
大坝缺陷识别系统设计与实现
2023-05-29 10:19葛从兵严吉皞
软件导刊 2023年5期
葛从兵,陈 剑,严吉皞
(南京水利科学研究院,江苏 南京 210029)
0 引言
水库大坝是我国经济社会发展的重要基础设施,其安全是国家水安全和公共安全的重要组成部分[1]。布设监测设施进行日常观测,可以反映大坝安全性态。但监测设施仅能监测到点,不能全面覆盖水库大坝,存在漏检和盲区。因此,《土石坝安全监测技术规范》(SL 551-2012)和《混凝土坝安全监测技术规范》(SL 601-2013)明确规定水库大坝巡视检查是大坝安全监测工作的重要组成部分,它可以全面、直观地对大坝安全性态进行快速诊断。对于大部分没有监测设施或监测设施损坏的中、小型水库,水库大坝巡视检查对保障水库大坝安全运行尤为重要。
随着水管体制改革,水库管理人员被精简,许多水库将巡视检查工作委托给服务公司,巡检人员为非专业人员,只能做到按规定路径巡视,用巡检仪拍照。大部分水库在大坝上安装了摄像机,可以定期对大坝、库面及其他重要区域拍照。未来,应用无人机对大坝进行巡检是必然趋势,它可以按规定路径飞行,在巡视点上悬停,对巡视部位拍照。上述巡检图像如由专业人员逐一查看,工作量大、时效性差,因此,迫切需要一个能够自动识别巡检图像中大坝缺陷的系统。大坝缺陷识别系统主要采用目标识别方法,目标识别方法包括传统目标识别方法和深度学习目标识别方法[2]。
传统目标识别方法基于颜色、纹理、边缘轮廓等特征,其中模板匹配算法抗干扰能力差,因而局限性较大[3]。2003 年,Fortunato 等[4]将遗传算法与模板匹配算法相结合,提高了目标识别率。2006 年,Wang 等[5]将词袋模型应用到图像识别分类。2010 年,Belongie 等[6]提出基于图像梯度的形状匹配方法,提高了匹配率,但不能实时处理目标图像。近年来,SVM 算法在识别分类领域得到广泛应用,对于小样本数据分类效果较好[7]。
随着卷积神经网络[8](Convolutional Neural Network,CNN)的出现,深度学习[9]备受瞩目。1998 年,Yann 等[10]首次提出LeNet,用于手写数字识别,卷积神经网络性能一直没有明显提升。直到2012年,Krizhevsky 等[11]提 出AlexNet,将Top5 错误率从18.2%降低到15.4%,卷积神经网络重新焕发生机。2013 年,Zeiler 等[12]提出CNN 可视化方法。2014 年,Simonyan 等[13]设计VGG,将Top5 降低到7.3%。2015 年,Szegedy 等[14]提出GoogLeNet,采用Inception 结构,减少了参数量,提高了网络性能。2016 年,He等[15]提出ResNet,允许层与层之间跳跃相连,网络性能获得很大提升。在目标识别方面,2014 年,Girshick 等[16]提出基于区域(Region)的卷积神经网络R-CNN,以候选框与卷积神经网络相结合的方式进行目标检测,取得了突破性进展。2015 年,Girshick[17]提出Fast R-CNN,将分类与检测任务合并,采用多任务损失函数,大幅缩短了网络训练与检测时间。同年,Ren 等[18]提出Faster R-CNN,采用RPN(Region Proposal Networks)与卷积层共享权值方式,进一步提高了图像分类和检测性能。2016 年,Redmon 等[19]提出采用单步(One-Stage)方法的YOLO(You Only Look Once),提高检测速度,满足实时性需求;同年,Liu 等[20]提出SSD(Single Shot MultiBox Detector),其速度比Faster RCNN 快,精度比YOLO 高。2017 年,He 等[21]提出Mask RCNN,用RoI Align 层替换RoI Pooling 层,增加目标轮廓预测分割分支。
本文在研究目标识别和迁移学习[22]基础上,采用TensorFlow[23]深度学习框架,开发了B/S 架构的大坝缺陷识别系统,实现了大坝缺陷识别模型训练和缺陷自动识别。
1 系统设计
1.1 系统框架
大坝缺陷识别系统开发基于深度学习框架Tensor-Flow,应用TensorFlow Object Detection API 库,采用MySQL数据库、Python 语言[24]和Django 框架[25],系统框架如图1所示。TensorFlow 是采用Python 语言的主流学习框架,其核心功能是加速计算、自动梯度、神经网络;TensorFlow Object Detection API 用于多目标检测,并在COCO、Kitti 和Open Images 等数据集上训练好模型,用于迁移学习;Django 是一个开源的、全栈式(full-stack)的Web 应用框架,它采用MTV 设计模式,包含Web 开发所用到的几乎所有模块。
大坝缺陷识别系统可根据需要选择预训练模型,建立大坝缺陷识别模型;上传缺陷样本,对样本进行重构,标注样本中的缺陷,将样本转换为TFRecord 格式文件;采用训练样本对模型进行训练;采用评估样本,对模型进行评估,显示评估结果;根据模型检查点文件,生成模型冻结文件;上传待识别图像,识别图像中的缺陷。系统主要流程如图2所示。
1.2 系统功能
大坝缺陷识别系统功能如图3所示。
模型管理可添加、修改、删除缺陷识别模型,添加或删除模型相应的目录、预训练模型、标签映射文件和配置文件;根据模型检查点文件,生成缺陷识别模型冻结文件,冻结文件存储模型网络结构(计算图)、模型变量及其取值;查询模型的网络节点和操作的属性;下载模型压缩包,包括配置文件、检测点文件和冻结文件,供其他大坝缺陷识别的软硬件使用。
样本管理可将样本的图像文件和标注文件上传至样本库;通过图像水平翻转、垂直翻转、旋转进行样本重构,增加样本数量;采用矩形或多边形标注样本中的缺陷;对样本是否已标注、缺陷名称是否正确进行合规性检查,对缺陷标注位置进行准确性检查;将图像文件和标注文件转换TFRecord 文件,提高模型输入数据速度。
模型训练可修改配置文件中模型训练参数;采用训练样本TFRecord 文件对预训练模型进行训练;显示训练过程参数,包括学习率、分类损失、定位损失、总损失和单步训练时间等。
模型评估可采用评估样本TFRecord 文件对模型进行评估;显示评估结果,包括分类损失、定位损失、AP(Average Precision)、mAP(Mean Average Precision)和评估样本图像。
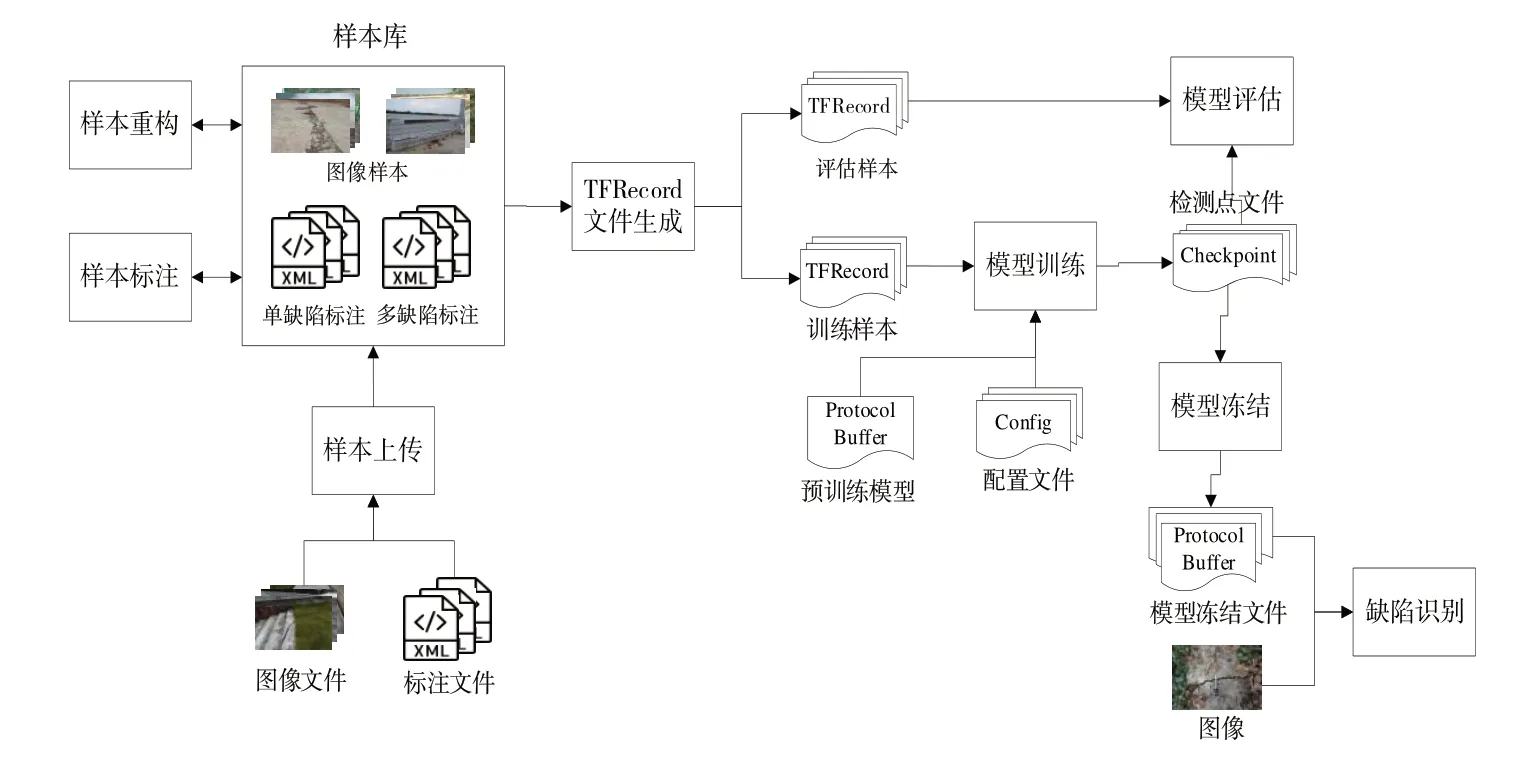
Fig.2 System process图2 系统流程
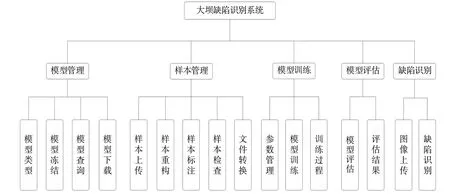
Fig.3 System function图3 系统功能
缺陷识别可上传待识别图像,并应用模型冻结文件,对待识别图像进行缺陷识别,显示图像及其缺陷类型、缺陷方框或缺陷淹膜。
2 关键技术
2.1 目标检测
2.1.1 Faster R-CNN
Fast R-CNN 将整张图像输入至CNN,得到图像的特征层;利用Selective Search 方法得到原始图像中的候选框,将这些候选框投影至特征层;针对特征层上每个大小不同的候选框,对其进行池化,得到固定维度的特征表示;通过两个全连接层,分别用Softmax 分类、回归模型进行检测。
Fast R-CNN 中Selective Search 方法的滑窗(anchor)选择效率低,会产生大量无效候选框。针对这一问题,Faster R-CNN 采用RPN 代替Selective search 方法产生候选框,如图4 所示。RPN 是一个小的全卷积网格,对于任意大小的图像,输出候选框的具体位置以及候选框是否为目标。
2.1.2 Mask R-CNN
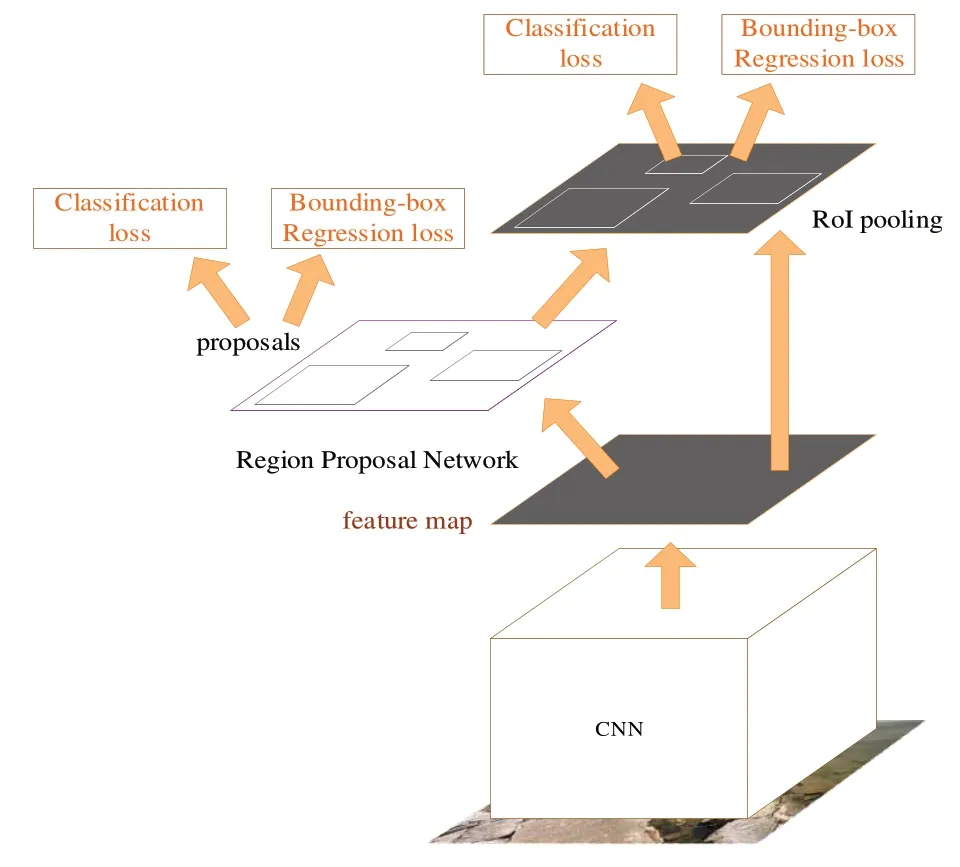
Fig.4 Faster R-CNN framework图4 Faster R-CNN框架
Mask R-CNN 是一个实例分割模型,由Faster R-CNN和FCN(Fully Convolution Nets)组合而成。前者负责物体检测(分类标签+方框),后者负责确定目标轮廓。Mask RCNN 用RoI Align 层替换Faster R-CNN 的RoI Pooling 层,并添加一个含FCN 层的预测分割分支,如图5 所示。与RoI Pooling 层不同,RoI Align 层使用插值算法得到输出坐标,不再进行量化;每个网格中的值也是使用差值算法得到,不再使用max 函数。FCN 是一种流行的语义分割算法,它通过卷积层和最大池化层,将输入图像压缩到原始大小的1/32,在这个细粒度级别进行分类预测;采用反卷积层对最后一个卷积层的特征图进行上采样,将图像还原成原始大小。
2.1.3 SSD
SSD 整合YOLO 的无显式候选框提取和Faster R-CNN中的滑窗机制,在特征空间中融合不同卷积层的特征进行预测。SSD 检测速度较快,检测精度也很高,可以与Faster R-CNN 相媲美,在实时目标检测方面有非常广泛的应用。
在Faster R-CNN 中,滑窗是在主干网的最后一个特征层上生成。而在SSD 中,其他几个高层特征层也产生滑窗。靠前的特征层用于检测小目标,靠后的特征层用于检测大目标。特征层上每个方格是一个特征点,每个特征点可以生成多个比例、多个尺度的滑窗。滑窗经过正负样本筛选,再进行分类和边界框位置学习。
大坝缺陷识别系统从Github 平台tensorflow 项目中下载采用上述3 种目标检测方法的预训练模型:faster_rcnn_inception_v2_coco、mask_rcnn_inception_v2_coco、ssd_inception_v2_coco,针对收集的大坝缺陷图像,采用Object Detection API 的trainer.train 函数对预训练模型进行再训练,得到缺陷识别模型。缺陷识别时,加载缺陷识别模型,采用tensorflow.Session 会话的run 函数识别图像中的大坝缺陷。
2.2 迁移学习
深度学习需要专业人员进行大数据收集和清洗,深度学习的极高识别精度主要来自于对深度卷积神经网络百万乃至千万个参数的训练。要将如此多的参数训练出来,除需要上万,甚至十万、百万以上的大数据外,还要有与之相匹配的超强算力。因此,深度学习存在数据收集困难、数据标注耗时、模型训练耗时等问题,迁移学习是一个非常好的解决方法。
迁移学习是将一个已经在大规模数据集上训练好的模型中的知识迁移到另一个模型,即保留特征提取器不变,在具有相似特征新的数据集上对分类器进行重新训练。由于特征提取器无需再训练,因而极大减少了需要训练的参数,仅需少量数据即可。
收集上万个大坝缺陷样本难度很大,因此大坝缺陷识别系统采用迁移学习方法,从Github 平台Tensorflow 项目中下载预训练模型,然后迁移至大坝缺陷识别模型。预训练模型的训练数据集为COCO(Common Objects in Context)数据集,该数据集包括人、自行车、汽车、猫、狗等多种类型的图像。大坝缺陷识别系统的数据集为大坝缺陷数据集,大坝缺陷数据集需根据预训练模型的输出类型,采用矩形或多边形在缺陷图像上标出大坝缺陷位置。
3 系统实现
3.1 主要功能实现
3.1.1 标注文件转换
系统中有2 种标注形式:矩形标签和多边形标签。矩形标签用于Faster R-CNN、SSD,一个样本的所有矩形标签保存在一个.xml 标注文件里;多边形标签用于Mask RCNN,一个样本的所有多边形标签保存在一个.json 标注文件里(见图5)。
对于矩形标签,首先将所有.xml 标注文件汇集成一个.cvs文件,主要从各.xml标注文件中读取文件名、图像宽度、图像高度、图像深度度、缺陷名称、缺陷框坐标等信息,保存至.csv 文件;然后将.csv 文件和图像文件转换为.tfrecord 文件,主要是采用具名元组方式从.csv 文件中读取样本的所有标签信息,从对应的图像文件中读取图像数据,采用tensorflow.train.Example 函数生成tensorflow 训练样本,以记录形式存入.tfrecord 文件,一个样本一条记录。
对于多边形标签,首先将多个.json 标注文件汇集成一个COCO 数据集,主要从各.json 标注文件中读取文件名、图像宽度、图像高度、图像深度、缺陷名称、缺陷形状和多边形各点坐标,根据预定义标签文件,将缺陷名称转换为缺陷标识,保存至.json 文件;然后将COCO 数据集的.json文件和图像文件转换为.tfrecord 文件,主要从.json 文件中读取每个样本信息及其对应的图像数据,针对每个样本,读取每个缺陷标签信息,计算每个缺陷标签坐标范围,采用tensorflow.train.Example 函数生成tensorflow 训练样本,以记录形式存入.tfrecord 文件。

Fig.5 Mask R-CNN framework图5 Mask R-CNN框架
3.1.2 模型训练
模型训练采用训练样本TFRecord 文件对预训练模型进行训练,得到模型的检查点文件。由于训练时间较长,因此在模型训练完成之前,系统将阻止启动新的模型训练。
模型配置文件主要包括以下5 部分参数:①model:模型主要信息,包括模型架构、特征提取器、图像尺寸调整器等;②train_config:训练参数,包括SGD 参数、输入预处理和特征提取器初始值等;③eval_config:评估参数;④train_input_reader:训练数据集位置;⑤eval_input_reader:评估数据集位置。
模型训练时,先根据预训练模型文件建立网络模型,再从TFRecord 文件中读取训练图像数据,采用Object Detection API 的trainer.train 函数对模型进行训练。模型训练可以采用分布式,由多台计算机共同完成模型训练,以缩短模型训练时间。系统测试时采用单机模式。
3.1.3 训练过程显示
在模型训练过程中和训练结束时,一般可用可视化工具TensorBoard 显示模型计算图的计算过程,以便有针对性地调整训练参数。由于TensorBoard 需另启动一个Web 服务,故本系统采用TensorBoard 事件加速器(EventAccumulator)的scalars.Items 函数从模型训练记录文件中读取计算过程数据,在页面上显示相关参数图形,包括学习率、分类损失、定位损失、总损失和单步训练时间等。主要代码如下:
3.1.4 模型评估
模型评估采用评估样本TFRecord 文件,对模型进行评估。模型评估时,先根据检查点文件,建立网络模型,再从TFRecord 文件中读取评估图像数据,采用Object Detection API的evaluator.evaluate 函数,对模型进行评估。
模型评估后,一般也可用可视化工具TensorBoard 查看评估结果。由于同样原因,该系统采用TensorBoard 事件累加器(EventAccumulator)的scalars.Items 函数从模型评估记录文件中读取数据,在页面上显示相关参数图形,包括分类损失、定位损失、AP、mAP 和评估样本图像,评估样本图像上将标注模型识别出的缺陷类型、缺陷方框或缺陷淹膜。
3.1.5 缺陷识别
缺陷识别根据模型冻结文件,对待识别图像进行缺陷识别。缺陷识别时,首先根据模型冻结文件建立网络模型,从预定义标签文件获取缺陷分类;然后逐个从待识别图像文件读取图像数据,采用tensorflow.Session 会话的run函数进行推理;最后显示识别结果,即模型识别出的缺陷类型、缺陷方框或缺陷淹膜的图像。缺陷识别界面如图6所示。

Fig.6 Defect recognition图6 缺陷识别
3.2 实验与结果分析
从37 份大坝安全鉴定报告收集到120 张裂缝图像和85 张破损图像,用作训练样本,其他类型缺陷图像较少;从196 份水库日常巡视检查报告收集到18 张裂缝图像和5 张破损图像,用作测试样本。典型图像如图7所示。
典型图像标注数据如下,其中size 标签存储图像大小,name 标签存储缺陷名称,bndbox 标签存储覆盖缺陷的方框在图像中位置:

Fig.7 Typical image图7 典型图像
从目标检测类TersonFlow 预训练模型中选择3 个典型预训练模型用于实验,如表1 所示。根据收集到样本和预训练模型,创建5 个缺陷识别模型,如表2 所示。将训练样本上传至系统后,对样本进行缺陷标注和标注文件转换。标注文件转换时,系统随机抽取10%样本,用于模型评估。
模型训练后,模型评估结果如表3 所示。从模型评估结果来看,采用mask_rcnn_inception_v2_coco 的性能优于faster_rcnn_inception_v2_coco,采 用 faster_rcnn_inception_v2_coco的性能优于ssd_inception_v2_coco。
将测试样本上传至系统,缺陷识别结果如表4 所示。对于大坝安全而言,能够自动识别图像上有无缺陷至关重要,至于具体缺陷数量和位置则较为次要,故增加缺陷图像识别率,以考察有缺陷的图像是否被识别出来。从模型测试结果看,对于大坝缺陷识别,采用faster_rcnn_inception_v2_coco 和mask_rcnn_inception_v2_coco 较为 合适,但mask_rcnn_inception_v2_coco 标注难度和工作量稍大。造成缺陷未识别、缺陷误识别的主要原因有:训练样本较少;一条裂缝被识别为多条裂缝;不同破损之间差异大;宽裂缝和某些破损相似,不宜区分。

Table 1 Pre-training model表1 预训练模型

Table 2 Defect recognition model表2 缺陷识别模型
4 结语
本文开发的大坝缺陷识别系统具有模型管理、样本管理、模型训练、模型评估和缺陷识别等功能,可根据需要建立单缺陷识别模型和多缺陷识别模型,所训练的模型可供其他终端使用。实验结果表明,在训练样本较少的情况下,采用faster_rcnn_inception_v2_coco 和mask_rcnn_inception_v2_coco 预训练模型可获取性能较好的大坝缺陷识别模型。为了获取性能更好的大坝缺陷识别模型,在进行模型训练前需做好以下工作:①收集尽可能多的缺陷图像样本;②按缺陷表象进行分类,兼顾相关规范中按缺陷机理和后果分类方式;③缺陷分类要尽可能地提高类内相似度和类间差异性;④提高样本标注中缺陷类型和位置准确性。

Table 3 Model evaluation表3 模型评估

Table 4 Model test表4 模型测试
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
电视技术(2014年19期)2014-03-11
中国三峡(2013年11期)2013-11-21
