
基于HLS的MobileNet加速器实现
2023-06-08 08:10:28韦苏伦陶青川
现代计算机 2023年8期
韦苏伦,陶青川
(四川大学电子信息学院,成都 610065)
0 引言
作为一种人工神经网络,卷积神经网络被广泛应用于图像、语音识别[1]等各种智能识别系统。随着卷积神经网络的发展,各种各样的网络层出不穷,并且被应用到越来越复杂的场景当中。但随着网络复杂性的增加以及随之而来的庞大计算量,运行卷积神经网络的计算设备也需要更好的性能。传统的CPU 并不适用于矩阵运算占主导的模型训练和推理,GPU 虽然满足这一特性,但对于一些嵌入式设备来说还需要更低的功耗[2]。FPGA 作为可编程逻辑器件,具有功耗低、性能高、灵活性好的特点,因此更加适用于卷积神经网络硬件加速的开发研究[3],Verilog 开发门槛比较高,开发周期相对较长,这极大影响了卷积神经网络在FPGA中部署的普及。
软件工程师们应该更多考虑的是大的架构,而非某个单独部件或逐周期运行,HLS 工具[4]的出现也是源自于此,它是一种代码综合技术,具体是指采用C、C++等高级编程语言进行程序编写,而不是传统的Verilog 语言,这大大提高了FPGA 的开发速度。本文应用HLS 高层次综合工具,基于轻量化的原则选择了Mobile‑Netv2 网络,在赛灵思的FPGA 开发板Kria KV260 上实现了一个卷积神经网络加速器,通过数据的串并转换,充分利用AXI 总线带宽,利用pingpong 缓存技术实现数据的读写与计算的并行操作,同时在卷积计算中使用分组分块计算进一步提高推理的速度。
1 开发平台与IP核的加速策略
1.1 开发平台与卷积神经网络
本文使用赛灵思的Kria KV260 FPGA 开发板作为实验板卡,Kria KV260 是赛灵思专为AI视觉设计的入门级FPGA 开发板。它的设计是一种模块化的设计方式,分为FPGA 板卡以及接口部分,其中FPGA 板卡部分是K26 SoM,它采用Zynq UltraScale+ MPSoC 架构,包含4 核ARM Cortex-A53 处理器,提供256 K 个系统逻辑单元和1.2 K 个DSP 单元。在软件开发环境方面,使用赛灵思的统一软件平台Vitis 以及高层次综合工具Vivado HLS作为编译测试环境。
神经网络模型方面使用的是MobileNetv2[5]。作为经典轻量化网络的MobileNet,自诞生就被广泛应用于工业界。它是一种构造体量小、低延时的网络结构,对于很多移动和嵌入式设备的图像应用都比较适合。MobileNet 是由谷歌团队提出的应用于移动端或者嵌入式设备中的轻量级神经网络,在准确率只有极小幅降低的情况下,大量减少参数与运算量。MobileNet 的特点是提出了深度可分离卷积,其还可被拆分成两个子模块:逐通道卷积(depthwise convolu⁃tion)与逐点卷积层(pointwise convolution)。

表1 KV260板卡资源

图1 KV260开发板俯视图
对于传统卷积来说,若卷积核大小为Dk,数量为N,图像的尺寸为Df,图像和卷积核的通道深度为M,那么对于N个卷积操作来说,总的计算量如公式(1)所示。
而对于深度可分离卷积神经网络来说,其计算量包括逐通道卷积和逐点卷积两部分,如公式(2)、(3)、(4)所示。
其中,CostDW和CostPW分别为
所以可计算出传统卷积与深度可分离卷积的计算量比值,由公式(5)可知,后者的计算效率明显高于传统卷积。
MobileNetv2 是MobileNetv1 的升级版,在MobileNetv1 的深度可分离卷积基础上,新增加了线性瓶颈和倒残差结构,其中倒残差结构如图2所示。

图2 MobileNetv2倒残差结构
在倒残差结构中,先用小的1*1 卷积升维,通过3*3 的逐通道卷积提取特征,最后再使用1*1 卷积降维,呈两头小、中间大的梭型结构。为了提升精度,在倒残差结构中,前两个激活函数使用ReLU6 来代替ReLU,最后使用线性激活函数。
1.2 加速核的整体设计
本文的总体设计基于vivado HLS 高层次综合[6]和PYNQ 平台[7]。由HLS 工具通过C++语言实现卷积神经网络的IP 核,通过仿真和综合之后可以打包zip 核文件,通过vivado 平台导入HLS 的zip 文件进行块设计、布线和整体编译得到硬件平台的.bit 和.hwh 文件,这是PL 部分的设计。PS 端可以使用C++语言在Vitis 中进行主机端的代码编写或者使用Python 语言在PYNQ中进行编写,进而控制数据的输入与输出并与PL 部分进行计算与交互,其数据传输的结构如图3所示。

图3 数据传输结构
首先通过S_AXI_lite 接口将主机端与FPGA相连接,通过读取和写入S_AXI_lite 端的控制寄存器来控制PL 端的行为,一般用来传输控制和状态寄存器以及读写的地址等。对于输入的图像数据、权重和偏置等数据则使用存储器映射接口M_AXI 来进行传输,M_AXI 存储器映射接口可以支持最高4 K字节的突发量,并且具有独立的读取和写入的通道,因此单个接口也可以同时执行读取和写入的操作。在传输读写地址之后,通过M_AXI接口将经过主机端映射存到全局存储器中的数据读取至PL内核中进行计算。
为了加快推理速度,可以进行BN 融合,即将BN 层参数和卷积层参数融合在一起,这样在模型训练之后的推理阶段就可省去BN 层的计算[8]。
考虑到MobileNetv2 结构的重复性,将整个网络分成三个部分来设计:Bottleneck 部分、Bottleneck 之前以及之后的部分。在每个部分也有基础的计算单元,如普通二维卷积、深度卷积、逐点卷积、残差结构以及全剧平均池化层等,本文将这些基础单元单独设计成IP计算核。
加速器总的系统结构块设计如图4 所示,左边是HLS 设计导出的5 个IP 核,中间从上往下分别是ZYNQ 的中心处理模块和时钟与复位信号模块,右边的两列则是传输总线AXI 的相关模块,对块设计进行综合之后得到总的资源使用情况,如图5所示。

图4 加速器整体块设计

图5 综合资源占用情况
1.3 加速器优化策略
1.3.1 pingpong操作
在两个计算模块之间传递数据时,由于前一个模块需要等待下一个模块计算完成才能交付数据,造成了一定的性能损失,所谓ping‑pong 操作是指设置缓冲来进行交替存储,进而实现读、算、写的同步。
数据的分块计算使得多个模块之间的计算满足上述情况,所以设置两个buffer来实现数据的pingpong 操作,buffer 的大小根据不同IP 核进行独立设置。pingpong操作的计算原理如图6所示。

图6 pingpong操作原理
1.3.2 for循环展开
HLS 可以使用Unroll 指令对for 循环进行展开,for 循环在默认状态下是折叠状态的,即在电路里中每一次循环都会分时地使用同一套电路。使用Unroll 可以对for 循环的代码区进行循环体展开,将之前的电路复制多份,实现以资源换取并行的计算逻辑,如图7 所示。Unroll 允许完全展开或部分展开,其中部分展开需要指定循环因子factor=N,即把循环展开N倍来减少循环迭代。

图7 Unroll循环展开原理
1.3.3 多精度计算优化
在IP核中采用的是AP_FIX16的精度进行存储和运算,这就有可能会因为数据精度过低以及数值溢出而产生一些计算误差,并有可能在深度神经网络中持续积累这种误差。于是本文在考虑资源占用的同时,采用多精度数据的方式来避免这种精度的溢出:将输入与输出设置为AP_FIX16的数据类型,然后在计算卷积的过程中,扩大精度来保存临时的数值,并在最后输出时恢复为最开始的精度。
1.3.4 计算分组分块
由于网络模型的参数量比较大,直接使用FPGA 中片上资源来保存每一层所有的数据并不是一个好的方法,所以本文对网络的各个模块用数据分组分块的方式来计算,以降低片内资源的占用,并配合pingpong 操作等优化方式进行并行计算,其过程如图8所示。

图8 分组分块计算
1.3.5 流水线优化
流水线的设计思想是新的输入数据在前面的数据计算完成之前就能提前处理,例如有一个复杂电路,它需要固定的时间周期才能得出最后的稳定结果,我们将其拆解为N个步骤,第一个步骤计算完成后将结果存起来传送给第二个步骤,然后紧接着继续往第一个步骤输入数据,以此类推,用这种方式实现流水线优化的并行处理,如图9所示。

图9 流水线加速时序
1.3.6 加法器树优化
在一次卷积计算过程中涉及到多次加法的运算,这个时候可以采用加法器树的设计方式,将卷积运算单元中的相加过程设计为树形的并行相加模式,进而提高运算效率,可以把时钟周期为N的工作缩小到log2N个时钟周期。
1.4 实验对比
通过实验对比,在不使用并行加速策略时,单核的Arm 设备平均耗时为35.6 s,而本文使用上述的并行优化设计,在KV260 的ZYNQ 平台中的平均计算耗时降低到0.046 s,且功耗并无明显变化,证明该加速器在保证功耗基本不变的情况下,还能充分发挥FPGA 的并行计算优势,提高计算速度。

表2 加速器优化策略性能对比
2 卷积神经网络加速器的设计与实现
2.1 普通卷积层的设计与实现
该部分是神经网络最上层卷积,输入为224×224×3 的图像数据与该层的权重数据。为了提升计算速度,我们对数据流进行了控制,将输入分为三个通道来处理输入数据,使用三条128位AXI总线进行传输。在实际传输时数据为16 位的定点数,这里将24 个16 位定点数打包,同时在AXI 总线上进行并行传输。对于权重、偏置和输出则分别使用一条64 位AXI 总线进行传输。
为进一步提升计算效率,对计算分为两路的pingpong 缓存和计算,如图10 所示。在ping‑pong 操作中进行后续的循环展开计算卷积模块,将输入数据进行如图8的分块卷积操作,对于权重来说,同样在for循环中每次读取出8个filter来进行卷积操作,以达到数据并行计算的目的。

图10 pingpong模块伪代码
经过HLS 仿真测试和综合之后,得到其资源使用报告,如图11所示。

图11 普通二维卷积IP核综合报告
2.2 逐通道卷积与逐点卷积层的设计与实现
Depthwise 是逐通道卷积,是将特征图的每个通道单独使用卷积核来进行卷积操作,获得特征图每个通道的空间特征,并使得到的特征图和输入的通道数保持一致。逐通道卷积的卷积计算采用PIPELINE 指令进行流水优化以及UNROLL 进行循环展开,同时利用pingpong 模块对缓存和计算进行并行处理。在接口方面,将输入设置为两个不同通道来处理输入数据,使用两条64 位AXI 总线进行传输,同样将8 个16 位定点数据打包到AXI 总线上并行传输,权重和偏置则采用一条32位AXI总线进行传输。
由于每次不同层的逐通道卷积尺寸不同,我们将数据分块来实现统一的单元化卷积计算,具体是将数据切分为若干个8×32 的小尺寸,且进一步将32 划分为4×8 的多通道数据,使得不同尺寸的卷积转换为多个固定尺寸的小的卷积,有利用逐通道卷积的加速核的统一化设计。对于不同步长的层,可通过传入的stride 值判断输出特征尺寸是否需要减半。分块卷积的伪代码如图12 所示,W为卷积核的大小,B_r、B_c、B_ch 分别为分块的尺寸以及通道大小,在B_ch处进行PIPELINE 循环展开,使用B_ch 个并行的乘法器和深度为[log2B_ch]的加法器树,每时钟将输入缓存的ch 个通道的特征值与对应的权重值进行乘法计算,然后将计算的数据进行累加,并使用加法器树优化计算,最后通过输出缓存存储结果。

图12 分块卷积实现伪代码
在HLS 中进行仿真和综合后的报告如图13所示。
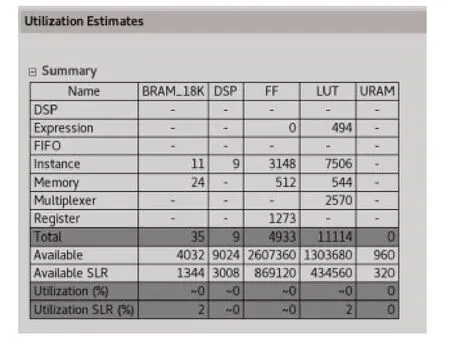
图13 逐通道卷积层IP核综合报告
Pointwise 是逐点卷积,使用和输入特征图通道相同数量的1*1 的卷积核,对特征图深度方面做了加权组合,相当于获得每个点的特征信息,大大减小了总体的计算量。
在具体的实现中,使用两条64 位AXI 总线进行传输,同样将8 个16 位定点数据打包到AXI 总线上并行传输,权重和偏置则分别采用两条64 位AXI 总线和用一条32 位AXI 总线进行传输。计算部分由于该模块存在许多1*1 的卷积,计算得到的通道数相对较多,同样采用了数据分块的思想,利用两层pingpong 嵌套操作来读取权重和特征数据并进行卷积计算。
同样经过仿真以及HLS 综合之后获得资源使用情况的报告,如图14所示。

图14 逐点卷积层IP核综合报告
2.3 残差层、全连接模块的设计与实现
由于已经单独实现了逐通道卷积和逐点卷积,所以这里残差层是指最后的原始数据与经过了残差之后的输出相加的操作,并通过流水展开来进行加速。
全连接模块由全局平均池化层和全连接层组成,本文将其实现为一个IP 核,输入大小为7×7×Channel,输出为最后的分类结果。接口方面直接使用一条16 位AXI 总线进行传输,具体的实现则是将卷积核的值当做分数来模拟求平均的计算,使用加法器树对齐进行并行加速,加载数据时同样利用pingpong 模块来进行缓存和计算优化。仿真和综合之后得到报告,如图15所示。

图15 残差层、全连接层IP核综合报告
3 实验与结果
经过上述的仿真和综合之后,从Vivado HLS 2020.2 中导出IP 核的压缩文件,在Vivado 2020.2 中导入IP 文件并在块设计中进行连线。对块设计进行仿真和综合后得到.bit 和.hwh 文件,利用Python 语言调用PYNQ 软件层的接口进行主机端编程。
数据集采用公开的DeepFashion 服装数据集来进行训练和测试,其中包括运动夹克、毛衣、连衣裙等46种类别,并使用2000张测试图片进行上板验证。分别从计算时间、识别准确率、芯片功耗几个方面来展示在KV260 的FPGA 上推理MobileNetv2 网络的实验结果,并且将该结果分别与网络在CPU 和GPU 计算平台上的推理结果作为对比来分析基于FPGA方法的优势。
3.1 实验测试平台
对于使用FPGA 加速器的方案,使用赛灵思的Kria KV260 作为硬件计算平台;对于直接使用CPU 的方案,使用i7-12th 作为硬件计算平台;而对于使用GPU 的方案,则使用RTX3060作为硬件计算平台。
3.2 实验性能对比

表3 计算速度对比
4 结语
本文基于赛灵思提供的Kria KV260开发板,使用高层次综合工具通过C++语言进行Mobile‑Netv2 的加速核设计,并在使用Python 在PYNQ平台中对主机端进行编程以及验证推理。实验表明,相比单核的Arm芯片,利用FPGA的并行计算设计以及HLS 相关指令对加速核进行计算优化效果明显,且该种方法设计的卷积神经网络加速器在推理Top1 上并无明显下降,在计算速度上相较于CPU 来说提升了2 倍左右,虽然与GPU 相比还是有一定差距,但在功耗方面降低了10倍左右,有着较大的优势。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
自动化学报(2019年6期)2019-07-23 01:18:32
测控技术(2018年6期)2018-11-25 09:50:12
测控技术(2018年8期)2018-11-25 07:42:08
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
地理与地理信息科学(2015年4期)2015-10-13 08:29:16
河南科技(2015年8期)2015-03-11 16:23:52
