
关联用户驾驶的整车道路试验大数据分析系统
2023-05-22 11:11陆林熊珂
时代汽车 2023年9期
关键词:大数据
陆林 熊珂
摘 要:为了在竞争日益激烈的汽车市场上取得成功,汽车制造商必须高度响应消费者的需求,并进一步加快新样车的设计验证周期。通过收集网联车辆的用户驾驶数据,促进数据驱动的试验认证,可以满足客户不同驾驶习惯的需求,但测试工程师面临着利用用户驾驶大数据的挑战。这促使一个专门的道路试验大数据分析系统的提出,为工程师获得对关联用户驾驶的整车道路实验提供有效途径。该系统不仅屏蔽了工程师操纵大数据的技术障碍,而且还帮助他们通过有指导的数据科学过程挖掘有价值的信息。该系统已被一些汽车工程师实际用于他们的道路试验用例,肯定了其灵活即用的功能和令人印象深刻的效率。
关键词:道路试验 大数据 用户关联
1 引言
整车道路试验(Vehicle Road Test, VRT)[1]是指在公共/测试道路上进行一定强度的预生产车辆驾驶操作,以评估车辆的设计功能和性能。VRT与仿真测试相比,具有更强的客观优势,通常被认为是原型车辆距离交付市场阶段的“最后一公里”。未关联用户的VRT可能导致某些子系统的过度设计或者欠设计[2]。这是由于消费者对主机厂过去售出车辆的使用信息未能有效向车辆研发与测试工程师反馈的结果。故朱佳琦[3]提出了基于用户使用数据分析的整车道路试验优化方案,江毓等人[4]提出了一种关联用户使用情况的相对合理的试验场整车耐久性试验方案。用户关联的VRT可用于测试认证规范的制定,以发现和消除潜在的设计缺陷,从而减少售后索赔和召回成本。
车联网[5][6]允许从开放道路上运行的车辆中收集车辆参数,为关联用户驾驶提供了数据收集渠道。然而,随着长期和高频的数据积累,研发工程师正面临着处理大数据的挑战。利用大数据技术可以为汽车行业提供转型的机会。2014年初,Johanson Mathias等人[7]开发了一个大数据框架,以探索利用汽车大数据进行知识驱动的产品开发。龚蓉军[8]开发了一个针对道路试验的数据平台,使用Hadoop、Hive和Spark工具实现数据收集、存储、分析和报告展示。然而,当将大数据技术应用于VRT领域时,以往的系统忽略了领域专家的学习成本,导致可用性体验较差。更糟糕的是,没有定制的分析组件来整合领域知识并协助业务专家应用到具体的案例级分析。
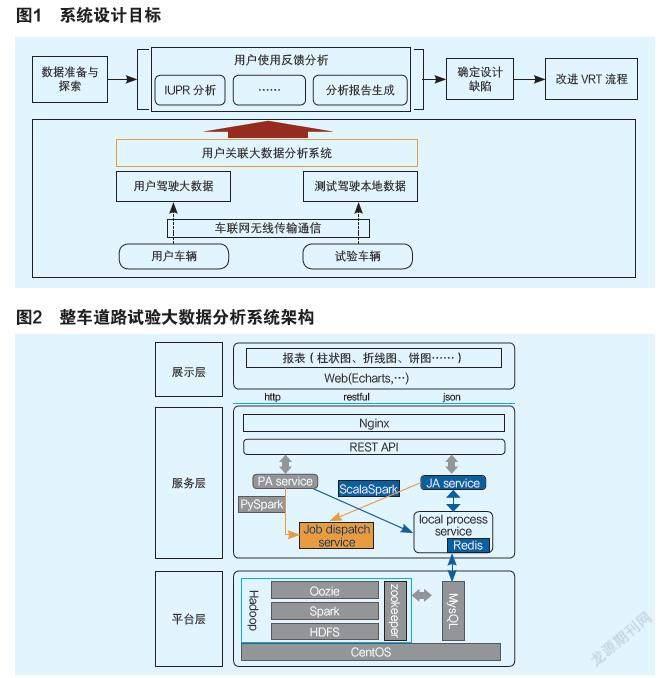
本文的目标是设计和实现一个大数据科学指导的VRT系统以屏蔽大数据的复杂性,使用户能够直观地探索、分析和可视化数据。如图1所示,该系统扮演着利用大数据科学指导工程师进行关联分析的最后一公里的角色,为关联用户驾驶的道路试验分析提供更直观的信息挖掘过程。
2 系统概述
图2为该系统的技术架构,其将整个系统分为三层架构:
大数据平台层。我们选择了Hadoop、Spark、Oozie用于分布式数据存储、计算和作业调度。该平台基于Spark SQL和ML来执行分析操作。Spark的数据源是存储在HDFS文件系统上的汽车传感器数据。然后,选择Oozie工作流调度器来调度特定作业(如Scala Spark程序和Pyspark脚本)。一旦后端服务提交了一个Spark作业,这个作业将立即被发送到相应的Oozie调度器。这个平台层主要用于探索和分析从全国客户处收集的大量真实驾驶数据。
混合服务层。中间层是一个混合的Java和Python服务,用于本地和集群计算,实现自动和智能的数据驱动分析。在我们的设计中,提供了两种后端服务。基于Python的分析(Python-based Analysis, PA)和基于Java的分析(Java-based Analysis, JA)服务。PA服务可以提交Spark分布式作业,也可以用本地进程服务处理本地数据。这个由Flask提供的本地进程服务结合了pandas和scikit-learn等软件包,用于提供快速统计或机器学习API。同样,JA服务也有两个分支,其本地进程服务在处理其他事务性功能方面具有优势。在某些情况下,本地数据分析仍然是必要的,测试工程师希望上传一个本地MDF文件,倾向于更节省时间的本地分析。当分析任务返回时,结果被提交给系统的展示层。这个服务层分别处理来自测试车辆和售出车辆的数据样本的实时计算任务。
展示层。我们选择使用一个基于web的用户界面,其采用了React框架实现,并使用Echart插件来绘制图表。这个展示层能够实现丰富的互动操作和选项,以指导数据科学流程。同时,如果定义了一个分析任务,对数据进行的分析类型将被记录。根据所要求的分析类型,分析任务的结果可以是不同种类的图表或图形,通过基于web的用户界面进行组合并提供给用户。
3 系统重点实现描述
该系统从业务目标的确定,数据准备,先样本后总体分析以得出结论,最后以web报告的形式可视化四个主要阶段辅助工程师快速利用大数据手段进行业务分析。
3.1 业务目标
VRT分析的一个共同业务目标是在用性能比(In Use Performance Ratio, IUPR)[9]研究,通常包括:(1)发动机怠速时长分析;(2)车速持续时间分析;(3)油门位置From-To分析;(4)油门位置与车速的距离范围;(5)发动机停机时间分析。这些案例具有强烈的实际意义,都可以通过我们的系统来实现。
3.2 数据准备
该阶段将准备一个关于业务目标的目标数据集。首先,测试人员既可以通过JA服务上传一个本地文件,也可以使用PA服务访问HDFS文件。无论数据集如何添加,它都被称为VRT域中的总体。然后,后端服务将启动一个本地或Spark作业,以获得關于此总体的摘要以及这个总体的子集。摘要是对数据的统计描述(计数、最小值、平均值等),以及所有信号的缺失值、唯一值情况。先样本后总体(First Sample Then Population, FSTP)是测试工程师进行IUPR分析的工业经验。这里的样本指的就是刚才的子集。
3.2.1 FSTP抽样策略
对上述大数据的一步步操作是很耗时的,用户的耐心会随着时间的推移逐渐耗尽。采样已被证明是处理大数据问题的一种有效方式。为了使我们的系统更加友好,我们将首先采样总体数据并将其加载到本地MySQL数据库中。因为动力学片段是测试工程师重点关注的样本,我们让采样过程中除了均匀随机的方式外,还选择几个动力学片段。提取部分动力学片段被称为线性采样。
考虑到要分析的整个数据集,我们假设由均匀和线性抽样产生的相对较小的比例可以近似于总体的分布。那么,我们对样本包含不同参数的缺失和异常情况就有更大的把握。这样一来,对样本的数据预处理步骤就可以完全复制到总体数据集上,有效避免在样本上的预处理步骤与总体数据集上的不一致问题。在统计上,样本分布的大小分别取决于置信水平、误差范围,分别表示为α、E。令p表示总体采样比例,根据公式(1)可计算得到样本量大小。
其中Zα/2是对应于置信度的Z分数。在VRT背景下,总体的大小总是已知的,如果是100万,那么计算出的样本n只有385。这大大提高了FSTP分析过程的效率。
3.3 FSTP分析
一旦数据准备好了,测试人员就可以为特定的用户群体分析创建一个新的工作台。相应的分析界面会根据信号的类型进行分类和显示,然后列出可选的分析组件。测试人员只需点击相关的分析组件,将需要分析的信号拖到相应的输入框中,就会立即计算并显示该组件对样本数据的分析结果。
可视化方面,我们提供了一些绘图组件,如直方图、散点图、柱状图、折线图和热图。它们可以用于不同的情况,例如,直方图可以用来检查汽车的速度分布,折线图可以用来观察制动状态的变化,热图可以显示发动机转速和扭矩的使用规律。可视化包括在工程师可容忍时间内的样本级分析呈现,和最终总体级别分析结果的呈现。
通过样本集上分析可视化,工程师可快速决定数据准备和分析逻辑是否是他们所期望的。如果这些操作是它们希望在总体级别上执行的操作,则将启动一个Spark作业,以分布式的方式进行集群计算。
4 案例研究
在本节中,我们将以某汽车研究院的某个应用为例进行阐述。该系统导入了基于车载T-BOX从市场用户车辆采集的各种车载传感器数据。典型的信号包括速度、转向角速度、里程表、转速、制动踏板状态、加速度开启度等。自2019年以来,该大数据平台已经存储了五千多辆汽车的数据。平均每天收集1800万条记录,容量为3.6GB,数据总容量为1328GB,其中包括225亿条记录。
在本示例中,工程师A、B和C想要获得一份关于所有用户车辆上动力系统极端温度分布的报告。他们的任务分工为:A进行数据准备和电机的极端温度分布分析,B负责蓄电池的极端温度分布,C最后汇报报告。
首先,A选择2019年7月1日在中国全省运行的所有车辆,并选择所需的信号,即车辆识别号(VIN)、电机和电池温度。然后,系统根据用户的选择开始数据准备任务,获得相应数据集上的描述性统计信息。同时,通过提出的采样策略,获得采样数据集并将其存储在MySQL表中。
上一阶段完成后,工程师A可以预览样本和相应的描述性统计结果,以检查是否存在空值或异常情况。如果数据质量不好,则将启动数据编辑操作。在编辑阶段,A可以选择删除或填充空值,并过滤掉相关的值。一旦确定,编辑步骤将被记录并封装成一系列的Spark操作,这些操作将提交给Oozie进行任务调度。用户可能需要很长时间来等待大数据平台才能完成数据编辑阶段。数据编辑阶段是可重复的,用户可以重复执行预览、探索和编辑操作,直到数据质量满足要求。
接下来,以准备好的样本数据作为输入,A和B可以并行完成他们的分析任务。分析工作台如图3所示,在我们的系统中,VIN显示为一个“维度”,因为它的数据类型是字符串;电池和电机温度信号是数值类型,所以它被分为“指标”栏。为了完成它们的工作,A和B都应该首先选择要分析的组件,在示例中是一个多维的条形图。对于电机部件,A将VIN和电机温度拖动到相应的输入箱中。通过点击电池温度并选择所提供的汇总方法中的最大选项,将显示所有车辆的最大电机温度的直方图。需要注意的是,这里给出的结果仍然是基于样本数据集的。如果样本集上的显示结果是他们想要的,他们保存这个项目。然后提交一个Spark作业,以对总体执行分析过程。完成后,电机和电池部件的结果图将共享给C制作最终报告。
通过这份报告,工程师发现用户驾驶数据中的动力系统温度分布与零部件供应商提供的温度分布有所偏差。动力系统温度是热管理系统中一些故障的关键。因此,研发人员修改了一些相关测试标准的参数。
5 结语
VRT的最终目标不仅是满足清晰的要求,还要涵盖用户的驾驶习惯,提高研发测试认证与实际使用的相关性,从而减少售后问题和召回成本。然而,该行业仍没有完全整合其用于道路试验,还有很多工作要做。为了应对测试工程师所面临的大数据挑战,我们提出了一个可视化的大分析系统。它是一个自助服务环境,支持整个分析周期——整合、准备、分析和可视化。此外,易于使用的界面和即时建模使业务分析师能够轻松工作,无需额外的IT协助。它还可以促进测试数据的收集和处理,这些数据可以用来更新整个车辆原型,从而减少现实和模拟测试之间的差距。在未来,我们将尝试涵盖更多的商业案例。
参考文献:
[1]Koopman, P. and Wagner, M., “Challenges in Autonomous Vehicle Testing and Validation,”SAE Int. J. Trans. Safety 4(1):15-24,2016,https://doi.org/10.4271/2016-01-0128.
[2]LI Yu-long,PENG Jian,LI Xin-tian. Failure distribution analysis for vehicle road durability test and customer complaint. Machinery Issue 5,Volume 40 (2013).
[3]朱佳琦.基于用户使用数据分析的整车道路试验优化方案[J].上海汽车,2017(03):16-19.
[4]江毓,王骁磊,郑燕萍,王羽尘.与用户使用关联的整车耐久性试验方案确定[J].时代汽车,2017,No.282(06):81-83+85.
[5]Johanson,M.(2011). Information and communication support for automotive testing and Validation.New Trends and Developments in Automotive System Engineering,473.
[6]趙津,张博,潘霞,谢蓉.车联网通信技术及应用前景研究[J].时代汽车,2021(06):15-16+32..
[7]Johanson,M.,Belenki,S.,Jalminger,J.,Fant,M.,& Gjertz,M.(2014,October).Big automotive data: Leveraging large volumes of data for knowledge-driven product development. In 2014 IEEE international conference on big data (Big Data)(pp. 736-741).IEEE.
[8]龚蓉军.基于云计算的轿车道路试验数据存储与分析[D]. 上海交通大学,2017.
[9]Guogang,Q.,Nan,X.,& Fan,Y. (2018,July).The In-Use Performance Ratio of China Real World Vehicles and the Verification of Denominator/Numerator Increment Activity Compliance. In International Conference on Frontier Computing(pp. 1821-1828).Springer, Singapore.
猜你喜欢
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
商(2016年27期)2016-10-17
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
