
基于YOLOX-s的农业害虫检测研究
2023-05-19 07:51:14张剑飞
计算机技术与发展 2023年5期
张剑飞,柯 赛
(黑龙江科技大学 计算机与信息工程学院,黑龙江 哈尔滨 150022)
0 引 言
关于现代农业害虫检测的相关研究,郭阳等[1]为解决人工识别水稻虫害难度大、费时费力的问题,提出了一种自动识别水稻虫害的方法。通过YOLOv3检测算法解决了田间复杂情况下的水稻虫害识别任务。张善文等[2]提出了一种可形变VGG-16模型的田间作物害虫检测方法,引入可形变卷积使网络适应不同形状、状态和尺寸等几何形变的害虫图像,提高了模型特征表达能力,在实际田间害虫图像数据库上的检测准确率达到91.14%。刘凯旋[3]提出使用R-CNN的小样本水稻害虫检测算法,通过数据扩增和预训练加速模型收敛过程,该方法能够有效地识别和检测复杂背景下的水稻害虫。肖德琴等[4]针对黄板诱捕的害虫体积小、数量多和分布不均匀,难以进行害虫识别的问题,提出一种基于改进Faster R-CNN的田间黄板害虫检测算法,该算法在中等密度下平均精度均值达到了89.76%。
候瑞环等[5]针对现有基于深度学习的林业昆虫图像检测方法存在检测精度低和检测速度慢的问题,提出了一种基于YOLOv4-TIA的林业害虫实时检测方法。冯晋[6]提出了基于深度学习的水稻灯诱害虫检测方法,通过对YOLOv3模型主干网络以及聚类算法的改进,检测效果得到大幅提升。姚青等[7]提出改进RetinaNet的水稻冠层害虫自动检测模型,模型采用ResNeXt101作为特征提取网络以及组归一化方法,实现了对水稻害虫的高精度检测。
尽管上述害虫检测方法已经具有了良好的检测性能,但针对该文所要研究的多种类害虫检测,仍然存在以下不足:
(1)大部分检测模型仅使用卷积神经网络进行搭建,但卷积的局部偏执特性会导致模型忽视全局特征信息。
(2)大部分害虫检测任务都是针对单一或少量同类目标,模型使用范围较局限,不能覆盖多种类害虫检测情况。
因此,该文提出了ST-YOLOX-s(Swin-Transformer-YOLOX-s)模型来解决上述问题。
1 相关工作
1.1 YOLOX
YOLOX[8]是基于YOLOv3[9]检测模型改进的无锚框(Anchor Free)单阶段目标检测模型,具有由小到大四种规格(-s、-m、-l、-x)。区别于以往YOLO系列基于锚框(Anchor Base)的设计,YOLOX摆脱了先验框的限制,使模型更易部署到下游任务当中。YOLOX引入解耦预测头,将原有预测任务进行分工,缓解了预测权重的压力。同时YOLOX加入了动态匹配正样本(SimOTA)策略,该策略为不同目标设定了不同的正样本数量,优化了模型正负样本的训练比例。
1.2 Transformer
Transformer[10]作为近期具有开创性的第四代神经网络,在CV领域产生了巨大的影响。先是ViT[11](Vision Transformer)将图片视为文本进行处理,在图像分类任务中取得了极佳的效果。随后的Swin-Transformer[12]将类似卷积神经网络的层次化结构融入Transformer,在降低模型计算量的同时提升了模型预测精度。
2 模型算法改进
ST-YOLOX-s在原有YOLOX-s模型基础上对整体网络进行改进。ST-YOLOX-s采用四尺度特征层检测结构进行预测,通过主干网络(BackBone)提取画面特征,颈部网络(Neck)实现特征融合,最后借助解耦预测头(Head)对目标进行分析预测。ST-YOLOX-s模型具体结构如图1所示。
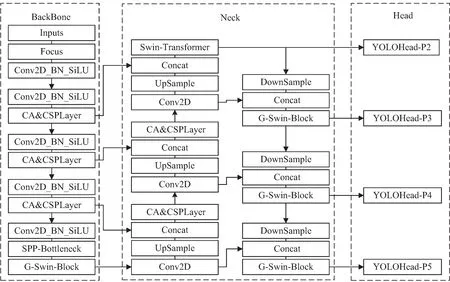
图1 ST-YOLOX-s模型结构
为进一步提高ST-YOLOX-s模型的检测性能,在模型训练前期设计了数据增强策略,借助数据增强技术有效提升数据多样性。与原始YOLOX-s相比,ST-YOLOX-s可以更好地处理多种类害虫检测任务,本次的主要工作如下:
(1)为实现模型对多种类害虫的检测任务,构建了一个包含30类害虫,共计3 956张标注图片的害虫数据集。
(2)为解决模型对小型害虫检测准确率偏低的问题,通过增添P2特征尺度来提升主干网络对微小目标的特征捕捉能力。
(3)为解决模型在复杂环境下多种类害虫目标检测效果不佳的问题,通过使用具有通道注意力机制的CA&CSPLayer以及具有图属性的G-Swin-Block,提升卷积网络对于通道信息以及全局信息的抓取能力。
(4)为进一步实现模型高精度定位,使用α-CIoU损失替换原始的IoU损失。
2.1 提出四尺度特征层检测结构
针对模型对小型害虫目标检测效果不佳的问题,提出了四尺度特征层检测结构改进方案。原网络使用三尺度特征层检测设计,对于640×640的输入图像,分别利用8倍、16倍、32倍下采样的特征图去预测不同大小尺寸的特征目标。但由于本次实验数据中包含较小的害虫目标,原有的三层尺度特征层检测设计对此类目标特征捕获较不敏感。为此,该文在原网络基础上增添了P2特征尺度层。该特征层受主干网络4倍下采样影响,将大小为160×160的特征图送入颈部网络进行特征融合,并将该尺度的预测信息通过YOLOHead-P2预测头进行反馈。YOLOHead-P2预测头受浅层高分辨率特征信息的影响,对微小目标的特征更加敏感。通过对网络结构的整体改进,使得网络可以更加全面地捕获多种尺度的特征信息。
2.2 构建具有通道注意力机制的CA&CSPLayer
针对卷积神经网络关于通道信息关注薄弱的问题,为CSPLayer(Cross Stage Partial Layer)的残差边施加ECANet[13]高效通道注意力,以此来提炼特征图的通道信息权重。该方法有助于弥补卷积神经网络对特征图通道信息关注薄弱的缺点。模型在使用具有通道注意力的CA&CSPLayer(Channel Attention &Cross Stage Partial Layer)后,可以有效引导ST-YOLOX-s模型提取关键通道特征信息,提高模型检测性能。
与原始CSPLayer相比,CA&CSPLayer会对原始的残差边额外施加一个通道注意力权重,以此得到具有通道注意力权重的X1特征图。关于通道注意力权重的提炼,CA&CSPLayer首先会对输入的特征图进行全局均值池化(Global Average Pooling,GAP)操作实现对特征图的维度压缩,随后借助一维卷积核(k)来学习各相邻通道之间的特征映射关系,算法会假设一维卷积核k和通道C之间存在以2为底的非线性指数映射关系,如公式(1)所示:
C=φ(k)=2(γ*k-b)
(1)
通过在通道维数C已知的情况下,一维卷积核k可以通过公式(2)计算得到:
(2)
其中,‖odd表示最近奇数,参数γ和b分别取2和1。
然后借助Sigmoid激活函数实现对通道特征的整合,最后通过与原输入特征图(Input)的结合,生成带有通道信息的特征图X1。生成的特征图X1会与经过残差瓶颈操作的特征图X2做拼接操作,最终实现对特征图的信息整合。CA&CSPLayer整体结构如图2所示。
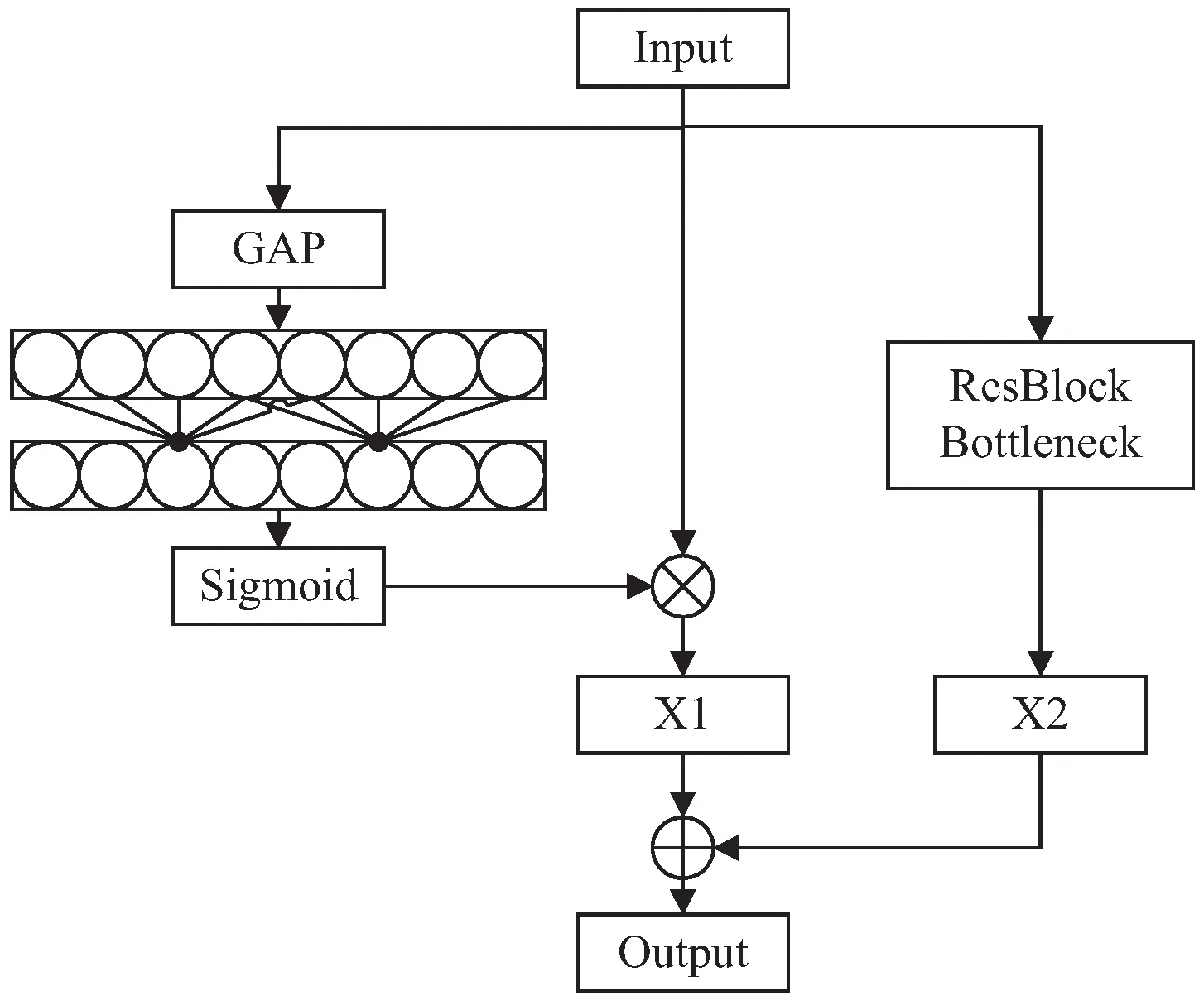
图2 CA&CSPLayer整体结构细节
2.3 构建具有图属性的Swin-Transformer
针对卷积神经网络模型缺乏获取全局特征信息的问题,通过使用Swin-Transformer模块来提升模型的全局特征学习能力,同时借鉴Vision GNN[14]模型的KNN图神经网络,进一步优化Swin-Transformer网络对特征图各局部图块(Patch)间的特征学习。
Swin-Transformer网络模型中使用了Windows Multi-head Self-Attention (W-MSA)以及Shifted-Windows Multi-Head Self-Attention (SW-MSA)两个概念,并通过与MLP(Multi-Layer Perceptron)的结合共同组合成Swin-Transformer模块。而在G-Swin-Block(Group Swin-Transformer Block)模块当中,首先会对输入特征图的每个图块(Patch)利用最邻近节点算法(K-Nearest Neighbor,KNN)进行操作,以此来学习每个Patch间的相互特征关系,更好地引导Swin-Transformer模块关注重点的Patch。同时在该操作前后施加卷积以及批量归一化(Batch Normalization,BN)操作防止特征权重出现过拟合。G-Swin-Block模块具体细节如图3所示。
当特征图进入G-Swin-Block模块后,Graph-KNN网络首先会对特征图每个Patch之间的特征信息进行KNN节点计算,以此来评估各Patch之间包含目标特征信息的权重比例,并最终将比例权重附加到每个Patch上面,具体操作如公式(3)所示。
ωpatchi=GraphKNN(patchi)
(3)
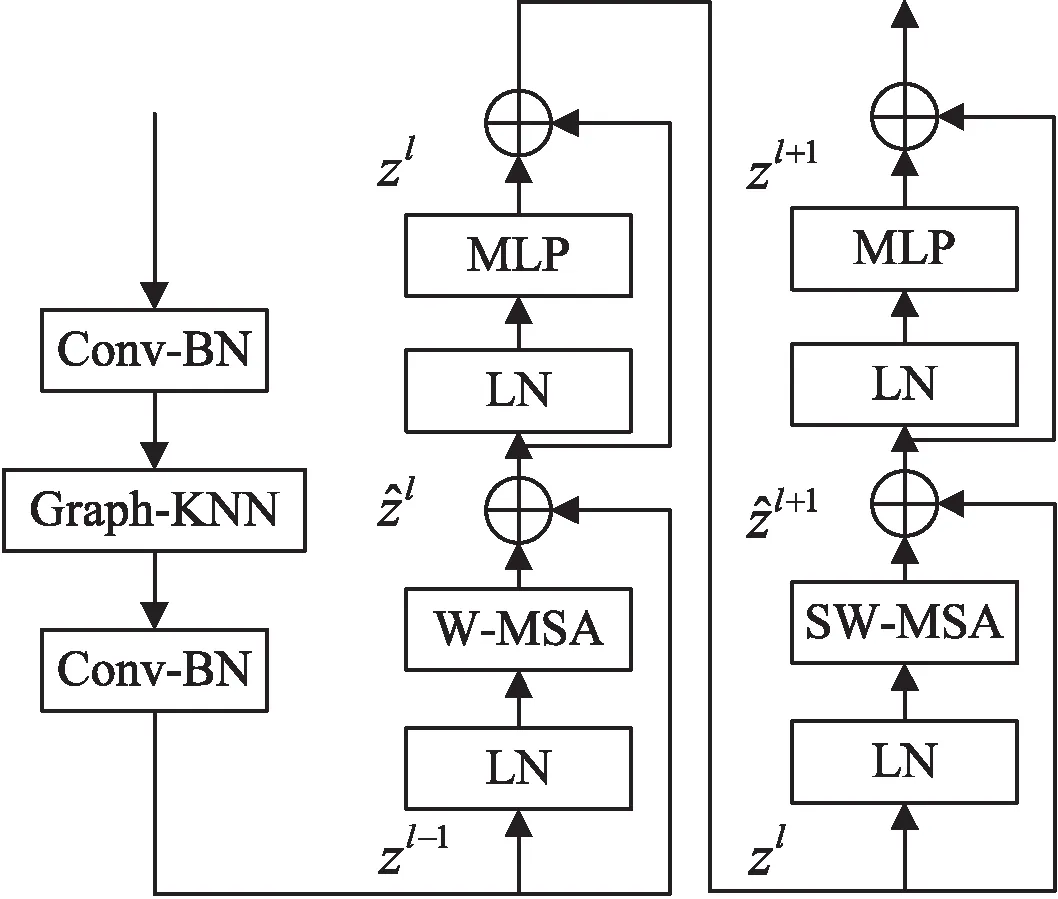
图3 G-Swin-Block模块整体结构
随后进行Swin-Transformer的层次化全局特征学习操作,操作流程如公式(4)所示:
(4)
通过构建具有图属性的Swin-Transformer,有效解决了卷积神经网络模型无法获取特征图全局信息的能力,使得模型检测性能得到提高。
2.4 引入α调节因子的CIoU损失函数
YOLOX-s模型使用交并比损失函数(IoULoss)来计算预测框和真实框的位置损失。该损失方法如公式(5):
(5)
虽然IoULoss具有良好的尺度不变性,但是也存在着两个缺点:一方面,IoU(Intersection over Union)无法精确地反映预测框和真实框的重合程度; 另一方面当预测框和真实框没有交集时,IoU无法反映二者的实际距离大小。为此,该文采用考虑因素更为全面的α-CIoU[15]作为目标检测任务的回归损失函数,该损失函数兼顾了重叠面积、中心点距离以及长宽比三要素,且实际效果优于IoULoss和CIOULoss[16]。α-CIoU回归损失的计算过程如公式(6)所示:
(6)
其中,α为调节参数,β为权重函数,w为框宽,h为框高,b和bgt分别为预测框和真实框的中心点,ρ为计算两个中心点的欧氏距离,v表示长宽比的相似性,c表示能够同时包含预测框和真实框的最小闭包区域的对角线距离。
通过使用α-CIoULoss,有效解决了IoULoss存在的不足。使模型回归框定位更加精准,且检测性能得到进一步提高。
3 实 验
3.1 数据集
为实现对多种类害虫的检测任务,借助LabelImg数据标注脚本,构建了包含:稻纵卷叶螟、稻瘿蚊、稻飞虱、稻象虫、稻叶蝉、蛴螬虫、蝼蛄、金针虫、黄地老虎、红蜘蛛、玉米螟、黏虫、蚜虫、白星花金龟、桃柱螟、麦圆蜘蛛、跳甲、斑蝇、盲蝽、芫菁、瓢虫、葡萄天蛾、斑衣蜡蝉、大青叶蝉、吹绵蚧壳虫、桔小实蝇、枯叶夜蛾、茶树白蛾蜡蝉、褐边蛾蜡蝉、脊胸天牛的30类害虫数据集,详细数据如图4所示。总数据量3 956张,其中单类数据最多212张,最少64张,平均每类130张左右。

图4 害虫数据集详细数据
3.2 数据增强
数据增强可以有效扩展样本多样性,使模型在不同环境下都具备较高的鲁棒性。本次实验除了使用光度失真和几何失真策略外,还使用了Mixup[17]和Mosaic数据增强策略,Mixup会从训练图像中随机选取两个样本进行随机加权求和,该操作可以有效提升检测模型的泛化能力,具体操作效果如图5所示。

图5 Mixup数据增强
Mosaic增强操作会将4幅预处理图像拼接为1幅大图,从而极大地丰富了被检测物体的背景,具体操作效果如图6所示。

图6 Mosaic数据增强
3.3 实验环境
本次实验在Python3.8,CUDA11.3,PyTorch 1.10.0环境下进行。所有模型均在NVIDIA RTX A5000 GPU上进行训练和测试。数据集按照9∶1划分为训练集和测试集,并从训练集中抽取10%作为验证集,模型规格为-s,使用SGD优化器以及余弦退火学习率,BatchSize大小设置为8,总共进行300次迭代训练(最后30次迭代训练会关闭Mixup和Mosaic)。ST-YOLOX-s模型经过300次迭代训练后趋于收敛。
3.4 评估指标
通过使用Python中的pycocotools工具包来计算COCO评价指标。实验最终结果如图7所示,可以看出改进后的ST-YOLOX-s模型的AP50以及AP50-95的检测精度都有明显提升。
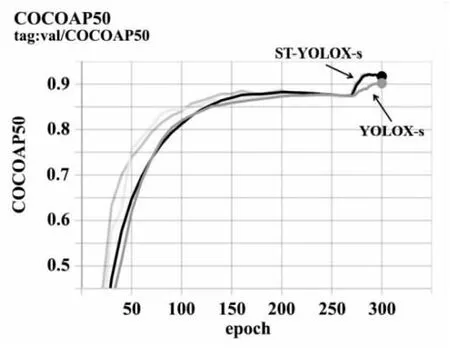

图7 实验训练结果展示
3.5 实验设计与结果分析
3.5.1 消融实验
通过消融实验可以有效反映模型改进成效。如表1所示,在将模型特征检测尺度扩展到P2后,AP50的精度提升了0.47百分点;在加入具有通道注意力的CA&CSPLayer后,AP50的精度提升了0.74百分点;在加入具有图属性的G-Swin-Block模块后,AP50的精度提升了0.22百分点;最后在加入高精度α-CIoU回归定位损失后,AP50的精度提升了0.58百分点。

表1 不同改进方法的实验结果
3.5.2 对比实验
选取的对比模型包括:两阶段目标检测模型Faster R-CNN[18],并选取ResNet50[19]作为其主干网络;无锚框(Anchor Free)的CenterNet[20],同样选取ResNet50作为其主干网络;单阶段目标检测模型中的YOLOv3、YOLOv4-tiny和基于MobileNetV3[21]主干网络的YOLOv4。实验结果表明,ST-YOLOX-s模型具有更好的检测性能,具体实验数据如表2所示。
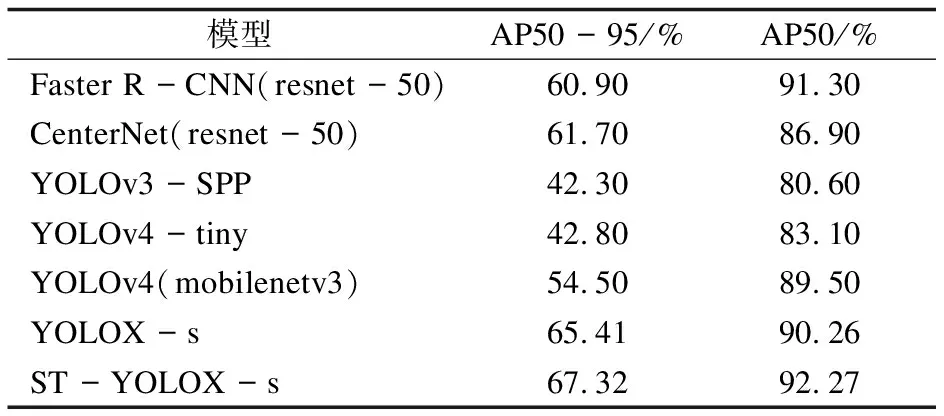
表2 主流目标检测模型性能对比
4 结束语
针对现有目标检测算法难以应对现代农业环境下多种类害虫高精度检测的问题,在YOLOX-s检测模型基础上,通过增添P2特征尺度、构建具有通道特性的CA&CSPLayer、构建具有全局图属性的G-Swin-Block以及α-CIoU高精度回归定位损失,得到ST-YOLOX-s目标检测模型。实验表明,ST-YOLOX-s检测性能优于常用的目标检测模型,最终AP50结果达到92.27%,AP50-95结果达到67.32%。该方法为现代农业高效治理提供有益参考,模型测试效果如图8所示。

图8 部分害虫检测效果
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
好孩子画报(2021年9期)2021-09-26 12:26:31
今日农业(2020年23期)2020-12-15 03:48:26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
现代园艺(2017年21期)2018-01-03 06:42:15
太空探索(2016年5期)2016-07-12 15:17:55
现代农业(2016年5期)2016-02-28 18:42:39
时代英语·高三(2014年5期)2014-08-26 17:01:17
