
ROS2 多线程执行器上DAG 任务的优先级分配方法
2023-05-22 11:59魏阳杰李宇溪
计算机研究与发展 2023年5期
纪 东 魏阳杰 李宇溪 王 义
1(东北大学计算机科学与工程学院 沈阳 110819)
2(医学影像智能计算教育部重点实验室(东北大学)沈阳 110819)
随着机器人和自动驾驶行业的发展,为了能够实现产品的快速迭代,代码复用性和模块化的需求变得日益强烈.目前行业内已经提出在许多软件平台(中间件)引入了模块化和可适应的功能,从而使构建相关系统变得更加容易.其中,机器人操作系统(robot operating system,ROS)在机器人行业中扮演着至关重要的角色,它以软件模块化和可组合性来加速机器人软件开发的过程.2017 年第2 代ROS2 发布[1],ROS2 提供了强大的实时能力,以支持实时机器人软件.例如,ROS2 采用数据分发服务(data distribution service,DDS)来进行实时数据的端到端交换,并且可以部署在实时操作系统之上.与ROS2 实时性能相关的核心组件是执行器,它协调底层操作系统(operating system,OS)线程中工作负载的执行.ROS2 有2 个内置执行器:一个是按顺序执行工作负载的单线程执行器,另一个是跨多个线程分配工作负载执行的多线程执行器.近些年,有几项工作[2-6]研究了ROS2 单线程执行器的建模和实时性能.结果表明,ROS2 执行器的调度行为与以往实时调度研究中的调度行为有很大不同.而随着现代机器人应用程序变得越来越复杂,通常需要在多线程执行器上实现它们,以充分挖掘多核处理器的计算能力,这就需要新的分析技术.
本文旨在研究ROS2 多线程执行器上运行的以有向无环图(directed acyclic graph,DAG)为特征的并行任务的执行行为,通过配置任务内结点的调度顺序,降低ROS2 上应用程序执行时间.DAG 调度问题是2 个众所周知的NP 难问题的组合:最小完工时间问题[7]和装箱问题[8].其目标是找到一个最短的最长完工时间的调度顺序.然而,在调度并行DAG 任务时,在某个时间点,该任务的许多顶点都符合执行条件,并且数量多于可用核数,因此需要提出一种优先级分配方法来指定这些顶点的执行顺序.但现有的调度算法,如文献[9-12]在这种情况下没有指定相关执行顺序.有的研究者通过求解一个具有分支定界[13-14]的整数规划问题来找到执行顺序,但是无法解决大多数实际规模的问题.而启发式方法(如最高级别优先、最长工作时间、关键路径和随机优先级[15])为任务分配优先级,属于迭代型优化算法.当问题规模很大时,大量的迭代搜索仍然会导致较大的计算耗时.此外,当问题发生变化时,通常需要重新搜索解决方案或调整启发式规则以获得更好的结果,但这会增加计算成本.
最近,工业界和学术界对寻找使用机器学习的自适应数据驱动调度算法的兴趣激增.本文基于自适应学习的思路,针对ROS2 多线程执行器和特殊的调度方式,提出了基于强化学习与蒙特卡洛树搜索(Monte Carlo tree search,MCTS)的优先级分配方法,通过在模拟平台进行反复交互,逐步学习DAG 的拓扑结构和执行状态,以及DAG 中每个顶点的运行时间和硬件资源使用情况.在此基础上,本方法利用策略价值网络在搜索树中逐步探索DAG 中任务执行先后顺序,目的是最小化最大完工时间.
本文的主要贡献包括3 个方面:
1)对ROS2 上任务的执行方式进行了全面和深入的分析和研究,尤其对于多线程执行器的调度机制进行了详细建模.
2)针对ROS2 上特殊的调度机制,本文开发了一套用于模拟ROS2 执行行为的模拟器,用于验证和追踪不同调度方法下程序的执行状态,并可提供详尽的模拟结果.
3)提出了基于强化学习和蒙特卡洛树搜索的ROS2 多线程执行器以DAG 表征的任务优先级配置方法.并对随机生成的测试用例进行了分析,结果表明提出的优先级配置方案相比基准测试方法能够找到更优的方案,进而缩短了任务的总执行时间.
1 相关工作
为了提高ROS[16-17]的实时性能,研究者们已经开展了大量工作.Casini 等人[2]对ROS2 执行器进行了形式化建模和分析,特别是对单线程执行器的调度行为进行了建模,为后续分析奠定了基础.Tang 等人[3]改进了响应时间分析技术并提出了优先级分配方法以优化响应时间.文献[5]通过考虑实际执行时间的差异并进一步探索 ROS2 中的调度特性来改进文献[2]的问题.文献[18]为ROS2 框架提出了一种基于链式结构的新的优先级驱动的调度器,并对提出的调度器进行了端到端延迟分析.目前,针对ROS2 系统的分析,现有工作都集中在单线程执行器的分析上,而对于多线程执行器的调度行为和优先级的设置问题,还没有相关工作研究.本文基于这个原因,开展了ROS2 多线程执行器上的研究分析.
在多线程或者多核平台上提高并行处理能力的主要方式是设计有效的任务调度算法.近年来,研究者对于DAG 系统进行了深入的分析,采用了不同的调度策略,包括全局调度[19-22]和联合调度[9,23-24].例如,Zhao 等人[25]探索了DAG 结构中的并行性和依赖关系,并基于并发提供者和消费者模型提出了优先级分配方法和响应时间界限.Pathan 等人[26]提出了一种利用任务内优先级分配来提高资源利用率的方法,并利用准备时间和结点响应时间的思想来减少任务内干扰.He 等人[27-28]开发并设计启发式方法以确定并行任务的优先级策略,提出了一种计算具有任意优先级分配的DAG 任务响应时限的分析方法.还有很多关于在具有任务内优先级分配的多处理器平台上的调度技术,他们的目标是减少端到端响应时间.文献[15,29]考虑了DAG 静态调度算法的优先级分配.Kwok 等人[30]提出了一种基于任务图的关键路径,将任务图分配给全连接多处理器的静态调度算法.
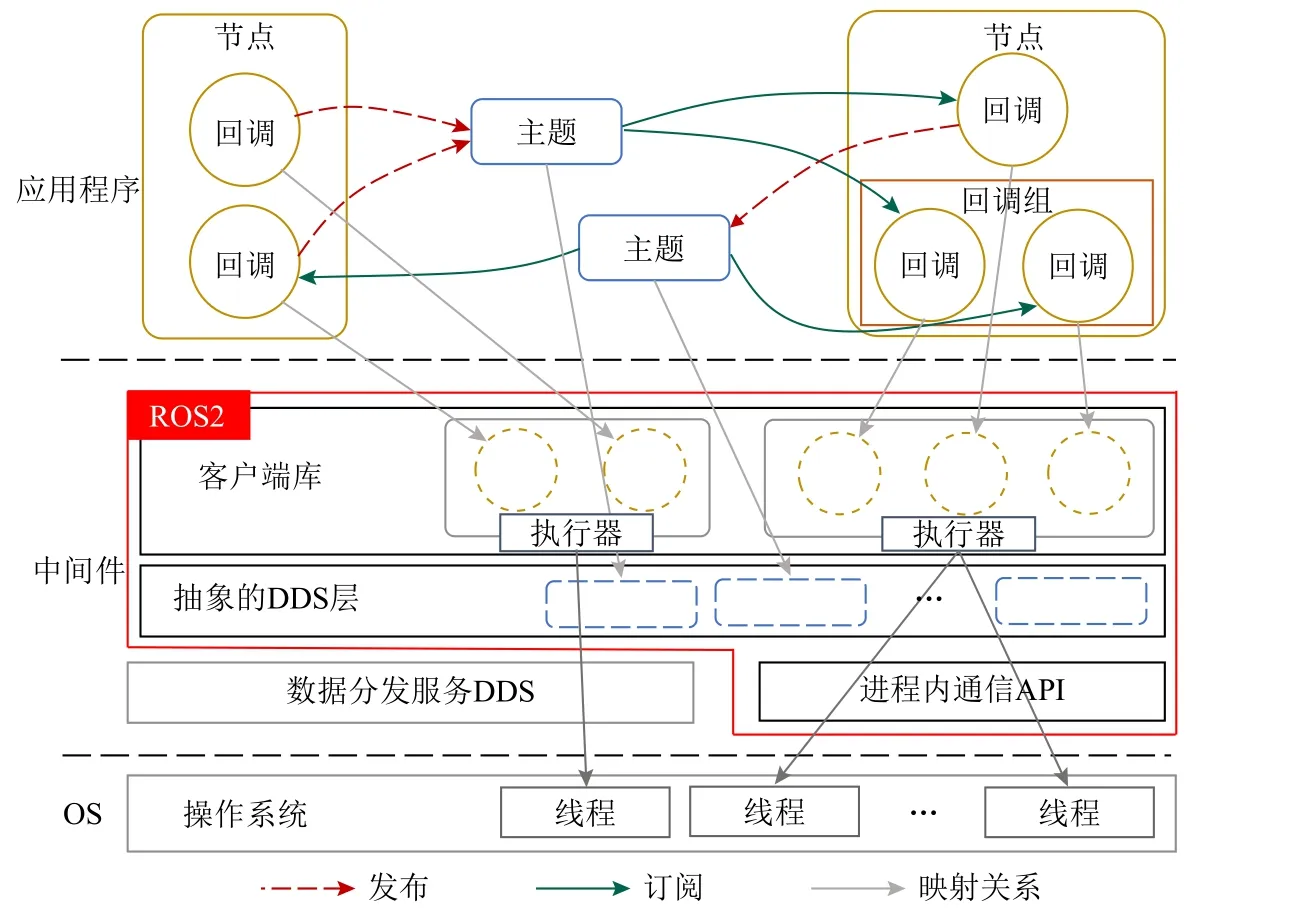
Fig.1 Illustration of ROS2图 1 ROS2 示意图
通过在多个处理器上调度大量任务来最小化执行时长被认为是一个NP 难问题.因此,为了获得接近最优的解决方案,研究者也在尝试使用基于机器学习的启发式方法.例如,文献[31-32]使用机器学习来学习作业结点的近似最优排序.但这些研究没有考虑由DAG 定义的作业之间的依赖性,也没有在分配执行器和其他资源时利用DAG 拓扑.强化学习(reinforcement learning,RL)作为一种重要的机器学习算法,越来越受到关注.强化学习是一个与未知环境反复交互以获得最优解[33]的学习过程.基于强化学习的任务调度,既考虑短期价值,又考虑长期价值.因此,使用强化学习进行任务调度相比启发式等算法,陷入局部最优解的可能性降低.Lee 等人[34]提出了一种使用图卷积网络来处理复杂的相互依赖的DAG 任务结构,并使用策略梯度方法开展了关于优先级的调度策略的研究,以最小化DAG 任务的执行时间.Decima[35]使用强化学习来选择DAG 作业的排序以及执行器的分配.但强化学习方法的好坏受到奖励函数、特征提取、探索过程等多个因素的影响,例如强化学习的奖励函数无法兼顾策略安全性与稳定性,对于给连续任务分配优先级的问题,策略梯度估计的方差会随时间的推移被放大,并且策略的探索与输出也难以预测和约束.本文受强化学习在调度任务的启发,提出了基于强化学习的蒙特卡洛树搜索方法,该方法不仅可以利用训练的策略网络指导搜索过程,提高树搜索的性能,还可以通过扩展树形结构模拟各种可能的未来轨迹进行评估,从而选择更有前景的方向来探索最佳策略,最终达到最小化任务执行时间的目的.
2 背景介绍
本节主要介绍了ROS2 体系结构以及其执行流程和调度机制.
2.1 ROS2 体系结构
如图1 展示了ROS2 的体系结构,ROS2 应用程序通常由节点组成,每个节点都是负责一个单一的用途模块,多个节点相互组合协同,从而简化了代码结构和提高了代码重用性.节点是发布和接收消息的主体,使用发布—订阅范例相互通信:节点在主题上发布消息,通过通信层数据分发服务DDS 将消息广播给订阅主题的节点.节点通过激活回调来处理每个消息,从而对传入消息做出反应.为了部署ROS应用程序,需要将各个节点分布到主机,然后映射到操作系统进程.ROS2 中的执行器用于协调操作系统进程中节点回调的执行.ROS2 提供了2 个内置的执行器:一个是在单个线程中执行回调的顺序执行器,另一个是在多个线程中处理回调的并行执行器.
一个执行器中同一节点内的回调可以属于某个回调组.回调组有2 种类型:互斥或可重入.在运行时,不同类型回调组中的回调根据特定规则进行调度(将在3.2 节介绍).回调也可能属于不同的节点,默认情况下,同一节点中未指定给任何回调组的回调被视为位于互斥回调组中.

Fig.2 The workflow of a thread in a ROS2 multi-threaded executor图 2 ROS2 多线程执行器中线程的工作流
2.2 多线程执行器的调度方法
本节介绍了ROS2 Foxy Fitzroy[36]中多线程执行器下的调度行为,该行为基于对源代码和相关文档的仔细检查[1-2,37],并通过使用跟踪工具 ROS2_tracing[4]进行的大量实验进行了验证.
回调是程序设计者可以处理的最小调度实体.图2 阐述了当回调被激活后,线程调度回调的工作流.执行器中的所有线程都维护一个公共集wait_set,以记录有可用消息的回调.wait_set由互斥锁mutex保护,线程在访问wait_set之前必须持有锁.也就是说,wait_set在任何时候最多只能由一个线程访问和修改;否则,线程将被阻塞,等待锁被释放.当持有锁时,线程通过固定顺序搜索不同类别的回调来寻找要执行的回调.
正如在文献[2-3,5]中介绍的那样,回调的优先级(即执行时选择执行的顺序)由2 个级别决定:1)回调类型.不同回调类型具有不同的优先级,回调分为计时器、订阅、服务和客户4 种类型.总的来说,4 种回调类型的优先级顺序,如图2 所示,依次是计时器、订阅、服务和客户.2)注册顺序.同一类型回调的优先级取决于它们的注册顺序,较早注册的回调具有更高的优先级,这样每个回调就静态分配一个唯一的优先级.在执行回调之前,还要进一步查验是否受到互斥影响.对于可重入模式的互斥组,可以直接进入执行阶段;而对于互斥回调组需要查验标志位can_be_taken_from,以确定是否可以执行.只有当can_be_taken_from=true 时,才能选择属于互斥回调组的回调;否则,线程将跳过此回调并继续查验下一个回调.当选择此组中的回调执行时,标志设置为false,然后在回调执行完成后设置为true.
一旦成功选择回调,线程就会释放锁,并从就绪集中移除.之后,ROS2 通过判断标志位yield_before_execute来决定所选回调是否可以立即执行.如果设置yield_before_execute=true,线程将把处理器交付给操作系统,直到操作系统再次调度它;否则,线程开始以非抢占方式执行回调.在本文中,由于本文内容不关注ROS2 和操作系统之间的交互,本文只考虑yield_before_execute=false 的情况,这也是默认配置.
如果在查询过程中,没有发现可以执行的回调,那么线程将进入更新阶段(此时仍然持有锁).在经过一些列初始化后,如在rcl层和rmw层的句柄重置和实体收集等,之后等待新的消息到来并更新wait_set(如果有可更新的).在等待函数wait_for设置中,还可以通过设置一定的时间限制timeout(默认情况无等待时长约束),即如果到达一定时间仍无法更新到新的回调,则线程将释放锁并变为空闲.
3 任务执行模型
本节将介绍抽象出来的ROS2 多线程执行器的相关行为的模型.
3.1 负载模型
描述并行任务最通用的模型之一是有向无环图模型,该模型允许将任务表示为一系列子任务,这些子任务描述了潜在的并行计算,以及表示子任务的执行顺序的约束情况.本文考虑在具有M个相同核的系统上执行应用程序.程序以有向无环图G=(V,E)的形式表示,其中V表示回调集合,E∈V×V表示受到执行约束的回调对之间的边的集合.每个回调vi执行需要一定的时间,其最坏执行时间(worst case execution time,WCET)用ei表示.一条边(vi,vi′)表示回调vi和vi′的优先关系,即vi′只能在vi执行完毕后才开始执行.没有传入(传出)边的顶点称为源点(汇点).在不丧失一般性的情况下,本文假设G只有一个源点(表示为vsrc)和一个汇点(表示为vsink).在G有多个源点或汇点的情况下,可以添加一个具有零WCET 的虚拟源点或汇点,以符合本文的假设.另外,每个回调属于一个唯一的回调组,本文使用G(vi)表示vi所属组的索引,如果G(vi)=0,表示vi属于可重入组.
路径λ=[vλ1,vλ2,…,vλk]是一个有限的回调序列,其中(vλi,vλi+1)∈E,i∈{1,2,…,k-1}.如果路径同时包含源点和汇点,则称为完整路径.路径长度是路径中结点的执行时间之和,即完整路径中路径长度最长的路径称为关键路径,本文使用L表示关键路径的工作负载,即仅关键路径中结点的WCET之和.在执行过程中,G会释放无限序列的实例.周期 T是 G的2 个连续实例的释放时间之间的最小间隔.DAG有一个相对的最后期限D,在时刻r释放的G实例必须在时刻r+D之前完成,也就是说最长路径的工作负载之和L≤r+D,在本文中主要考虑了满足这种约束条件下的任务执行模式,称为可调度的G.L的负载之和为本文优化的DAG 总执行时间,即最长完工时间makespan.
3.2 调度模型
在运行时,G中源点后的回调实例首先被释放,而G中的其他回调实例将在前任实例的输入消息可用时才被释放.被释放的回调vi的实例能否执行还取决于回调组的情况:
1)vi属于互斥回调组.vi所在的回调组中没有回调(包含vi)的实例正在执行时,表示处于准备就绪状态;否则,vi将被阻塞.
2)vi属于可重入回调组.vi在释放后始终处于就绪状态.
执行器维护一个就绪集合Ω,它记录了可以执行的就绪回调.执行器可以选择Ω中的就绪回调进行执行.从上面的描述中可以看到,同一互斥回调组中回调的回调实例不能并行执行,而可重入回调组中回调的多个回调实例可能并行执行.另外,回调实例准备就绪后不会立即添加到Ω.相反,只有在Ω中没有符合条件的回调且线程空闲时,才能将就绪回调实例添加到Ω.此外,当更新Ω时,首先设置Ω=∅,然后将所有当前就绪的回调实例添加到Ω.即在同一时刻(通常称为轮询点)Ω中加入了一组回调实例.
在执行阶段,M个线程逐个选择Ω中符合条件的回调实例,并以非抢占方式执行.而选择合格回调实例的顺序取决于它们的优先级.每个回调都有一个固定且唯一的优先级,其所有实例都继承该优先级.当选择执行回调实例时,回调实例将从Ω中删除.
图3 阐述了使用2 个线程在ROS2 系统上运行DAG 程序执行的示例.该程序由7 个回调组成(源点和汇点不考虑在内),圆形符号表示程序中的回调,箭头表示回调之间的依赖关系,其中回调v4,v6,v7属于同一互斥回调组,其他回调属于可重入回调组.所有回调的优先级和最坏情况执行时间如图3(b)所示.向上菱形符号表示DAG 实例释放时刻,释放周期为6,其中表示第i个回调的第j个实例.我们通过设置2 种不同的优先级来展示优先级对DAG 任务执行的影响,其中优先级1 的结果如图3(c),优先级2 的结果如图3(e).对应的每个轮询点的Ω中的回调实例如图3(d)(f)所示,集合的内容由任务依赖关系和线程更新Ω时刻所决定.例如,在时刻 2执行完后线程T1空闲,且此时Ω为空,则线程T1将就绪的和更新到Ω.比较2 种优先级配置的运行结果可发现,尽管只是对v2和v4优先级进行了互换就导致了整个系统由可调度变成了不可调度的情况,观察图3(c)(e)可发现,DAG 中最长路径的一次实例的执行时长也由 6变成了9.原因就是在时刻2,在优先级2 的配置下,v2先于v4执行,又因互斥组的原因导致了v6和v7的延后执行.这说明合理设置优先级以及DAG 中回调的约束关系对程序运行和执行时长的重要性.

Fig.3 Example of task scheduling under ROS2 multithread executor图 3 ROS2 多线程执行器下的任务调度示例
4 提出的方法
本节描述了优先级配置方法,包括马尔可夫决策过程(Markov decision process,MDP)模型和带有RL智能体的MCTS 算法.图4 说明了整体架构及其主要组件.该方法遵循通用的强化学习框架,关键组件为环境状态、动作、奖励和模拟环境.智能体按照典型的Actor-Critic 算法执行训练,并结合MCTS 方法计算得到最优方案.执行过程从初始化状态开始,根据跟踪的文件数据1 获取下一时刻的环境状态,并以简明的形式提取状态特征2,并反馈到RL 智能体以生成可行的动作结果3,最后,计算该动作的奖励4并返回给智能体进行训练.由于大多数调度任务的执行性能指标只能在整个回调序列被调度后才能计算,因此在奖励计算期间,本方案将每个单独动作的中间奖励保持为0,只计算完成回调序列中的最后一项回调后的最终奖励.一旦安排了整个DAG 回调执行序列,本方案就会建立一个包含优先级特征的执行轨迹.
4.1 马尔可夫决策过程
本节从马尔可夫决策过程的角度讨论了在ROS2系统下DAG 的执行方式.一般来说,MDP 具有一组状态、一组动作、奖励函数和状态转移概率.
1)状态.首先,本文方法封装了当前时刻t、核的工作状态以及回调间的互斥约束关系.为了通过顺序选择来调度DAG 任务,状态还需要关于随时间演变的子任务分区的信息,即处于该状态下满足当前依赖关系的就绪回调集合Ω和已经执行完的回调集合.而这些状态信息是通过模拟器按ROS2 的执行策略和DAG 约束条件,随时间变化模拟得到的.
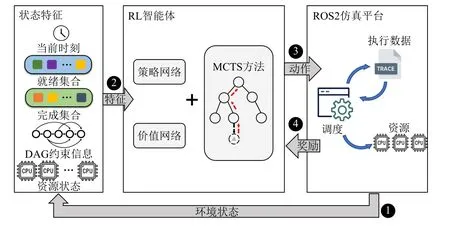
Fig.4 Frame diagram of reinforcement learning-based priority assignment method图 4 基于强化学习的优先级分配方法框架图
2)动作.动作行为表示时刻t在就绪集合Ω中选择一个回调进行执行.本文将拥有N个回调程序的动作,选择操作a编码为一个离散空间{0,1,…,N},当a=m时表示选择第m个回调,如果满足约束条件,则将回调挂载到空闲核上,此动作并不占用实际的执行时间.如果a=0,则表示对挂载的回调进行处理,将占用核上资源并产生执行时间.
3)奖励.为了学习得到最合理的优先级配置,以最小化DAG 工作流完成时间作为最优策略奖励参数.我们将程序完成时的总累积奖励设置为负的工作流完成时间,即vi的-makespan.而在任务未完成时的动作选择奖励为0.因此,最大化强化学习模型的回报相当于最小化工作流完成时间.奖励函数的定义为
4)转移概率.在MDP 中,过渡状态是确定性的,即对于一个状态和动作,下一个状态是没有随机性的.这是因为调度操作不执行任务,它只影响调度策略并更改任务的排列(优先级顺序).当采用强化学习处理大规模组合优化问题时,这种设置很常见[38].
4.2 MCTS 过程
MCTS 是一种最佳优先搜索算法,由Coulom 在2006 年引入[39],用于在围棋中找到好的决策,但也可用于不同的MDP,如集群资源调度[35]、生产调度[40].使用MCTS 可以有效地搜索决策的空间,MCTS 由4个部分组成:选择、扩展、模拟和回溯.在本文中,我们使用训练好的策略网络来指导MCTS 过程,即在搜索过程中使用经过强化学习训练的智能体给出最有希望的动作,在缩小搜索空间的同时使MCTS 可以更有效地找到任务的执行顺序.具体步骤有5 个:
1)选择阶段.在算法的初始阶段,蒙特卡洛树中只有一个初始结点.这一步从根结点开始,逐树探索下一个最有希望的子结点,以保持探索和利用之间的平衡.一般情况下,使用上置信界(upper confidence bound,UCB)作为每个结点优劣的评价标准,即
2)扩展阶段.如果选择最有希望的结点不是终止结点,则通过一个未探索的动作来扩展搜索树.在这个阶段,可用的子结点是就绪任务队列中的一组动作或处理动作(a=0).
3)模拟阶段.在经典的MCTS 方法中,扩展后的搜索树中添加了新结点,选择一个新结点作为模拟的开始,其中移动一般由随机策略选择,并进行快速模拟到游戏结束及获得结果.然而,大量的决策维度导致搜索算法开销很大,无法获得有希望的结果.所以本文使用经过训练的强化学习智能体来替换随机策略.
4)回溯阶段.在模拟结束时,根据模拟的makespan结果,从叶结点到根结点的访问路径上的所有结点,使用反向传播方式更新当前动作序列的值.对于每个结点,该值被更新为当前负makespan和新makespan的最大值,表示为
5)迭代预算.MCTS 算法重复上面4 个步骤来增加搜索树的规模,直到计算资源耗尽.最后,MCTS 将选择导致最高可能值的操作.受文献[41]启发,迭代次数被设置为资源预算.值得注意的是,本方案还为每个级别的预算设计了一个适当的衰减函数,在DAG 调度问题中,当向下遍历搜索树时,搜索空间呈指数下降.因此,可用的决策减少,然后随着树的深入,将迭代的上限设置为
其中di是树的当前深度,binitial和bmin分别表示初始和最小迭代预算.
5 实验和评估
本节评估了提出的优先级分配方法,通过生成随机任务集和使用离散事件模拟器模拟多线程执行器的执行来评估本文设计的方法.
5.1 实验参数
该实验通过随机生成的DAG 任务进行评估,任务集和测试集生成遵循在各种现有可调度性分析论文中使用的相同程序,例如文献[42-43],以便在可调度性测试和模拟结果之间进行比较.生成各种DAG的具体输入参数有:1)回调数N;2)线程数M;3)DAG的长度L;4)结点的最大出度maxout;5)结点的最大入度maxin;6)DAG 的形状参数 α;7)DAG 的正则性参数β;8)任务执行时间e;9)DAG 中的互斥组个数上限g;10)互斥组中任务个数上限u.在实验中,这些参数的值是从给定的集合中均匀采样得来的,其中N∈{5,10,20,30,40,50};M∈{2,3,4};maxout=3;maxin=3;α ∈{0.5,1.0,1.5} ;β ∈{0.0,0.5,1.0,2.0};每个回调的最坏执行时间e在[1,100]随机采样;互斥组个数在{0,1,2,…,g}随机选择,g=N/10;互斥组内回调个数在{1,2,…,u}随机选择,其中u=(N/10)+1.通过上述设置,可以获得大量具有不同属性的任务流,从而防止对特定调度方法的偏见.
Actor 网络和Critic 网络使用相同的配置,即宽度均为128 网络的隐藏层神经网络.使用了tanh 激活功能.softmax 函数为Actor 网络的输出层中的动作空间生成一系列概率.受近端策略优化(proximal policy optimization,PPO)[44]良好性能的影响,本文应用PPO来训练调度器.Actor 网络和Critic 网络的学习率分别设置为3×10-4和1×10-3,折扣率γ=0.99,裁剪范围系数为0.2.训练数据和测试数据来自由随机参数生成的1 000 个DAG.在MCTS 实现中,本文使用预先训练的PPO 智能体作为指导,binitial=100和bmin=10.
所有实验都是基于Python 3.6.13,torch 1.7.0 和gym 0.19.0 环境实施,并在具有128 GB 内存的 Intel®Xeon®Bronze 3104 CPU@1.70 GHz 和具有CUDA 11.1 NVIDIA geforce rtx 3090 GPU 的ubuntu 18.04.6 LTS 系统上进行训练和测试.
5.2 基准测试方法
对于本文的多线程执行器模型,DAG 任务在M个同构处理器上执行,则核数M和回调数N设置为数据规格,并包含在测试数据集中.也就是说,在测试阶段,从数据集采样的每个DAG 任务被配置在M个处理器的系统上运行.本文的模型旨在最小化单个DAG 任务的完成时间.因此,本文通过模拟器环境测量了各个调度方法的最长完工时间并将其用作评估指标.比较的方法有:
1)随机方法(Random).在动作空间中随机采样动作,在存在空闲核的情况下,如果采样的动作无效,如受到回调间约束关系和互斥关系而无法执行,则重新选择动作.如果发现此时没有空闲的核挂载该就绪回调,则将当前动作变更为0.
2)短任务优先方法(shortest job first,SJF).该方法首先在就绪集合Ω中根据最坏执行时间按降序对回调进行排序,然后选择第1 个回调作为下一个动作.同随机方法,如果发现此时没有空闲的核挂载在就绪回调,则将当前动作变更为0.因为增加了核的状态判断,所以本方法相比于随机选择动作的方法,在对空闲核的利用上会表现得更有优势.
3)PPO.使用PPO 算法训练的网络,根据环境状态选择下一个可执行的回调.
4)没有PPO 的MCTS(MCTS_N).为了验证强化学习对MCTS 调度程序的关键影响,分别对有和没有PPO 智能体的MCTS 进行了消融实验.
5.3 模拟环境
为了评估本文提出的方法,本工作需要搭建与执行环境交互的平台.虽然可以直接以ROS2 真实系统作为交互环境,但由于ROS2 的性能依赖于系统的调度策略且受限于系统资源状态,如果直接在ROS2系统中训练会存在训练时间长以及参数测量不准等潜在问题.为了解决此问题,本文实现了一个基于ROS2 执行策略的gym[45]调度模拟器,模拟器对于DAG 调度方法至关重要,为智能体和环境之间的交互提供平台.该模拟器可以模拟M个同构处理器的ROS2 系统执行行为,并精确计算每个DAG 任务按给定优先级顺序下的最大完工时间.回调序列和执行器的设置参数被输入至模拟器,以模拟ROS2 处理平台如何执行回调.在初始化步骤,初始化回调序列、执行器状态和就绪回调集合等.然后,按优先级对就绪回调进行排序.模拟器从就绪回调逐个选择回调实例,并根据所选回调实例的约束情况决定执行步骤,如挂载到相应的空闲核上并记录此时状态等.最后,模拟器根据核上回调的执行时长,并按降序排列,更新模拟时间以确定下一个调度时刻,并更新核的工作状态.模拟器重复上述过程,直到所有作业都分配给执行器,最后算出DAG 任务的最大完工时间.
5.4 实验评估与分析
图5 展示了优先级分配方法与基准测试在不同DAG 尺寸下随机选取的100 组测试集数据的最长完工时间情况.表1 展示了增加核数区分后的实际平均结果.


Fig.5 Performance of makespan in different DAG sizes图 5 不同DAG 尺寸下的最大完工时间性能
从表1 可以看出,本文所提出的优先级分配方法明显优于其他所有方法,且随着回调数N和核数M的增加效果更加明显.其中由于随机方法选择动作的不确定性,对核的利用不佳,执行时长最长且波动范围最大.SJF 直接在就绪集合选择回调,再选择执行动作,所以整体来说核的利用率更高,运行时间相对较短.PPO 的执行时间略高于SJF,这是因为虽然本文对DAG 约束关系进行了表征,但仍然在某些情况不能完全涵盖,如虽然当前存在空闲核,但由于互斥原因,在Ω集合中选择的回调无法执行,这给PPO的训练过程带来了偏差,而且随着核数减少,复杂的约束关系将变得更加明显.

Table 1 Average makespan with Different Methods表 1 不同方法的平均最长完工时间
加入MCTS 后,MCTS_N 和MCTS 方法的最长完工时间makespan好于Random,SJF,PPO 三种方法.通过消融实验,也说明了PPO 在帮助MCTS 快速搜索相关结点的前提下,带来了更好的计算结果,并且随着结点数越多,核数越多,可选择的动作越多,可操作的空间越丰富时,其效果越明显.除此之外,本文以核数为4 的ROS2 模拟系统为例,对提出方法的求解过程带来的时间开销进行了测量.本文随机选取了测试集中DAG 结点数为30 的50 个组进行测量,其中PPO 测试的平均makespan为238.59,平均时间开销为843 ms.对不同资源限制配置下的MCTS 和MCTS_N 计算时间也进行了测量,如表2 所示.
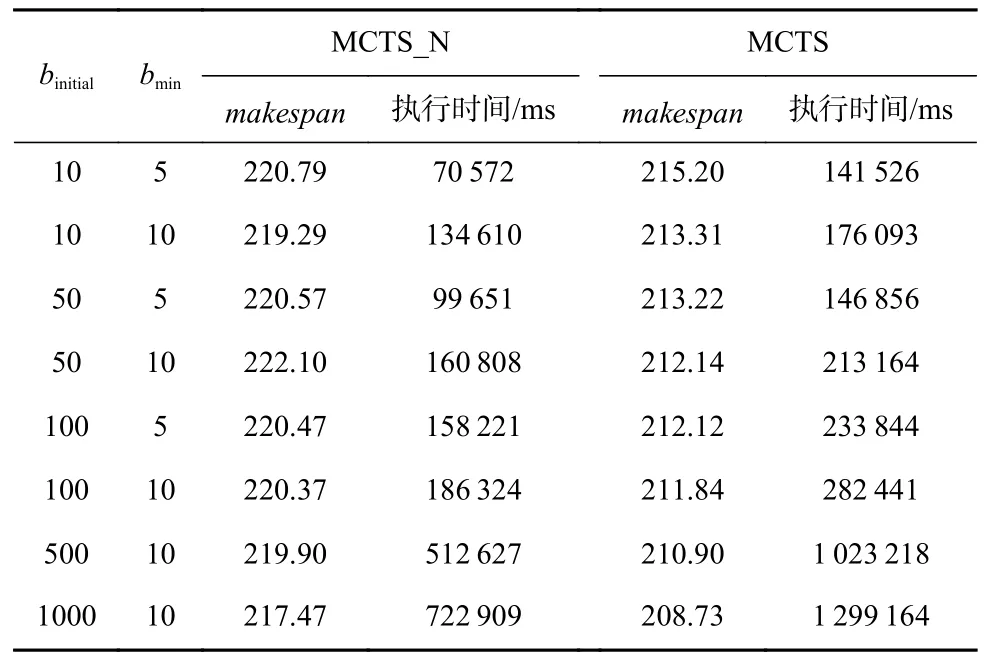
Table 2 Execution Time Analysis for MCTS Method表 2 MCTS 方法执行时间分析
从表2 可以看到MCTS 在PPO 的帮助下,虽然同样配置下的运行时间要高于MCTS_N,但makespan的结果要优于MCTS_N,而且随着binitial的增加,makespan效果趋于更好的结果.横向比较这2 种方法,MCTS在binitial=10和bmin=5时就能达到很好的效果,运行时间和运行结果都好于在更高迭代预算情况下MCTS_N的结果.这说明引入的神经网络有效地指导了MCTS的探索过程,提高了MCTS 的执行效率.
本文还对2 个核10 个回调的DAG 进行了针对性的案例研究:在设置优先级时,由于ROS2 采用的是在轮询点一次性放入多个就绪回调到Ω的方式,并且只有Ω为空时线程才能再次更新的机制.优先级设置的分析可以简化为只考虑在2 次更新阶段之间的时间段能够进入Ω的回调的优先级关系.但需要注意的是,不同的优先级设置,会导致Ω中的回调在更新点时刻并不是一成不变的.通过实验观察到的现象是:1)如果Ω中回调均为可重入模式,本文提出的方法会倾向于将执行时长最长的回调置于较高优先级,然后依次类推.其目的是尽量防止执行时间较长的回调被阻塞.2)如果Ω中存在属于互斥组的回调,方法会倾向于将属于回调组的且执行时间最长的回调置成较高的优先级.尽量将可能带来后续影响的任务提前执行,以提高并行的概率,防止如图3(e)所示的互斥影响.虽然在本文中没有进一步研究这种规律的深层原因,但这些发现可以通过形式化的方式进行进一步论证,这样不仅可以使基于强化学习的方法更具有可解释性,也可以从实践角度作为一个较好的优先级设计技巧去简化复杂的调度分析过程.在未来工作中,我们将进一步分析和解决这个问题.
6 结 论
本文提出了一种基于强化学习和MCTS 的在ROS2 调度机制下的优先级配置方法,即设计回调的执行顺序.该方法通过使用PPO 训练策略价值网络指导MCTS 方法寻找最佳的方案以最小化DAG 形式表示的回调集合的最大完工时间.基于这种方法,在深入研究了ROS2 执行模式前提下,搭建了模拟平台,并通过实验验证了本文所提出的方法相比基准测试方法更具优势.在未来的工作中,将专注于优化所提出的方法和进一步扩展,例如使用图卷积神经网络表征环境状态,支持单个DAG 扩展到支持多个DAG 的分析,优化DAG 中回调组的设置.
作者贡献声明:纪东提出了算法思路和实验方案并撰写论文;魏阳杰和王义提出指导意见;李宇溪修改论文.
猜你喜欢
测控技术(2018年12期)2018-11-25
数学物理学报(2018年1期)2018-03-26
制造技术与机床(2017年9期)2017-11-27
环球市场(2017年36期)2017-03-09
自动化学报(2016年8期)2016-04-16
自动化学报(2016年5期)2016-04-16
电子设计工程(2014年12期)2014-02-27
计算机工程与科学(2013年2期)2013-06-07
吉林建筑大学学报(2012年3期)2012-08-15
苏州市职业大学学报(2010年1期)2010-01-29
