
大数据环境下嵌入式可信软件异常识别研究
2023-06-01 13:42江志华赵飞宇
计算机仿真 2023年4期
江志华,赵飞宇
(1. 乐山师范学院电子信息与人工智能学院,四川 乐山 614000;2. 西华大学信息与网络管理中心,四川 成都 610039)
1 引言
现阶段,数字化控制系统被广泛应用于工业及制造业等领域之中[1],智能化仪器仪表也逐渐替代传统仪器仪表,大幅度提升了现代工业智能化水平。数字化控制系统和智能化仪器仪表等均以嵌入式系统为核心[2],其安全性建立在可信嵌入式软件基础上[3],嵌入式软件的潜在风险通常高于个人计算机软件,更易导致系统故障等问题的发生,对嵌入式软件异常识别和监督是保障嵌入式系统安全运行的基础,因此构建科学合理的嵌入式操作内核可信软件异常识别方法尤为重要。
罗森林[4]等人将高斯算法和聚类算法相结合用于软件集合簇的划分,以划分后若干簇内类别比为依据筛选可靠样本,采用后验概率识别边界并在此基础上平衡加权数据,通过平衡优化数据构建嵌入式操作内核可信软件异常识别模型,实现软件异常识别。杨宏宇[5]等人融合长短期记忆网络和变分自动编码器生成混合网络,并在该网络基础上建立嵌入式操作内核可信软件异常识别模型,长短期记忆网络用于提取软件数据时序特征,变分自动编码器用于建模数据分布,通过混合网络模型处理关键特征参数并获取相关异常度量值,引入耦合度方法优化传统的线性加权,量化软件异常状态,实现软件异常识别。仇开[6]等人采用信息熵法赋权嵌入式操作内核可信软件各维度数据,引入改进的加权局部离群因子检测方法初次识别软件数据异常,结合软件运行时上下文信息,二次识别软件异常数据,实现软件异常识别。
虽然以上方法在现阶段取得了较好的应用效果,但是忽略了对软件数据规模较大和复杂度较高导致的“维数灾难”问题的考虑,导致软件异常识别结果出现一定程度偏差。为了解决上述方法中存在的问题,提出嵌入式操作内核可信软件异常识别方法。
2 软件数据降维
大数据技术的发展使数据收集难度降低,但大数据环境下嵌入式操作内核可信软件的数据规模和复杂度大幅度提升,导致大规模高维数据的产生,“维数灾难”问题造成异常识别困难、识别效果下降等问题,因此在嵌入式操作内核可信软件异常识别前需要将数据降维处理。
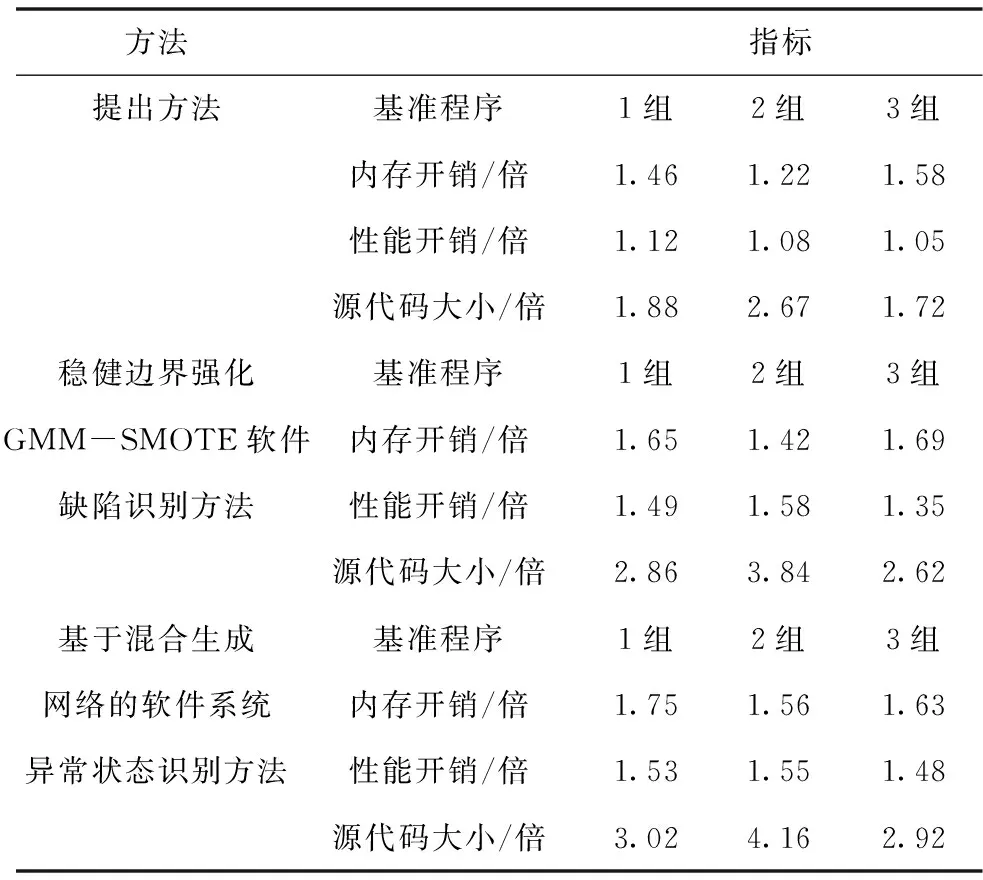
采用深度信念网络降维数据[7],深度信念网络由高斯—伯努利型和伯努利—伯努利型受限玻尔兹曼机堆叠而成[8]。受限玻尔兹曼机由可见层和隐藏层神经元共同构成,总体上为二分图形式。用n表示嵌入式操作内核可信软件数据样本总数,m表示数据维度,则数据集可表示为Xn×m,将Xn×m输入网络模型,最终输出低维数据集Yn×d,其中,d表示降维后数据维度,d< =-uTWg-(b1)Tu-(b2)Tg (1) 当可见层单元为实数且服从高斯分布时,该受限玻尔兹曼机为高斯—伯努利型,对于可见层和隐藏层的每个向量u和g,对应能量函数E(u,g)如下所示 (2) 结合能量函数E(u,g),可得到可见层与隐藏层联合概率密度P(u,g)如下所示 (3) 用〈·〉data和〈·〉mod el分别表示相应参数在数据和模型中估计的期望值,则对于ωij存在 ∇ωijJNLL(W,b2,u)=-[〈uihj〉data-〈uihj〉mod el] (4) 因为获取〈·〉mod el的准确值难度较大,所以借助对比散度算法对〈·〉mod el加以估计,通过t步吉布斯采样获取〈uihj〉mod el的近似值〈uihj〉t,用〈uihj〉k表示经历k此迭代时均值[10],则有 ∇ωijJNLL(W,b2,u)=-[〈uihj〉0-〈uihj〉t] (5) 将待处理数据输入模型的输入层,通过第一个受限玻尔兹曼机处理后映射输入数据至第一个隐含层,将隐含层输出数据作为第二个受限玻尔兹曼机的输入数据,经训练后可生成第二个隐含层,第二个隐含层输出值即为深度信念网络最终输出,即降维后数据。 采用改进遗传算法优化的支持向量机构建异常识别模型[11,12]。支持向量机是依据结构风险最小化原则将实际风险最小化的分类方法[13],目前被广泛应用于分类和回归问题之中。用{(xi,yi),xi∈RN,yi∈{-1,+1}}表示m个降维后嵌入式操作内核可信软件数据样本,i=1,2,…,m,φ(x)=(φ1(x),φ1(x),…φM(x))表示特征映射,ω表示权值向量,b表示偏置,y(x)=sgn(ω·φ(x)+b)表示构造的最优分离超平面,C表示正则化参数[14],ϑi表示松弛变量,则可将二分类的1范数软边界支持向量机描述为优化问题J(ω,ϑ) (6) 引入拉格朗日定理转换式(6)问题为对偶问题Q(τ),用Γ=(τ1,τ2,…,τn)T表示拉格朗日乘子[15],i,j=1,2,…,m,τi,τj∈Γ,yi,yj表示对应最优分离超平面,转换后问题可描述为如下所示 (7) 依据泛函分析原理,若存在核函数K(xi,yi)满足Mercer原理,则该核函数与某一变化空间的内积相对应,即K(xi,yi)=[φ(xi),φ(xj)],因此可转换式(6)为二次规划问题,如下所示 (8) 结合KKT条件可知τi满足下式 τi{yi[ω·φ(xi)+b]-1+ϑi}=0 (9) 得到的结果中非零τi对应样本即为支持向量,依据式(7)可解τi取值,从而得到软件异常识别模型f(x)为 (10) 其中 (11) 式中,σ表示径向基函数扩展常数。在支持向量机中,C和σ为两个可控参数,不同取值对分类器泛化能力具有不同影响。 确定C和σ取值是可信软件异常识别的基础,引入改进的遗传算法搜索软件异常识别模型最优解。传统遗传算法在种群演化过程中交叉概率和变异概率始终为同一取值,导致支持向量机训练时间过长的问题,为此,所提方法采用梯度下降方法改进遗传算法,减少获取全局最优解所需时长。 ①交叉操作 交叉是选取母代染色体中部分基因互相交换生成新染色体的操作。交换第一个母代染色体和第二个母代染色体的⎣2/D」维,D为染色体维度总数。 用t和tmax表示当前迭代次数和最大迭代次数,Pcmax和Pcmin表示最大和最小交叉概率,M表示群体中染色体总数,则执行交叉操作染色体个数Nc和交叉概率Pc如下所示: (12) ②变异操作 (13) (14) ③梯度下降法 (15) (16) 依据式(15)和(16)即可获取到最优搜索方向和最优搜索步长。优化后支持向量机有效优化了软件异常识别结果的精度。 实验选取来自嵌入式操作内核可信软件一段时间内500000条相关日志信息数据,数据涉及10台嵌入式系统主机,包含user、syslog、maill、localal、kern、daemon、cron、authprivi等多层次运行日志,其中反映软件正常运行数据和异常运行数据分别有9166条和4990834条。实验以准确率(Accuracy)、召回率(Recall)、查全率(Precision)和F1值为指标检测所提方法对嵌入式操作内核可信软件的异常识别能力,指标数值越接近100%,则对应方法的异常检测效果越好。用N表示样本总数量,T表示全部样本中被正确识别的样本总数,TP表示异常样本中被正确识别的样本总数,FN表示异常样本中被错误识别的样本总数,FP表示非异常样本中被错误识别的样本总数,则各指标计算方式如下 (17) 其中,准确率能够较为直观表现算法的识别准确性;召回率和查全率能够表现算法的拟合状态,若召回率较低,则说明有大量异常样本被识别为非异常样本;若查全率较低,则有大量非异常样本被识别为异常样本;F1值能够综合表现算法的拟合能力,F1值越接近100%,则算法拟合效果越好,反之效果越差。对所提方法、稳健边界强化GMM-SMOTE软件缺陷识别方法和基于混合生成网络的软件系统异常状态识别方法的准确率、召回率、查全率和F1值加以计算,结果如图1所示。 图1 准确率、召回率、查全率和F1值测试结果 由图1所示,在采用嵌入式操作内核可信软件相关日志信息数据识别软件异常时,所提方法的准确率、召回率、查全率和F1值均在95%以上,说明所提方法对异常状况及非异常状态的识别更为准确。 以3组基准程序为测试对象,对比三种方法应用后与原始代码的内存开销和性能开销之比,实验均在2G内存,Win7的i3PC系统上执行,计算三种方法的性能开销和内存开销,结果如表1所示。 表1 内存开销和性能开销检测结果 表中数据各个指标均为与基准程序相比的倍数。由表中源代码大小和内存开销数值可知,所提方法在基准程序上源代码大小和内存开销均小于文献方法,说明采用所提方法对系统造成的负担较小;由性能开销数值可知,所提方法的性能开销接近于1,说明所提方法与原程序执行时间几乎一致,不会造成异常识别延迟较大的问题,更有利于瞬时错误的发现与改进。 为了解决软件异常识别方法存在的准确率、召回率、查全率和F1值较低问题,提出嵌入式操作内核可信软件异常识别方法,采用深度信念网络降维数据,利用梯度下降法改进的遗传算法优化支持向量机并构建软件异常识别模型,将降维后数据输入模型,完成嵌入式操作内核可信软件异常识别,为嵌入式系统更安全稳定的应用于各个领域中奠定基础。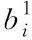



3 嵌入式操作内核可信软件异常识别
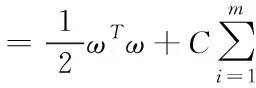











4 实验与结果


5 结束语
猜你喜欢
车主之友(2022年4期)2022-08-27
今日农业(2021年9期)2021-07-28
海峡姐妹(2019年12期)2020-01-14
成都信息工程大学学报(2018年4期)2019-01-23
信息安全研究(2018年12期)2018-12-29
现代电子技术(2018年20期)2018-10-24
现代情报(2018年11期)2018-01-07
新农业(2016年23期)2016-08-16
计算物理(2014年1期)2014-03-11
燕山大学学报(2014年1期)2014-03-11
