
基于Unity3D三维多视角虚拟数据集构建
2023-05-19 07:51:10郑义桀罗健欣陈卫卫潘志松张艳艳孙海迅
计算机技术与发展 2023年5期
郑义桀,罗健欣,陈卫卫,潘志松,张艳艳,孙海迅
(陆军工程大学 指挥控制工程学院,江苏 南京 210007)
0 引 言
数据集在深度学习模型的训练和测试中起着重要的作用,但现实世界的数据集制作需要耗费大量时间和精力,深度学习多视角三维重建(Multi View Stereo,MVS)的数据集相比于二维图像需要的信息更多,通常需要增加相机姿态和场景深度,制作也更为复杂。
当前已有一些三维重建有关的数据集,主要来源于现实世界,但一些不包含相机标定或深度信息,可作为深度学习MVS训练的数据集并不多,目前常用的主要有DTU[1]、ETH3D[2]和Tanks and Temples[3]等。这些数据集为获取高精度3维场景图像和3维点云,制作均有较高的硬件要求。例如,3种数据集均采用专业高清单反相机拍摄场景图像;ETH3D和Tanks and Temples使用亚毫米级激光扫描仪获取场景深度;DTU在一个6轴工业机器臂上安装了一个相机和一个结构光扫描仪,同时获取图像、深度图和相机姿态。数据集制作也消耗大量人力和时间成本。例如,在Tanks and Temples制作中,每个场景必须进行多次扫描才能密集覆盖表面。简单的物体从4个位置扫描,如小雕像。中型结构物体从8到10个位置进行扫描,如火车;最大的室外场景从14个和17个位置进行扫描,如宫殿和寺庙,尤其宫殿数据集的数据采集持续了两天。且后期还需要进行的点云对齐和优化。
近年来计算机图形学的发展使得虚拟图像设计更加真实。各种渲染引擎的出现,例如UE4,Unity3D和CryEngine,使得逼真的虚拟图像的获取更加方便可行。不需要过高配置的硬件和大量的人力、时间投入,使得虚拟数据集的研究愈加火热,也产生了各种虚拟数据集,例如:用于自动驾驶Virtual KITTI[4]、用于对象检测ParallelEye[5]、用于语义分割SYNTHIA[6]等,大多取得了不错的效果。
大量研究证明了虚拟数据集的可行性,且制作了许多虚拟数据集,但当前还没有专门应用于深度MVS的虚拟数据集。受上述研究启发,该文基于Unity3D提出了一种自动生成三维多视角虚拟数据的方法,并制作了虚拟数据集Visual DTU,通过实验证明了该数据集的有效性。主要贡献有:
(1)提出了一种使用虚拟世界仿真现实世界的方法。融合域适应和域随机方法,通过Unity3D引擎搭建虚拟三维场景,设置虚拟相机,自动控制虚拟相机位置和方向的变换以获取三维多视角虚拟数据,主要包括相机图像、相机参数及场景深度图。
(2)提供了基于Unity3D引擎制作的可用于深度MVS模型训练的虚拟数据集Visual DTU及详细制作过程。该数据集包含了128组图像,每组图像包含了49个相机视角和7种光照强度变化,及每个相机视角的内外参数和每个视角的深度图。
(3)通过实验验证了Visual DTU的有效性,证明了使用虚拟引擎生成的高质量相机图像、场景深度图和相机参数可用于深度学习多视角三维重建模型的训练,同时可大幅降低了数据集制作时间和成本。将该数据集应用于当前主流的几种深度MVS模型,如:CVP-MVSNet[7]、M3VSNet[8]、PatchmatchNet[9]、JADCS-MS[10]等。证明其训练效果基本与真实数据集相当,并在增加训练样本或混合真实数据集和虚拟数据集的情况下可进一步提高模型性能。
1 MVS数据集研究发展
1.1 真实数据集
Seitz等[11]提出的多视角数据集是最早的MVS评估数据集,它仅包含两个具有低分辨率图像和校准相机的室内物体。Strecha等[12]获取建筑立面的真实模型,并为MVS评估提供高分辨率图像和真实点云。为了评估不同光照条件下的算法性能,DTU数据集用固定的相机轨迹获取了128个室内小物体的图像和点云。点云被进一步三角化成网格模型,并被渲染成不同的视点,以生成相机深度图。当前基于深度学习的MVS网络通常使用DTU数据集进行训练。Tanks and Temples使用高清摄像机和激光扫描仪获取室内外不同大小的物体和场景,然而,它们的训练集只包含7个具有真实点云的场景。ETH3D包含一个低分辨率集和一个高分辨率集,涵盖了从自然场景到人造的室内和室外环境不同的视角和场景类型,也是第一个涵盖了手持移动设备的重要使用情况,但是类似Tanks and Temples,ETH3D只为网络训练提供了少量的真实数据。Yao等[13]为提高MVS模型泛化性,制作了BlendedMVS数据集,其中包含了超过17 000张高分辨率图像,涵盖了各种场景,包括城市、建筑、雕塑和小型物体。
1.2 虚拟数据集
相比于真实数据集的高人力和财力需求,虚拟数据集制作更加简单高效,因此近年来使用虚拟数据集训练和测试深度神经网络的做法越来越流行。
当前已有一些虚拟数据集,主要应用于目标检测[14-17]、自动驾驶[4,18]和语义分割[6,19-20]等方面,都取得了不错的效果。由于虚拟数据集与真实数据集之间存在域差,使得虚拟数据集训练的模型在真实数据集的测试不易取得很好的性能。为了提高模型训练效果,目前主要分为两种方法:
一是域适应,即让虚拟数据更接近真实数据。Nogues等[21]利用CycleGAN网络对源域图像进行处理,使其与目标域图像外观上更加接近,这样使用风格转换之后的虚拟数据训练出的网络可以在真实数据集上取得更好的性能。Chen等[22]利用梯度反转层对Faster R-CNN中的图像级特征和实例特征进行对抗训练处理,使得两个特征在源域和目标域的差距尽可能小。Saito等[23]则通过对抗训练方法对全局特征进行弱对齐,对局部特征进行了强对齐,进而实现Faster R-CNN的域适应。
二是域随机。域随机[24]用一种相反的思路,不刻意追求虚拟数据的真实性,而是通过以非照片真实感的方式随机扰动环境,故意放弃照片真实感,迫使网络学习关注图像的基本特征。Tremblay等[25]提出了一个利用合成图像训练深度神经网络进行目标检测的系统。为了处理真实世界数据中的可变性,系统依赖于域随机技术,其中模拟器的参数(如照明、姿势、对象纹理等)以非真实方式随机化。结果显示域随机不仅优于更真实的照片级数据集,而且改善了仅使用真实数据获得的结果。在车辆识别和状态估计实验中[26],将强度响应、模糊、噪声三种因素随机化引入到虚拟图像中,通过特殊的场景车辆布置方法和丰富的背景图片来保证虚拟图片的丰富变化性,以2D包围盒检测作为实例验证虚拟数据集的性能,结果显示该虚拟数据集相比其他虚拟数据集有着明显优势。
2 虚拟场景仿真及数据集生成
在近几年大部分著名的深度学习MVS研究中,均采用了DTU数据集进行模型训练,因此该文参照DTU数据集设置虚拟世界场景并制作虚拟数据集Visual DTU。DTU数据集包含了128组场景,每组场景包含了49个相机视角及7个不同光照的343张图像,以及对应的相机参数和深度图。
如图1所示,首先通过Unity3D设置虚拟场景,而后控制相机视角,同步生成多视角相机图像、相机深度图和相机参数。再对生成的相机图像进行中心剪裁、深度图格式转换、相机参数的坐标系转换,最后组合成虚拟数据集Visual DTU。
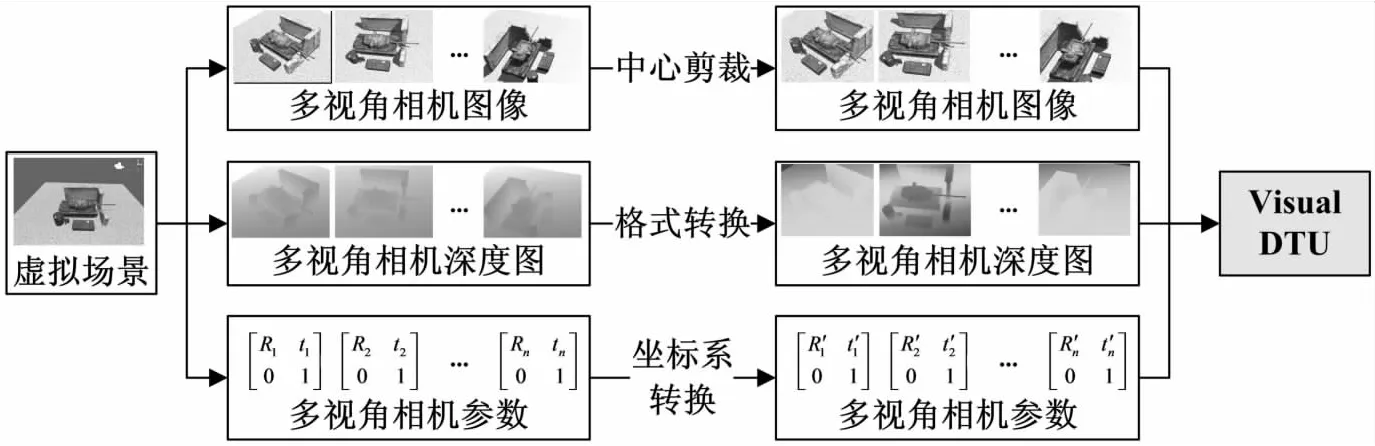
图1 Visual DTU生成流程
2.1 虚拟仿真场景设置

(1)
其中,R为旋转矩阵,t为平移向量。
计算发现49个相机基本部署在同一球面上,因此可拟合出球心坐标,作为物体放置的位置。图2展示了相机和物体位置关系。
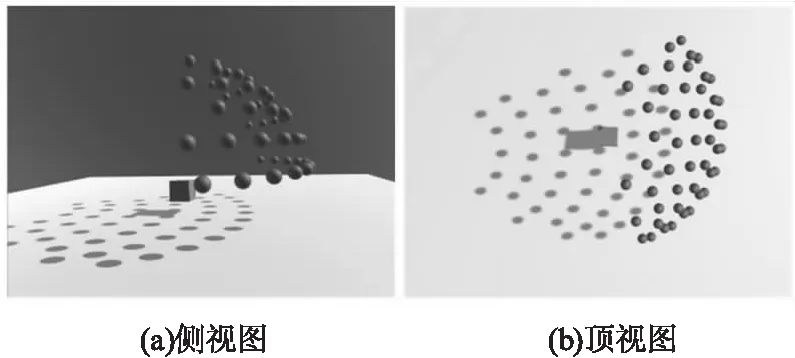
图2 虚拟场景中相机(球体)和物体(立方体)位置
Visual DTU共128组场景,使用已构建好的人物、动物、车辆、建筑、家具摆件等各类3D模型。在设置不同的场景时,分别采用了域适应和域随机的方法。
为实现域适应,部分场景设置采用高分辨率高仿真性物体模型,以尽可能仿真真实世界,图3展示了4组真实物体和虚拟物体的对比,每组图像中,左侧为真实物体,右侧为虚拟物体。同时每个相机视角均采集7种不同光照强度和方向的图像,以增强网络模型对不同光照条件下的适应性。图4展示了不同光照下的场景设置。

图3 真实物体与虚拟物体对比

图4 不同光照强度和方向的场景设置
为实现域随机效果,部分场景采用低分辨率低仿真性的简易物体模型,或采用非真实卡通造型,或在场景中随机加入一些三维物体,或者随机改变物体颜色,以强化网络模型学习图像的基本特征。同时,采用域随机的方式可以无限增加数据集,提高数据集生成速度。图5展示了部分场景中的域随机效果。

图5 域随机场景
2.2 三维多视角虚拟数据生成
该文通过控制虚拟世界中相机位置和方向,获得三维多视角虚拟数据,主要包括不同相机视角的图像、相机参数和深度图。图像和深度图的生成方法采用文献[27]提供的函数“ImageSynthesis”,该函数通过相机挂载可直接生成任意尺寸的相机图像(该文设置1 600×1 200尺寸)和以单通道灰度图表示的深度图(与相机图像尺寸相同)。
相机外参矩阵可由C#库函数“matrix.SetTRS”获得,但有几点区别:(1)该函数采用相机坐标系转换为世界坐标系的外参矩阵,而深度MVS模型采用世界坐标系转换为相机坐标系的外参矩阵;(2)Unity3D使用左手坐标系,而深度MVS模型使用右手坐标系;(3)Unity3D中使用米(m)作为长度单位,而深度MVS模型使用毫米(mm)作为长度单位。因此外参矩阵需要转换。
原外参矩阵为:
(2)
转换后的外参矩阵为:
(3)
其中:
(4)
(5)
(6)
相机内参数需单独设定,可直接在Unity3D中设置。内参矩阵一般表示为:
(7)
其中,f代表相机焦距,单位毫米;1/dx代表x轴方向1毫米内的像素个数;1/dy代表y轴方向1毫米内的像素个数;(u0,v0)代表图像原点位置。由于虚拟相机图像和相机传感器的宽和高可以直接设置,因此相机内参矩阵可由公式(8)计算得出。
(8)
其中,Wpic和Hpic代表相机图像的宽和高,单位像素;Wsen和Hsen代表相机传感器的宽和高,单位毫米。
2.3 多视角三维重建虚拟数据集构建
为能适用当前大多数深度MVS模型的训练需要,按照文献[28]中图像的处理方法,将原始1 600×1 200尺寸的相机图像降采样为800×600尺寸的图像,然后进行中心裁剪得到640×512尺寸的图像。与图像大小变化相适应,相机外参数保持不变,内参数减小1倍。
深度图根据不同的深度MVS模型训练需求进行相应降采样和剪裁,但初始深度图是单通道灰度图,每个像素点对应1个0~255的灰度值,因此需要将其转化为真实深度值。通过公式(9)可进行灰度值与深度值的转化。
(9)
其中,Vgrey为像素灰度值,far和near分别为相机的远、近剪裁平面的距离。为方便计算,该文设置为far=10,near=0.01。
3 实 验
将Visual DTU与当前流行的几种真实MVS数据集进行对比,以验证Visual DTU的有效性。主要采用2个评价指标:一是数据集制作的时间和经济成本;二是采用不同数据集训练的MVS网络模型的三维重建效果。三维重建效果采用DTU数据集提供方法评估。主要包括准确性(Acc.)、完整性(Comp.)和总体性(Overall)。准确性(Acc.)以重建的三维点云与真实物体点云的距离来衡量,表示重建的点的精度;完整性(Comp.)表示物体表面被重建的完整程度;总体性(Overall)是准确性和完整性的平均值,是一个综合的误差指标。3种指标的值越小代表误差越小。
然后,通过改变训练样本数量、混合真实数据集和虚拟数据集的方式分析Visual DTU的使用规律,以达到最好的训练效果。
3.1 数据集制作成本对比
该文主要对比了Visual DTU与当前流行的几种真实数据集(ETH3D、Tanks and Temples、DTU)在数据采集过程中的经济和时间成本。结果如表1所示,其中价格是依据各数据集进行数据采集所需的主要设备计算得来,具体是参照该型号设备的当前价格,对于原始论文中没有说明设备型号的情况,则按照同类型设备的均价计算。

表1 数据集制作成本对比
从经济成本看,真实数据集所需设备成本都比较高。例如,ETH3D和Tanks and Temples所采用的如Focus3D X330激光扫描仪需花费几十万,各种高清相机也需数万元。而且,该文并未将一些辅助设备列入。例如,DTU为了产生光照变化的场景而设置了16个LED灯,Tanks and Temples为了获取更稳定的图像而使用相机云台。而相比之下,制作Visual DTU仅需一台普通的笔记本电脑(该文采用的是联想Air15),可大幅度降低经济成本。
从时间成本看,真实数据集时间消耗普遍较大,尤其Tanks and Temples和ETH3D需采集室外大范围场景数据,而室外容易受到自然环境或人为运动的影响而出现采集失败的情况。DTU主要是室内小场景,通过机器臂完成视角转换,速度相对较快。而Visual DTU完全由电脑自动计算完成,不会受到外界的影响,可快速完成数据采集工作;时间消耗与场景类型无关,且时间消耗将随着主机性能的提高而降低。
3.2 Visual DTU和DTU训练效果对比
使用当前比较流行的几种有监督(CVP-MVSNet[7]、Patchmatchnet[9])和无监督(M3VSNet[8]、JDACS-MS[10])深度MVS模型进行对比实验。有监督深度MVS模型训练需要输入相机图像、相机参数和场景深度图,无监督深度MVS模型训练仅需要输入相机图像和相机参数,不需要输入场景深度图,因此在两类模型上比较更具有一般性。实验均使用Pytorch实现,在4个NVIDIA GTX 1080Ti GPU上进行训练。和原模型训练方法相同,采用79组图像作为训练集,除因主机内存限制而降低个别模型训练的批大小外,其余各训练参数设置均与原模型相同。为方便对比,训练后的模型均采用DTU数据集中的22组图像进行测试。模型在深度估计后均重建了场景的三维点云。

表2 Visual DTU与DTU数据集训练效果对比

图6 不同数据集重建效果对比
表2展示了测试结果,括号内表示使用的数据集。从表中数据可以看出,采用虚拟数据集Visual DTU训练的模型的重建效果基本与采用真实数据集训练的模型相当,有监督模型总体重建效果平均差距仅0.012 5 mm,无监督模型总体重建效果平均差距仅0.014 5 mm。证明由Unity3D生成的相机图像、场景深度图和相机参数与实际比较相符,可以作为深度MVS模型的训练输入,而该文制作的虚拟数据集Visual DTU一定程度上可代替真实数据集DTU用于模型的训练。图6展示了各深度MVS模型采用不同数据集训练后重建的点云效果,直观上可看出两种数据集训练的模型重建效果基本相当,只在一些细微的地方有所差距。
3.3 Visual DTU训练样本数量变化对比
上文证实,当采用相同数量的Visual DTU样本进行深度MVS网络训练,基本可达到采用真实数据集DTU训练的效果,但还是有一些差距。因此,本节分析了增加训练样本的情况下三维重建效果的变化。将Visual DTU训练的场景数量从80逐步增加至130,总体性误差随训练样本数量变化如图7所示。由图7可以看出,训练样本数量逐渐增加时,总体性误差承下降趋势,最终总体误差能小于原先采用79个DTU场景训练的情况。由此可以看出,虽然虚拟数据集Visual DTU与真实数据集DTU还有一些差距,但可以通过增加训练样本数量来弥补。但从总体误差变化趋势也能看出,增加训练样本并不能无限降低误差,误差的决定因素还是深度MVS网络的结构设计,仅通过增加训练样本很难突破深度MVS网络本身的不足。
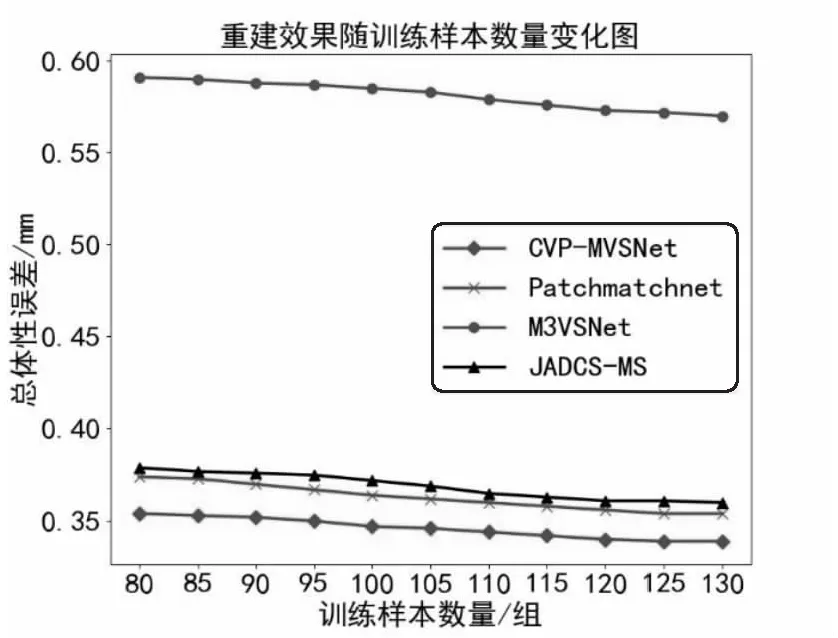
图7 重建效果随样本数量变化
3.4 混合数据集训练
本节研究了深度MVS模型在Visual DTU与DTU两种数据集上共同训练的情况。分别采用3种混合训练方式:(a)两数据集随机混合成一个更大的整体,而后在这个更大的数据集上进行训练;(b)先用DTU数据集训练,后用Visual DTU数据集训练;(c)先用Visual DTU数据集训练,后用DTU数据集训练。选用CVP-MVSNet进行对比实验。训练时,除第一种方式中训练样本扩大一倍意外,其余各参数设置均与3.2节相同。测试同样采用DTU测试集的22组图像,表3展示了仅用一种数据集训练和混合数据集训练的重建效果对比。
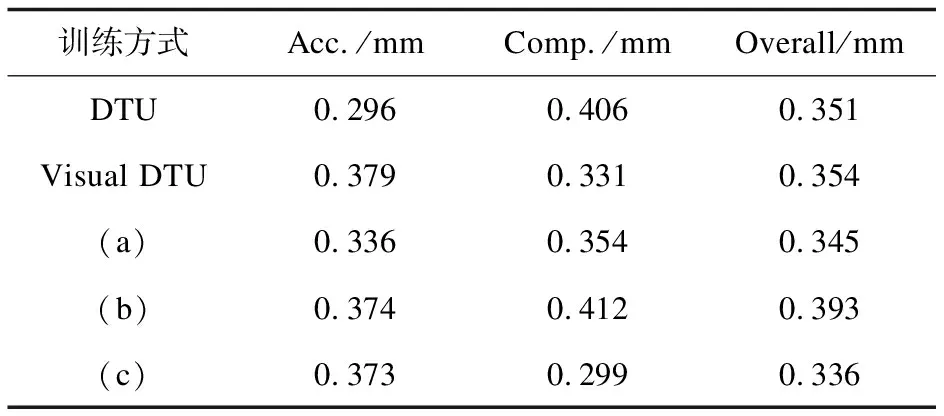
表3 混合数据集训练效果对比
从表3可以看出,3种混合训练方式的重建结果有很大区别。采用整体混合数据集训练的重建效果虽然精确性误差比DTU数据集要低,完整性误差比Visual DTU低,但总体性误差要优于仅采用一种数据集训练。先用Visual DTU数据集训练、后用DTU数据集训练的方式的重建效果最好,各个指标均比仅使用Visual DTU训练的模型更好,整体性误差比仅使用DTU数据集降低了4.27%,比仅使用Visual DTU降低了5.08%。但是,先用DTU数据集训练、后用Visual DTU数据集训练的方法的重建结果反而比仅使用一种数据集训练更差。分析主要原因,是由于测试采用的是真实数据集DTU,因此模型后期采用Visual DTU训练反而会使预测值与真实值增大偏差。由此可得出结论,先采用虚拟数据集预训练,后用真实数据集训练可以达到最好的模型训练效果。
4 结束语
基于Unity3D提出了一种虚拟世界仿真现实世界的方法,通过Unity3D引擎搭建虚拟场景,设置虚拟相机,自动同步生成三维多视角虚拟数据,并制作了虚拟数据集Visual DTU。通过大量实验证明,虚拟引擎生成的高质量相机图像、场景深度图和相机参数可用于深度MVS模型训练,且该方法可大幅度降低了数据集制作的成本和时间。证明了虚拟数据集Visual DTU基本可以代替真实数据集,并可通过增加样本数量可弥补与真实数据集直接的差距。同时,采用虚拟数据集预训练、后用真实数据集训练的方式可进一步提高训练效果。
在未来的工作中,将进一步研究数据集与深度MVS网络性能的内在关系,以达到可以通过设计特定的数据集来提高特定网络的重建效果。并进一步通过Unity3D设置更复杂的大场景或运动场景,提高深度MVS网络的鲁棒性和泛化性。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
计算机应用(2019年3期)2019-07-31 12:14:01
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
