的估计量的估计效果均较差;
2) 仅考虑指数平方损失函数的估计方法时, 相对于独立工作矩阵的估计量“ESL.IND”, 融合组内相关性的估计量“ESL.CHO”“ESL.EXCH”“ESL.AR1”均具有更优良的估计效果, 且本文所提出的“ESL.CHO”在各指标上表现最佳. 这说明有效考虑纵向数据个体重复观测有利于提高回归参数的估计效率. 综上, 本文所提出的估计方法, 可以为纵向多折点回归模型的参数提供更为稳健的、 有效的估计.
此外, 不同情形下K=2时, 3种估计方法“ESL.CHO”“ESL.IND”“MKQR”的标准差、 标准误、 95%的 Wald型置信区间的平均长度及经验覆盖率亦上传至Github. 由结果可见, 3种估计量的标准差与经验标准误差接近, 并且所构造的置信区间的经验覆盖率均在置信水平95%左右. 并且, 相对于“MKQR”方法, 本文所提方法的置信区间的长度更短.
4.3 折线效应存在性检验的功效性分析
为研究本文第3节所提出的折线效应存在性检验统计量Tn的有限样本性质, 考虑折点个数为2时检验统计量的功效. 对于情形1, 设置-b1=b2=0,0.1,0.2,0.3; 对于情形2和情形3, 设置-b1=b2=0,0.15,0.3,0.45, 其中当系数b1和b2都等于0时, 不存在折线效应. 设置L=300, 显著性水平α=0.05. 表4展示所得检验统计量均值(Mean ofTn, 简记为Mean-Tn)及经验p值(Power). 根据统计量的定义, 当原假设成立时, 统计量Tn应接近于0, 模拟结果与理论一致. 注意到, 当折线效应不存在时, 经验P值接近名义上的显著性水平0.05, 而随着折线效应增强, 检验功效增加, 并趋近于1, 这说明本文提出的检验统计量能够有效识别折线效应.

表4 K=2时各情形在不同折线效应下统计量Tn均值及检验功效的势
本文亦使用所提方法“ESL.IND”“ESL.CHO”分析文献[4]的纵向黄体酮数据, 参数的估计值、 平均绝对误差、 置信区间, 以及拟合曲线(结果见Github). 实证结果显示, 相较“SEG”“MKQR”方法, 所提估计具有明显竞争优势.
5 证明
为了证明定理1, 我们给出如下引理.

(16)
(16)式等价于

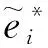
以及
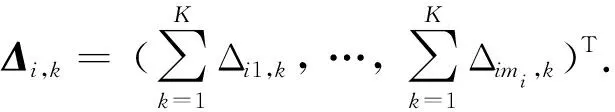



(17)


(18)
结合(17)式及(18)式,
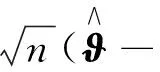
故而定理1可证.
定理2的证明记折点位置真值为τ0=(τ1, 0, …,τK,0)T. 由(9)式可得等式


经计算,

定理3得证.
6 总结
本文基于指数平方损失提出纵向多折点回归模型参数估计和统计推断方法. 为处理折点回归模型, 本文首先基于局部线性平滑方法将折点回归模型转化为普通的纵向线性模型. 然后为融合纵向数据中重复观测间的相关性, 本文利用修正的Cholesky分解方法对重复观测间的协方差阵进行建模, 以提高回归模型参数的估计效率. 本文讨论了参数估计的大样本性质, 并同时讨论了指数平方损失函数中调谐参数的选择、 折点个数的确定方法和折线效应的检验问题等. 数值模拟和实证分析结果显示本文所提方法可以为纵向多折点回归模型的参数提供更为稳健的、 有效的估计.
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
净水技术(2020年2期)2020-02-24
汽车科技(2017年4期)2017-08-08
统计与决策(2017年2期)2017-03-20
现代营销·学苑版(2016年12期)2017-01-23
数学物理学报(2016年5期)2016-08-24
广州医药(2016年2期)2016-08-11
系统工程与电子技术(2016年2期)2016-04-16
电测与仪表(2015年6期)2015-04-09
数学物理学报(2014年3期)2014-03-11
