
时间和能量敏感的端—边—云车路协同系统资源调度优化方法
2023-05-22 11:59郑莹莹周俊龙申钰凡丛佩金吴泽彬
计算机研究与发展 2023年5期
郑莹莹 周俊龙,2 申钰凡 丛佩金 吴泽彬
1(南京理工大学计算机科学与工程学院 南京 210094)
2(处理器芯片全国重点实验室(中国科学院计算技术研究所)北京 100190)
智能交通系统是未来交通运输系统的发展方向,它将智能传感与控制、大数据、物联网等先进技术与嵌入式软件融入到交通系统中,为用户提供了更好的服务[1-2].在智能交通系统中,车辆通常受到计算和存储资源的限制,导致其数据处理能力较低.然而,随着信息技术的发展,诸多新兴技术(例如辅助安全驾驶、红绿灯车速引导和道路情况提醒等)对于计算和存储资源的需求变得越来越大,车辆终端越来越难以有效支持这些技术[3].一种常用的解决方案是将这些任务提交至云(即任务卸载至云数据中心),借助云服务器的强大计算和存储能力来应对智能车飞速增长的技术需求.
云数据中心虽然具有足够的资源支持计算密集型应用,但是云服务器通常部署在远离车辆的地方.网络传输引起的响应时间久问题会严重降低车辆任务卸载到云的效果,这对于时间敏感的强实时任务是不可接受的.因此,为缓解该问题,研究者们提出采用边缘计算技术,在车道附近的路边单元部署计算资源(即边缘服务器).由于车辆终端与路边单元之间传输距离较短,可有效降低传输时延,适合处理时间敏感的强实时任务[4].然而,为了降低基础设施成本,在路边单元部署的边缘服务器计算和存储能力有限,一些计算密集型任务仍需卸载到云执行.因此,相比单独采用云计算或者边缘计算,车辆终端与两者相结合形成的端—边—云层次性计算架构可以更好地满足用户的多样化需求[5].在采用端—边—云架构的车路协同系统中,车辆可以将时间敏感的任务卸载到附近的路边单元执行,利用该路边单元的边缘服务器满足其实时性要求;而延时容忍或计算密集型的任务则可以继续由路边单元上传到云中心执行,充分利用云服务器的资源优势.显然,端—边—云的层次性计算架构可以整合边缘计算和云计算的优势,从而显著提高服务质量,并有效缓解云中心的拥塞[6].
采用端—边—云层次性计算架构,虽然有助于降低任务的计算时间,但车辆卸载任务时也会带来额外的时间和能量开销.而且,任务在传输过程中也容易发生错误,导致可靠性降低[7].车辆终端应用的时延、能耗和可靠性一直以来都是智能交通系统关注的重点.这是因为终端应用的实时性和可靠性是决定车辆用户体验的关键因素;并且,降低车辆能耗有利于控制车辆碳排放量,减少环境污染,是智能交通可持续发展的关键[8].此外,随着车辆增多但路边单元的资源有限,很容易在高峰时段出现过载现象[9].因此,非常迫切需要设计合理有效的端—边—云车路协同资源调度方法,以优化智能交通系统中车辆终端应用的实时性、可靠性和能效.
端—边—云架构下的车路协同资源调度问题实质是多智能体(智能车)对环境资源(路边单元、云中心等)的竞争与共享问题.并且,每个智能体在与环境交互过程中会通过学习改进自己的策略,而环境资源也在动态变化[10].考虑到智能体对于资源的竞争与合作关系以及环境的不稳定性,传统的单智能体强化学习方法通常不能解决该问题[11].因此,本文针对端—边—云架构的车路协同系统,设计了一种基于多智能体强化学习的资源调度算法,通过任务卸载和计算资源分配,实现可靠性约束下的系统时延和能耗优化.
1 相关工作
当今时代,随着车路协同系统在智能交通系统中的应用越来越广泛,对于其资源调度问题的研究也越来越受到国内外学者的关注.在过去几年中,国内外学者已经提出了许多有价值的工作来解决这个问题.其中,将端—边—云架构与车路协同系统相结合,为智能交通系统的优化提供了新的思路和方向.本节将简要介绍与本研究相关的文献,并着重强调本文方法与现有资源调度方法之间的差异.
1)车路协同资源调度技术
车路协同资源调度是实现智能交通系统的关键技术之一,主要包括任务卸载和计算资源分配,已被广泛研究.例如,文献[12]针对车辆任务卸载环境的不确定性,提出了一种基于自适应学习的任务卸载算法,使每个任务车辆能够以分布式的方式学习服务车辆的延迟性能,避免频繁的状态信息交换,从而降低平均卸载时延.文献[13]考虑车辆行驶速度的变化和无线信道条件的不稳定性,将任务卸载问题定义为马尔可夫决策过程,并提出了一种低开销的启发式算法为每个任务作出卸载决策.文献[14]研究了如何高效调度志愿车辆中的空闲资源来应对路边单元中边缘服务器的过载问题.文献[15]综合考虑通信资源和计算资源的分配,提出了针对计算卸载时延和成本的多目标优化问题,并利用粒子群优化算法获得帕累托最优解.然而,以上工作均未考虑端—边—云层次性计算架构.
2)基于端—边—云架构的车路协同资源调度方法
端—边—云层次性计算架构的兴起为改善车辆服务体验和增强车辆计算能力提供了一种新范式,在学术界和工业界均引起了广泛关注.例如,文献[16]针对端—边—云框架下的计算卸载和资源分配问题,设计了一种分布式算法,通过博弈论制定卸载决策并采用拉格朗日乘子法实现资源分配,以最小化任务处理时延和计算资源成本.文献[17]提出了一种面向移动边缘计算的车联网任务动态卸载方案.该方案考虑资源的有限性和车辆的移动性,并根据边缘服务器的覆盖范围、传输速率和车辆的移动速度等约束动态推导出最优卸载方案,以缩短任务卸载时间和提高车辆能效.为了实现低延迟通信,文献[18]研究了端—边—云架构中车辆间的任务上传问题以及边缘服务器和云服务器间的计算迁移问题,并提出了一种基于概率统计的协同卸载算法.文献[16-18]所述的工作虽然考虑了任务的延迟和能耗开销,但忽略了端—边—云架构下任务传输和执行过程中的可靠性问题,容易遭受错误而导致任务失败.
本文的贡献是:运用机器学习技术解决端—边—云架构下的车路协同资源调度问题.现有研究中已提出了基于强化学习的车路协同资源调度优化方法(例如文献[19-20]),但这些方法均为单智能体强化学习算法,不适用于多智能体环境.考虑到本文研究的端—边—云车路协同系统属于多智能体环境,并将多智能体强化学习算法与车辆结合以促进车辆与环境的协作并提高车辆应对动态环境的能力[21].本文提出一种基于多智能体强化学习的端—边—云车路协同资源调度方法,以优化智能交通系统中车辆任务的实时性、可靠性和能效.具体来说,该算法充分利用端—边—云架构的特点,采用集中训练—分散执行(centralized training with decentralized execution,CTDE)的框架.在这个框架下,每辆智能车是一个智能体,在集中训练—分散执行上部署actor 网络以负责作出动作(即任务卸载和计算资源分配决策);所有智能体的critic 网络将集中部署在云数据中心并集中训练,critic 网络指导actor 网络以改进策略.当所有actor 网络训练完成后,则不再需要critic 网络,届时每个智能体可根据局部观测作出最优决策且不产生额外的迭代开销.
2 系统模型
本节主要介绍基于端—边—云架构的车路协同系统的相关模型,包括系统架构模型、任务通信模型、任务计算模型和可靠性模型.
2.1 系统架构模型
如图1 所示,端—边—云车路协同系统包含1 个云数据中心C、M个路边单元(roadside unit,RSU),以及N辆智能车.每个路边单元都配备1 个边缘服务器.假设RS U={RS U1,RS U2,…,RS UM}表示路边单元的集合,RS Um⊂RS U表示第m个路边单元及其配备的边缘服务器.每个路边单元RS Um覆盖一个区域Am=(ιm,hm),其中 ιm(单位为 m)表示Am是一个以 ιm为半径的圆,hm(单位为km/h)表示Am内限定的车辆最高时速.每个区域都有且仅由1 个路边单元负责,处于区域Am中的车辆可以和路边单元RS Um通信.
假设V={V1,V2,…,VN}表示系统内车辆的集合.每辆车Vn⊂V表示为四元组Vn=(τn,,ζn),其中τn表示Vn的当前任务,表示Vn微控制单元的计算频率,表示Vn上传τn的数据传输功率,ζn表示Vn当前所处的路边单元覆盖区域.任务τn可表示为五元组τn=(dn,ωn,vn,δn,Rth),其中dn是任务的数据量(即输入数据,单位为b);ωn是任务的处理密度(单位为cycle/b),即处理单位比特数据所需要的处理器时钟周期数;vn是任务遭受软错误的脆弱性因子;δn是任务的截止时间;Rth是任务的可靠性要求,若未到达此可靠性要求则认为任务处理失败.
当任务的数据量不大时,任务可以留在车辆本地执行;否则,可以将部分数据卸载到路边单元执行.因此,定义 βn(0 ≤βn≤1)为卸载任务 τn的决策变量 βn,表示从车辆Vn卸载到路边单元RS Um的数据在任务总数据量dn中的占比.借助于该决策变量 βn,卸载到RS Um中的边缘服务器上处理的数据量为βndn,留在车辆Vn本地处理的数据量为(1-βn)dn.
路边单元中边缘服务器的计算和通信能力通常都是有限的.假设用(单位为cycle/s)表示路边单元RS Um的最大计算能力,其可能无法满足区域Am内所有卸载任务的执行要求(例如截止时间和可靠性等).为应对该情况,可以将部分任务的数据进一步上传到资源充足的云数据中心C进行并行处理.云数据中心C的计算能力表示为fC(单位为cycle/s),它与路边单元之间的传输速率表示为 ϖC.
2.2 任务通信模型
由于路边单元的信号覆盖范围有限,而车辆是不断移动的,因此需要考虑车辆与路边单元的相对位置.假设当车辆Vn进入路边单元RS Um的覆盖区域Am时,RS Um向Vn发送信息,发送给Vn的数据包中含有RS Um的编号信息m(1 ≤m≤M),以告知Vn已进入其通信范围,并记录Vn进入区域Am的时刻.假设计算资源有限的车辆为减少其计算负载,在其行驶区域内会向所属的路边单元请求卸载任务的部分数据.当路边单元接收到请求后,会检查边缘服务器当前的计算能力是否能满足该任务的执行需求.
从上述示例可知,我们需要确定任务 τn是否需要继续上传到云,因此,定义一个二元变量 μn表示路边单元是否能够满足任务 τn的执行需求,
1)车辆Vn到路边单元RS Um的通信模型
在车辆与路边单元的通信中,下行的时延和能耗与上行相比可以忽略不计并且路边单元传出的数据包通常很小,因此可以不考虑下行的时延和能耗[6].上行链路通常采用正交频分多址技术,支持对边缘服务器的多址接入.为了保证发送卸载请求的车辆之间的上行传输的正交性,基站带宽Bm被划分为相等的子带,并给每个需要通信的车辆分配一个子带.
为方便表示,定义二元变量zn,m表示当前时隙内车辆Vn是否在路边单元RS Um覆盖范围Am内,即
定义变量Lm表示当前时隙内路边单元RS Um连接的车辆数目,它表示为
RS Um与Vn之间的信噪比(signal to interference plus noise ratio,S INRn,m)为
其中gn为车辆Vn到路边单元RS Um之间的信道增益,σ为背景噪声.根据Shannon-Hartley 定理,从Vn到RS Um的上行数据传输速率为
相应的传输能耗为
2)路边单元RS Um到云数据中心C的通信模型
为了将任务传输到云、边缘服务器和云数据中心之间的高速光纤通信链路是端—边—云网络架构中必不可少的基础设施,它确保了边缘服务器的灵活性和可扩展性.假设边缘服务器和云之间的数据传输速率用 ϖC表示,当路边单元RS Um将任务数据全部上传到云(即μn=1)时产生的传输时延为
值得指出的是,本文仅考虑通信过程中车辆产生的能量开销,因此不需要计算路边单元卸载任务到云的能耗.
综合考虑上述1)和2)两种情况,车辆Vn卸载任务的总传输时延为
2.3 任务计算模型
计算模型可分为本地执行模型和远程执行模型2 类,其中根据边缘服务器的计算能力是否能满足任务的执行需求,可将远程执行模型进一步分为路边单元计算模型和云计算模型.
1)本地计算模型
由于本地数据量为(1-βn)dn,本地计算时间为
因此,任务在本地的计算能耗为
其中 κ为本地计算频率的相关系数.
2)远程计算模型
①路边单元计算模型.当μn=0时,边缘服务器的计算能力可以满足任务的执行需求,因此任务数据不需上传至云端处理.任务在边缘服务器的执行时间为
②云计算模型.当μn=1时,边缘服务器的计算能力不足以满足任务的执行需求,任务数据需要上传至云端处理,且需要将接收的任务数据完全上传给云,不再分割.因此,任务在云上的执行时间为
其中fC(单位为cycle/s)表示云数据中心的计算能力.任务 τn上传到路边单元部分数据的计算时延为
值得指出的是,本文关注的是车辆的能量开销.因此,仅计算任务在车辆本地执行时产生的能耗,未计算任务在路边单元或者云上执行的能耗.
2.4 可靠性模型
任务的可靠性模型主要包括传输可靠性和执行可靠性,其中执行可靠性又包括本地执行可靠性和卸载执行可靠性.
1)传输可靠性
任务在传输过程中可能会遭受噪声和干扰位错误以及传输链路上的位同步错误.任务的传输可靠性定义为任务成功传输至其卸载目的地而不出现误码的概率.根据位错误模型,传输可靠性可表示为
其中 ρ为恒定误码率.
2)执行可靠性
任务在执行过程中可能会遭受瞬时故障引起的软错误.瞬时故障是一类由于高能粒子撞击电路或者受电磁干扰而导致逻辑错误的故障.不同于永久性故障,瞬时故障持续时间短,并不会对硬件设备造成损坏,因此也被称为软错误.任务的执行可靠性通常定义为任务没有遭受软错误而成功执行的概率.任务的2 类执行可靠性均可表示为指数函数.
3 问题定义
在智能交通系统中,影响车辆用户体验质量(quality of experience,QoE)的2 个关键因素是任务的时延和能耗.为同时考虑这2 个因素,本文提出一个新的效用函数以量化采用基于端—边—云架构的资源调度技术以改善系统在任务时延和能耗.
为了定义效用函数,首先计算任务完全在车辆本地执行所需的时延和能耗分别为
然后结合任务的通信模型和计算模型,并考虑卸载到边缘服务器的任务数据和本地数据可以同时执行,任务的总执行时间则表示为本地执行时间和卸载执行时间的较大值.因此,计算任务采用卸载技术后执行所需的时延和能耗分别为
在式(19)~(22)定义的基础上,所提出的效用函数表示为
本文的研究目标为提升车辆用户的QoE,即在可靠性的约束下最小化系统总时延和总能耗(即最大化效用函数值 Un).研究问题的形式化为:
由式(24)可知,目标函数为所有车辆的效用值之和.为了提升系统中所有车辆的QoE,需要最大化所有车辆的效用值之和.约束C1表示任务的可靠性不得低于给定的阈值,以保证任务顺利完成.约束C2表示任务需在截止期限之前完成,以保证实时性.约束C3表示RS Um分配给其区域Am内所有车辆的计算能力之和不得超过其自身的计算能力
4 基于多智能体强化学习的端—边—云车路协同资源调度优化算法
本节提出了一种多智能体强化学习算法,以解决本文研究的端—边—云车路协同资源调度问题.在求解中,1 辆智能车对应于1 个智能体,端—边—云网络架构对应于强化学习的环境,车辆的效用函数对应于智能体的奖励函数.本节将详细介绍所提出的基于多智能体强化学习的端—边—云车路协同资源调度优化算法.
4.1 多智能体强化学习框架
强化学习的主要角色为环境和智能体,智能体在每个时隙都会对所处环境状态进行观察,然后根据观察到的状态作出动作决策.环境会因为智能体的动作响应而发生变化,智能体也会从环境中感知到新状态的奖励信号.智能体将通过不断调整和更新动作策略,最终实现最大化累积奖励,即回报.强化学习算法中有3 个关键要素,即状态、动作、奖励,下面将结合系统模型和研究问题展开介绍.
1)状态空间
为了让智能体(即智能车)可以根据环境中的信息作出合适的动作,可以将第n个智能体在时隙t的状态空间表示为
2)动作空间
3)奖励
在多智能体强化学习算法中,一个时隙t的奖励是所有智能体的奖励之和.对于车辆Vn而言,若当前状态满足所有约束,当前动作的奖励可以用式(23)计算.再结合式(24)的约束条件,可以将第n个智能体在时隙t的奖励表示为
其中r为一个取值为负的参数.如果扩展为多智能体环境,当前状态对应的系统奖励r(t)可以表示为所有智能体获得的奖励总和,即
4.2 基于多智能体强化学习的资源调度算法设计
在多智能体环境中,一个智能体的策略和动作通常会影响其他的智能体,因此我们使用集中训练—分散执行架构以满足智能体之间共享信息的需求.此外,我们引入深度确定性策略梯度算法,该算法通过策略网络将智能体的观测映射为一个确定的动作,以应对动作空间连续的问题.因此,本文介绍所设计的基于多智能体强化学习的资源调度算法.
4.2.1 多智能体深度确定性策略梯度算法网络架构
集中训练—分散执行是多智能体强化学习的一种常用架构.本文所提出的多智能体深度确定性策略梯度算法是在集中训练—分散执行架构的基础上进行扩展,通过引入深度确定性策略梯度算法以解决连续动作空间的问题,算法架构如图2 所示.
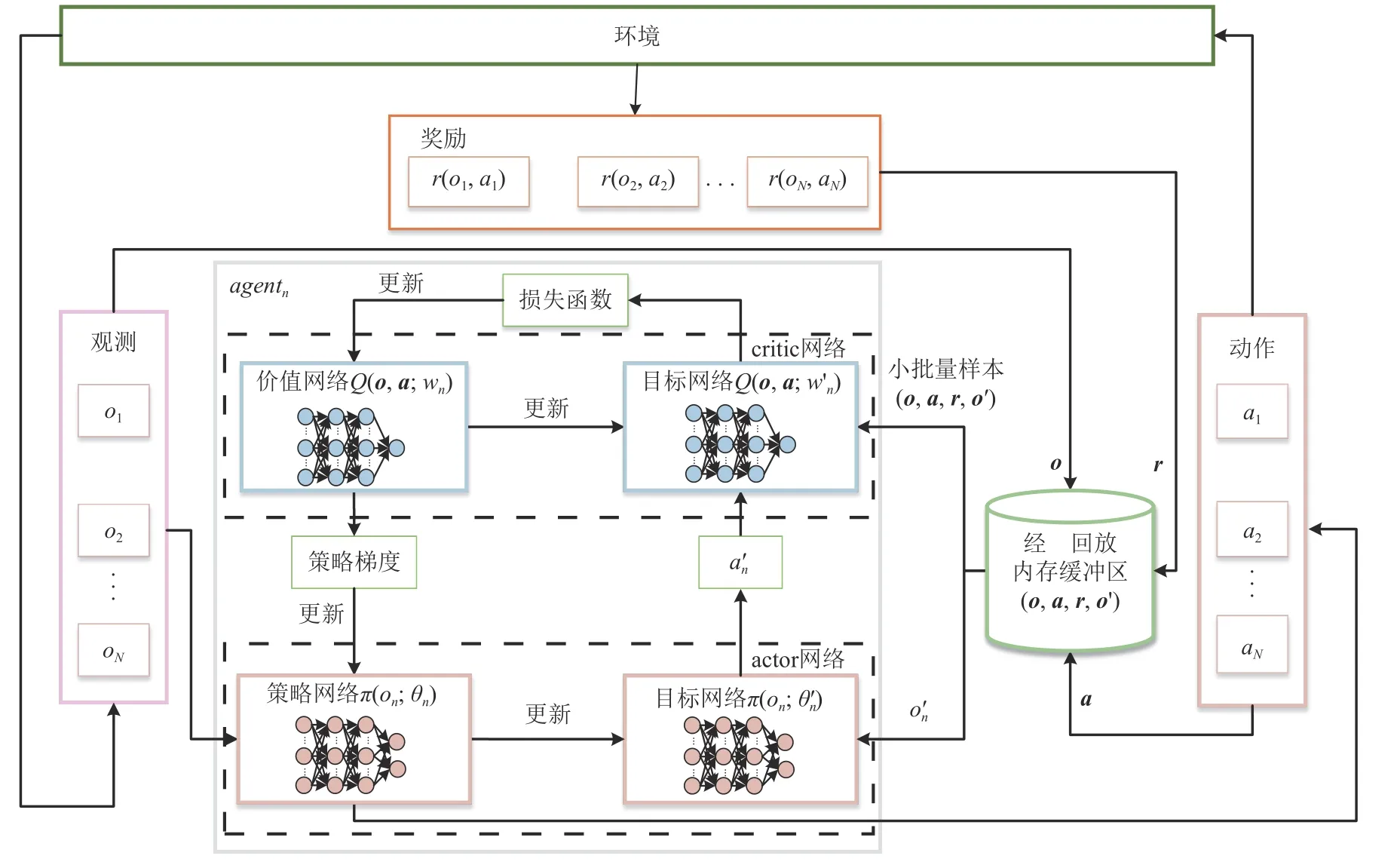
Fig.2 Architecture of multi-agent deep deterministic policy gradient algorithm图 2 多智能体深度确定性策略梯度算法架构
在这种架构下,每个智能体(agent)上均单独部署一个actor 网络,输入为智能体自身的观测on,每个智能体自身的决策不会依赖其他智能体的观测;每个智能体都对应一个集中式的critic 网络,部署在控制中心上,每个critic 网络收集全局的观测和所有智能体的动作,根据自身的参数wn评价状态和动作的价值,并通过反向传播以更新策略网络的参数 θn.当训练结束后,智能体不再需要控制中心,每个智能体独立地与环境交互并在actor 网络的指导下作出动作.所提算法在每个智能体上部署了一个策略网络和一个目标网络,共同组成actor-critic 结构中的actor部分.每个智能体的价值网络部署在控制中心以收集全局的观测o、动作a和奖励r,它和目标网络共同组成actor-critic 结构中的critic 部分,o=(o1,o2,…,oN),a=(a1,a2,…,aN),r=(r(o1,a1),r(o2,a2),…,r(oN,aN)).
1)策略网络
图3 为策略网络模型.对于第n个智能体,策略网络的输入是智能体自身的观测on,经过2 层全连接的隐藏层,其激活网络为ReLu 函数,输出层用sigmoid 作为激活函数以限制动作空间,最后输出为二维动作.策略网络的优化器采用自适应矩估计优化算法[22].
2)价值网络

Fig.3 Policy network model图 3 策略网络模型
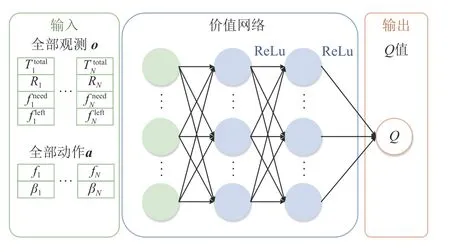
Fig.4 Value network model图 4 价值网络模型
图4 为价值网络模型.对于第n个智能体,其价值网络的输入是所有智能体的观测o和所有智能体的动作a.输入经过2 层全连接的隐藏层,其激活网络为ReLu 函数,然后输出一维Q值.价值网络的优化器也采用自适应矩估计优化算法[22].
4.2.2 网络训练
深度神经网络为了保证有监督学习模型,要求数据满足独立同分布.因此,深度神经网络算法通过经验回放对样本数据进行存储,然后利用随机采样更新深度神经网络参数,以实现数据之间的独立同分布并降低其关联性,解决了经验数据的相关性和非平稳分布问题[23].因此,本文所提出的多智能体确定性策略梯度算法同样采用经验回放机制,具体训练过程为:
从经验回放内存缓冲区 D中随机选取数量为S的小批量样本(ot,at,rt,ot+1).对于第n个智能体,根据时间差分法(temporal-difference,TD)[24]计算其TD 目标:
critic 中价值网络的参数wn可以通过最小化loss函数实现,loss 函数定义为
其中Q(ot,at;wn)为部署在控制中心上的第n个智能体对应的critic 网络中的价值函数对于时隙t状态和动作的评价.actor 中策略网络的参数可以通过确定性策略梯度方法更新,其loss 函数的梯度计算为
4.2.3 基于多智能体强化学习的资源调度优化算法
本文面向时间和能量敏感的端—边—云车路协同系统,提出了一种基于多智能体强化学习的资源调度算法,其流程如算法1 所示.
算法1.基于多智能体强化学习的资源调度算法.
需要注意的是,在训练网络时,策略网络需要智能体自身的观测、动作以及价值网络返回的Q值,而价值网络需要所有智能体的观测、动作和奖励信息.所以将critic 部署在云控制中心,而actor 部署在车辆本身.训练完成后,执行阶段只需要策略网络,不再需要价值网络,每个智能体可以根据自身的观测作出最佳决策.
5 实 验
本节通过大量实验来验证所提算法的有效性,具体的实验设置和结果分析将在本节列出.为方便理解,表1 给出主要的参数设置.
5.1 实验设置
实验所考虑的端—边—云车路协同系统包含1个云数据中心.众所周知,云中心的计算能力远大于边缘服务器的计算能力,通常认为不受限制.但为了量化云中心的计算能力,本文假设云中心由若干个服务器集群组成,每个服务器的计算能力为36.0 GHz;并且,服务器默认按需使用以节省开销,即当一个服务器的计算能力不够用时再开启新的服务器.假定系统中有20 个路边单元,每个路边单元配备3 个Dell R230 边缘服务器,每个服务器的计算能力为18.0 GHz[25].每个路边单元覆盖的区域半径为400 m,最高时速为60 km/h.为比较不同车辆数目对路边单元服务质量的影响,每个路边单元覆盖范围内的车辆数分布在10~60.车辆的本地计算能力随机分布在0.5~1.0 GHz,任务的数据量随机分布在1~10 MB.

Table 1 Detailed Configuration of Parameters表 1 参数详细配置
在所提算法中,策略网络的学习率固定为0.0001,价值网络的学习率固定为0.001,折扣因子 γ设置为0.8,目标网络的软更新率λ=0.001.表2 给出了本文所有超参数的设置.

Table 2 List of Hyperparameters表 2 超参数列表
为了实现所提算法,每个智能体的策略网络和价值网络都是4 层全连接神经网络,中间2 层为隐藏层[26],神经元数量分别为64 和48.为验证所提算法的性能,本文将它与SPSO 算法和DDPG 算法进行对比:
1)慢移动粒子群优化算法(SPSO)[27]是一种改进版的PSO 算法,它在搜索最优解时通过减缓粒子运动,使得粒子在个体最优粒子和全局最优粒子的指导下搜索出更多的高质量解,具有较好的性能.本文将其作为对比算法,运用于解决端—边—云架构下的车路协同资源调度问题.
2)深度确定性策略梯度算法(DDPG)[28]是一种单智能体强化学习算法.该算法使用actor-critic 架构和DQN 算法,用于解决具有连续动作空间的强化学习问题.本文将其作为基准算法,运用于解决端—边—云架构下的车路协同资源调度问题.
5.2 实验结果
本文所提算法和SPSO 算法、DDPG 算法的评价指标均为式(24)中的目标函数,即综合体现时延和能耗优化效果的效用值函数.并且,效用值越高,说明算法在优化时延和能耗的效果越好.为全面评估3种算法的性能,实验中将观察在不同智能体数量N和权重 α下效用值的变化.
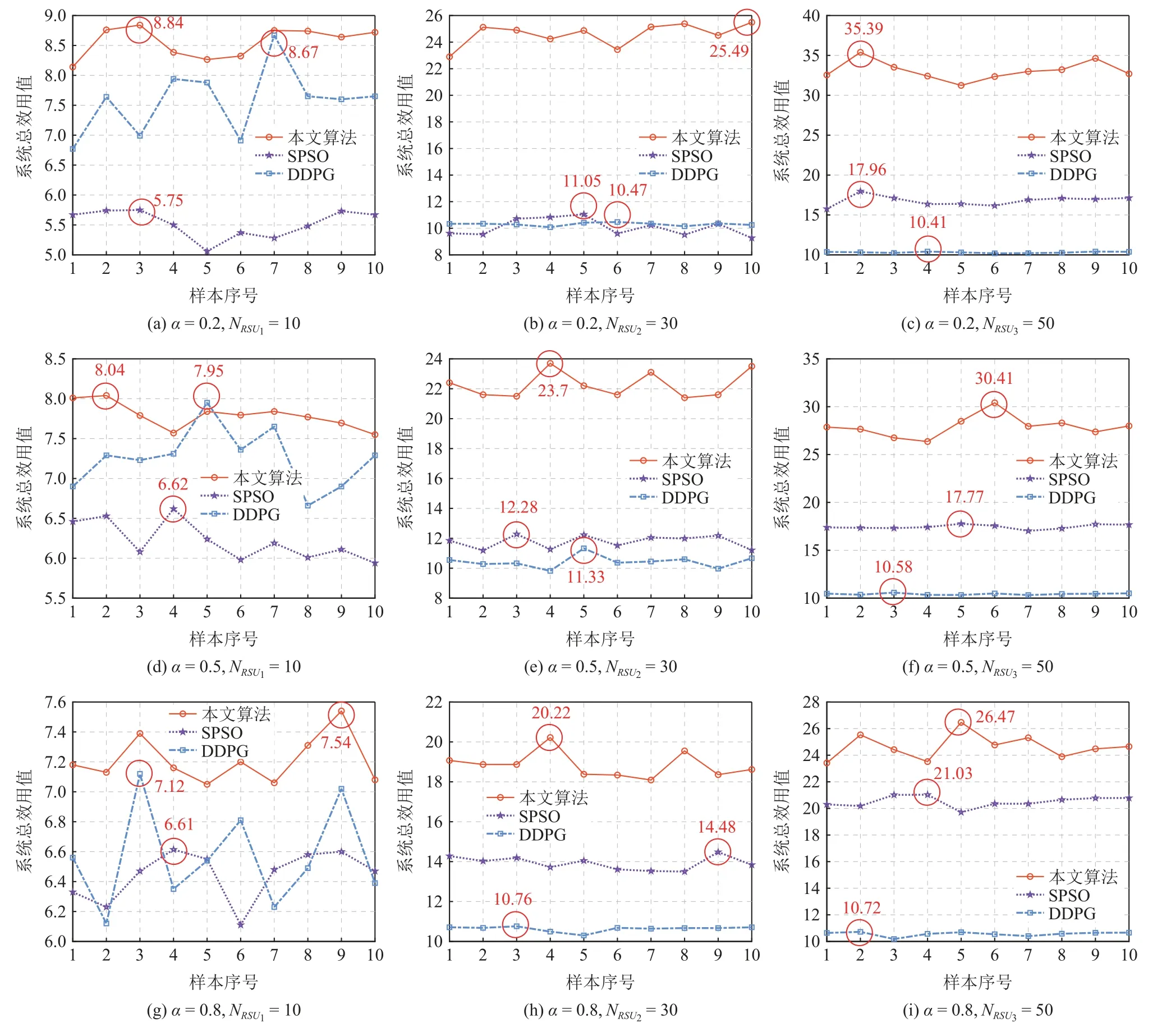
Fig.5 Total system utility values achieved by three algorithms under different weights and number of vehicles图 5 不同权重和车辆数下3 种算法取得的系统总效用值
为比较不同权重和车辆数的情况下3 种算法所取得的系统总效用值,图5 展示了3 个代表性路边单元(分别是N=10,N=30,N=50)的系统总效用值.如图5 所示,不论权重 α和车辆数N如何变化,所提算法明显优于SPSO 算法和DDPG 算法.具体来说,当N=10时,所提算法相对于另外2 种算法的优势并不显著;但随着车辆数增加,所提算法在动态变化的多智能体环境中优势逐渐体现,其系统总效用值明显高于SPSO 算法和DDPG 算法.
为了更直观地比较3 种算法,图6 计算了不同权重 α下各算法的系统平均效用值,具体结果为:
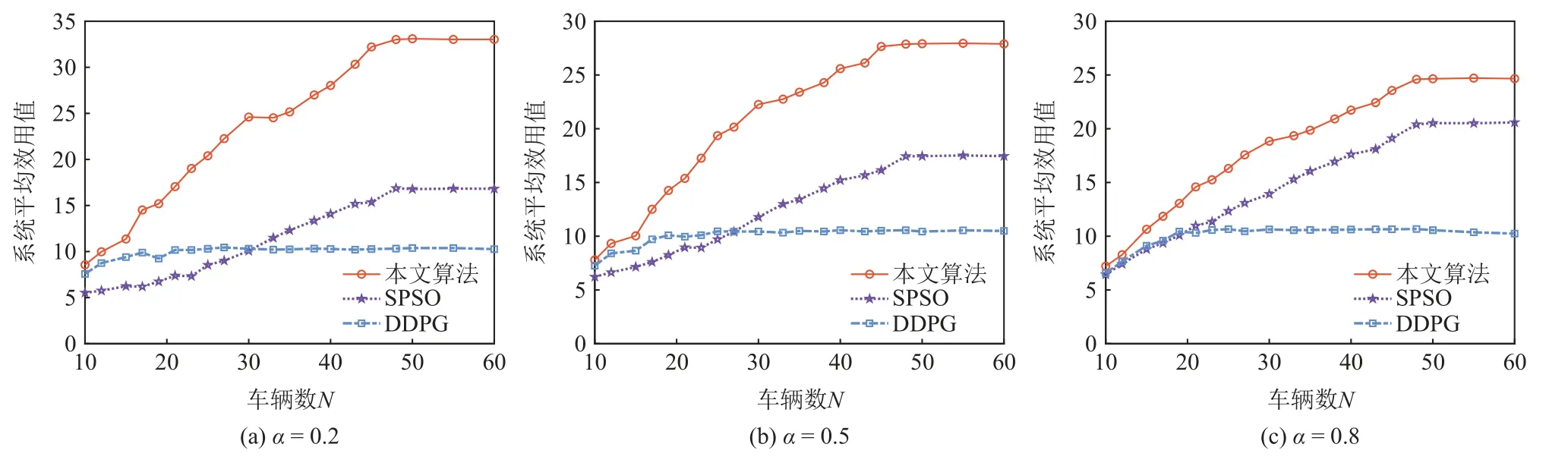
Fig.6 Average system utility values achieved by three algorithms under different weights图 6 不同权重下3 种算法取得的系统平均效用值
1)当权重α=0.2时,表明当前系统更注重能效.如图6(a)所示,所提算法实现的系统平均效用值显著高于SPSO 算法和DDPG 算法.例如,当车辆数N=23时,所提算法相比于SPSO 算法,平均效用值最高可提升159.57%;当车辆数N=60时,相比于DDPG算法,平均效用值最高可提升221.9%.
2)当权重α=0.5时,表明当前系统中时延和能效同等重要.如图6(b)所示,所提算法实现的系统平均效用值依然明显高于SPSO 算法和DDPG 算法.例如,当车辆数N=25 时,所提算法相比于SPSO 算法,系统平均效用值最高可提升 99.5%;当车辆数N=50时,所提算法相比于DDPG 算法,系统平均效用值最高可提升168.3%.
3)当权重α=0.8时,表明当前系统更注重时延.如图6(c)所示,所提算法实现的系统平均效用值仍然高于SPSO 算法和DDPG 算法.例如,当车辆数N=30时,所提算法相比于SPSO 算法,系统平均效用值最高可提升35.2 %;当车辆数N=60时,相比于DDPG 算法,系统平均效用值最高可提升140.8 %.
综合观察图6(a)(b)(c),可以发现当路边单元的车辆数较少时,3 种算法的系统平均效用值相差不大.随着车辆数的增加,3 种算法的系统平均效用值虽然都呈上升趋势,但相比于SPSO 算法和DDPG 算法,所提算法实现的系统平均效用值增幅较大.这是因为当系统中车辆较少时,车辆对资源的竞争并不激烈,各个算法均能较容易地找到近似最优解.然而随着车辆增多,环境变得更为复杂,智能车之间的资源竞争更加激烈,SPSO 算法容易陷入局部最优,DDPG 算法甚至在车辆数N=20时就趋于收敛,这是因为单智能体算法不适用于动态变化的多智能体环境.而所提算法可以通过迭代学习训练所有智能体的actor 网络,无论环境如何变化,智能体都能够根据自身的观测作出决策使系统接近纳什均衡状态,因此可以适应系统车辆增加而作出最优决策.这体现了所提算法在解决多智能车辆资源调度问题中的优越性.此外,在云边资源有限的系统中,由于车辆对于通信资源和计算资源的竞争性,系统效用值不会随着车辆数的增加而无限增长.因此,本文还探究了系统平均效用值的收敛性.由图6 可知,在资源给定的情况下,所提算法的系统平均效用值在车辆数N=48时趋于收敛.
给定一个端—边—云车路协同系统,图7 进一步展示了采用3 种算法后该系统中不同车辆所实现的效用值.值得注意的是,图7 中的每个柱状图对应的是图5 中的相应折线图中3 种算法的最优解.例如,图5(a)中3 种算法的系统总效用值最优解分别为8.84(本文算法),5.75(SPSO 算法),8.67(DDPG 算法);图7(a)则用柱状图展示了这3 个最优解对应的系统中每个车辆实现的效用值.
如图7 所示,所提算法可以保证系统中每辆车的效用值基本都不低于采用SPSO 算法和DDPG 算法取得的效用值.具体来说,车辆数较少时,所提算法的优势并不明显;但随着车辆数增加,该算法获得的单个车辆的效用值明显高于SPSO 算法和DDPG 算法所获得的.这是因为所提算法以最大化系统效用值为目的,通过不断地迭代学习直到所有智能体作出的决策使得系统接近纳什均衡状态.在这种状态下,智能体可以作出最优的资源调度方案,从而充分利用系统中的资源,以实现较高的卸载效用值.观察图7(c)(f)(i)可以发现,当车辆数较多时,所提算法和SPSO 算法都存在某些智能体的效用值相对较低的情况,这是因为在资源受限的情况下存在一些不需要卸载就能在本地完成执行的任务,这些任务的资源竞争力较弱,优先级较低,分配到的资源相对较少,其效用值自然会比较低.但是在给定资源相同的情况下,所提算法可以保证大部分车辆获得较高的效用值,而SPSO 算法只能保证少部分车辆具有相对较高的效用值(低于本文所提算法),且存在部分车辆效用值为0 的情况(例如α=0.2,N=30时).并且随着车辆数增多,效用值为0 的车辆数逐渐增多,这是因为SPSO 算法容易陷入局部最优,为了满足所有车辆获得的计算能力总和不超过路边单元计算能力的约束,SPSO 算法将放弃卸载一些能够在本地处理的任务,从而导致这些任务的卸载效用值为0.而DDPG 算法则无法适应动态复杂的多智能体环境.由图7 可知,随着资源竞争愈发激烈,DDPG算法输出的每个智能体的卸载决策和资源分配策略基本相同,即将边缘服务器的资源平均分配,使得所有智能体的效用值基本相同,却忽略了任务的多样性以及对于云中心计算资源的利用,从而导致智能体的效用值普遍较低且系统效用值过早收敛.

Fig.7 Utility values of vehicles achieved by three algorithms for a given system图 7 给定系统中的不同车辆采用3 种算法取得的效用值
通过以上实验结果分析可以看出,所提算法与SPSO 算法和DDPG 算法相比具有明显优势,能够充分利用路边单元的计算资源,显著提高卸载效用,从而优化系统时延和能耗,有效解决了端—边—云车路协同系统中的资源调度优化问题.
5.3 硬件平台测试
在5.2 节中我们对所提算法进行了训练,并验证了该算法相较于SPSO 算法和DDPG 算法在多智能体环境中的优越性.本文所提算法采用了集中训练—分散执行架构,主要目的是训练actor 网络,使其能够输出最优动作(即最优资源调度方案);当训练完成后,actor 网络可以根据自身对于环境的观测独立地作出最优动作.该网络也将最终部署于端—边—云车路协同系统中的车辆终端.因此,为进一步验证所提算法的训练效果,将训练过的actor 网络部署在真实的硬件平台上进行测试.如图8 所示,本文选取的硬件平台为NVIDIA Jetson AGX Xavier 开发板[29].不失一般性,我们部署了3 种不同量级的actor 网络,并测试了这些网络在不同权重下(α=0.2,0.5,0.8)的效果.考虑到开发板的资源限制,将3 种actor 网络对应的车辆数分别设置为N=10,N=17,N=25.
在本组实验中,每个actor 网络都产生了10 个样本.表3 列举了不同权重下3 种actor 网络的测试样本均值和训练样本均值.如表3 中结果所示,测试所获得的系统平均效用值与训练所获得的系统平均效用值非常接近,表明actor 网络已获得了较好的训练,可以根据自身观测作出最优动作(决策).并且,测试结果也验证了所提算法训练的actor 网络部署在真实硬件平台的可行性.因此,该网络未来可直接部署于端—边—云车路协同系统中的车辆终端.
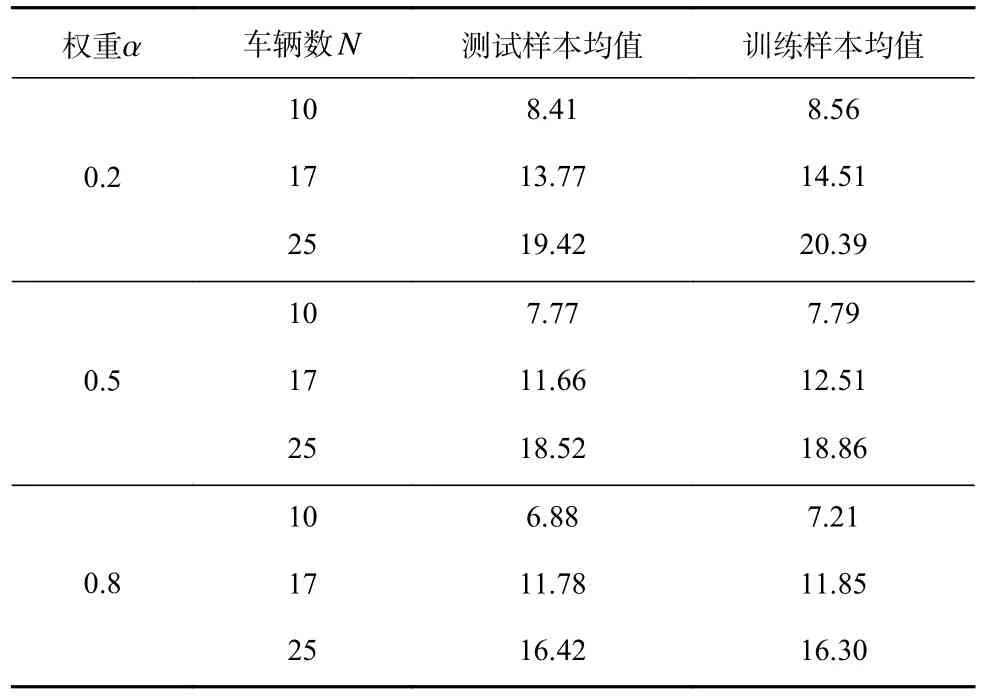
Table 3 Average System Utility Values Achieved by Three actor Networks Under Different Weights表 3 不同权重下3 种actor 网络的系统平均效用值
6 结 论
本文面向智能交通系统中时间和能量敏感的车辆终端应用,提出了一种基于多智能体强化学习的端—边—云车路协同资源调度方法,以实现可靠性约束下的时延和能耗优化.该方法采用集中训练—分散执行的框架,并结合深度确定性策略梯度算法来训练和构建深度神经网络,以决策任务的卸载和计算资源的分配.本文定义了一个效用函数以量化采用基于端—边—云架构的任务卸载和资源调度后,车辆任务在时延和能耗方面的改进.实验结果表明,相比现有算法,所提方法可以充分利用端—边—云车路协同系统的计算资源,获得最高的效用值,验证了所提方法的有效性.此外,本文还验证了所提方法部署在实际硬件平台的可行性,为将该算法部署于实际的端—边—云车路协同系统奠定了实验基础.在未来的工作中,我们将搭建完整的端—边—云车路协同系统硬件平台,并结合实际部署效果对所提算法展开进一步优化.
作者贡献声明:郑莹莹实现研究方案,验证实验,撰写论文;周俊龙提出研究思路,设计研究方案,修改论文;申钰凡和丛佩金协助实验验证,参与论文撰写与修改;吴泽彬指导研究方案,参与论文撰写与修改.
猜你喜欢
少儿美术(2019年7期)2019-12-14
铁道通信信号(2019年9期)2019-11-25
汽车观察(2019年2期)2019-03-15
中国交通信息化(2018年12期)2018-03-21
网络安全和信息化(2017年10期)2017-03-08
知识产权(2016年8期)2016-12-01
网络空间安全(2016年3期)2016-06-15
中国塑料(2016年9期)2016-06-13
现代农业(2015年5期)2015-02-28
现代农业(2015年5期)2015-02-28
