
基于改进YOLOv5的光学遥感图像水坝检测研究
2023-05-19 07:54:56薛继伟孙宇锐
计算机技术与发展 2023年5期
薛继伟,孙宇锐
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163000)
0 引 言
当今世界科学技术发展的同时也带来了一系列环境问题,生态环境的破坏将会给人们的日常生活带来严重影响,保护环境并及时采取措施已经刻不容缓[1]。水坝是影响全球碳循环和水循环的一个重要因素,对其进行监测是非常有必要的,想要监测水坝首先需要了解水坝在图像中的位置。对高分辨率遥感影像的目标分类识别进行研究,是对地观测系统进行图像分析的一种重要手段[2],目标检测是将图像数据转化为应用成果的关键一环[3]。目前大部分基于深度学习的目标检测算法只针对普通图像,对于遥感图像的一些特征提取能力有待提升[4]。为了环境保护后续工作的开展,该文针对遥感图像中的水坝目标检测方法进行研究,使用检测通用目标的YOLOv5算法进行实验并结合CBAM注意力机制进一步提升水坝目标检测的精度。
1 相关工作
目标检测技术如今已经逐渐趋于成熟,从最初的SIFT[5]、HOG[6]、DPM[7]等传统目标检测算法发展到如今基于深度学习的目标检测算法,目标检测的精度和速度都在不断提高。基于深度学习的目标检测方法的发展主要分为三个阶段,分别是双阶段、单阶段和无锚框阶段[8]。双阶段方法主要有R-CNN系列[9]、SPP-Net等,单阶段方法主要有YOLO[10]系列、SSD[11]、EfficientDet[12]等,无锚框方法主要有CenterNet[13]、FCOS[14]等。
以上方法主要针对普通图像,而光学遥感图像具有背景复杂、目标形状尺度变化大等特征[15],一些学者根据遥感图像的特征在通用的目标检测算法基础上进行改进。R2CNN[16]方法改进了Faster R-CNN算法以适应遥感图像中长宽较大的目标,YOLT[17]方法将YOLOv2模型引入遥感图像检测领域,ROI Transformer方法对水平框采用可学习参数训练方式转为旋转框,再对旋转框内部区域特征池化,R3Det[18]方法对特征图重构解决特征不对齐的问题,SCRDet[19]方法针对遥感图像背景复杂的问题引入并行的像素级注意力机制和通道注意力机制弱化背景信息,提高了检测性能。
目前在光学遥感目标检测领域大部分是针对舰船、运动场以及飞机和机场等目标的研究[20],针对水坝目标的检测方法较少。在深度学习方法成为研究热点之前,对水坝的检测基本上使用传统的目标检测算法。
2020年Zou Caigang等学者[21]使用深度学习的方法提出了基于双阈值的目标检测网络模型,该模型在基本的单级目标检测网络基础上增加双阈值结构,对检测结果进行二次决策,提高了网络检测的准确性,并在水坝遥感数据集中进行测试证明了该网络的有效性。
针对水坝目标的特性,该文使用深度学习目标检测方法YOLOv5模型结合CBAM注意力机制,对水坝目标进行训练及验证,可以使得检测精度在只使用YOLOv5模型的基础上有所提高。
2 目标检测算法研究
2.1 YOLOv5算法
YOLOv5算法是单阶段目标检测方法,网络结构主要分为四个部分,分别是输入端、骨干网络(Backbone)、Neck结构和Head输出层。
输入端为用户输入的图像,YOLOv5在输入端对数据进行缩放、归一化、Mosaic数据增强等预处理。Backbone结构的作用是提取目标的通用特征,最新版本YOLOv5的Backbone包含CSPDarkNet53结构。Neck部分位于Backbone结构和Head结构之间,可以进一步提取特征,提升特征的多样性和鲁棒性。最新版本YOLOv5的Neck结构使用了SPPF和C3模块。SPPF模块通过多个大小为5*5的最大池化层串行传递输入特征大小。
YOLOv5最新版本中的激活函数使用SiLU,该损失函数没有上界,有下界,平滑且不单调,如公式(1)所示。
f(x)=x·sigmoid(x)
(1)
Head结构也是网络的输出层,包含三个预测分支,三个预测分支的总损失乘以batchsize可以得到用于更新梯度的损失。
YOLOv5的损失函数包括定位损失、置信度损失以及分类损失三个部分, 总的损失为三种损失之和。其中置信度损失采用二分类交叉熵损失函数(BCELoss),如公式(2)所示。
(2)
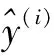
边界框(Boundingbox)回归损失使用CIoU Loss[22]。CIoU Loss考虑了重叠面积、中心点距离、长宽比三种几何参数的计算,如公式(3)~公式(5)所示。
(3)
(4)
(5)
其中,α和v为边界框的长宽比,w和h表示预测框的宽和高,wgt和hgt分别表示GroundTruth的宽和高。b表示预测框中心坐标的参数,bgt表示GroundTruth中心坐标参数。ρ2表示两个中心点之间距离的平方。
2.2 CBAM注意力机制
在计算机视觉领域中适当应用注意力机制可以在一定程度上增强对图像信息的处理。注意力模块能够在大量的信息中提取出重要信息从而增强对重点目标的关注,这种关注是根据不同的分配权重获得。基于深度学习的目标检测中常用的注意力机制模块有SE[23]、ECA[24]、CA[25]、CBAM[26]等。该文在YOLOv5模型的网络结构中添加通道注意力模块与空间注意力模块相结合的注意力机制Convolutional Block Attention Module(CBAM)模块,可以进一步提高网络特征的表达能力。
CBAM模块在SE注意力机制的基础上对通道注意力模块进行了改进,并且增加了空间注意力模块。通道注意力在前,空间注意力在后,这种排列方式增强了模块的特征提取能力。通道注意力机制将输入的特征图经过全局最大池化(Global Max Pooling)和全局平均池化(Global Average Pooling)后,分别经过多层感知机(MLP)得到通道注意力的权重,再经过一个激活函数Sigmoid将注意力权重进行归一化,最后通过乘法加权到原始特征图上,生成空间注意力需要的输入特征。AveragePooling和MaxPooling共用一个MLP可以减少学习参数。
通道注意力模型如图1所示。
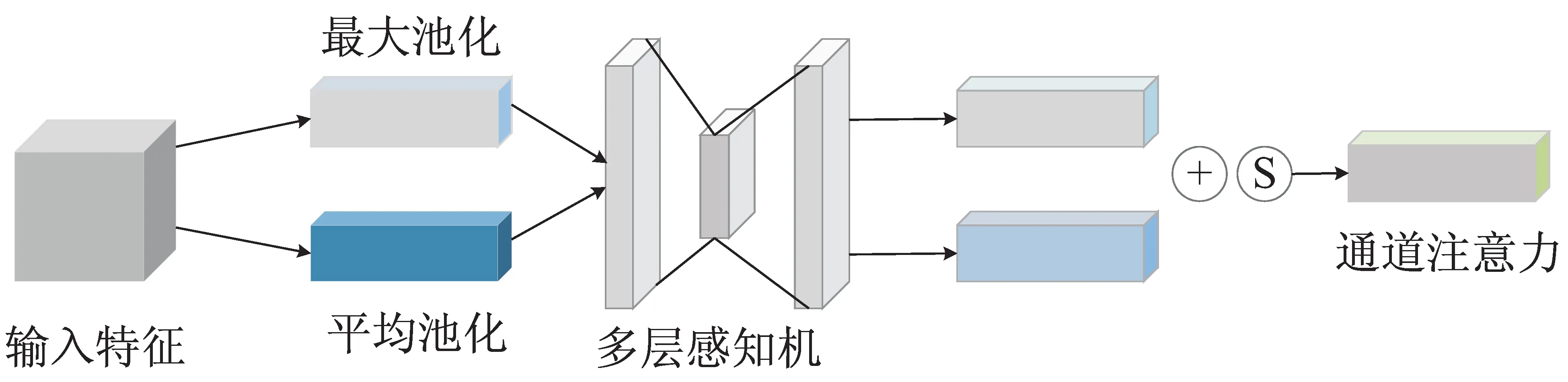
图1 通道注意力模型
空间注意力模块在得到的通道注意力权重基础上进一步操作,与通道注意力部分相似,首先同样需要经过MaxPooling和AveragePooling,将结果进行concat连接,再经过一个卷积层将特征图降维为一个通道。最后同样使用Sigmoid函数乘法加权相应特征,获得最终的空间注意力特征。
空间注意力模型如图2所示。
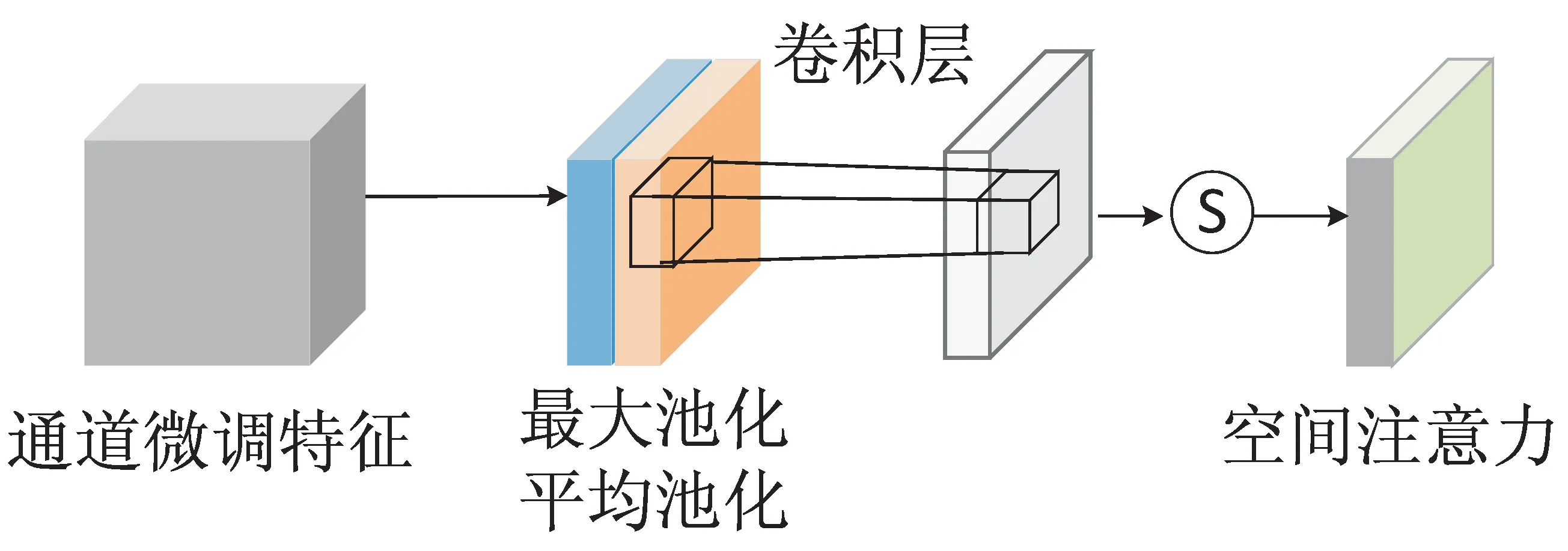
图2 空间注意力模型
文中将CBAM注意力模块插入YOLOv5模型backbone结构中最后一个C3模块与SPPF模块之间,结合CBAM后的模型如图3所示。
图3 YOLOv5+CBAM网络结构
3 实验与分析
针对目标检测三个阶段中的经典算法在水坝遥感目标检测数据集上进行对比实验,并选用其中精度最高的YOLOv5方法进行改进,结合CBAM注意力机制模块进一步提高检测精度。该文使用包含水坝目标的高分辨率遥感图像目标检测数据集DIOR,并对数据集进行预处理,提取需要的图像,舍弃冗余图像,最后对算法进行训练和验证,得到目标检测模型。
3.1 数据集
现有的常用光学遥感目标检测数据集中仅有DIOR[27]数据集含有水坝目标,该数据集使用LabelMe工具标注,共有23 463张图像和190 288个实例,包含了20个目标类,每个类别包含约1 200张图像,其中包含水坝目标的图像987幅。DIOR数据集具有四个特征,图像和实例数量规模较大,目标的尺寸变化范围在不同空间分辨率以及物体类间和类内都较大。以水坝目标为例,在仅含有一个水坝目标的图像中,水坝目标尺寸为大目标,但在含有其他目标的图像中,如在含有高尔夫球场目标和水坝目标共存的图像中,水坝相对来讲是一个小目标,如图4。对数据集中目标大小进行分析,散点图分布如图5,其中左图表示数据集中所有目标标注框中心点的xy坐标,右图表示标注框的高(height)和宽(width),越接近右上角说明目标越大,越接近左下角说明目标越小。

图4 DIOR数据集水坝目标图像示例
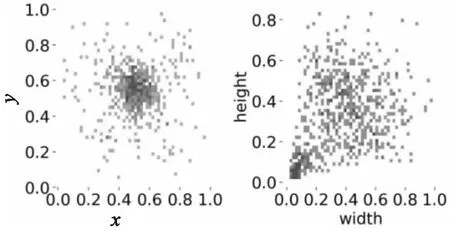
图5 DIOR数据集水坝目标分布散点图
3.2 数据预处理
DIOR数据集的标注格式为VOC格式,为了避免DIOR数据集中其他类别目标对水坝目标检测精度的影响,需要将images文件夹中含有水坝标注信息的图像筛选出来。
由于依旧存在部分图像中含有多个类别的标注信息,需要对标注信息进行二次处理。删除初筛集多类别标注图像中除水坝类别外的其他类别标注,最终得到仅含有水坝类别标注的xml文件。
将数据集进行划分,20%作为验证集,80%作为训练集,网络的输入层将图像大小由800 px*800 px Resize为640 px*640 px并进行一系列缩放、翻转等操作。
在将图像输入到网络之前,需要对数据进行归一化处理,使得数据经过处理后的限制区间为[0,1]。在对比实验中,除了YOLOv5,其他方法在归一化的基础上进行了标准化,使得处理后的数据限制区间为[-1,1]。基于数据的均值和方差进行标准化,即在R、G、B三个维度减去均值并除以方差。在对比实验中除YOLOv5方法外,其他几种方法使用的均值在R、G、B上分别为0.485、0.456、0.406,方差分别为0.229、0.224、0.225。YOLOv5在文中只进行归一化,不进行标准化。
3.3 设备及环境
CPU:Intel Core i7-11800H;
GPU: NVIDIA GeForce RTX3070;
语言:Python3.7;
深度学习框架:Pytorch1.11.0;
CUDA:11.3.0;
编译器:Pycharm2021。
3.4 评价指标
单类别目标检测中的评价指标主要为AP、AP50。目标检测的精确率(Precision)是指一组图像中模型检测出真正例占所有目标的比例,召回率(Recall)表示所有真实目标中被模型检测出的目标比例。根据精确率与召回率的值可以绘制PR曲线,AP即为PR曲线下的面积值,可以用积分计算,如公式(6),其中p表示PR曲线中作为纵坐标的精确率值,R表示作为横坐标的召回率值。对目标检测模型性能的评估通常需要与IoU阈值联系起来,而AP50表示的是IoU阈值为0.5时,AP的测量值。
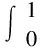
(6)
3.5 训练和验证
该文分别使用双阶段模型FasterR-CNN、单阶段模型YOLOv5、EfficientNet以及AnchorFree模型CenterNet、FCOS进行训练,并选择AP50相对较高的YOLOv5模型进行改进实验。
训练设置batchsize为8,epoch为300,学习率为0.01,YOLOv5模型使用Backbone为DarkNet53,FasterR-CNN、FCOS和CenterNet使用ResNet50作为Backbone,EfficientNet使用RetinaNet作为Backbone。对比实验结果如表1。
在YOLOv5的基础上结合CBAM注意力机制对水坝单目标进行训练,训练设置同上。结果表明添加CBAM注意力机制模块可以提高对水坝目标的检测精度。YOLOv5和YOLOv5-CBAM的PR曲线对比如图6所示,结合CBAM训练得到的best.pt最佳模型在验证集中的AP50可以达到86.4%,未结合CBAM的模型AP50为83.2%。
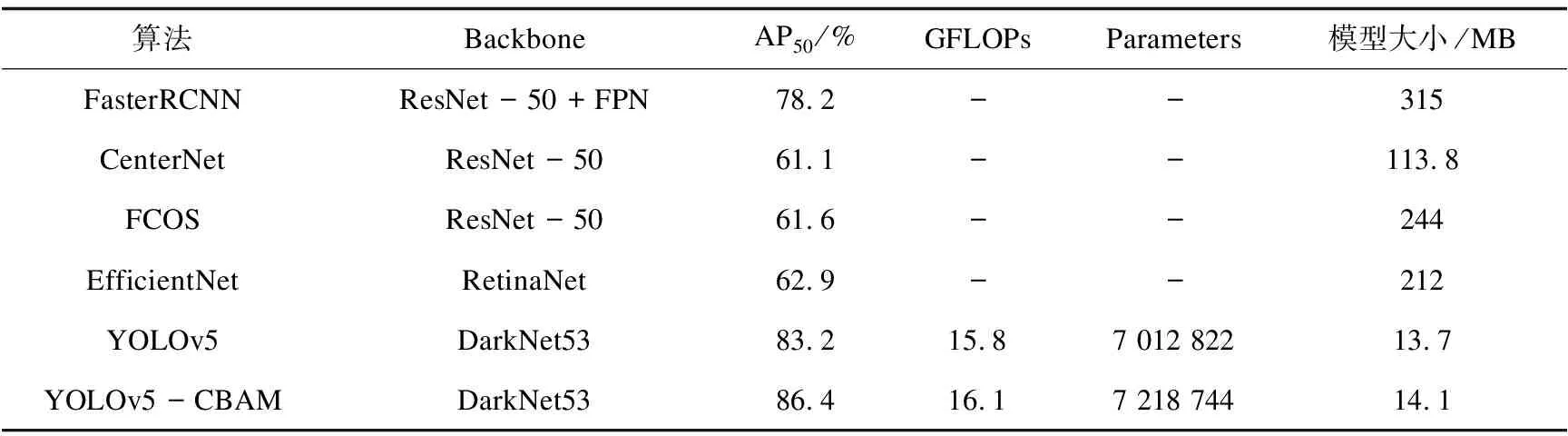
表1 水坝目标检测算法实验结果对比
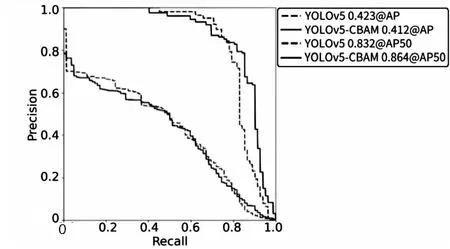
图6 PR曲线对比
在验证过程中发现,有部分图像产生漏检情况如图7左,与其他图像相比水坝在图中目标较小,在下一步的改进中考虑提高算法对小目标的检测能力。图7右中产生了误检情况,检测器将与水坝特征相似的湖泊边沿误检为水坝进行了标记,说明未来算法改进应考虑到与水坝具有相似特征的目标影响,如桥梁等。

图7 漏检和误检情况
3.6 测 试
测试集为根据全球水坝地理位置信息数据集GOODD在谷歌地图中靶向搜索国内水坝图像并进行标注,共100张,将上述训练得到的模型应用于测试集中,测试结果如图8所示,其中上为标签,下为检测结果。


图8 YOLOv5-CBAM检测结果
4 结束语
该文主要针对光学遥感图像中的水坝目标进行检测,在单阶段目标检测模型YOLOv5的基础上在Backbone阶段引入了CBAM注意力模型,该方法结合了通道注意力和空间注意力,增强模型对水坝目标的关注进而提高对水坝目标的检测精度。在验证集上,可以将YOLOv5的AP50从83.2%提升至86.4%,有针对性地单独训练水坝目标可以降低误检率。后续可以根据此模型建立水坝目标检测系统,扩展该模型在遥感图像目标检测范围内的应用。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
中学生数理化·八年级物理人教版(2019年4期)2019-05-20 10:02:34
作文小学中年级(2018年11期)2018-11-22 06:23:26
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
传媒评论(2017年3期)2017-06-13 09:18:10
小雪花·成长指南(2016年1期)2017-02-13 10:22:58
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
科普童话·百科探秘(2015年5期)2015-05-26 07:13:03
