
基于Windows API调用序列的恶意代码检测方法
2023-06-21 09:43杨波张健李焕洲唐彰国李智翔
四川师范大学学报(自然科学版) 2023年5期
杨波 张健 李焕洲 唐彰国 李智翔


摘要:为解决现有恶意代码检测方法存在的特征提取能力不足、检测模型泛化性弱的问题,提出了一种基于Windows API调用序列的恶意代码检测方法.使用N-gram算法和TF-IDF算法提取序列的统计特征,采用Word2Vec模型提取语义特征,将统计特征和语义特征进行特征融合,作为API调用序列的特征.设计了基于Stacking的三层检测模型,通过多个弱学习器构成一个强学习器提高检测模型性能.实验结果表明,提出的特征提取方法可以获得更关键的特征,设计的检测模型的准确率、精确率、召回率均优于单一模型且具有良好的泛化性,证明了检测方法的有效性.
关键词:恶意代码检测; API调用序列; 特征融合; 机器学习; 三层检测模型
中图分类号:TP309.5 文献标志码:A 文章编号:1001-8395(2023)05-0700-06
Windows操作系统一直是使用最广泛的PC端操作系统,在给人们的工作和生活带来方便的同时,也受到许多针对Windows操作系统的恶意代码的攻击.传统的恶意代码检测方法依赖大量的人工进行手动分析且速度较慢,面对未知病毒时无法及时更新其特征库,导致难以检测未知病毒.
针对以上问题,人们开始研究基于机器学习的恶意代码检测方法,此方法包括静态检测方法和动态检测方法[1].静态检测方法通过对恶意代码进行反编译获取文件字节码操作码等静态特征进行检测,具有流程简便、执行速度快的优点.但对于经过加壳、代码混淆等操作的恶意程序,静态分析很难获取其源代码相关信息,使得准确率较低.动态检测方法通过将恶意代码放置在沙箱等虚拟环境中运行,可以获取恶意代码运行中的Windows API(application programming interface)调用序列、网络流量等动态特征进行检测.API调用序列可以反映一个恶意代码的实际运行情况,是恶意代码检测中非常重要的特征.Tang等[2]提出了一种API序列的特征提取方法,根据颜色映射规则、API的类别、出现次数生成特征图像,采用卷积神经网络模型对图像分类.雷凯[3]通过挖掘API调用序列数据信息,将API分为296类,对API进行One-hot编码,使用Light GBM模型进行分类,取得了97.4%的准确率,但通过调用种类对API序列进行分类会明显丢失API序列的时序特征.文献[1-2]均在基于API调用序列的动态检测技术上有所研究.这些研究成果可以很好应对静态检测技术的缺点,但也存在特征提取能力不足,模型泛化能力差的缺点.
本文以恶意代码的API调用序列为研究对象,提出了一种基于Windows API调用序列的恶意代码检测算法.主要贡献如下:1) 提出一种新的基于API调用序列的恶意代码特征提取方法,从统计特征与语义特征2个角度完成了对API序列的特征提取,可以从API序列中获得更加丰富的特征;2) 设计基于Stacking集成策略的三层检测模型,使用多个不同的弱学习器构成一个强学习器,提升了检测模型的性能.
1相关知识
1.1Windows API Windows API是Windows操作系统中内置的功能函数,是应用程序与Windows操作系统交互的接口.例如,应用程序如果想要实现获取权限、删除文件、修改注册表等功能就需要调用API实现.
恶意代码通过调用一系列的API来实现某种恶意行为.恶意行为相似的恶意代码往往调用的API也具有相似性.因此可以通过分析API调用序列来判断样本是恶意样本还是良性样本.
1.2N-gram算法 N-gram算法是一种基于统计语言模型的算法,被广泛应用于词性标注、垃圾邮件分类、机器翻译和语音识别中.它的基本思想是将文本里面的内容按照词语进行大小为N的滑动窗口操作,形成長度是N的词语片段序列.其中N是指连续的N个词语,N的取值任意.使用N-gram算法对API调用序列进行特征提取,将这个序列以N为大小进行窗口滑动操作得到长度为N的API序列.
N-gram算法可以较好地保留单个API之间的时序特性,但是当N越大时,特征维数会急剧增加,使得分类器的学习时间过长、模型复杂度过高.因此,在使用N-gram算法时,需要选择合适的N值.
1.3TF-IDF算法 TF-IDF(term frequency-inverse document frequency,词频-逆向文件频率)是一种统计方法,用以评估一段文字中一个词语在一个语料库中的重要程度.核心思想是:如果某个词语在一段文字中出现的频率高且在其他文字中出现的频率很低,则认为此词语具有很好的类别区分能力,适合用来分类.TF-IDF值的计算可表示为:TF-IDF=TF·IDF#.(1)TF表示某个API片段在样本j中出现的频率,定义为
1.4Word2Vec模型 Word2Vec是一种从大量文本语料中以无监督方式学习语义知识的语言模型,被广泛地应用于自然语言处理中.Word2Vec模型本质上是具有一个隐含层的神经元网络,其特点是能够将单词转化为向量来表示,以便定量地去度量词与词之间的关系.
Word2Vec模型有CBOW[4]和Skip-Gram[5]两种方式.CBOW方法用周围词预测中心词,根据中心的预测结果,使用Gradient Descent调整周围词的向量.Skip-Gram方法用中心词来预测周围词,根据周围词的预测结果,使用Gradient Descent调整中心词的词向量.CBOW对小型数据库比较合适;Skip-Gram在大型语料中表现更好,语料库中有大量低频词时Skip-Gram的学习更加细致.
1.5集成学习 集成学习就是将多个弱学习器按某种组合策略进行组合,构成一个强学习器,发挥单个学习器各自的优点,提高整体模型的分类性能[6].Sagi等[7]指出集成学习可以提高模型的性能的原因有以下3点:
1) 避免過拟合:当只有少量数据可用时,学习算法容易找到许多不同的假设,这些假设正确地预测了所有训练数据,而对未知实例的预测较差.平均不同的假设可以降低选择错误假设的风险,从而提高整体预测性能.
2) 计算优势:执行局部搜索的单个学习器可能陷入局部最优.通过组合多个学习器,集成方法降低了获得局部最小值的风险.
3) 最佳假设:组合不同的学习器,可以扩展搜索空间,从而更好地拟合数据空间.
常见的组合策略有Bagging、Boosting、Stacking.Bagging的主要作用是减少数据的方差,Boosting主要作用是减少数据的偏差,Stacking集成学习框架是一种具有数学基础,并且在不同领域得到良好应用的集成学习算法,主要用于提升预测结果.
2基于Windows API的恶意代码检测方法
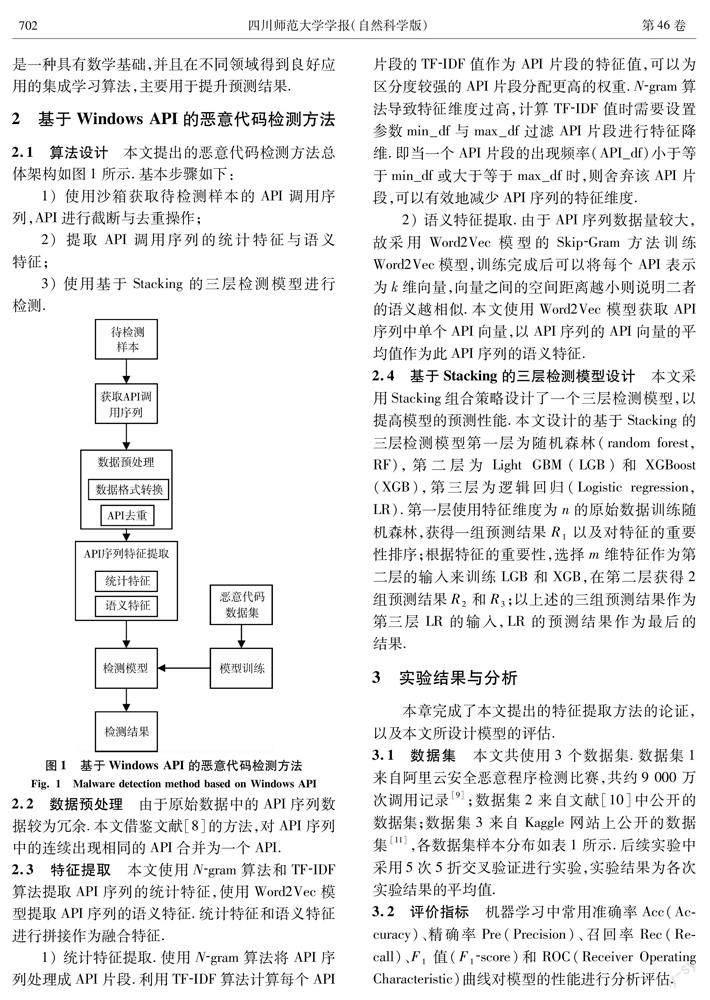
2.1算法设计 本文提出的恶意代码检测方法总体架构如图1所示.基本步骤如下:
1) 使用沙箱获取待检测样本的API调用序列,API进行截断与去重操作;
2) 提取API调用序列的统计特征与语义特征;
3) 使用基于Stacking的三层检测模型进行检测.
2.2数据预处理 由于原始数据中的API序列数据较为冗余.本文借鉴文献[8]的方法,对API序列中的连续出现相同的API合并为一个API.
2.3特征提取 本文使用N-gram算法和TF-IDF算法提取API序列的统计特征,使用Word2Vec模型提取API序列的语义特征.统计特征和语义特征进行拼接作为融合特征.
1) 统计特征提取.使用N-gram算法将API序列处理成API片段.利用TF-IDF算法计算每个API片段的TF-IDF值作为API片段的特征值,可以为区分度较强的API片段分配更高的权重.N-gram算法导致特征维度过高,计算TF-IDF值时需要设置参数min_df与max_df过滤API片段进行特征降维.即当一个API片段的出现频率(API_df)小于等于min_df或大于等于max_df时,则舍弃该API片段,可以有效地减少API序列的特征维度.
2) 语义特征提取.由于API序列数据量较大,故采用Word2Vec模型的Skip-Gram方法训练Word2Vec模型,训练完成后可以将每个API表示为k维向量,向量之间的空间距离越小则说明二者的语义越相似.本文使用Word2Vec模型获取API序列中单个API向量,以API序列的API向量的平均值作为此API序列的语义特征.
2.4基于Stacking的三层检测模型设计 本文采用Stacking组合策略设计了一个三层检测模型,以提高模型的预测性能.本文设计的基于Stacking的三层检测模型第一层为随机森林(random forest,RF),第二层为Light GBM(LGB)和XGBoost(XGB),第三层为逻辑回归(Logistic regression,LR).第一层使用特征维度为n的原始数据训练随机森林,获得一组预测结果R1以及对特征的重要性排序;根据特征的重要性,选择m维特征作为第二层的输入来训练LGB和XGB,在第二层获得2组预测结果R2和R3;以上述的三组预测结果作为第三层LR的输入,LR的预测结果作为最后的结果.
3实验结果与分析
本章完成了本文提出的特征提取方法的论证,以及本文所设计模型的评估.
3.1数据集 本文共使用3个数据集.数据集1来自阿里云安全恶意程序检测比赛,共约9 000万次调用记录[9];数据集2来自文献[10]中公开的数据集;数据集3来自Kaggle网站上公开的数据集[11],各数据集样本分布如表1所示.后续实验中采用5次5折交叉验证进行实验,实验结果为各次实验结果的平均值.
3.2评价指标 机器学习中常用准确率Acc(Accuracy)、精确率Pre(Precision)、召回率Rec(Recall)、F1值(F1-score)和ROC(Receiver Operating Characteristic)曲线对模型的性能进行分析评估.
3.3实验环境 本文的实验环境分为硬件环境和软件环境,硬件环境:CPU(2.2 GHz)、内存(128 GB)、磁盘(36 TB);软件环境:系统环境(Centos 7.8)、Python环境(Python 3.6).
3.4特征提取 本节实验在数据集1上完成了对API调用序列的特征提取.首先使用N-gram算法完成对API序列的离散化,计算API序列片段的TF-IDF值并设置min_df与max_df剔除冗余API片段,得到一维统计特征.其次,训练Word2Vec模型,得到API序列的统计特征.统计特征与语义特征进行拼接作为融合特征.
3.5模型评估 经过特征提取后,获得的融合特征的维度为1 361维.本节实验使用本文设计的基于Stacking的三层检测模型(ST)与单一模型进行比较.实验结果分别如表4和图2所示.
3.6检测方法评估 本文方法与文献[12-14]的方法,在数据集1上进行对照实验.实验结果表明:文献[12-14]及本文的方法Acc分别为96.70%、97.10%、97.91%和98.30%.
可以看出本文提出的方法要优于其他3个方法.其原因在于:1) 使用N-gram算法可以保留单个API之间时序特性.使用TF-IDF算法可以反映API的调用频率特性,给分类能力强的API片段赋予更高的权重,通过设置参数min_df和max_df过滤掉一些分类能力较弱的API片段.使用Word2Vec模型可以从API的语义层面反应API之间的关系.因此,本文所提出的恶意代码特征提取方法可以获得更重要的特征;2) 本文通过基于Stacking集成策略设计的学习器可以继承各个学习器的优点,增强模型的泛化性.所以在最后的实验中可以取得较好的检测效果.
4结论
为了充分挖掘出API调用序列中的重要特征,提高模型的准确性和泛化能力,本文提出了一种从API序列提取特征的方法,提取API序列的统计特征和语义特征为融合特征.设计了基于Stacking的三层检测模型,利用集成学习的思想使用多个学习器构成一个学习器,以提高模型的性能.实验结果表明,本文的特征提取方法是有效的.在多个数据集上证明了基于Stacking的三层检测模型具有良好的准确率和泛化性.通过与其他文献的方法进行比较,证明了本文检测方法具有一定优势.
参考文献
[1] GIBERT D, MATEU C, PLANES J. The rise of machine learning for detection and classification of malware:research developments, trends and challenges[J]. J Netw Comput Appl,2020,153:102526.
[2] TANG M D, QIAN Q. Dynamic API call sequence visualisation for malware classification[J]. IET Inf Secur,2019,13(4):367-377.
[3] 雷凯. 使用Windows API进行恶意软件检测的研究[D]. 北京:北京邮电大学,2021.
[4] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-01-16) [2022-12-14] https://arxiv.org/pdf/1301.3781.pdf.
[5] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]//Proc 26th Inter Conf Neural Info Process Syst. Sydney:NIPS,2013,2:3111-3119.
[6] DONG X B, YU Z W, CAO W M, et al. A survey on ensemble learning[J]. Frontiers of Computer Science,2020,14(2):241-258.
[7] SAGI O, ROKACH L. Ensemble learning:a survey[J]. Wiley Interdisciplinary Reviews:Data Mining and Knowledge Discovery,2018,8(4):18.
[8] TOBIYAMA S, YAMAGUCHI Y, SHIMADA H, et al. Malware detection with deep neural network using process behavior[C]//Proc Comput Soft & Appl Conf. Atlanta:IEEE,2016.
[9] 阿里云. 阿里云安全恶意程序检测[EB/OL]. [2019-03-24]. https://tianchi.aliyun.com.
[10] CATAK F O, YAZ A F, ELEZAJ O, et al. Deep learning based sequential model for malware analysis using windows exe API calls[J/OL]. Peer J Comput Sci,2020. doi:10.7717/peerj-cs.285.
[11] OLIVEIRA A. Malware analysis datasets:API call sequences[EB/OL]. (2022-08-20) [2022-12-14] www.kaggle.com.
[12] 芦效峰,蒋方朔,周箫,等. 基于API序列特征和统计特征组合的恶意样本检测框架[J]. 清华大学学报(自然科学版),2018,58(5):500-508.
[13] 王天歌. 基于API调用序列的Windows平台恶意代码检测方法[D]. 北京:北京交通大学,2021.
[14] 赵翠镕,张文杰,方勇,等. 基于语义API依赖图的恶意代码检测[J]. 四川大学学报(自然科学版),2020,57(3):488-494.
Malware Detection Method Based on Windows API Call SequenceYANG Bo ZHANG Jian LI Huanzhou TANG Zhangguo LI Zhixiang(1. College of Physics and Electronic Engineering, Sichuan Normal University, Chengdu 610101, Sichuan;
2. Institute of Network and Communication Technology, Sichuan Normal University, Chengdu 610101, Sichuan)
Abstract:In order to solve the problems of insufficient feature extraction ability and weak generalization of the detection model in existing malicious code detection methods, this paper presents a malicious code detection method based on Windows API call sequence. This detection method uses N-gram algorithm and TF-IDF algorithm to extract the statistical features of the sequence, and uses Word2Vec model to extract the semantic features, and then fuses the statistical features and semantic features as the features of API call sequences. The three-layer detection model based on stacking is designed, which forms a strong learner through multiple weak learners to improve the performance of the detection model. The experimental results show that the proposed feature extraction method can obtain more critical features, and the designed detection model is superior to the single model in accuracy, precision and recall rates, and has good generalization, which proves the effectiveness of the detection method.
Keywords:malware detection; API call sequence; feature fusion; machines learning; three-layer detection model
(編辑 周俊)
猜你喜欢
软件导刊(2017年7期)2017-09-05
无线互联科技(2017年12期)2017-07-18
科技资讯(2017年11期)2017-06-09
电子技术与软件工程(2017年5期)2017-04-23
现代电子技术(2017年7期)2017-04-14
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
科教导刊·电子版(2016年10期)2016-06-02
