
人工智能医疗器械性能评价通用方法专家共识(2023)
2023-06-13 02:42通信作者刘士远mailcjrliushiyuanvip163com李静莉maillijlinifdcorgcnmailwujian2000zjueducn
协和医学杂志 2023年3期
通信作者:刘士远,E-mail:cjr.liushiyuan@vip.163.com 李静莉,E-mail:lijli@nifdc.org.cn 吴 健,E-mail:wujian2000@zju.edu.cn
1海军军医大学第二附属医院影像医学与核医学科,上海 200003 2中国食品药品检定研究院医疗器械检定所,北京 102629 3浙江大学公共卫生学院,杭州 310027
新一代人工智能(artificial intelligence,AI)技术与生物医疗的交叉融合,不断深化我们对疾病和诊疗方法的认知与思考方式,为解决临床问题提供了新思路,为医疗产业发展开拓了新视野。如智能医学检测技术可辅助快速检测医学影像中的病灶,智能分类技术可快速准确地辅助测量骨龄和分辨眼底彩照中的疾病等[1-3]。大量的科研和实践经验表明,AI技术在解决部分临床问题方面具有速度优势、效果优势,有望缓解医疗资源稀缺紧张、分配不均的现状。当前,AI医疗器械的研发与转化已进入活跃期,但具体产品在性能指标、验证方法、临床表现和用户反馈等方面存在较大差异,质量参差不齐。随着AI医疗器械产品功能的增加和适应证的扩展,其产品检验与质量控制技术也处于不断发展变化中,大量实际问题亟待探索研究和解决。学术界、工业界已提出大量检测方法和度量指标,但其科学性、公正性、有效性、规范性、适用性有待统一。
目前,各个国际标准化组织开始布局AI医疗器械标准的起草,性能评价是重中之重,如国际电工委员会医用电器设备标委会(IEC/TC62)提出的《人工智能医疗器械性能评价过程》《人工智能医疗器械测试》等[4-5],此类项目目前处于框架阶段,属于通用标准,具体细节尚未展开。
我国AI医疗器械标准体系发展较快,目前已发布了《人工智能医疗器械 肺部影像辅助分析软件 算法性能测试方法》《人工智能医疗器械 质量要求和评价 第1部分:术语》《人工智能医疗器械 质量要求和评价 第2部分:数据集通用要求》《人工智能医疗器械 质量要求和评价 第3部分:数据标注通用要求》4个行业标准[6-9],在热点产品的算法测试方法、测试流程、数据集通用质量评价等方面取得了突破[10-16]。在实践层面,中国食品药品检定研究院联合国内临床机构共同建设了糖网眼底彩照图像测试集和胸部CT肺结节测试集,分别在糖尿病视网膜病变辅助诊断软件、胸部CT肺结节辅助检测软件的算法性能测试中开展了应用,并积累了早期经验。然而,目前我国尚缺乏兼具全面性和通用性的评价框架,用以指导医疗领域的所有AI医疗器械。因此,在现有研究基础上,有必要进一步凝练行业共识,研究AI医疗器械的通用性能评价框架,统筹后续标准的发展方向,参与国际标准的制订。
为更好地满足质量评价需求,本共识在征集和总结专家意见的基础上,对AI医疗器械的性能评价进行系统梳理,为建立通用性能评价框架提供相关解决方案。本共识内容具有一定的前瞻性,同时将跟随产品技术升级、市场情况变更、医疗器械监管要求、临床实践演化而更新,逐步建立更为科学合理的统一规范,鼓励全社会有序开发和利用医学数据资源,研发AI医疗器械,持续更新性能评价方法和指标体系。
1 共识形成方法
本共识由浙江大学睿医人工智能研究中心发起,共识专家组由中国食品药品检定研究院等多家专业机构以及人工智能医疗器械标准化技术归口单位医学与计算机人工智能学科交叉领域的14位专家共同组成,无相关利益冲突。参照共识和指南的制订方法[17-20],2022年1月启动该共识的制订工作,2022年11月定稿。专家组拟定关键问题和共识提纲后,以“人工智能医疗器械”“质量要求”“质量评价”“软件测试”“Medical Artificial Intelligence”“Quality Management”“Software Engineering”“Artificial Intelligence Device Evaluation”等为关键词,于ACM Digital Library、IEEE Digital Library、PubMed、中国知网、万方数据知识服务平台、维普数据库中检索相关中、英文文献,检索时间为建库至2022年3月。2022年6月22日和2023年3月9日,专家组经2次线上讨论和修改,最终形成共识终稿。考虑到AI医疗器械发展迅猛、实际检测要求多样的现状,本共识仅保留投票结果一致性100%赞成的意见,最终确定三大类14种AI医疗器械质量特性及示例(表1)和四大类17种推荐AI医疗器械测试方法(表2)。

表2 17种AI医疗器械测试方法
2 AI医疗器械的质量模型
参考ISO/IEC 25010和ISO/IEC TR 29119,AI软件产品的一般质量模型如图1所示,包括软件特性和AI特性两个层面。其中软件特性又分为功能特性和一般性能。对于AI医疗器械而言,对质量模型的理解需依托实际的临床应用场景。表1所示为上述各质量特性含义的解读和示例。
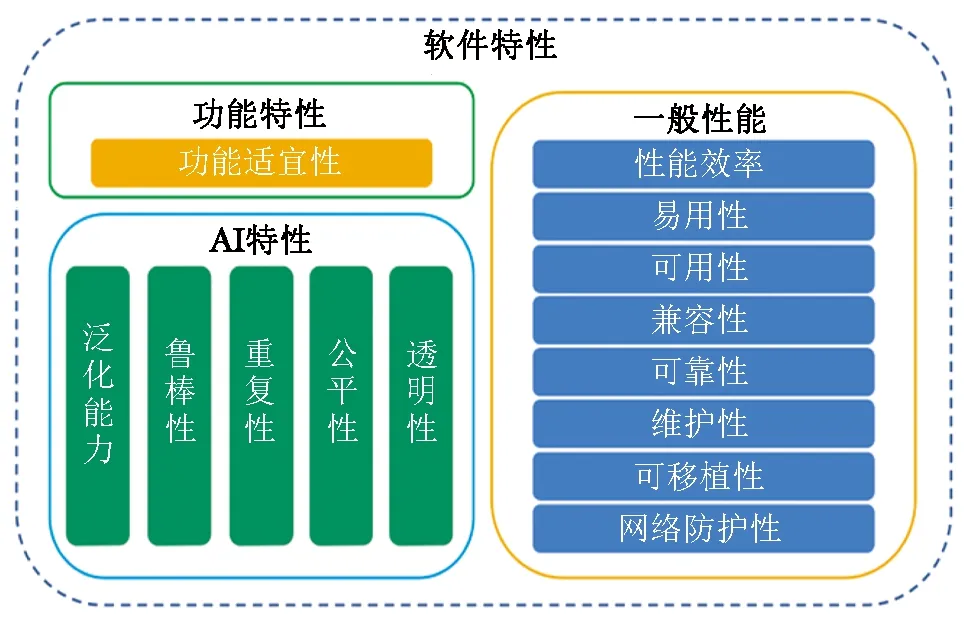
图1 AI软件产品的一般质量模型
AI医疗器械质量特性在其质量评价中扮演重要角色。其中,软件特性的评价一方面可参照通用软件的测试方法,如GB/T 25000.51标准,通过编写测试用例、检查文档和实际操作进行验证;另一方面需结合临床医生的实际体验,进行主观、定性的评价,如医疗器械软件的可用性试验。
AI特性的评价则相对复杂。由于目前AI医疗器械大部分采用深度学习的技术路线,算法的工作机理不透明,难以直观评价,而需借助算法的输入-输出关系进行间接观测,客观上需依托高质量临床数据建设专用的测试集。
对于AI医疗器械而言,软件特性和AI特性存在一定交叉,如辅助决策的正确性(常见指标包括灵敏度、特异度、准确率等)与功能的正确性、算法的泛化能力均有关系。再比如产品的网络防护性能,既要考虑对自身网络安全漏洞的控制,又要考虑算法抵御欺骗性攻击的能力。
3 AI医疗器械的性能评价需求
AI医疗器械的性能评价,一般需考虑产品生存周期的研发设计、验证确认、临床应用、迭代更新4个主要阶段。在研发设计阶段,主要考虑对AI算法模型自身的功能、性能、效率、安全性进行调优验证,为算法定型和封装提供决策。在验证确认阶段,需关注医疗器械的成品能否满足设计要求、能否满足用户需求的功能和性能,开展实验室测试、临床预试验、临床评价等活动,包含对算法性能指标、安全特性的考量。在临床应用阶段,需关注产品的日常质控、真实临床表现、上市后监督、不良事件监测等问题,开展必要的评价。在AI技术迭代更新之后,则需进行新的循环,周而复始。
上述环节在4个方面需通过测试活动形成客观证据,为企业研发、临床使用、政府监管的决策制订提供支持。因此,针对AI医疗器械质量特性中的软件功能特性,需进行一般性能测试中的部分测试流程;针对AI特性,需进行泛化能力与鲁棒性测试中的部分测试流程(AI特性中的公平性和透明性评价方法目前处于研究阶段,暂不纳入);针对软件的一般性能,需进行一般性能测试、泛化能力测试、鲁棒性测试以及安全性测试的部分测试流程。本文将所有测试流程归纳为四大类,具体内容如下:
(1)一般性能测试:AI算法实现其预期用途的程度需通过具体的技术指标进行表征,如预期用于辅助分类的AI算法可使用灵敏度、特异度、准确率作为性能指标。依托具体的测试集,测试机构可获得定量的测试结果,用于评价算法的一般性能。
(2)泛化能力测试:泛化能力是AI产品能否推广应用的关键,可衡量算法对陌生样本的适应能力。我国幅员辽阔,人口众多,不同地区、医疗机构在流行病学特征、数据采集方面存在较大差异,对泛化能力要求较高。因此在产品的测试环节,有必要增强测试数据的多样性,灵活组合和模拟各种情形,充分考量泛化能力。
(3)鲁棒性测试:由于产品上市后可能遭遇各种来源的数据扰动和噪声,产品性能能否保持平稳、符合预期,对临床用户和患者权益具有重要影响。不同于对样本数据适应性进行评价的模型泛化能力测试,鲁棒性测试的目的是检验模型对异常问题的应对能力。目前,业内推荐采用对抗测试,对已有数据样本进行适当扩增,观测算法在面对扰动时的表现,具体方法有待细化和扩展。
(4)安全性测试:由于AI医疗器械多以独立软件、软件组件的形态存在,公共利益方关注产品的网络安全、数据安全能力。因此,产品的安全性测试同样重要,需模拟现实挑战,形成配套的方法和技术服务能力,满足监管要求。
4 AI医疗器械的测试方法
AI医疗器械测试方法是为有效反映被测试医疗器械在被期待的质量特性上的性能水平,包含前文所述4种情形。为保证对被测试AI医疗器械质量检测的全面性和客观性,结合国内外相关研究[21-23],笔者从代表性样本、对抗攻击、模型综合表现、数据安全4个方面纳入了17种不同的AI医疗器械检测方法,用于支撑AI医疗器械通用质量评价框架,针对不同待测产品及其应用场景可调用其中的测试方法和配套性能指标,作为产品性能评估的客观依据,具体内容详见表2。现对具体的测试方法、对应指标,以及测试方法的选用条件分类进行阐述。
4.1 一般性能测试方法
鉴于医疗领域的敏感性与关键性,AI医疗器械质量评价过程首先需实现其医疗AI模型在一般场景下的表现测试,确保其实用性。因此,测试方应构建常规测试数据库,针对模型的常规数据表现、训练效率以及运算速度进行测试。针对不同算法的应用场景与任务,需专家给定不同的指标衡量AI医疗器械性能。本共识以最为常见的分类、检出、分割为例。对于分类任务,通用的测试指标采用灵敏度(sensitivity)衡量模型对阳性样本的灵敏程度(漏诊情况),采用特异度(specificity)衡量模型判断实际阴性样本的成功率(误诊情况),采用曲线下面积(area under the curve,AUC)值衡量模型综合考虑实际阳性样本与阴性样本的分类能力。
对于检出任务,通用的测试指标包括精确度(precision)、召回率(recall)、F1分数等,还可采用准确率(accuracy)和距离误差,分别描述被测试AI医疗器械的识别准确度和检测对象的检测框位置定位准确度。以欧氏距离误差为例,公式定义如下:
其中pi代表检测任务中模型预测的目标位置坐标,yi则代表真实标签的位置坐标。
对于分割任务,通用的测试指标采用像素准确率(pixel accuracy,PA)和类别平均像素准确率(mean pixel accuracy,MPA)衡量模型的像素分割准确度,采用交并比(intersection over union,IoU)、平均交并比(mean IoU,mIoU)和Dice衡量模型预测区域与真实区域的交集占比,混淆矩阵作为模型在各个类别像素分割准确预测数量的直观表示。以MPA和mIoU为例,公式定义如下:
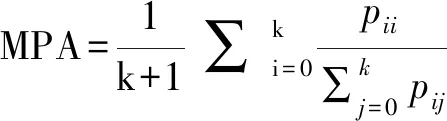
其中,pi代表模型输出预测为i类目标像素的集合,yi则为真实标签中属于i类目标的像素集合,|·|代表集合中像素的数量。而针对三维影像的分割任务,通用的测试指标包括平均表面距离、Hausdorff距离,衡量模型的3D体素分割区域与真实区域偏移的空间距离。Hausdorff距离的公式定义如下:
其中X代表模型分割的体素集合,Y代表真实的体素集合,d(x,y)代表体素x与体素y的欧式距离,sup代表上确界,inf代表下确界。
基于上述指标和公式,可采用下述的测试方法和流程,在不同条件下对AI医疗器械性能进行评价。
4.1.1 常规数据表现测试法
一般样本是指“测试样本分布符合产品适用人群一般分布”的样本。在该测试过程中,测试方从目标数据库中抽样出数据分布符合预期临床场景、不存在偏离较为严重情况的样本用于测试AI医疗器械。在该测试过程中,以专家人工标注得到的参考标准作为基准,对被测试的AI医疗器械输出结果进行评分。当评分满足制造商标识的水平时,认为被测试AI医疗器械通过了常规数据样本测试。在最终的检验报告中,应对测试样本和参考标准进行描述。
4.1.2 效率测试法
产品模型大小测试是对模型运行成本的一种度量性测试。对于基于AI技术的医疗器械,该测试法应在技术要求规定的环境中开展。在该测试中,测试方记录被测AI医疗器械的模型参数量、内存占有量、每秒所执行的浮点运算次数(floating-point operations per second,FLOPS)、CPU占用量和GPU占用量等模型参数。在最终的检验报告中,应注明测试结果各项指标及配置环境。
4.1.3 应用场景效率测试法
4.2 泛化能力测试方法
对AI医疗器械的泛化能力测试通常是基于观察系统如何对环境修改或突变作出响应。通过选择一些特殊样本输入模型进行测试,这些样本的分类效果反映了AI医疗器械的泛化能力与真实性能的差距。因此,测试方应选取被测试AI医疗器械针对的临床场景中常用的、具有特殊代表性的样本进行测试。代表性样本测试方法包括:患者亚人群组合测试法、压力样本测试法、混合征样本测试法、跨设备测试法等。现针对泛化能力常用测试方法的含义和测试流程进行详细介绍。
4.2.1 患者亚人群组合测试法
患者亚人群是指具备类似特征的患者样本子集,常见为具有相近年龄、生活习惯等的患者样本或拥有相近治疗轨迹和结局等的样本子集。不同于下文提到的混合征样本测试法,该测试法通过整理具有单一特征的样本组成患者亚人群,通过组合不同患者亚人群的样本作为测试集进行测试,以实现测试数据的多样性。在该测试过程中,测试方从患者亚人群数据库中抽样出具有多种患者亚人群的样本作为测试数据集,使用被测试的AI医疗器械对具有多样性和变化性的测试样本进行预测,以专家人工标注得到的参考标准作为基准,对被测试AI医疗器械的输出结果进行评分。当评分满足制造商标识的水平时,认为被测试AI医疗器械通过了患者亚人群组合测试。在最终的检验报告中,应对测试样本和参考标准进行描述。
4.2.2 压力样本测试法
压力样本可理解为“被正确识别有难度”的样本,也称为“困难样本”。在该测试过程中,测试方从目标数据库中抽样出一部分难以分类的、非典型样本用于测试AI医疗器械,以专家人工标注得到的参考标准作为基准,对被测试AI医疗器械的输出结果进行评分。当评分满足制造商标识的水平时,认为被测试AI医疗器械通过了困难样本测试。在最终的检验报告中,应对测试样本和参考标准进行描述。
4.2.3 混合征样本测试法
混合征样本一般出现在多种病灶或多种相似疾病同时发病的情况,如肺结节患者同时存在多种类型的肺结节。该测试法通过整理具有多种不同特征(如多种类型的肺结节)的样本组成作为测试集进行测试,检测模型在面对易混淆、多标签数据时的泛化能力,实现测试数据的多样性。在该测试过程中,测试方从数据库中抽样出具有多种标签(代表类别)的样本,使用被测试AI医疗器械对测试样本进行多类别预测,以专家人工标注得到的参考标准作为基准,对被测试AI医疗器械的输出结果进行评分。当评分满足制造商标识的水平时,认为被测试AI医疗器械通过了混合征样本测试。该测试方法仅用于临床上存在混合征疾病的部分AI医疗器械,为非必要测试方法。
4.2.4 跨设备样本测试法
跨设备样本一般出现在临床器械品牌较多的情况,如眼底光学相干断层扫描技术(optical coherence tomography,OCT)设备。在测试过程中,测试方从数据库中选用多种常用型号医疗器械记录的产品样本,测试AI医疗器械在跨设备样本中的识别效果。当在不同设备中产生的样本识别效果差距小于制造商标识的水平时,认为被测试AI医疗器械通过了跨设备样本测试。
4.3 鲁棒性测试方法
对于基于随机算法的AI系统,并非经常存在一个可用作预期结果的精确值。AI医疗器械的每次决策,可能得出不同的结果(如计算可能基于随机种子,每次都会产生不同但可行的结果)。因此,被测试AI医疗器械可能存在非确定性,导致了可重复性的缺乏。此外,针对一些非典型、难以分类的样本,以及模型运行在不同环境时也可能得出不同的结果。在此两种情况下,实际结果中的不确定性要求测试人员获得比传统系统更复杂的预期结果。因此,测试方应选取一些领域内临床场景常用的、具有特殊代表性的样本和环境进行测试。代表性的样本测试方法包括:自然噪声样本测试法、不合格样本测试法、可信区域测试法、结果一致测试法、对抗攻击测试法、结果无偏测试法、不确定性测试法等,现对各测试方法的含义和测试流程进行详细介绍。
4.3.1 自然噪声样本测试法
自然噪声样本是指在器械、环境等因素条件下,导致存在粒度粗细不一致、分布不一致、背景不一致等噪声信息的样本。在测试过程中,测试方从数据库中选用存在较大自然噪声的样本(如来自特定厂家产品的数据),测试AI医疗器械在这些大噪声样本中的识别准确率。当算法性能未显著低于普通样本的识别效果(低于识别阈值时,需提请专家组评估确定)时,认为被测试AI医疗器械通过了自然噪声样本测试。
4.3.2 不合格样本测试法
不合格样本是指不具备被识别信息的样本,常见为非该疾病类型的样本、医学影像中的错片和废片等。在该测试过程中,测试方从数据库中抽样出其他类型的样本和/或其他有明显错误的样本混合在正确样本中,使用被测试AI医疗器械进行判别,测试其能否避开误导。测试时采用召回率评估被测试产品对错误样本的识别效果,召回率高说明被测试产品能够准确识别错误样本。当召回率超过一定阈值(如95%)时,认为被测试AI医疗器械通过了错误样本测试。该测试为非必测项目,由被测AI医疗器械应用场景和器械的使用声明等决定。如某些器械声明具有“不合格样本检出”的特性,则需进行不合格样本测试。
4.3.3 可信区域测试法
可信区域测试指模型适用范围的确认,是模型泛化能力的补充。在该测试过程中,测试方从数据库中抽取不同类别、采集自不同设备、适用于不同任务的样本。对于不同的数据子集,采用被测AI医疗器械对这些子集进行预测,并采用准确率、AUC以及使用五折交叉验证后二者指标的方差进行度量。当被测试AI医疗器械在任意子集上准确率指标均不低于产品的设计预期,以及多次抽样测试的方差不大于预定阈值时,则认为被测试AI医疗器械在该类场景是可信的。在最终的测试报告中,应详尽注明不同场景条件下被测试AI医疗器械的性能和评测结论。
4.3.4 结果一致测试法
结果一致性测试是指验证模型的临床应用分析是否建立在关键特征分析上的测试方法。在该测试过程中,测试方对抽样的样本进行变换操作(如对图像进行裁剪、翻转,对文本进行one-hot嵌入,对心电图进行傅里叶变换等)后和变换前组成样本对,应用被测试AI医疗器械对变换后的样本和原样本进行预测,并采用一致率指标进行度量。一致率指标定义为:
其中,Nc表示样本对预测结果一致的数量,N表示样本对的总数量。原则上,当一致性指标不低于专家多次反复判断的一致率时,认为被测AI医疗器械的结果一致性测试基本合格。
4.3.5 对抗攻击测试方法
对抗攻击测试是指通过输入添加的微小扰动使得分类器分类错误,一般用于深度学习网络的攻击算法。通过对抗攻击测试,测试方可评价智能器械的内核模型对样本中的微小扰动是否过于敏感,检验智能器械在进行应用时能否捕捉关键特征,避免因某些不适应的特征导致结果跳变。如在测试过程中,从数据库中抽样出相应样本,首先使用Carlini and Wagner(C&W)攻击,对数据添加控制,在l∞,l2和l0范围内变动,使样本变化无法使人察觉,被测试AI医疗器械预测的算法性能无明显下降(损失的性能阈值需提请专家组评估确定)时,认为其通过了C&W攻击测试。然后使用通用扰动方法(universal adversarial perturbations),生成施加了足以跨越分类边界的微小扰动而不偏离真实样本数据分布的样本,如对任何图像实现人类几乎不可见但能推出分类边界的扰动,但同一个扰动针对的是同一类样本的所有样本,且可泛化至大部分针对该样本的网络模型。被测试AI医疗器械预测的算法性能无明显下降(损失的性能阈值需提请专家组评估确定)时,认为其通过了通用扰动攻击测试。
4.3.6 结果无偏测试法
无偏估计是指用样本统计量估计总体参数的一种无偏推断。估计量的数学期望等于被估计参数的真实值时,则此估计量为被估计参数的无偏估计,即具有无偏性,是一种用于评价估计量优良性的准则。结果无偏测试是指验证模型对关键特征的识别是建立在理论逻辑上的另一种测试方法。在该测试过程中,测试方对样本进行编辑等操作,使用裁剪等方式抹去数据中除关键特征点(如肿瘤)外的无关特征,或使用翻转、旋转等数据增强方式生成新的相关样本,采用被测试AI医疗器械编辑后的样本进行预测,并采用精确度指标进行模型的结果验证,当对数据的预测准确率与原预测准确率相差不大于设定的阈值时,认为被测试AI医疗器械的结果无偏测试基本合格。
4.3.7 不确定性测试法
不确定性测试是指使用样本统计量估计样本的不确定性,同时使用估计的模型参数梯度估计模型输出的不确定性[24]。通过样本输入的不确定性,估计模型输出的不确定性,有效评估模型的稳定性,保证该模型适用于目标样本。在该测试过程中,测试方通过对标准样本的各个输入施加一个极小扰动(如10-6),通过中心差值近似估计模型的差分梯度。采用样本数据库建立时得到的样本各个输入方差作为样本不确定性估计值,通过以下公式估计模型各个输出的不确定性Uyi:
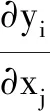
4.4 安全性测试方法
安全性测试方法旨在测试被测AI医疗器械产品的对抗性及稳健性。从AI模型部署至后期使用维护,安全性测试方法用于测试被测产品是否存在安全问题,包括隐私保护测试法、模型推断攻击测试法和模型部署攻击测试法等。
4.4.1 隐私保护测试法
隐私保护测试是指验证产品是否具有涉及隐私提取和泄露的行为,AI医疗器械常通过企业驻场或云端部署等方式为医疗机构提供服务,需保护本地客户端存储的患者隐私信息。在该测试中,测试方通过运行多种隐私风险监测工具对被测AI医疗器械的代码和接口进行全方位分析,对所有可产生数据上传的代码进行上下文分析和命名调用递归分析,查看是否调用了网络权限、系统权限、数据库数据等,检查相关产生网络权限的参数和函数是否有上传隐私数据的行为。针对基于联邦学习的AI医疗器械产品,也应分析部分客户端上传的变动是否能分析出患者的私人信息。当分析结果认为不存在隐私数据泄露时,认为被测试AI医疗器械通过了隐私保护测试。
4.4.2 模型推断攻击测试法
推断攻击是指攻击者从全局参数变化情况推断出某一攻击目标的参数变化情况。在该测试中,测试方通过上传特定测试样本,根据模型输出结果估计模型中的重要参数,并与模型真实参数进行对比。当分析结果得到的参数与真实模型参数差距小于由专家认定的阈值时,认为被测试AI医疗器械通过了模型推断攻击测试。
4.4.3 模型部署攻击测试法
模型部署攻击测试是验证产品能否在模型部署攻击下进行正常工作。模型部署攻击是指对模型加载数据、加载预训练权重文件等过程进行攻击,此类攻击会干扰模型数据的加载从而影响训练和推断过程。通过该测试检查模型能否在部署攻击下进行正常数据和权重加载。
5 AI医疗器械测试数据抽样
数据集是AI医疗器械检验的重要基本要素,用于满足各类临床场景的数据模拟。针对不同的AI医疗器械,应从医学多场景(包括门诊、住院等)、多系统(电子病历、实验室信息管理系统、影像归档和通信系统等)、多模态(影像、视频、体征、生理参数等)、多角度构建专用数据集,同时应满足符合全国或区域流行病学统计的数据分布,包含压力样本及各种实际类别(如疾病类别)等。国内外已有相关标准对AI医疗器械数据集提出了详细要求,如IEEE 2801《医学人工智能数据集质量管理标准》[26]和YY/T 1833.2《人工智能医疗器械 质量要求和评价 第2部分:数据集通用要求》[7],包括数据入库前应进行合理完整的标注、规范管理、保持可扩展性和安全性等。
为保证数据集总体描述不泄露,同时保证AI医疗器械质量检测过程公平、合理、科学、符合临床条件,因此设计数据抽样方法,在测试前独立抽取与临床数据场景同分布的数据集用于AI医疗器械质量测试至关重要。本共识建议结合层次抽样和随机抽样等抽样方法,以保证抽样数据尽可能接近真实分布、涵盖所有种类数据。单次测试集总样本量可由单次测试阳性样本量除以阳性样本比例获得。在测试前,需确定单次测试阳性样本量选取的依据。如该AI医疗器械产品提交时预期用于分类任务,单次测试阳性样本量可采用召回率计算[20]。此外,为满足“压力样本测试法”“错误样本测试法”等一系列特殊样本的测试需求,需额外抽样一定比例的特殊样本加入数据集并标记位置或单独形成测试数据集以供测试使用。
6 小结与展望
本共识总结了AI医疗器械性能评价的通用方法,以促进AI医疗器械测试标准和流程的制订,提高AI医疗器械检验标准化,保障AI医疗器械行业健康发展。本共识对相关检验方法、度量指标提出了建议,并总结了支撑检验方法的数据库建设原则、抽样方法以及数据库对应的配套模型库建设原则和使用方法,具有较强的科学性、可操作性、灵活性。然而,需指出的是,AI医疗器械领域发展迅猛,新器械、新模型层出不穷,实际检测要求更加复杂多样,需要进一步的流程和标准指引。随着对AI医疗器械检测技术的不断探索,包括但不限于安全性、透明性、公平性等,本共识内容将在现有基础上不断更新,帮助业内形成统一认识。
作者贡献:吴健、李静莉、刘士远牵头制订共识框架;应豪超、王浩负责共识内容编制;陈晋泰、徐宇扬负责撰写共识初稿;应豪超、王浩组织协调专家组成员对共识内容进行修订,并组织会议讨论;应豪超、王浩、徐宇扬负责对专家意见进行汇总,并对共识内容进行完善;吴健、李静莉、刘士远对共识全文进行最终审校并形成共识终稿。
利益冲突:所有参与共识制订的专家组成员均声明不存在利益冲突
专家组成员(按姓氏首字母排序):李佳戈(中国食品药品检定研究院),李静莉(中国食品药品检定研究院),刘士远(海军军医大学第二附属医院),陆遥(中山大学),孟祥峰(中国食品药品检定研究院),钱天翼(腾讯医疗健康(深圳)有限公司),史国华(中国科学院苏州生物医学工程技术研究所),唐桥虹(中国食品药品检定研究院),王浩(中国食品药品检定研究院),吴健(浙江大学),吴凯(华南理工大学),颜子夜(广州柏视医疗科技有限公司),应豪超(浙江大学),周少华(中国科学技术大学苏州高等研究院)
执笔者:应豪超(浙江大学公共卫生学院),王浩(中国食品药品检定研究院光机电室),徐宇扬(浙江大学计算机学院),陈晋泰(浙江大学计算机学院)
猜你喜欢
数学物理学报(2022年5期)2022-10-09
医疗装备(2020年10期)2020-06-13
电子制作(2019年16期)2019-09-27
电子制作(2019年15期)2019-08-27
质量安全与检验检测(2019年3期)2019-07-31
质量安全与检验检测(2018年6期)2018-12-28
上海建材(2018年3期)2018-03-20
中华老年口腔医学杂志(2016年3期)2017-01-15
铁道通信信号(2016年8期)2016-06-01
中国洗涤用品工业(2016年2期)2016-02-28
