
基于GNN的文本分类算法研究
2023-05-19 07:55:18于舒娟姚成杰黄丽亚
计算机技术与发展 2023年5期
高 贵,赵 阳,于舒娟,姚成杰,黄丽亚
(南京邮电大学 电子与光学工程学院,江苏 南京 210046)
0 引 言
在信息数字化的21世纪,自然语言处理(Natural Language Processing,NLP)在人工智能研究中的地位越来越重要。作为NLP领域的重要分支之一,文本分类技术常被用于处理复杂多样的文本信息,其主要工作是根据特征对文本进行分类,并为其分配不同的标签。基于文本分类技术,用户可以通过搜索关键词或查找相应标签,快速准确地找到所需信息。
在基于深度学习的文本分类技术中,图神经网络(Graph Neural Networks,GNN)对非欧几里德数据的独特建模方式吸引了学者们的广泛研究。2004年,Mihalcea等人[1]首次将图模型应用于文本分类任务,TextRank通过图论将自然语言中的文本重新定义表示,包括单词、短语、完整句子等。Defferrard等人[2]提出了基于图的卷积神经网络模型Graph-CNN,首次将文本转化为一组词的图的集合,利用图卷积对每个子图进行卷积运算。Yao等人[3]构建了一个简单高效的图卷积网络TextGCN,模型基于词的共现性和词与词之间的相互关系,将待分类的整个文本数据集构建成文本图。该方法考虑了节点的高阶邻域信息,有效提高了文本分类性能。

然而,虽然这些图神经网络和注意力机制方法在文本分类任务上取得了成功,但是在图神经网络的数据增强以及关键信息的权重计算方面还应用较少。在研究中发现,由于GNN的特殊图文转换特征,其在训练数据集较少时容易出现过拟合的问题。此外,由于传统GNN模型的词嵌入方式对高阶领域信息捕捉能力不足,当训练数据稀疏时会对模型性能带来负面影响。
基于以上GNN模型在文本分类任务中所遇到的问题,该文提出了Att-DASA-ReGNN模型。该模型主要有如下三点创新改进:
(1)针对模型训练中容易出现的过拟合问题,在模型的数据特征提取阶段应用了EDA技术和Self-Attention技术。该技术在扩充数据集的同时加强了单词级别的相互联系,改善了过拟合问题。
(2)针对原模型词嵌入方式对维度很高且稀疏情况下的高阶邻域信息捕捉能力不足的问题,在模型中引入了区域词嵌入技术。该技术进一步加强了词级之间的关系,使得模型更容易捕捉高阶邻域信息,从而减轻数据稀疏带来的影响。
(3)为了进一步提升模型的文本分类准确率,在模型的图词特征交互阶段改进了注意力权重提取方式。通过引入三种不同的注意力机制验证模型性能的提升效果,最终确定为Soft-Attention作为该阶段的注意力权重提取方式。
1 相关工作
前馈神经网络是最早用于文本分类的深度学习模型。它们使用词嵌入模型来学习文档中文本表示,将文本中的词向量相加的和或平均值作为输出将其送入前馈神经网络中[7]。2015年,Zhou等人结合CNN和RNN两者的优势,提出了一个C-LSTM模型[8]。该模型首先利用CNN提取高层次的特征,然后将特征送入LSTM以获得句子表示。2017年,王俊丽等人提出了一个ResLCNN模型[9]。该模型不仅将LSTM与CNN结合起来提取更复杂的抽象特征,而且还使用残差来缓解LSTM梯度消失的问题。2018年,谭咏梅等人利用卷积神经网络结合双向LSTM从文本中提取特征[10]。该模型将得到的特征输入全连接层,然后利用语义规则进一步处理分类结果,最终提高了中文文本的分类性能。
图神经网络以其在分类精度的优越性,被广大研究学者应用于文本分类领域。Bruna等人将欧几里德空间卷积转移到图网络中,并为谱域和空间域提出了相应的图卷积方法[11]。Henaff等人将图卷积应用于神经网络,对有和无输入标签的大型数据集都进行分类[12]。Defferrard等人[2]在图谱域定义并应用卷积,解决了Bruna等人的计算高复杂性和滤波器的非局部问题。Li等人提出了一种能够处理任何图结构的图网络,以解决以前的图卷积神经网络面临的固定滤波器和图结构的问题[13]。Huang等人重新改进了图神经网络的结构,将单个文本视作图,用词共现方法构建词之间的关系,最后用图卷积神经网络提取特征,在提升模型性能的同时还减少了不必要的内存消耗[14]。Zhang等人使用门控图神经网络提出了一种基于GNN的归纳式文本分类方法,同时提出了不同的构建文本图的方法[15]。该方法通过训练样本获得词之间的相互关系,该模型对于有较多新词的文本分类数据集效果更好。
数据采样部分如图1所示,简单数据增强技术EDA是Wei等人提出来的一种数据增强方法,包含了四种类型,分别是:
(1)同义词替换:在一个句子中随机抽取其中的词,用这些词的近似词进行同义替换,形成新的句子。
(2)随机插入:在一个句子中随机选择一个词,之后用该词的同义词随机插入该句子中的任意位置。
(3)随机交换:将一个句子中任意选定的两个单词进行互换位置。
(4)随机删除:将一个句子中的任意单词以概率p进行概率性随机删除。
使用EDA对文本进行数据增强后,可以得到数倍于原数据的有效数据。
接着,Att-DASA-ReGNN模型在EDA数据增强后引入了自注意力机制Self-attention。这样做的目的是将增强后的数据集通过两个神经网络层和一个归一化层组成的模块,让提取到的特征拥有更多的细节。自注意力的计算公式可以表示为:

图1 Att-DASA-ReGNN模型
Att(Q,K,V)=ω(QKT)V
(1)
其中,Q是查询向量矩阵,K是键向量矩阵,V是值向量矩阵。
如图2所示,Xi为词嵌入产生的词向量。接着词向量Xi分别与三个矩阵W(q)、W(k)、W(v)相乘得到三个矩阵向量Q、K、V。每一个Qi与所有的Ki进行矩阵乘法得到αij,其中Qi与Ki进行相乘之后需要除一个d,d是Qi与Ki的维度。最后,每一个αij经过SoftMax层之后得到了βij,之后将所有的βij相加即可得到输出b1,即词Xi的自注意力机制得分。

图2 自注意力机制流程示意图
区域词嵌入是专注于学习文本区域特征的词嵌入方法。该方法在进行区域特征表示的同时保留了原本数据集的内部结构信息。其中,区域可以理解为文本中固定长度的连续子序列,用wi表示句子中的第i个词,用region(i,c)表示当前第i个词与该词前后一共2c+1个词组成的短语。Att-DASA-ReGNN模型中,区域词嵌入方式用ew表示第w个词的嵌入,该嵌入可以用矩阵E∈Rh×v表示,其中v表示词汇的大小,h表示嵌入的大小。区域词嵌入的具体流程如图3所示。
为了利用单词的相对位置和本地语境的信息,除了学习单词嵌入外,还为每个单词学习了一个局部的语境单元,表示为矩阵Kwi∈Rh×(2c+1),Kwi中的每一列都可以用来与相应的wi进行相对位置上的上下文词的交互。

(2)
2 Att-DASA-ReGNN模型
Att-DASA-ReGNN主要由四个部分组成:第一部分是自注意力机制Self attention和EDA结合生成的数据增强数据采样部分;第二部分是利用滑动窗口进行图形构建;第三部分为基于门控图神经网络(Gated Graph Neural Network,GGNN)的词特征交互;最后将提取到的特征送入两个多层感知机(Multi-Layer Perceptron,MLP)完成文本的预测分类。图1为DASA-GNN模型的结构框图。
2.1 图形构建和词特征交互
如图1所示,首先将句子中选中的单词表示为节点,接着用单词之间的共现形式表示为边来进行图形构建,图可以用G=(V,E)表示,其V表示图形的节点,E表示图形的边。共现指的是在滑动窗口中单词的相关性,其中滑动窗口大小一般默认设定为3,其中的边都为无向边。Nikolentzos等人[16]将滑动窗口的大小定义为2。他们将图视为密集连接的图,其模型中图消息的传递机制主要是用一个特定的基本节点与其他每一个节点相连,因此在该图中只能得到模糊的结构消息。而门控图神经网络GGNN中为避免图的密集连接导致的单词特征信息模糊,会首先初始化文本数据的词特征来进行节点的嵌入表示,接着将任意一个文档都进行了单独子图表示,因此在模型中词交互阶段部分,单词特征信息能够清晰地传播到上下文中[17]。
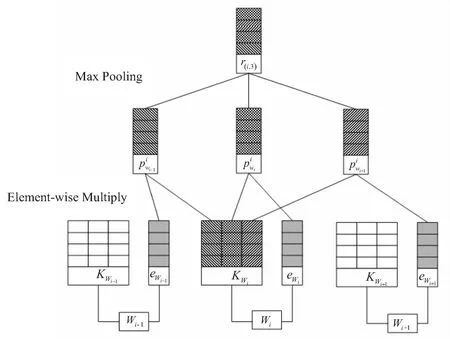
图3 区域词嵌入流程
2.2 特征交互的注意力权重提取方式
为了进一步提升Att-DASA-ReGNN模型的准确率,从模型的图词特征交互的角度出发,在特征交互的注意力权重提取中分别引入了硬注意力、软注意力和多头注意力机制。

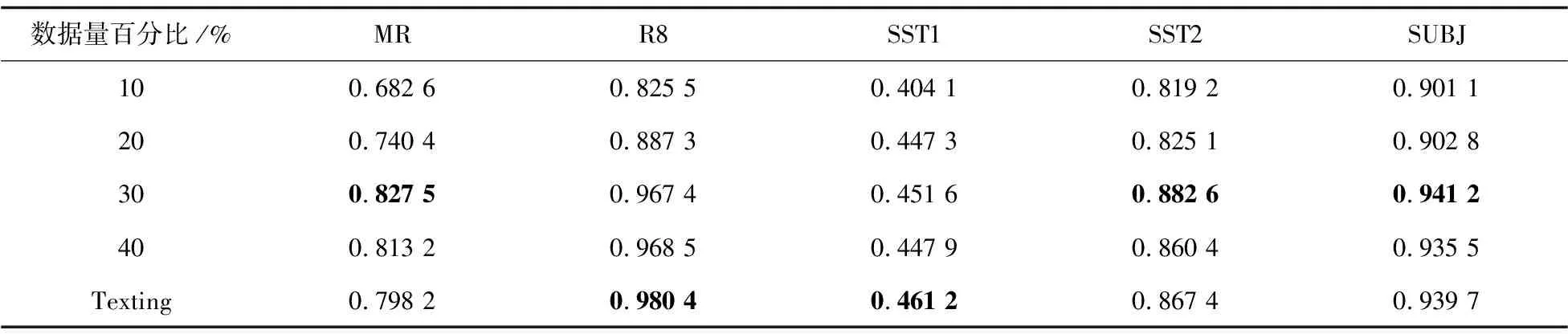
p(st,i=1|sj (3) (4) 在分类问题中,经常被提到的就是软注意力机制。其主要思想是,首先将Source中的构成元素想象成是由一系列的 Attention(Query,Source)= (5) 多头注意力机制是对注意力机制的每个头进行运算,是对于输入Query、Key、Value进行的运算,然后把每个头的输出拼起来乘以一个矩阵进行线性变换,得到最终的输出,其表达式为式(6)。 (6) 本节将在多个不同的数据集上进行一系列实验,验证所提模型的文本分类性能,而且为更精确地展现Att-DASA-ReGNN模型的分类性能,选取了文本分类方面的几种经典算法模型以及最新的研究成果模型作为实验的对照组。 为了验证模型的性能及其稳定性,挑选5种不同的英文数据集来比较模型的分类效果。这些数据集是: (1)MR:MR数据集属于电影评论领域。它是一个二分类数据集,其中每个评论仅包含一句话,分为正面评论和负面评论。 (2)R8:R8数据集属于新闻领域。它是从路透社的新闻专线中收集分类得到的,总共分为8类。 (3)SST1:SST1数据集属于社会领域。它来自于斯坦福情感树库,包括非常消极、消极、中性、积极、非常积极五种类型的数据。 (4)SST2数据集与SST1数据集相同,但去掉了中性评论和二进制标签,只保留了两类标签。 (5)SUBJ数据集是主观性数据集,该数据集用主客观的指标将句子进行二分类。 (6)TREC数据集为问句类型的数据集。 这些实验数据集的详细信息如表1所示。 表1 实验数据集详细信息 为更精确地展现DASA-GNN模型的分类性能,本章选取了文本分类方面的几种经典算法模型以及最新的研究成果模型作为实验的对照组。所选模型按照原理大致可以分为深层神经网络模型和基于图的网络模型,具体介绍如下: (1)CNN(non-static):该模型将卷积神经网络应用于文本分类,并使用了随机初始化单词嵌入来提取句子的关键信息。 (2)CNN(rand):该模型同样基于卷积神经网络,与CNN(non-static)不同的是,它使用了预训练单词嵌入来提取句子关键信息。 (3)BiLSTM(RNN):该模型使用双向LSTM结构进行文本分类,并使用了预训练单词嵌入提取信息。 (4)Texting(GNN):Texting为每个文档构成单独的图,并利用GGNN进行文本分类。 (5)TextGCN(GCN):TextGCN将整个语料库构成一个图,并应用GCN进行文本分类。 为评价文中改进模型对文本分类的有效性,采用准确率作为评价指标。其公式可以表示为: (7) 其中,TP表示真正例,TN表示真反例,FP表示假正例,FN表示假反例。 为了对DASA-GNN模型进行全面分析,本节设计了多组实验。实验1:基于自注意力机制的EDA的数据增强效果验证实验;实验2:基于Dropedge技术的区域词嵌入对模型性能提升效果验证实验;实验3:三种不同的注意力权重提取方式对模型性能提升效果验证实验;实验4:模型超参数设置对模型分类性能的影响实验。具体分析如下: (1)为了更好地了解EDA数据增强的作用及其对DASA-GNN模型的性能影响,实验1选择了Texting作为对照模型,并选择了不同百分比训练数据下的准确率作为对比结果考量。实验结果如表2所示,对于MR、SST2和SUBJ数据集上的实验结果而言,DASA-GNN模型的最佳性能对比Texting模型有2.93百分点、1.52百分点和 0.15百分点的提升,且最佳性能都在30%数据量时出现。对于R8和SST1数据集而言,服务器上得出的最佳结果尽管略微不如Texting模型,但是符合实验预期的结果。由此可见,在模型的数据增强部分加入自注意力层后可以进一步改善数据质量,提升模型性能。 (2)将引入区域词嵌入的DASA-ReGNN模型与七个深度学习领域的算法进行对比,最终对比结果见表3。表中模型在不同数据集上的最佳准确率用加粗字体表示,次优准确率用下划线表示。从表3中可以看出,DASA-ReGNN模型在多个数据集上都表现出了优异的性能。其中,在R8、SUBJ数据集上显示图神经网络具有良好的分类性能,而DASA-ReGNN通过引入区域词嵌入表现得更为优异;与其余六个深度学习领域的经典以及最新的算法的最佳性能相比,DASA-ReGNN还提升了0.36百分点和0.24百分点的分类精度。在除SST1以外的其余五个数据集上DASA-ReGNN都提升了一定的分类精度,表现出了良好的模型性能。 表2 引入自注意力机制的模型性能比较 表3 引入区域词嵌入的GNN与其他网络模型的准确率比较 (3)实验中采用了三种不同的注意力权重提取方式对模型性能提升效果进行验证,其结果如表4所示。从四个模型在不同数据集上的分类结果对比可以得出,在Att-DASA-GNN模型中引入不同的注意力机制可以有效提升文本分类的性能。例如在MR数据集上,DASA-ReGNN的分类准确率为0.829 4,而引入硬注意力机制的Att-DASA-ReGNN模型的准确率可达0.830 0,引入软注意力机制和多头注意力机制的模型准确率提升效果更好,分别为0.841 0和0.832 4。在其他数据集上的提升效果也较明显。 表4 不同注意力权重提取方式效果对比 表5为三种不同注意力机制的Att-DASA-ReGNN模型与传统文本分类模型的性能比较实验结果。由表5可以得出,相对于一些传统模型,三种Att-DASA-ReGNN模型的文本分类准确率均有不同程度的提高,其中以软注意力机制模型Att-DASA-ReGNN+Soft的分类准确率最佳。例如,在MR数据中,性能表现最好的传统模型CNN(non-static)的分类准确率为0.815 0,而三种Att-DASA-ReGNN模型的分类准确率分别为0.830 0、0.841 0和0.832 4,均超过其他对照模型。此外,软注意力机制模型Att-DASA-ReGNN+Soft的分类性能在4个数据集上的分类准确率最高。由此可见,在模型图词特征交互中加入注意力机制的方法可以有效提升文本分类准确率,并且软注意力机制的提升效果最为有效。 表5 Att-DASA-ReGNN模型与其他的 (4)最后,为探究两个重要超参数learning rate和hidden size对模型性能的影响,选择了在R8、SST2、SUBJ和SST1数据集上进行模型训练做进一步测试。实验结果如图4所示。 当hidden size参数不变时,DASA-GNN模型的准确率在learning rate参数数值为0.005时达到最大;当learning rate参数不变时,hidden size参数为 96模型准确率达到最高。例如在SUBJ数据集上,从图4(c)中可以看到,hidden size参数为96的柱形图为模型准确率的最高值,并且其随着learning rate参数的提升而不断升高。由此可见,DASA-ReGNN模型训练中的超参数learning rate和hidden size最优值依旧为0.005和96,模型性能稳定可靠。 图4 Att-DASA-ReGNN模型在不同learning rate和hidden size下的准确性比较 针对现有的基于图神经网络的文本分类方法存在的过拟合、特征稀疏和特征多样性不足等问题,提出了Att-DASA-ReGNN。Att-DASA-ReGNN模型在保留图神经网络中图形编码特性的同时,使用了基于自注意力机制的EDA数据增强技术,同时在图词特征交互阶段引入了区域词嵌入技术改善了高阶领域信息的捕捉问题,最后在图词特征交互阶段改进了注意力权重提取方式。实验表明,相较于其他现有模型,Att-DASA-ReGNN模型在多个不同种类数据集上的分类准确率均有不同程度的提升,性能优越性显著。
3 实 验
3.1 实验数据集

3.2 对比模型
3.3 评价指标

3.4 实验结果




4 结束语
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
中国交通信息化(2018年5期)2018-08-21 03:37:40
数学物理学报(2017年5期)2017-11-23 07:51:31
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
