
基于人工智能的抑郁症辅助诊断方法
2023-06-21 07:09:14周莉芸武孟青王雪珠孟宪佳
西北大学学报(自然科学版) 2023年3期
赵 健,周莉芸,武孟青,王雪珠,孟宪佳
(西北大学 信息科学与技术学院,陕西 西安 710127)
抑郁症是一种伴有思维和行为异常的精神心理障碍疾病,有着高复发率、高致残率、高自杀率。据世界卫生组织报告数据显示,全球有超过3.5亿人患有抑郁症[1],并且近十年患者的增速约18%,预计到2030年,抑郁症将上升为第一致残诱因。然而,在抑郁症患病高增长率的背景下,临床中对抑郁症的诊断主要是量表筛查和精神科医生问诊,常用的抑郁量表有很多,如汉密尔顿抑郁量表(HAMD)[2]、贝克自评抑郁量表(BDI)[3]等,但这种方式的诊断结果依赖医生的经验以及患者的配合度,其误诊率也高居不下,根据《中国抑郁障碍防治指南》,重度抑郁症误诊率高达65.9%。因此,迫切需要客观、高效、准确率高的辅助诊断方法。
随着人工智能(artificial intelligence,AI)的发展,已有大量研究将人工智能应用到抑郁症的辅助诊断预测中。知识驱动的第一代抑郁症诊断主要依靠机器学习,通过特征提取算法对语音信号、面部表情、脑电等信号提取表征抑郁的特征,结合机器学习算法,包括随机森林(random forest,RF)、朴素贝叶斯(naive Bayes,NB)、高斯混合模型(Gaussian mixed model,GMM)、支持向量机模型(support vector machine,SVM)等构建抑郁识别模型进行预测[4]。数据驱动的第二代抑郁症诊断主要使用深度学习网络,将抑郁症数据送入深度网络,例如卷积神经网络(convolutional neural network,CNN)、长短时记忆神经网络(long short term memory,LSTM)、深度卷积神经网络(deep convolutional neural network,DCNN)、深度残差回归卷积神经网络(deep residual regression convolutional neural networks,DRR-CNN)等[5]进行训练,从而对抑郁症进行预测。
目前,已有的抑郁症辅助诊断研究能得到较高的准确率,但在基于机器学习的抑郁症诊断系统中,手工提取特征需要大量先验知识并且存在信息丢失的问题。而深度学习网络具有不可解释性,出于对医疗行业安全性考虑,对AI的心理检测结果接受度不高[6],仅依靠深度网络得出的诊断结果无法应用到临床。本文系统性分析了第一代和第二代抑郁症诊断研究,总结了已有的抑郁症辅助诊断方法,思考并讨论抑郁症诊断的发展方向——第三代抑郁症辅助诊断系统。
1 知识驱动的第一代抑郁症诊断
第一代人工智能的本质是基于知识与经验的推理模型,用来模拟人类的理性智能,利用知识、算法和算力3要素构造AI,是知识驱动的AI,以机器学习为主[7]。通过机器学习算法构建的抑郁症诊断模型,我们称为第一代抑郁症辅助诊断方法。
1.1 基于语音数据的抑郁症辅助诊断
越来越多研究者从心理学角度发现,与正常群体比较,抑郁症患者存在着强烈的负性倾向认知和潜在的生理障碍,在语音声学特征方面存在音调较低、语速较慢、语调单一等特点。针对抑郁语音发声特点,提取出不同特征(如韵律、声源、共振峰和频谱)作为抑郁症的有效预测因子[8]。Cummins等人利用梅尔频率倒谱系数(MFCC)和共振峰特征,结合 GMM、SVM 模型,在47个抑郁患者构建的库上进行评估,识别正确率可达到80%,证实了语音特征可以作为抑郁症辅助诊断的有效检测指标[9]。Shin等人提取了声门、速度频谱、共振峰等21个语音特征,在评估抑郁症发病严重程度上灵敏度为65.6%,特异性为66.2%[10]。Dogrucu等人提出了Moodable框架,并开发了应用程序,利用程序收集了简短的语音样本,将K-nearest neighbors (KNN)、SVM、RF部署到Moodable应用程序,并对335名志愿者进行测试,获得0.766的F1分数,0.75的敏感度和0.792的特异性[11]。Jiang等人提出一个集成逻辑回归模型,比较了SVM、GMM和逻辑回归(LR)的分类效果,分析了MFCC、韵律、频谱和声门语音特征对于男性和女性在抑郁症识别的分类性能,发现女性使用频谱、韵律和MFCC特征,男性使用韵律和频谱特征的分类效果好,该模型在女性和男性数据集上分别达到了75.00%和81.82%的准确率[12]。使用相同的方法,利用不同的特征,得出的结果大不相同,说明了抑郁症诊断的研究过程中特征的选取尤为重要。
1.2 基于面部数据的抑郁症辅助诊断
人脸面部表情是传递情感最直接的方式,研究发现,抑郁症患者在情绪失控或者陷入自我负性循环时,其面部表情具有垂目、皱眉、嘴角下拉等特点,表1整理了抑郁症常用面部特征[13]。

表1 抑郁症检测常用面部特征Tab.1 Common facial features for depression detection
徐路分析了患者与正常人在访谈过程中动作单元(AU)的出现频次、变化速率、强度等特征,发现二者存在明显差异,并以此通过SVM进行分类,男性的抑郁识别率达到73.48%、女性达到68.43%[14]。Li等人提取了位置特征、区域特征、动作单元等面部特征,分别针对女性和男性建立模型,采用朴素贝叶斯、支持向量机和随机森林进行分类,得到的准确率女性为86.8%,男性为79.4%,再次证实了从面部指标检测抑郁症是可行的,并且发现眉毛和嘴巴的贡献比面部其他部位多[15]。Wang等人则是在定位面部特征的基础上,通过SVM根据眼睛、眉毛和嘴角的运动变化对抑郁症进行分类,特征检测准确率为78.85%,召回率为80.77%[16]。Tadalagi等人考虑到光照变化的影响,利用光照不变的局部二值模式(LBP)描述符对每一帧图像进行特征提取,用于人脸检测,SVM与LBP共同用于构建抑郁水平检测的完整模型[17]。
1.3 基于电生理数据的抑郁症辅助诊断
近年来,电生理数据辅助抑郁症的诊断也得到大量研究。相关电生理信号主要包括脑电、心电、体温等[18],其中,脑电信号使用频率最高,包括脑电图(Electroencephalogram,EEG)、脑磁图、眼动信号等[19]。Akbari等人提出了一种基于脑电信号重建相空间和几何特征的抑郁检测方法,采用粒子群优化算法和SVM分类器进行特征选择与分类,实现了99.3%的平均分类准确率[20]。Stolicyn等人通过眼动信号中的瞳孔大小、注视位置、注视时间等特征,与机器学习算法相结合,建立抑郁症患者预测模型,准确率较高,且数据获取相对成本更低[21]。Jiang等人提出一种有效的基于脑电图的空间信息抑郁症分类检测方法,向30名参与者(包括16名抑郁症患者和14名健康对照者)呈现相同的正面和负面情绪面部表情刺激,利用差分熵和遗传算法进行特征提取和选择,利用SVM进行分类,对积极刺激和消极刺激分别获得了81.7%和83.2%的分类结果[22]。
1.4 基于多模态数据的抑郁症辅助诊断
由于抑郁症的复杂性,仅使用单模态数据的模型可能会忽略个体差异对判决结果的影响。因此,在人工智能技术的抑郁症辅助诊断研究中,除了使用单一模态数据辅助抑郁症诊断,也有很多使用多模态数据进行诊断研究。多模态数据的抑郁症辅助诊断框图如图1。
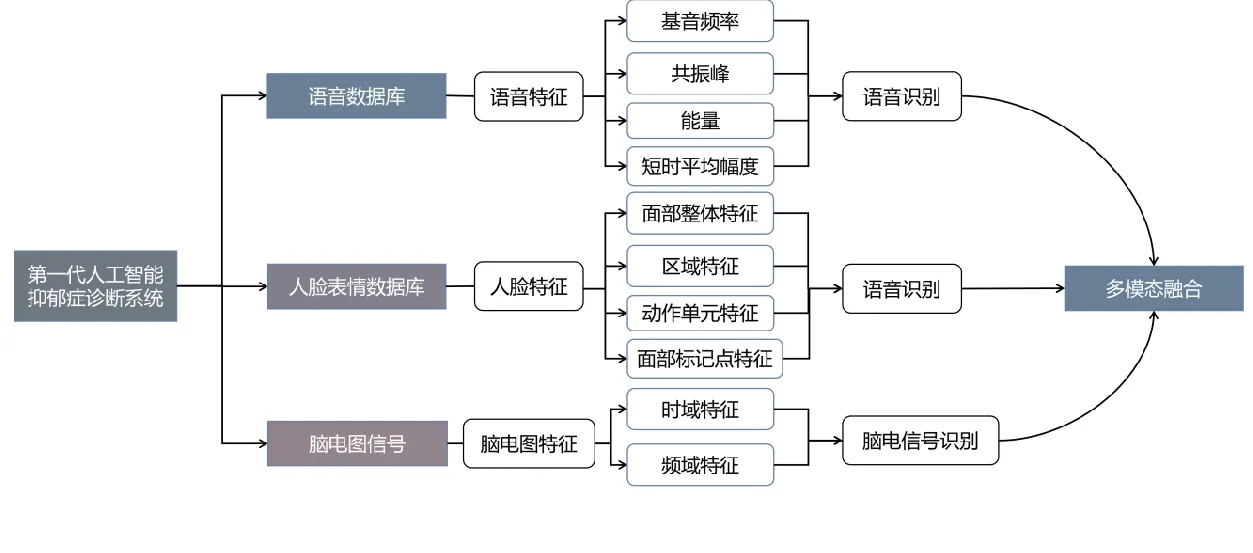
图1 第一代人工智能抑郁症诊断框图Fig.1 The first generation of artificial intelligence depression diagnosis diagram
Alghowinem等人从说话行为、眼睛活动和头部姿势提取特征,支持向量机用于多特征选择的分类,在30名抑郁症患者和30名健康对照受试者的数据集上,个体单模态分类准确率分别为语音83%、眼睛73%、头部63%,特征融合后的平均准确率达到88%,与单模态系统相比,融合后的准确率显著提高,证明了模态的互补性[23]。
Zhang等人提出了一种采用多智能体策略的多模态抑郁症检测方法,从生理和行为两个角度同时进行探索,融合了脑电图和声音信号[24],如图2所示。对受试者分别收集脑电图采集实验和面对面访谈数据,去除不相关的噪声信号,并从每个模态中提取适当的特征。将有效特征在每个模态上训练6个表征分类器,每个分类器获得自己的决策,使用多智能体策略相互交换决策信息。最后,将不同分类器的决策聚合为最终的检测结果。对170名受试者(81名抑郁患者和89名正常对照组)的实验结果表明,所提出的多模态抑郁检测策略在准确性、F1评分和敏感性方面均优于单模态分类器。
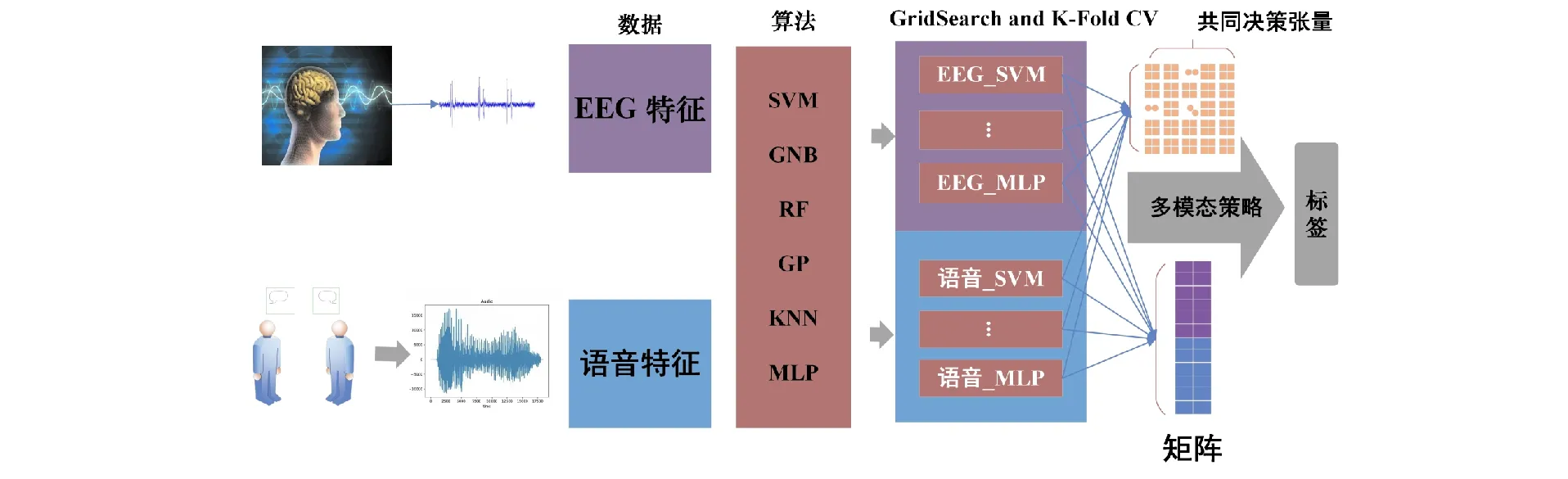
图2 多智能体策略的多模态普遍抑郁检测[24]Fig.2 Multi-modal pervasive depression detection method with multi-agent strategy[24]
我们的研究团队提出了一种基于语音信号和面部图像序列的多模态融合算法进行抑郁症诊断[25]。引入频谱减法增强抑郁语音信号,采用频谱法提取变异率大的音高频率特征和差异显著的共振峰特征,从时域和频域分析了不同情绪语音的短时间能量和频谱系数特征参数,建立了训练和识别模型。同时,实现了正交匹配追踪算法,获得了人脸测试样本的稀疏线性组合,以及基于声音和面部情绪比例的级联。基于融合语音和面部情绪抑郁检测算法的识别率已达到81.14%,与仅使用语音模式相比提高了6.76%,实验结果表明该方法是一种有效的抑郁症检测方法。
知识驱动的第一代人工智能抑郁症诊断方法和人类一样基于知识进行推理,具有可解释性。但从原始数据 (包括图像、语音、视频和文本) 中获取知识主要靠人工,效率不高,并且机器学习的特征选择直接关系到情感识别结果的好坏,必须提取到足够多的与抑郁相关的特征才能有效地提高识别效果,而我们对抑郁症的认知不够充分,可能会导致数据的部分呈现,在一定程度上模型分类的效果会受到制约。随着对抑郁症发病机制的深入研究,对于抑郁指标的选取能够更加精准,与其他学科的合作对于抑郁症诊断系统的研究至关重要。今后仍需要开展大量临床研究来验证和完善这些客观指标,最终为抑郁症患者提供一个安全准确的诊断方法。
2 数据驱动的第二代抑郁症诊断
随着在神经网络模型和学习算法上取得重大进步,开启了以深度学习为基础的第二代人工智能的新纪元[26]。第二代AI利用数据、算法与算力 3要素构造,是数据驱动的AI,以深度学习为主[7]。通过深度学习网络构建的抑郁症诊断模型,我们称为第二代抑郁症辅助诊断方法。近年来,自动抑郁检测已经获得越来越多的关注,具有良好的性能,为抑郁诊断系统的临床应用奠定了基础。本文对现有诊断方法进行全面总结,根据所采用的数据类型,大致分为基于音频、视频和多模态数据的抑郁症辅助诊断方法。
2.1基于音频数据的抑郁症辅助诊断
Ma等人提出了一个深度听觉网络模型——DepAudioNet,从声音线索中挖掘抑郁表征,采用LSTM和DCNN编码抑郁识别的鉴别音频表征[27]。DCNN可以从原始波形中建模空间特征表示,而LSTM可以从摩尔尺度滤波器组中学习短期和长期的特征表示。此外,在训练阶段引入随机抽样策略,减少样本分布不均匀所造成的偏差,平衡样本。在DAIC-WOZ数据集进行了评估,证明了该方法的有效性[27]。Niu等人提出了一个新的框架,该框架集成了挤压和激励(SE)组件,以及时频通道注意(TFCA)块,以代表有区别的时间戳、频带,此外,考虑到数据的时频属性,提出了一个时频通道向量化(TFCV)块来形成张量[28]。在AVEC2013和AVEC2014上进行验证,RMSE分别是8.32和9.25,解决了语音频谱的不同频带对抑郁检测贡献不均等问题[28]。Dong等人提出一个深层的ADE架构,使用预训练模型提取深度语音特征,并结合深度说话人识别(SR)和语音情感识别(SER)特征,利用可变长度语音的FVCM算法,计算两个深度语音特征矩阵中分层多通道变化的协方差系数Cij,k和相关系数Rij,k,获得协调特征FVCMk(式中简记为FFVCM)。针对训练样本有限且模型复杂度高容易过拟合的问题,采用层次化抑郁检测模型、深度语音协调特征及其模糊向量作为输入,回归区间作为约束条件,对抑郁症严重程度进行预测。该方法在AVEC2013和AVEC2014基准测试数据集得到了82%的准确率[29]。
Cij,k=Cov(Xij,k)
(1)
Rij,k=r(Xij,k)
(2)
FFVCM=[eig(Rij,k),log(tr(Cij,k)),Entropy(Cij,k)]
(3)
式中:Cov(·)表示协方差运算;r(·)表示关联操作;Xij,k为时滞多通道二进制矩阵;eig(Rij,k)为特征值集合;tr(·)表示矩阵的轨迹;log(tr(Cij,k))为总功率;Entropy(Cij,k)为熵。
2.2 基于视频数据的抑郁症辅助诊断
对于抑郁症的识别,空间部分带有关于人脸的外观和静态表情的面部信息,时间部分捕获了帧之间的运动,包含面部动态信息。对此,Zhu等人提出了一种基于深度卷积神经网络的人脸外观和动态建模方法用于抑郁症的检测[30],结构见图3。
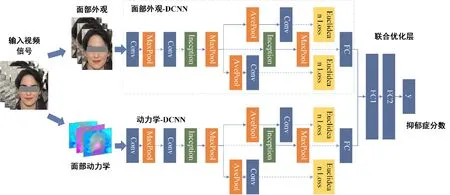
图3 深度学习网络识别抑郁症结构图[30]Fig.3 Deep neural network architectures for depression recognition[30]
将面部外观表示通过深度卷积神经网络(DCNN)建模,面部动态由另一个深度神经网络建模,通过计算视频连续帧之间的光流位移,并将其转换成“流图像”作为网络的输入,从而捕捉面部运动。同时,将微调网络的损失函数改为欧式损失[式(4)],在训练过程中,分别对两个DCNN进行训练,最后,通过联合调整层将两个深度网络集成到一个深度网络中,以实现最终的抑郁症识别。该模型在AVEC2013数据库的MAE为7.74,RMSE为9.91,在AVEC2014数据库融合模型后的MAE 7.53,RMSE 9.73。
(4)
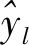
文献[31]提出了一个双流DCNN框架,从RGB图像和视频剪辑中捕获和编码时空动态信息,将面部表情的动态编码为图像映射,图像序列为时间流,其作为ResNet-50架构的输入,采用均方误差函数解决回归问题,平均池化用于融合外观和动态信息,进行输出融合。Zhou等人在CNN的基础上加入残差结构,搭建了一个多区域的DepressNet结构,通过该网络联合学习不同人脸区域的多个局部深度回归模型,在AVEC2013上测试取得了均方根误差为8.28的结果,有效解决了网络退化的问题[32]。
He等人提出了深度局部全局注意卷积神经网络架构(DLGA-CNN),提取视频帧图像中的全局和局部信息,进行抑郁症识别[33]。采用CNN获取局部表示,采用具有注意力机制的CNN和加权空间金字塔池(WSPP)获取全局表示,全局与局部信息的结合提高了模型的泛化能力,其在AVEC2013和AVEC2014数据集上测试均方根误差分别为8.39和8.30。
2.3 基于多模态数据的抑郁症辅助诊断
除了单模态音频和视频外,多模态融合方法可以提高抑郁症预测的性能,融合的主要思路见图4。
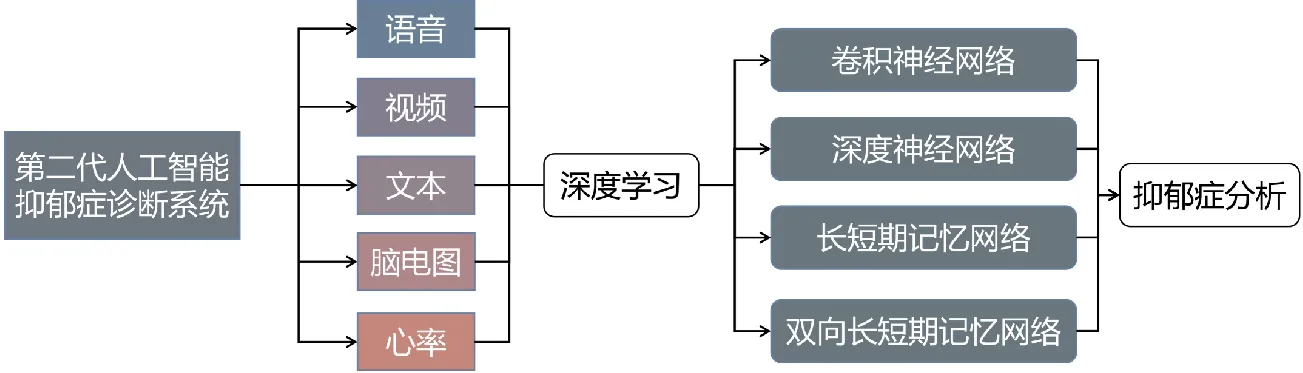
图4 第二代人工智能抑郁症诊断框图Fig.4 The second generation AI depression diagnosis block diagram
Bin等人提出了一种深度学习双向长短期记忆(bi-directional long short-term memory,Bi-LSTM)的方法,融合了脑电图数据和人脸面部特征来检测抑郁症[34]。Malhotra等人提出了一个实时的深度学习系统,融合来自用户的社交媒体信息源(文本、图像和视频)中的多种模式的单个向量表示,获得联合表示[35]。这些联合表示用于获得加权平均分数,该分数使用Softmax层进行最终抑郁分类,可以根据日常帖子持续分析用户的心理状态,是第一项实时检测抑郁症的研究[35]。Madhu等人提出了一种基于深度神经网络和汉密尔顿抑郁量表的多模态数据的抑郁症严重程度检测技术,使用深度神经网络(DNN)检测视频、语音和文本的各个模态,并将所有模态与相应的权重相融合,以计算汉密尔顿抑郁评定量表中的总分,根据计算的分数预测抑郁程度[36]。Fang等人设计了一种具有多级注意机制的多模态模型(MFM-Att),利用两个LSTM和一个具有注意力机制的Bi-LSTM分别学习多视图音频特征、视觉特征和文本特征,再将3种模态的输出特征送入注意力融合网络(AttFN),获取有效的抑郁信息,利用抑郁症检测方式之间的多样性和互补性,减少冗余信息并提高模型整体性能[37]。
Wu等人提出一种从情绪识别到抑郁检测的新型方法,利用从情绪识别模型中提取的预训练特征进行抑郁检测,进一步将情绪模态与音频和文本融合,形成多模态抑郁检测[38],结构如图5所示。他们采用具有10 ms帧移、25 ms帧长以及一阶导数系数的40维Log Mel滤波器组特征(FBKs)作为音频特征。将语音中捕捉的语义与上下文作为文本分支的输入,使用共享的全连接层减少每个输入句子的嵌入维数,由五头自注意层进行整合,通过双向门循环单元(Bi-GRU)训练音频,并通过Bi-LSTM模型训练文本。将BERTs模型作为情绪特征提取器,在融合层获得情感特征,采用Bi-LSTM模型汇集段级特征,并产生抑郁症诊断的会话级决策,将情感融合音频、文本后的F1为0.87。
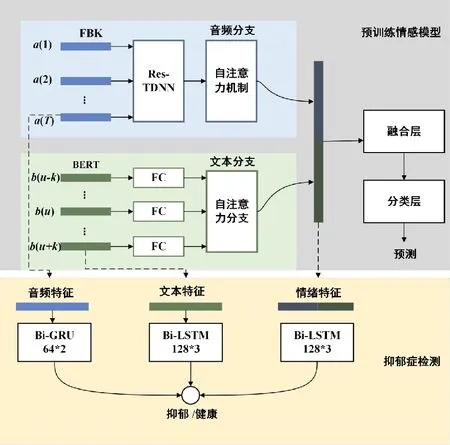
图5 融合3种模式的多模态抑郁检测[38]Fig.5 Fusion of three models more modal testing for depression[38]
3 第三代人工智能的抑郁症诊断
深度学习网络的训练需要大量数据推动,但抑郁症的病理表现涉及病人隐私特殊性,样本数据需要征得参与者同意后从医院或者心理诊所获取,多数已有数据集尚未得到授权公开用于抑郁症分析研究,只有少数数据库公开发布[39]。表2列举了一些开源数据库。

表2 开源抑郁数据库简介Tab.2 Introduction to open source depression database
如表2所示,数据集的有限大小限制了抑郁症诊断的研究,为了解决这个瓶颈,需要有效的方法来增加有限数量的注释数据。并且深度学习作为黑盒模型难以解构,预测机制难以解释,即使能够获得很高的准确率,却没办法给出更多可靠信息[40]。为了建立一个全面反映人类智能的AI,把第一代的知识驱动和第二代的数据驱动结合起来,通过同时利用知识、数据、算法和算力等4要素,构造更强大的第三代AI[7]。基于第三代AI的思想,第三代抑郁症诊断系统结合前两代抑郁症分析系统各自的优势,更加全面、准确地对抑郁症进行诊断。
信息融合通过结合不同来源的异构信息确保处理信息的高质量,使得决策更加全面可靠[41]。手工提取的特征结合深度模型可以更好地挖掘到抑郁特征信息,将第一代知识驱动和第二代数据驱动的抑郁症诊断系统进行特征融合(见图6)与决策融合(见图7)。
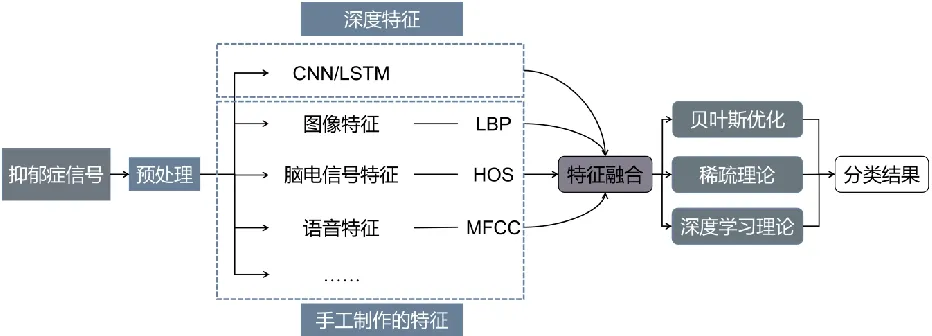
图6 特征融合的第三代人工智能抑郁症诊断Fig.6 The third generation of artificial intelligence depression diagnosis feature fusion
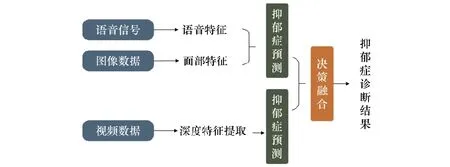
图7 决策融合的第三代人工智能抑郁症诊断Fig.7 The third generation of artificial intelligence depression diagnosis decision fusion
3.1 手工特征与深度特征融合
手动提取的特征与深度学习模型特征具有不同属性,将手工特征与深度特征结合起来,既可以利用医生的经验,又可以挖掘原始数据中的隐藏信息,在高性能的基础上获得更可靠的结果。
Huang等人提出名为混合加框架(HPF)的特征融合框架用于抑郁症检测[42]。其包含FET模块和增强DNN,FET模块提取手工制作的特征并将其转换为稀疏分类特征,增强DNN直接从原始数据中提取深层特征,并利用嵌入层将稀疏的高维分类特征转化为低维的神经嵌入特征。将FET模块和DNN的输出通过全连接层进行抑郁分类。Omeroglu等人对语音信号和电声门(EGG)信号分别提取手工特征和深度特征,并连接这些特征获得特征集,最后,使用SVM分类器进行分类检测,该方法在SVD语音数据库上获得的准确率高达 90.10%,此外,分别获得了 92.9%、84.6% 和 92.57% 的敏感性、特异性和F1分数结果[43]。Huang等人提出多视角特征融合模型[44],结构如图8所示。从抑郁症数据集中提取手工视图特征,从深度学习模型中获得深度视图特征。手工特征包括心电信号的形态特征以及时间特性,深度特征提取采用CNN-LSTM结构,提取不同尺度的特征以及动态时间特征。全连接层融合两种不同视角的特征并发送到分类器,用随机森林分类器代替Softmax分类器进行分类,采用RF分类算法进行融合特征分类,贝叶斯优化被用于分类器的超参数调整。实验的平均准确率为98.93%,证明了多视角特征融合模型的有效性和优越性。
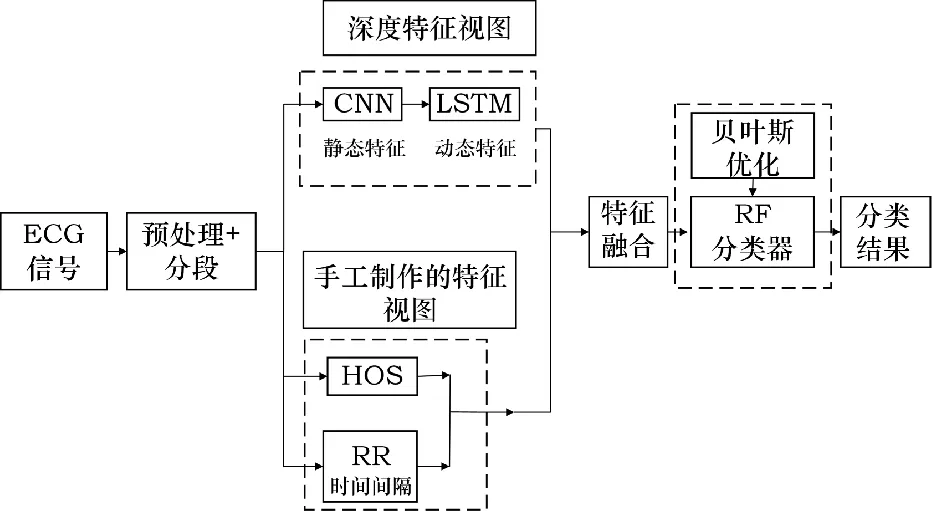
图8 多视图特征融合模型结构[44]Fig.8 Structure of the multiview feature fusion model[44]
3.2 第一代与第二代的决策融合
决策融合是融合不同分类器获得的信息的过程,能够利用它们各自的优势,具有很强的容错性。Zhang等人提出一种基于决策级多模态融合的计算机辅助识别框架,多组对照试验结果表明,与独立分类器相比,决策级多模态融合方法对抑郁症的识别能力更强,最高准确率为92.13%[45]。Soni等人在提出的Node2vec算法框架上对脑电信号进行了决策融合,在公开数据集上测试的峰值准确率达到0.933[46]。Yan等人提出一种新的融合思想(见图9),根据每种信号模态的分类精度、不同信号模态之间的相关性以及信号模态的稳定性,设计不同加权方法的自适应多模式决策融合[47]。
第三代人工智能抑郁症分析系统基于第三代AI的思想,结合前两代抑郁症分析系统各自的优势。目前存在的研究结果表明信息融合后的模型在较高的准确率上增加了结果的可靠度,更加全面地对抑郁症数据进行分析,为抑郁倾向识别提供了良好的理论支撑。
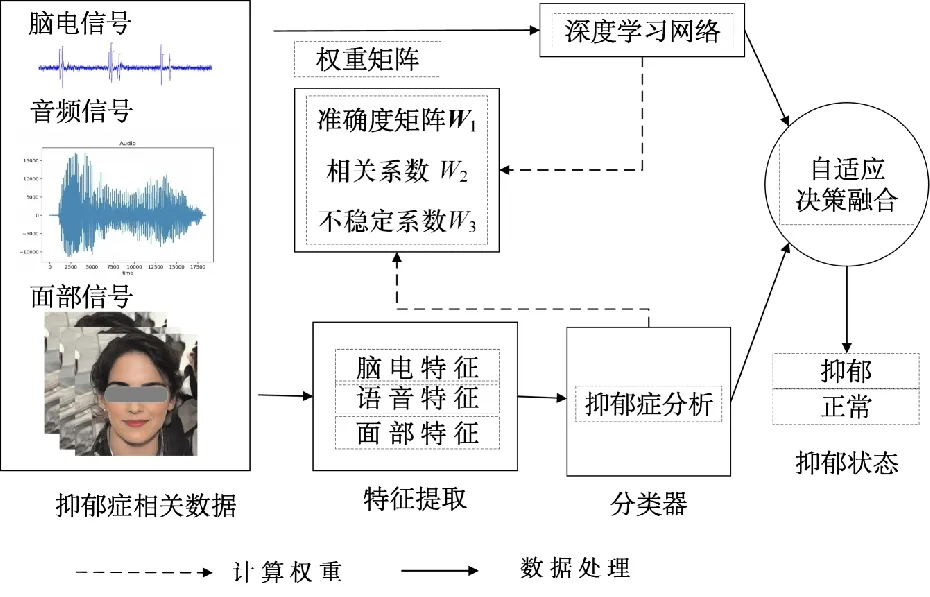
图9 自适应多模式决策融合[46]Fig.9 Adaptive multiple mode decision fusion[46]
4 结论与展望
利用人工智能技术进行特定数据分析,在一定程度可节约医疗资源、提高工作效率,加快对疾病的介入治疗,同时,规模化抑郁症诊断系统,有可能实现民众普及自检自测,具有重要的研究意义。本文按照人工智能的发展阶段将抑郁症诊断方法划分为机器学习的第一代诊断方法、深度学习的第二代诊断方法以及融合后更全面的第三代诊断方法。本文系统地分析了近年来人工智能抑郁症诊断方法,总结现有诊断方法的研究成果,指出了未来抑郁症诊断方法的发展方向。目前关于第一代和第二代抑郁症诊断的研究方法较为全面、成果显著,但第三代抑郁症诊断方法的研究还处于初期阶段,相关的研究成果较少。
为推动抑郁症研究进入临床应用,要在保证高准确率的基础上增强系统的可解释性,建立一套医患互信的新医疗系统。我们的研究团队在前期已有成果的基础上,将继续推动第三代抑郁症诊断方法的研究,未来,我们将开展以下研究。
1)抑郁症的诊断依赖于包括临床心理学、情感计算和计算机科学在内的多个领域的协同努力。为了实现抑郁症诊断系统的临床使用,我们将与跨学科领域的研究人员合作,获得更多的抑郁症医学指标,便于多维度的诊断。
2)现阶段抑郁症数据量较少,还需要开展更多的工作来收集额外的数据。我们将尝试收集包括音频、视频、文本、生理信号的多模态数据库。
3)我们将深入研究手工特征和深度学习特征之间的互补模式,以提高系统辨别特征的能力及系统的健壮性。
4)对于多模态数据,我们将借鉴不同领域研究人员的经验,考虑不同模态之间的互补模式,通过研究不同的融合方法,提高数据间互补信息的能力。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
中国交通信息化(2018年5期)2018-08-21 03:37:40
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
