
可解释机器学习模型预测心脏骤停患者院内死亡风险:基于MIMIC-Ⅳ 2.0数据库
2023-06-13 02:36龚欢欢柯晓伟王爱民李湘民
协和医学杂志 2023年3期
龚欢欢,柯晓伟,王爱民,李湘民
中南大学湘雅医院急诊科,长沙 410008
心脏骤停是成人死亡的主要原因之一,全球每年新增病例达800万至900万,而我国每年约54万人发生心脏骤停且该数据呈逐年上升趋势[1]。心脏骤停后机体血流循环中断,数分钟内即可导致脑缺血死亡,即使进行有效的心肺复苏,短期死亡风险仍较高,而住院期间转归是临床医生及患者家属最迫切关注的问题。准确预测心脏骤停患者院内死亡风险有助于治疗方案的优化、临床决策的制订以及和谐医患关系的建立。由于心脏骤停病因的多样性和病情的复杂性、危重性,传统指标如神经元特异性烯醇化酶(neuron-specific enolase,NSE)、S100β、脑电图、颅脑影像学表现、格拉斯哥昏迷评分(Glasgow coma score,GCS)、急性生理学评分系统Ⅲ(acute physiology score Ⅲ,APSⅢ)在此类患者死亡风险的预测中难度较大[2]。
近年来,伴随计算机性能的巨大突破,医工融合现象逐渐明显,机器学习算法逐步被引入医学领域。Ngiam等[3]研究表明,对于病情严重、临床数据广泛且复杂患者的健康评估,机器学习算法的表现优于传统方法。基于其运行速度快、可高效处理大数据的优势[4],机器学习算法已广泛用于多种危重症患者的预后评估[5-9]。在心脏骤停方面,既往大量研究已证实,基于机器学习算法构建的模型在此类人群神经功能评定、疾病复发风险预测方面表现出良好的性能[10-13]。但此类模型存在“黑盒子”问题,即缺乏临床易于理解的可解释性。2020年Lundberg等[14]建立了Shapley加法解释(Shapley additive explanation,SHAP)算法用以解释任何机器学习模型的输出,其不仅可根据SHAP值正负性反映变量对模型的影响程度,并可通过SHAP值对模型中每个变量的贡献进行量化,突破了机器学习模型难以解释的“黑盒子”问题[15]。迄今为止,基于可解释机器学习模型对公共医疗卫生大数据库中心脏骤停患者住院期间死亡风险预测的相关研究仍较缺乏。本研究基于美国重症监护医学信息数据库Ⅳ(Medical Information Mart for Intensive Care database Ⅳ,MIMIC-Ⅳ)2.0中的数据,开发6种预测心脏骤停患者住院期间死亡风险的机器学习模型,经筛选后采用SHAP算法对最优模型进行解释,以期辅助心脏骤停患者临床决策的制订。
1 资料与方法
1.1 研究对象
本研究数据来源于MIMIC-Ⅳ 2.0(https://mimic.physionet.org/)。该数据库包含2008—2019年贝斯以色列女执事医疗中心4万余例转入ICU的患者临床资料。纳入标准:(1)年龄≥18岁;(2)根据国际疾病分类(international classification of diseases,ICD)诊断为心脏骤停,疾病编码为ICD-9中的“4275”,ICD-10中的“I46”“I462”“I468”“I469”“I9712”“I97120”“I97121”“I9771”“I97710”“I97711”。排除标准:(1)多次(≥2次)住院;(2)住院时间<24 h;(3)孕妇;(4)临床资料不完整者。
本研究以心脏骤停患者住院期间转归为结局指标,并据此将患者分为死亡组和存活组。
本研究人员已完成美国国立卫生研究院开设的“保护人类研究参与者”课程,并获得MIMIC-Ⅳ2.0数据库使用权限(认证号:10264242),可下载数据进行相关研究。
1.2 方法
1.2.1 数据提取与处理
采用PostgreSQL 13提取患者转入ICU后24 h内的临床资料(若多次检测,以首次数据为准),主要包括:(1)转入ICU首日记录:如年龄、性别、生理特征及实验室检查,并计算GCS、器官功能障碍逻辑性评分(Logistic organ dysfunction score,LODS)、APSⅢ、牛津急性疾病严重程度评分(Oxford acute severity of illness score,OASIS)、序贯器官功能衰竭评价(sequential organ failure assessment,SOFA)评分、全身炎症反应综合征(systemic inflammatory response syndrome,SIRS)评分;(2)主要的基础疾病:包括高血压、糖尿病、心力衰竭、肾衰竭等;(3)使用的药物及特殊操作:抗感染药物、血管活性药物、抗凝药物、静脉补液量、尿量、是否机械通气/肾脏替代治疗等。(4)其他资料:住院时间、转入ICU时间等。变量缺失值的处理:若缺失值超过40%,该变量予以删除;否则采用K近邻(K-nearest neighbor,KNN)插补法进行填补。KNN插补法可根据已知的数据点之间的距离,选择K个距离最近的点作为邻近点,然后根据邻近点的属性值进行加权平均,得到缺失值的估计值。
1.2.2 模型构建与评估
基于机器学习算法,构建6种预测心脏骤停患者院内死亡风险的模型,分别为XGBoost模型、轻量级梯度提升机(light gradient boosting machine,LGBM)模型、决策树(decision tree,DT)模型、KNN模型、Logistic回归模型、随机森林(random forest,RF)模型。模型构建时,采用网格搜索法对超参数进行优化。随机将80%的数据划分为一个训练集,同时保留剩余20%的数据作为独立的测试集。采用十折交叉验证法进行模型训练。在训练集中,将训练集数据随机划分为10个小组,其中9个小组用于模型训练,1个小组用于算法的性能评估。将训练集中所有可能的训练小组和测试小组进行折叠组合,重复该过程10次,然后在独立测试集中对得到的10个模型进行评估并计算评价指标均值。评价指标包括灵敏度、特异度、曲线下面积(area under the curve,AUC)、阳性似然比(positive likelihood ratio,PLR)、阴性似然比(negative likelihood ratio,NLR)。选取AUC居前3位的模型,绘制临床决策曲线和校准曲线,进一步评价模型的临床实用性(净收益)及准确性。
1.2.3 可解释性分析
SHAP是一种机器学习解释方法,可用于解释模型预测结果的特征重要性。其基于合作博弈理论中的 Shapley 值概念,采用一种加性方法计算每个特征对模型预测结果的贡献。SHAP算法可为每个特征提供一个解释值,表示该特征对于模型预测结果的影响程度,计算结果不仅可解释单个预测结果的特征重要性,还可用于解释整个数据集的特征重要性分布。同时,该方法可提供一种可视化工具,以直观展示每个特征对于每个数据点的影响程度,以及整个数据集的特征重要性分布结果。此外,SHAP支持对多输出模型和时间序列数据进行解释,并能够处理缺失值和分类特征等常见问题。因此,该方法已成为机器学习领域中重要的解释方法之一,被广泛应用于数据科学、自然语言处理、计算机视觉等领域。本研究采用Python 3.9 软件构建模型并通过SHAP算法对模型进行解释,采用代码“shap.summary_plot”导出汇总图,采用代码“shap.dependence_plot”导出依赖图。
1.3 统计学处理
采用SPSS 25.0软件进行统计学分析。年龄、心率、呼吸频率等符合正态分布的计量资料以均数±标准差表示,组间比较采用t检验;体温、住院时间、SIRS评分等不符合正态分布的计量资料以中位数(四分位数)表示,组间比较采用Mann-WhitneyU检验。性别、合并的主要基础疾病等计数资料以频数(百分数)表示,组间比较采用卡方检验。采用受试者操作特征(receiver operator characteristic,ROC)曲线计算模型预测心脏骤停患者院内死亡的AUC、灵敏度、特异度等指标。采用Python 3.9软件绘制临床决策曲线和校准曲线。以P<0.05为差异具有统计学意义。
2 结果
2.1 一般临床资料
基于MIMIC-Ⅳ 2.0数据库共筛选1996例心脏骤停患者,排除多次转入ICU者253例、ICU住院时间<24 h者233例、临床资料不完整者45例,最终入选1465例符合纳入与排除标准的心脏骤停患者。其中存活组773例、死亡组692例。研究对象入选流程见图1。
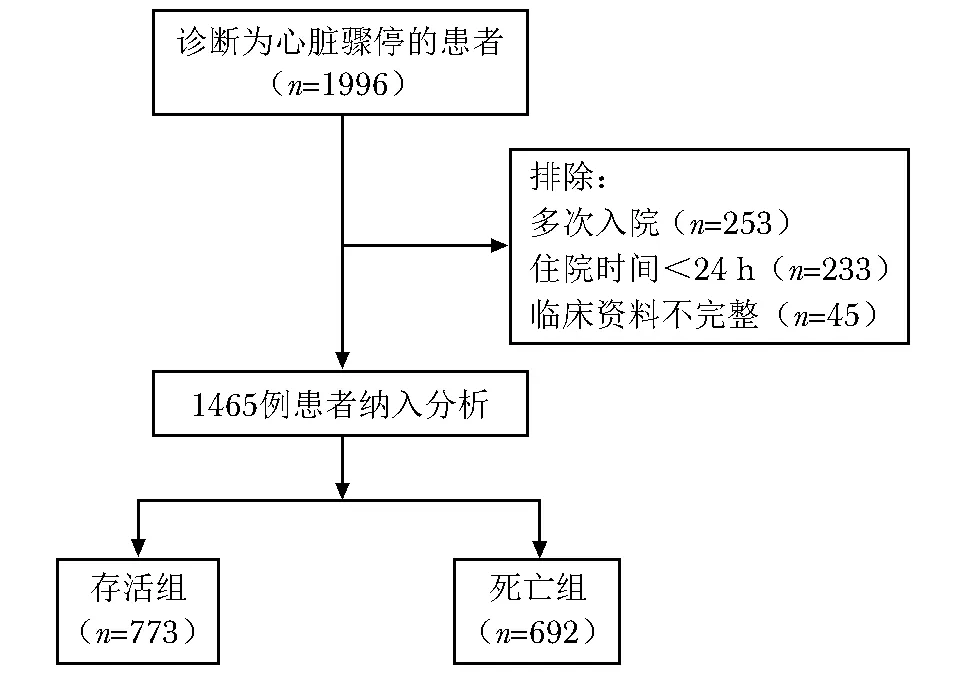
图1 心脏骤停患者入选流程图
死亡组在年龄、心率、呼吸频率、药物治疗、合并基础疾病、多种系统评分以及住院时间等方面与存活组均有显著差异(P均<0.05),详见表1。
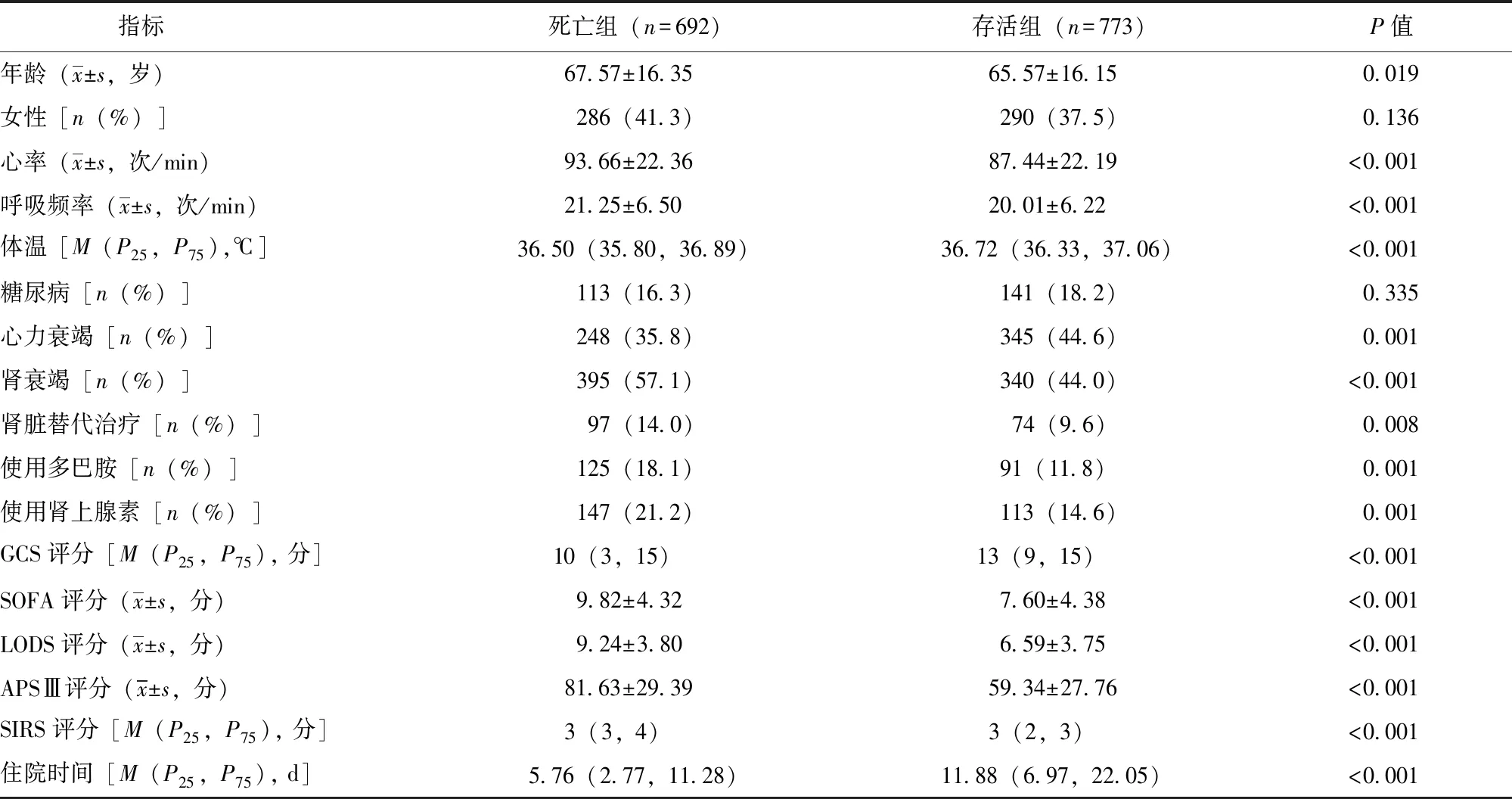
表1 1465例心脏骤停患者基线主要临床资料
2.2 6种预测模型的性能
经筛选,共纳入82个临床特征用于构建6种机器学习模型(每个模型均包括82个相同的临床特征),并基于测试集数据评价了模型性能。ROC曲线显示,LGBM模型预测心脏骤停患者院内死亡的AUC最高(AUC:0.834),Logistic回归模型(AUC:0.809)、XGBoost模型(AUC:0.827)次之,KNN模型、DT模型、RF模型的AUC较低(AUC均低于0.8)。详见图2,表2。
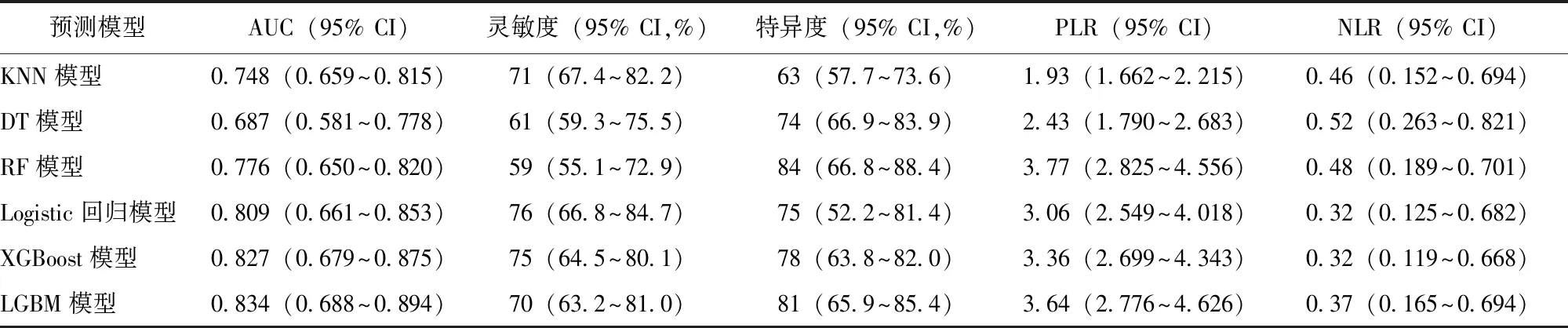
表2 6种机器学习模型预测心脏骤停患者院内住院死亡风险的性能比较
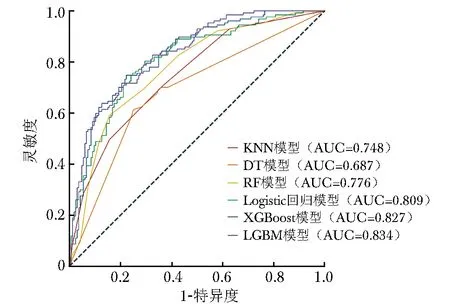
图2 6种机器学习模型预测心脏骤停患者院内死亡风险的ROC曲线图
校准度反映模型预测概率与实际概率之间的差异,该数据越小表示模型预测结果与实际结果越接近,即模型的准确性越高。校准曲线如图3所示,通过计算,LGBM模型的校准度(0.166)较Logistic回归模型(0.178)、XGBoost模型低(0.179)。临床决策曲线可用于衡量机器学习模型在不同决策阈值下的性能表现。临床决策曲线显示,相较于Logistic回归模型、XGBoost模型,若阈值概率(判断结局变量发生的概率)处于5%~90%,则LGBM模型预测患者住院死亡风险时可增加更多的净收益,整体来看LGBM模型的临床应用价值更优(图4)。
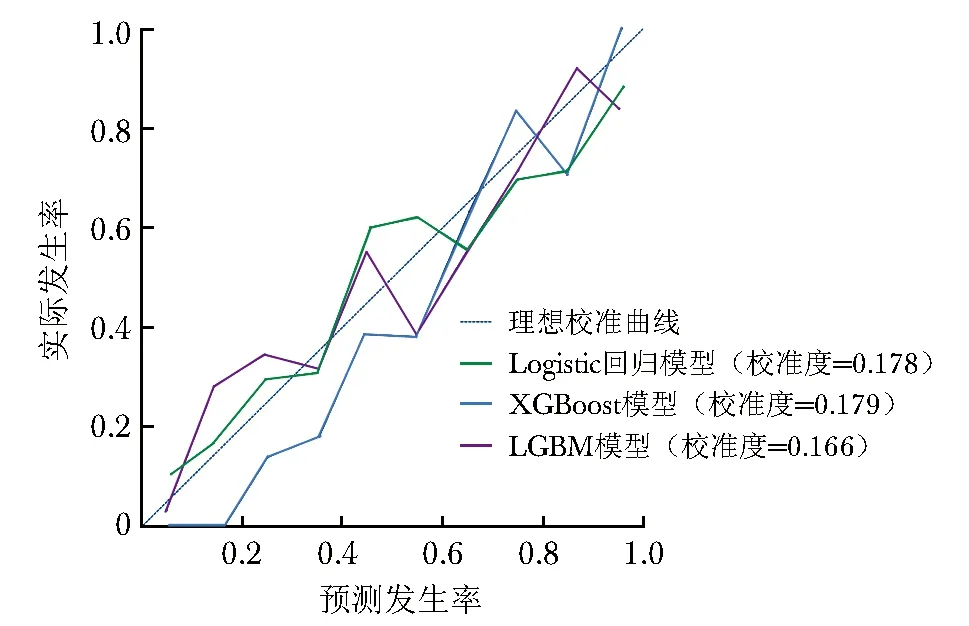
图3 预测效能Top 3模型的校准曲线
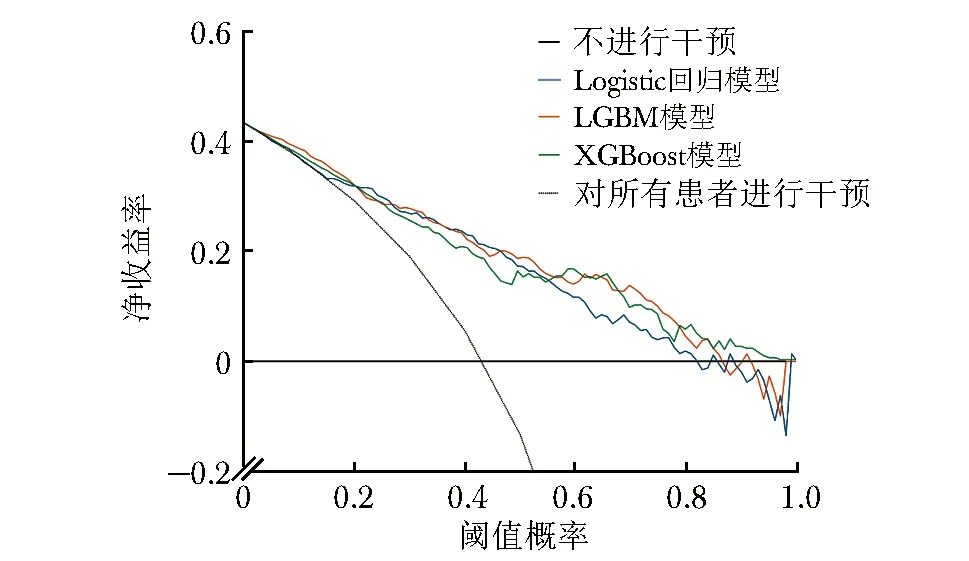
图4 预测效能Top 3模型的临床决策曲线
2.3 模型可解释性分析
采用SHAP算法对LGBM模型进行可解释性分析,并输出SHAP汇总图,汇总图可视化展示了临床特征对LGBM模型输出结果的影响。其中图5A展示了前20个临床特征SHAP值的分布情况:图中每个点表示一个特征,点的位置表示特征的SHAP值,其值代表该特征对模型输出的贡献大小。如果数值为正,则说明该特征对输出结果产生正面影响;如果数值为负,则说明该特征对输出结果产生负面影响。红色表示高值,蓝色表示低值。颜色越深表示该特征对目标变量的影响越强。条形图为按照特征的平均SHAP绝对值大小从高至低进行排列后形成,该排序表示每个特征对于整个模型的贡献程度,SHAP绝对值越大表示该特征越重要,对模型输出结果的影响越大。影响性居前10位的重要临床特征依次为GCS睁眼反应评分、碳酸氢盐水平、白细胞计数、APSⅢ评分、谷草转氨酶水平、GCS运动评分、红细胞分布宽度、体温、钙离子含量、年龄(图5B)。
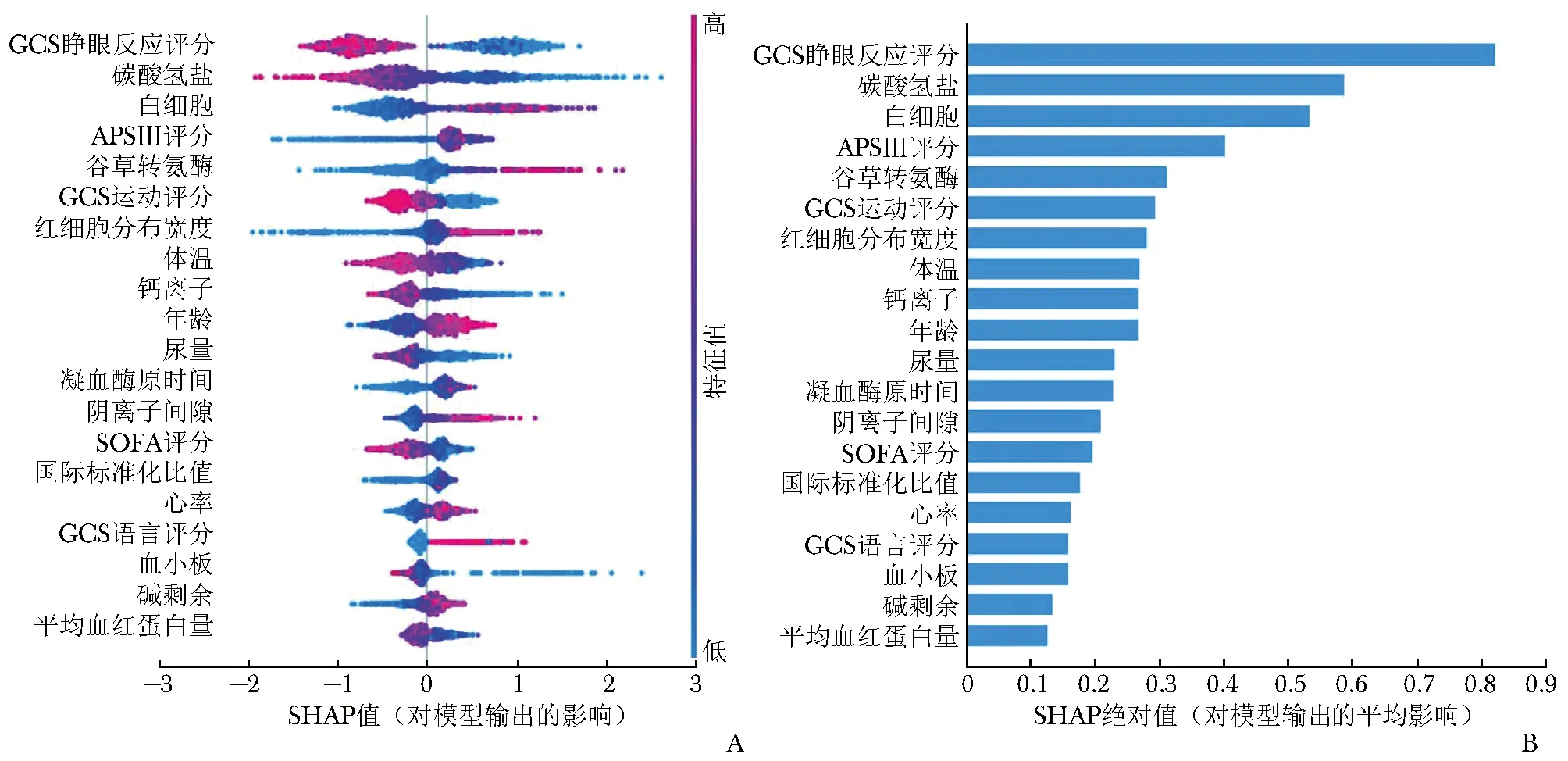
图5 SHAP汇总图
基于SHAP汇总图,进一步导出影响性居前3位临床特征的SHAP依赖图,以解释临床特征对患者死亡风险的影响。SHAP依赖图的纵轴为临床特征的SHAP值,横轴为该临床特征的变化范围,若SHAP值高于零,表示患者院内死亡风险增加,见图6。
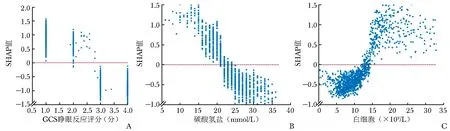
图6 对模型输出结果影响性Top 3临床特征的SHAP依赖图
3 讨论
本研究基于MIMIC-Ⅳ 2.0数据库,构建了6种可预测心脏骤停患者院内死亡风险的机器学习模型,并尝试采用SHAP算法对最优模型进行可解释性分析。结果显示,LGBM模型在心脏骤停患者院内死亡风险的预测中表现[AUC:0.834(95% CI:0.688~0.894)]优于其他模型,且临床实用性强、预测准确性高,综合性能最佳。可解释性分析显示,对LGBM模型输出结果影响性居前10位的临床特征依次为GCS睁眼反应评分、碳酸氢盐水平、白细胞计数、APSⅢ评分、谷草转氨酶水平、GCS运动评分、红细胞分布宽度、体温、钙离子含量、年龄。
3.1 机器学习预测模型构建与评价
机器学习算法可对数据进行深度挖掘,以分析数据之间的内部联系,在大数据的处理中优势凸显。近年来,其在心脏骤停预警及心脏骤停患者神经功能预后预测方面取得了长足进步[12,16-18]。Wu等[16]研究表明,相较于传统预测模型,基于机器学习算法生成的XGBoost模型可提高急性冠脉综合症患者住院期间发生心脏骤停风险的预测准确性。系统评价显示,机器学习模型可更准确地预测院外心脏骤停患者神经功能结局,且在某些特定情况下其预测效能优于传统统计学模型[17]。Mayampurath等[19]基于117 674例院内心脏骤停患者的临床资料比较了不同机器学习模型在此类人群神经功能预后中的预测作用,发现梯度增强算法模型的预测准确性最高。本研究以MIMIC-Ⅳ 2.0数据库中心脏骤停患者的临床资料为基础,经筛选后保留82个临床特征用于建立6种可预测心脏骤停院内死亡风险的机器学习模型,包括KNN模型、DT模型、RF模型、Logistic回归模型、XGBoost模型、LGBM模型。本研究首先通过ROC曲线评估了6种模型的区分度,即早期识别出心脏骤停院内死亡患者的能力,结果显示Logistic回归模型、XGBoost模型、LGBM模型具有较高的识别度,其中以LGBM模型的表现最佳。进一步对3种区分度较好模型的准确性及临床实用性进行评价。相较于Logistic回归模型、XGBoost模型,LGBM模型校准曲线的校准度最低,提示该模型的准确性较高;临床决策曲线示,LGBM模型的整体净收益高于Logistic回归模型、XGBoost模型,提示其临床实用性更佳;且综合灵敏度、特异度等指标后,LGBM模型的整体表现亦更好,提示其在心脏骤停患者死亡风险的预测中更具优势。LGBM模型是一种经过改进的梯度提升集成算法,主要用于分类和回归预测,其可利用决策树迭代训练以提升模型的性能[20],具有准确度高、内存消耗低、训练速度快的优势[21]。既往Rufo等[22]在糖尿病的研究中证实,LGBM模型凭借其训练速度快、预测性能高的优势在糖尿病诊断模型的构建中优势得到凸显。Ge等[23]在一项纳入12 460例脓毒症患者的研究中亦发现,基于LGBM构建的脓毒症相关脑损伤预测模型显著优于XGBoost、DT等常见模型。由此可见,LGBM模型训练速度快、支持大样本量运算的优势可满足心脏骤停患者住院期间死亡风险预测的全面性、广维度要求。综上可知,LGBM模型预测心脏骤停患者院内死亡风险的总体性能较高,可辅助临床早期识别死亡高风险个体,有助于对患者进行个体化管理和精准诊疗的实施。
3.2 模型的可解释性
机器学习预测模型作为临床疾病诊断及患者预后评估的有效工具,由于其形成过程存在的“黑盒子”问题,导致临床医生难以理解模型的原理,进而限制了其临床应用。本研究基于SHAP算法对LGBM模型预测心脏骤停患者院内死亡风险的可解释性进行分析,结果显示对模型输出结果影响性较大的3个临床特征分别为GCS睁眼反应评分、碳酸氢盐水平、白细胞计数,可作为预测此类患者住院死亡率的重要指标。GCS评分是神经系统检查的常用指标,可评估患者昏迷程度,具有简便、快捷、低成本的优势,既往研究证实入院时GCS评分超过4分可预测院外心脏骤停患者的院内生存率[24]。睁眼反应是GCS评分的重要组成部分,蔡兰兰等[25]研究发现,GCS睁眼反应评分≤2分的心脏骤停患者预后明显较≥3分患者差。本研究SHAP依赖图显示,GCS睁眼反应评分≤2分时,心脏骤停患者住院死亡风险显著升高(图6A),进一步证实了上述观点。血液中碳酸氢盐是调节机体酸碱度的重要成分,对心脏骤停时因缺血缺氧造成的酸中毒具有中和作用。Chen等[26]研究发现,院外心脏骤停患者予以适当的碳酸氢钠干预有助于提高生存率。Celik等[27]则研究认为,过高或过低的碳酸氢盐均可增加心脏骤停患者死亡风险。本研究结果符合既往研究结论,发现碳酸氢盐处于20~40 mmol/L时,心脏骤停患者住院期间的死亡风险显著降低(图6B),提示维持适宜的碳酸氢盐水平对改善患者预后至关重要。白细胞是反映机体炎症水平的重要因素,与多种患者住院期间死亡率密切相关。既往研究显示,根据白细胞中的中性粒细胞、淋巴细胞计算的比值与心脏骤停患者不良预后风险呈正相关[28]。本研究亦证实,白细胞>15×109/L时心脏骤停患者院内死亡风险显著升高(图6C),进一步验证了白细胞水平在心脏骤停患者住院期间死亡风险预测中的重要性。
本研究局限性:(1)临床特征相关信息为回顾性收集,可能存在信息偏倚;(2)由于数据库限制或变量存在严重缺失(如体质量指数、脑功能表现分级评分等),可能影响了预测模型性能的提高;(3)部分患者于入院24~48 h内死亡,其入院24 h内首次检查/检验结果可能极差,针对该部分人群,预测模型可能存在一定程度的标签泄露风险;(4)研究数据来源于MIMIC-Ⅳ 2.0,模型的普适性仍有待验证。
综上,本研究基于大型公共医疗卫生数据库,建立了可预测心脏骤停患者住院期间死亡风险的可解释性机器学习模型。结果示LGBM模型在心脏骤停患者死亡风险的预测中更具优势,对该模型影响较大的3个临床特征分别为GCS睁眼反应评分、碳酸氢盐水平、白细胞计数,上述研究结果有助于增加临床医师对机器学习模型的理解度,促进了模型的临床应用,从而早期识别院内死亡高风险人群并优化治疗方案,作出符合患者最大利益的临床决策。
作者贡献:龚欢欢负责数据统计、图表绘制及论文撰写;柯晓伟负责数据整理及论文修订;李湘民、王爱民负责研究设计及写作指导。
利益冲突:所有作者均声明不存在利益冲突
猜你喜欢
新作文·小学低年级版(2022年6期)2022-08-30
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
青年歌声(2019年5期)2019-12-10
电影(2018年8期)2018-09-21
哈尔滨医药(2016年1期)2017-01-15
中国卫生(2016年7期)2016-11-13
第二课堂(课外活动版)(2015年5期)2015-10-21
小学生·多元智能大王(2015年7期)2015-07-03
祝您健康(1989年1期)1989-12-30
