
单图像超分辨率多尺度特征融合网络
2023-06-08 08:10:18赵光辉杨晓敏
现代计算机 2023年8期
赵光辉,杨晓敏
(四川大学电子信息学院,成都 610065)
0 引言
单幅图像超分辨率(SISR)是计算机视觉领域中一项重要任务[1],其目标是将低分辨率(LR)图像重构为高分辨率(HR)图像。在军事、医学、公共安全、计算机视觉等领域具有重要的应用前景。近年来,随着深度学习的兴起,基于卷积神经网络的超分辨率模型得到了积极的探索,并在各种基准数据集上取得了先进的性能表现。Dong 等[2]首先提出了基于卷积神经网络(CNN)的方法,并取得了令人印象深刻的效果。随后,出现了更多基于CNN 的SR 方法[3‑7],并表现出了良好的性能。
尽管基于CNN 的模型已经得到充分探索,但现有的方法仍存在一定的局限性。残差学习缓解了随着网络深度增大带来的梯度消失现象[8],单纯的增加网络深度已经难以获得突破性的提升,而且网络深度的增加往往伴随着模型训练的困难和昂贵的计算资源[9]。一些经典的 深 度 网 络 模 型,如EDSR[4]、DBPN[9]和RCAN[3],已经很难通过加深模型层来提高模型性能。因此,如何建立更高效的SR 模型仍然是一个重要的问题。此外,图像的超分辨率是低分辨率图像的上采样任务,很少有研究者研究如何利用下采样特征来提高SR 效果。文献[9]提出了采用迭代上投影单元和下投影单元的纠错反馈机制网络。文献[5]利用迭代下采样产生反馈,实现超分辨率增强。尽管他们必须采用迭代方案来抵抗信息丢失带来的性能下降,但证明了通过特征下采样操作提高SR 性能的可行性。此外,最有效的学习策略尚不明了,很难确定学习到的端到端的非线性映射就是最优解[10],因此,如何找到LR/HR/SR 图像之间潜在的联系,寻求更精确的损失函数是一项有意义的研究工作。
通过特征下采样获取多尺度特征融合是一种有效改善视觉识别性能的方案,而现有的超分辨率模型几乎没有探索特征下采样方法在超分辨率任务中的应用。超分辨率是将低分辨率输入映射到高分辨率输出的过程,所以特征下采样对于图像超分辨率是一种逆直觉行为,另外下采样操作往往伴随着信息损失,因此它很少应用到超分辨率方法中。我们对特征下采样方法在超分辨率中的应用进行了探索,利用Pixel‑Unshuffle 操作降低特征的尺度,同时避免信息损失,并通过多尺度特征融合增强特征表示。探索了一个多尺度特征融合额外约束方案的高效模型。具体而言,我们构建了一个由Pixel‑Unshuffle、最大池化层和3*3 卷积层组成的高效下采样模块(pixel‑unshuffle downsampling block,PDB)来获取多尺度特征;提取浅层多尺度特征之后,利用残差注意力和Pixel‑Shuffle[11]构建的RPUB 模块(RCAB and pixel‑shuffle up‑sampling block)学习深层特征,注意每个RPUB模块都包含一次特征上采样操作,进而获得深层多尺度特征,并通过多尺度特征融合(multi‑resolution feature fusion,MRF)模块将获取到的特征与对应尺度特征融合。最后,参考文献[12]中提出的方法,利用PDB 模块将SR 图像重构为低分辨率图像,该方法可以提供额外的约束条件,减少可能的函数空间。
本文的工作总结如下:
(1)设计了一种高效的下采样模块(PDB)来生成浅层多尺度特征,该模块由Pixel‑Unshuffle操作和非线性层两部分组成。与步长卷积相比,Pixel‑Unshuffle 运算可以在避免信息损失的同时降低特征分辨率,强大的非线性运算可以提取更复杂的局部特征;
(2)利用残差注意力模块和Pixel‑Shuffle 构建了RPUB模块学习深层特征,生成深层多尺度特征,有效增加了网络深度;
(3)提出了一种高效的多尺度特征融合模块(MRF)来融合多尺度特征。浅层多尺度特征表征关注纹理结构信息,深层多尺度特征更关注抽象本质。这种融合方法使本文网络绕过共有的信息,更多地关注特殊的特征,从而实现更具有判别性的特征学习。
1 相关工作
1.1 基于CNN的超分辨率网络
Dong 等[2]首先提出了基于CNN 的SR 算法(SRCNN),并取得了优于传统插值算法的性能。在这项开创性的工作之后,许多更深、更高效的超分辨率模型出现了。Haris 等[9]提出了DBPN,利用传统算法迭代反投影提出了包含多个迭代的上采样层和下采样层形成误差反馈机制,通过不断迭代产生更优的解。Zhang 等[3]研究了一种针对高精度图像SR 的通道注意机制,提出了残差通道注意网络(RCAN),使非常深的网络训练难度降低,但这些方法都有各自的局限性,很难学习到更精确的解。
1.2 Pixel⁃Unshuffle
Pixel‑Unshuffle 是Pixel‑Shuffle 的逆变换,Pixel‑Shuffle 是一种上采样方法,可以替代插值或反卷积的方法对特征图进行放大。主要功能是将低分辨的特征图,通过卷积和多通道间的重组得到高分辨率的特征图。Pixel‑Shuffle 是Shi等[11]提出的基于特征抽取和亚像素卷积将特征映射从LR 空间转换到HR 空间的有效方案。相应的,Pixel‑Unshuffle 是一种降低特征图尺度的下采样方法,它将形状张量(*,C,H×r,W×r)中的元素重新排列为形状张量(*,C×r2,H,W),其中r是一个降尺度因子。图1 展示了Pixel‑Un‑shuffle的过程。通过该操作能得到包含原始特征全部信息的子特征,降低了特征分辨率[13]。
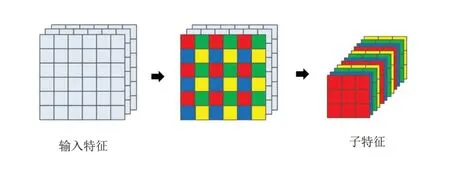
图1 Pixel⁃Unshuffle 操作的可视化
1.3 对偶学习
不同于现有的学习范式,对偶学习方法同时训练两个相互的对偶模型,形成闭环。对偶学习的核心思想是建立对偶模型与原始任务模型之间的双向反馈通道,可以有效地通过信息反馈来完善特征信息,进而不断提升模型的性能。许多人工智能应用场景都涉及两个互为对偶的任务,例如机器翻译中从中文到英文翻译和从英文到中文的翻译互为对偶[14‑15]、语音处理中语音识别和语音合成互为对偶[16]、图像理解中基于图像生成文本和基于文本生成图像互为对偶、问答系统中回答问题和生成问题互为对偶,以及在搜索引擎中给检索词查找相关的网页和给网页生成关键词互为对偶。这些互为对偶的人工智能任务可以形成一个闭环,使对没有标注的数据进行学习成为可能[17]。我们借鉴了双重学习方法,构建了一个双重任务,为我们的SR模型提供额外的约束。
2 模型框架
本文提出了一个增加约束的多尺度特征融合网络(additional constraint in multi‑resolution feature fusion network,ACMF)来处理超分辨率任务,整个网络结构如图2所示,其中虚线矩形框内为对偶任务。提取的浅层特征输入到特征下采样模块,通过不断向下进行获取多尺度特征,多尺度特征融合部分通过多分辨率特征融合进行特征学习,图像重建部分将学习到的特征恢复到图像中,对偶模型将从SR图像重构LR图像,提供额外的损失函数约束。值得注意的是,在输入网络提取浅层特征之前,我们先使用双三次插值算法将LR图像放大到SR的尺度。
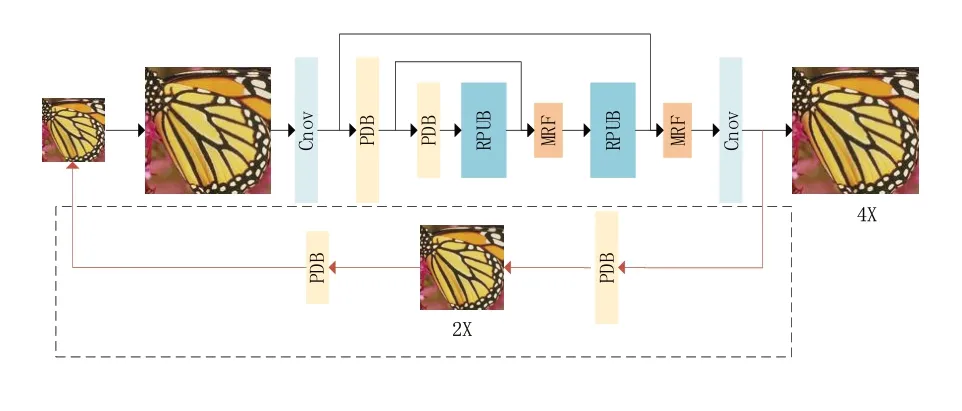
图2 ACMF网络的结构图(x4)
2.1 浅层特征提取和重建部分
在将LR 图像输入网络之前,我们先使用双三次插值算法将其放大到SR尺度。如图2所示,我们利用一个3*3 卷积作为浅层特征提取部分,然后将每个PDB 模块得到的浅层特征输送到MRF模块进行多尺度特征融合。需要注意的是,最后一个PDB 模块的输出直接输入到RPUB 模块学习深层多尺度特征,由于网络最终输出的深层特征已经被放大至SR 尺度(详见2.2 节),我们的图像重建部分只有一个3*3卷积,没有上采样层。重构层将学习到的特征恢复为图像。
2.2 多尺度特征融合
多尺度特征融合部分是网络的主干部分,包括PDB、RPUB 和MRF 三部分。多尺度特征融合过程的特征映射可视化如图3所示。下面分别介绍这些模块的详细细节。

图3 多尺度特征融合过程
2.2.1 PDB模块
PDB 模块的细节如图4(a)所示。该模块由三部分组成:Pixel‑Unshuffle、最大池化层和3*3标准卷积层。先前的研究[18‑19]表明,低分辨率特征可以增强高分辨率表示。PDB 模块作用于浅层特征获得浅层多尺度特征,通过特征融合增强特征表示。
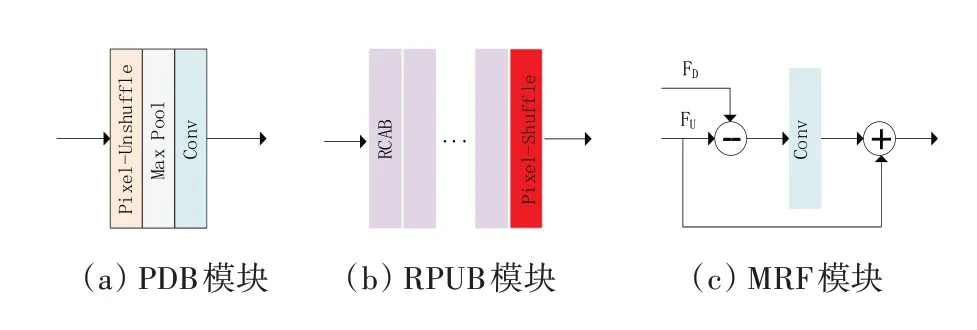
图4 模块结构图
Pixel‑Unshuffle 可以简单理解为Pixel‑Shuffle操作的逆变换。它可以将原始特征变换为多个更低尺度的子特征,与原始特征相比,子特征包含了原始特征的全部信息,同时降低了特征的尺度。与步长卷积或插值相比,Pixel‑Unshuffle 在降低特征分辨率的同时避免了信息的丢失。在Pixel‑Unshuffle 操作之后,我们需要对低尺度子特征进行非线性操作以提取更好的局部特征。参考Sun 等[13]的工作,我们选择最大池化来处理子特征。这个过程描述为
其中:Fout代表输出特征,Pu表示Pixel‑Unshuffle操作,M代表最大池化层(步长为1),Fin表示输出特征。这里Fout是通过非线性运算后得到的低尺度特征,与原始特征的子特征相比,它能表达更突出的局部特征。然后利用标准的1*1卷积层来减少特征通道的数量。
2.2.2 RPUB模块
我们选择残差通道注意力模块(RCAB)[3]作为网络的基本块,使用B个RCAB块堆叠来增加网络深度。通过RCABs得到深层学习特征之后,利用Pixel‑Shuffle 来放大特征,如图4(b)所示,这个过程可以表述为
其中:P代表Pixel‑Shuffle操作,Rb-1代表第(b-1)个RCAB块,Fb-1则代表该块相应的输入。通过以上流程之后,就得到了放大后的深层特征,需要注意的是,每一次的深层特征放大都对应前面的一次PDB。
2.2.3 多尺度特征融合模块(MRF)
我们利用PDB 模块和RPUB 模块分别获得浅层多尺度特征和深层多尺度特征。接下来需要一种高效的融合方法来融合多尺度特征,所以我们构建了多尺度特征融合模块,该模块的细节如图4(c)所示。用FD表示由PDB 模块获取到的浅层特征,用FU表示由RPUB 模块得到的深层特征,这个融合过程可描述为
其中:C表示标准的3*3 卷积层,RUD表示一个源中存在而另一个源中不存在的信息,Fout表示经过融合后得到深度残差特征。该融合模块能使网络绕开不同源特征中的相同部分,更加关注不同特征源中的特殊部分。该模块能提高网络的判别能力,并在融合不同来源特征的同时进行残差学习,与单纯的加法操作和拼接操作相比,有利于提高特征学习能力[20]。
2.3 增加约束的对偶学习
对偶学习方法同时学习两个相反的映射,通过对偶模型间的相互反馈提高初始任务模型的性能。在我们的网络中,初始任务模型的任务是训练SR 模型。相应地,对偶任务是学习从SR 到LR 的下采样映射。参考文献[12]中的方法,我们引入了一个对偶学习任务,从SR 图像重建LR 图像。为了保证与SR 网络的一致性,对偶学习任务通过PDB模块实现下采样映射(见图2中虚线框部分)。
如果重建的SR 图像无限接近真实的HR 图像,则相应的从SR 图像下采样得到的图像应该是近似LR 图像。意识到这一点,就可以通过增加额外约束来减小函数空间,优化训练时的损失函数。训练过程中,除了计算SR 图像与HR图像之间的损失(LP)之外,还引进了LR 图像与对偶模型重建出的图像之间的损失(LD),最终损失函数(L)由LP和LD共同确定。其表达式为:L=LP+λLD。训练中设置λ=0.1。
3 实验结果
3.1 实验环境
3.1.1 数据集和指标
参考前人的研究工作[21‑23],我们选择数据集DIV2K[22]和Flickr2K[4]作为训练数据来训练我们的网络模型。选择以下标准基准数据集进行测试:Set5[24],Set14[25], B100[26],Urban100[27]和Manga109[28]。选 择 了 图 像 评 价 指 标PSNR 和SSIM[29]来衡量重建图片质量。将图像转换到YCbCr空间,并在Y通道上评估图像质量。对于BI 退化模型,我们通过实验分别重建了比例因子为x4,x8的图像。
3.1.2 训练参数设置
我们将成对的LR 和HR 图像裁剪成大小为48×48 的块作为训练数据集,并使用[3‑4]中的数据增广方法。在将LR 图像输入网络之前,我们先利用双三次插值对LR 图像进行上采样,上采样因子为SR 因子。设r= 2 为Pixel‑Unshuffle 中的比例因子。对于4xSR,我们在RPUB 模块中设置B= 30 个RCAB 块,并设置logr(4)个PDB模块和RPUB 模块;对于8×SR,我们在RPUB模块中设置B=30个RCAB块,并设置logr(8)个PDB模块和RPUB模块。采用ADAM优化器更新网络参数权重,指数衰减速率设置为β1= 0.9,β2=0.999,初始学习率设置为10-4,经过106 次迭代的余弦退火学习率衰减到10-7。
3.2 结果对比
为了证明所提方法的有效性,我们将训练模型重建图像的评估结果与以下经典方法进行比 较:ESPCN[11],SRGAN[30],LapSRN[6],Dense‑Net[31],EDSR[4],DBPN[9],RCAN[3],SAN[32],RRDB[33]和DRN[12]。表1 列出了所有与BI 退化模型的对比结果。从结果来看,我们的ACMF网络与以上方法相比,可以取得更好或相当的性能。对于4xSR,ACMF 在Set14 和Manga109上表现最好,SSIM 指标在Set5 上表现出最好结果。特别是对于8xSR,ACMF 在大多数基准数据集上的性能都远远优于其他方法,这也证明了我们的网络具有更强的泛化能力。
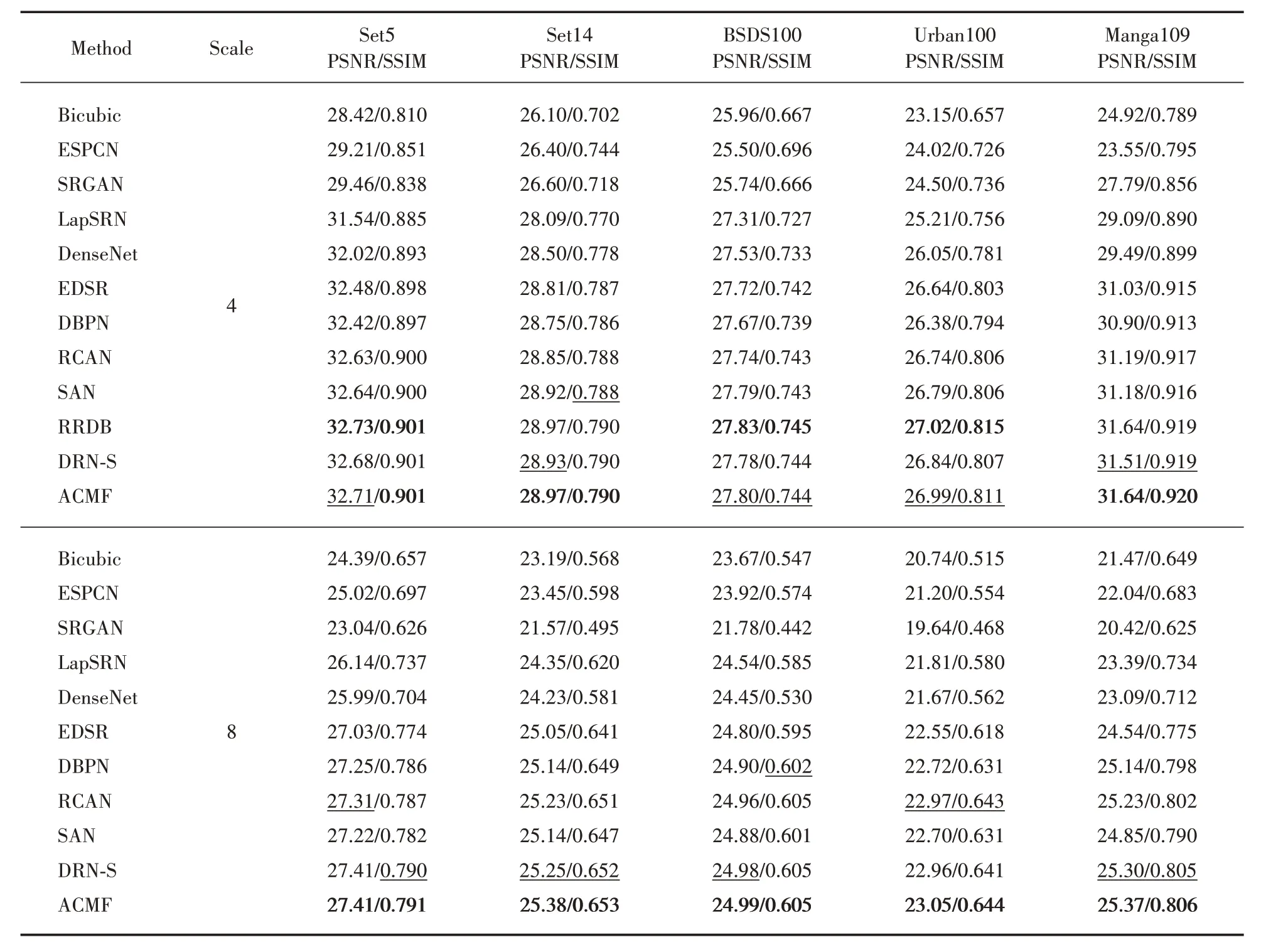
表1 BI退化模型下各基准数据集下的结果比较
对于图像的视觉质量比较,我们将重建的SR 图像与其他方法重建的图像进行视觉效果对比。
图5 和图6 展示了对比结果,对于图像“img002(x4)”,与其他方法产生的图像整体模糊相比,我们的图像具有更高的对比度。对于图像“img015(x4)”,大多数方法都容易产生伪影或生成的轮廓不够清晰。相比之下,本文方法恢复了更准确的细节和更尖锐的轮廓。对于图像“img024(x4)”,本文方法实现了其他比较方法无法恢复的线细节。对于图像“img070(x4)”,可以清楚地看到其他方法生成的图片中城堡线轮廓的失真,而我们的方法恢复了接近真实的线轮廓。此外,在图6中,本文模型重建的SR 图像对于8×SR 具有更清晰的边缘和形状。这些对比结果进一步证明了本文方法可以提取更复杂的特征,并且重建出更接近真实的图像。
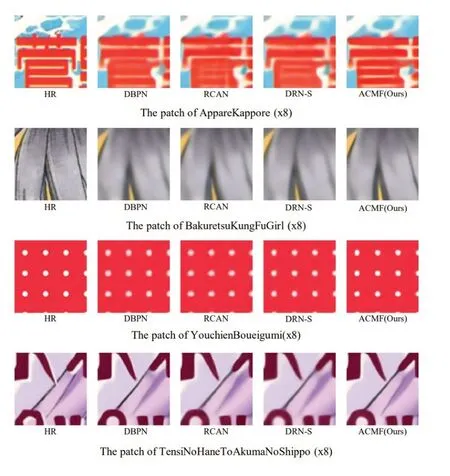
图6 8xSR视觉效果对比
3.3 消融实验
通过进一步的实验证明了所提方法的有效性。为了便于比较,以步长为2的卷积作为PDB模块的基准;以加法特征融合作为MRF 模块的基准,分别研究了PDB 模块和MRF 模块对实验结果的影响。4×SR不同组合消融结果见表2。
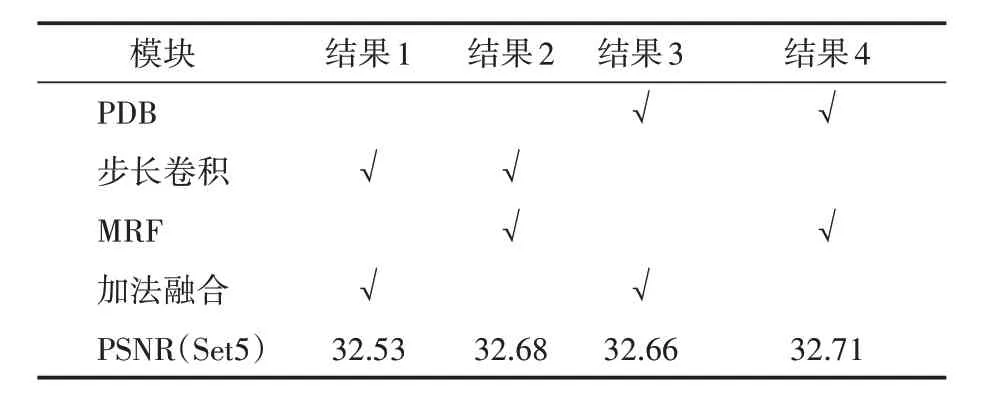
表2 不同模块对网络模型的影响
3.3.1 PDB模块的影响
前节讨论了PDB 相比于步长卷积,既能保证信息的完整性,又能与Pixel‑Shuffle 操作对称互补。从表2 的结果来看,仅使用PDB 模块的模型比基准模型(使用步长卷积和加法特征融合的模型)的PSNR结果高出0.13 dB;使用PDB模块和MRF 模块的模型比仅使用MRF 的模型PSNR 结果高出0.03 dB。这主要是因为PDB 中的Pixel‑Unshuffle 操作可以在降低特征分辨率的同时避免信息丢失,下采样过程保留了相对完整的特征信息。得益于互为逆运算的上下特征采样操作,下采样特征和上采样特征形成信息对称互补。这些结果表明,我们的PDB 模块可以学习到更完整的信息,提高SR的性能。
3.3.2 MRF模块的影响
前面讨论了MRF 有利于提高特征学习能力,并在融合不同特征源时进行残差学习。从表2 的结果来看,仅使用MRF 模块的模型比基准模型(使用步长卷积和加法特征融合的模型)的PSNR 结果高出0.15 dB;使用PDB 模块和MRF 模块的模型比仅使用PDB 的模型PSNR 结果高出0.05 dB。这是因为MRF更关注不同特征源之间的特殊部分,同时进行残差学习,能够提高模型辨别能力,学习到更好的特征。这些结果表明MRF模块提高了特征融合效果。
4 结语
提出了一种附加约束的多尺度特征融合网络(ACMF)。ACMF 框架有效地挖掘了浅层下采样特征信息,并进行了高效的多尺度特征融合,提高了SR任务的性能。我们利用Pixel‑Unshuffle操作来降低特征分辨率,同时避免信息丢失,并通过多尺度特征融合增强特征表示。此外,还学习了获取重构LR 图像的对偶任务,以增加额外的约束来优化损失函数。在基准测试上的大量实验表明,我们的模型表现出相当有竞争力的性能。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
太空探索(2016年5期)2016-07-12 15:17:55
应用数学与计算数学学报(2015年1期)2015-07-20 11:39:06
数学年刊A辑(中文版)(2014年4期)2014-10-30 01:50:38
数学年刊A辑(中文版)(2014年6期)2014-10-30 01:41:24
时代英语·高三(2014年5期)2014-08-26 17:01:17
