
基于加强图像块相关性的细粒度图像分类方法
2023-05-19 07:54:48朱子奇
计算机技术与发展 2023年5期
王 坤,朱子奇
(武汉科技大学 计算机科学与技术学院,湖北 武汉 430065)
0 引 言
细粒度图像分类又称之为具体子类别图像分类[1],目的是对粗粒度大类别进行更为精细的子类区分,比如识别不同的飞机、鸟、车、狗等[2-4]。不同于人脸识别等传统对象级分类任务,细粒度图像任务难点在于类间差异小类内差异大[5],比如两种外形十分相似的狗属于完全不同的品种,由于存在光照、遮挡、背景干扰等诸多不确定性元素,借助肉眼很难分辨。因此,细粒度图像分类任务相比于传统图像分类任务难度更大。
解决细粒度图像分类问题的关键是对目标对象进行有效检测,并从中提取出具有区分性的局部特征。最近,随着Transformer架构在NLP的机器翻译[6]等相关研究领域取得显著成果,许多研究者将Transformer架构逐渐迁移到计算机视觉任务上,比如图像分类[7]、目标分割[8]等。Alexey等人[7]将Transformer架构直接应用到图像分类任务上提出ViT模型,显著提高了传统图像分类任务的性能。作者思路是直接把图像分割成固定大小的图像块序列,然后通过线性变换得到图像块嵌入向量,这也就类比于NLP中的词序列和词向量,然后将图像块嵌入向量和一个空白的分类标记向量[7](class token)直接送入多层编码器进行特征提取分类。
由于Transformer的自注意力机制在整合全局信息方面比CNN更有优势,能够获得特征长距离依赖,因此基于ViT框架的一系列方法在计算机视觉领域的一些任务上表现出色。但ViT基于其自注意机制对图像关注区域并非总是有效,结合注意力层捕捉到的注意力图的可视化效果,发现还是会存在捕捉区域与目标区域重叠度低的现象[9]。
同时ViT也有其固有缺陷:(a)对于图片局部区域特征的关注度不够且容易受光照等不确定因素干扰[9];(b)切割图片带来的关键特征不完整表达[10];(c)其注意力计算方式需要综合全局信息导致计算量非常大[10]。考虑到细粒度图像分类任务中图片局部区分性特征的表征能力对分类效果十分关键,许多研究工作都围绕着如何让ViT模型提取出更具区分性的特征而展开,但是对图像块输入特征做处理的工作非常少。而且编码其中的多头注意力机制主要通过建立所有图像块向量联系来发挥作用,但所有的图像块起到的作用并非相等。
针对以上问题且结合提取图像区分性局部特征对细粒度图像分类任务至关重要的实际情况,在现有ViT工作的基础上,该文提出一种基于加强图像块相关性的细粒度图像分类方法。首先,通过赋予图像块相关性权重系数并对图像块相关度进行评价差异化,加强对局部区分性特征的关注。其次,为了降低分割图像对某些区分性图像块造成的特征不完整表达,引入图像块位置信息加强图像块特征上下文信息的联系。最后,在交叉熵损失函数基础上增加相似损失函数,更有利于细粒度图像分类任务中降低相同子类别差异性。整个方法模块以嵌套方式应用于不同层次的编码器中,融合了不同层次特征信息。结合实验结果证明了该方法思路可行,进一步提升了ViT框架在细粒度图像分类任务上的表现效果。
1 相关工作
对于现阶段的细粒度图像分类模型可以按照模型使用了多少辅助信息分为强监督分类模型和弱监督分类模型[11]。同时,最近基于ViT框架的分类模型在许多视觉任务上取得了良好效果,这类模型具有弱监督的分类思想,许多研究工作基于此展开。
1.1 强监督分类模型
在细粒度分类任务上采用强监督分类模型主要是通过数据集提供的额外标注信息训练出一个网络模块,这个网络可以检测出目标物体边框以及部分物体部位的标注框,然后将这个网络获取到的特征信息在主干网络上进行特征调整、融合等操作,最后通过训练分类在细粒度图像分类任务上取得了较好的效果。比较有代表性的工作有Part-based R-CNN[12]、Pose-normalized CNN[13]等。
1.2 弱监督分类模型
基于弱监督学习的细粒度分类模型在不借助标注信息的情况下,也实现了对全局特征和局部特征的较好捕捉。Lin等人[8]提出的双线性卷积神经网络模型(B-CNN),通过两个VGG-Net[6]网络提取特征,并在特征送进全连接层前对两个分支提取出的特征进行双线性融合操作,有效提升了特征表征能力。但网络模型参数量太大导致训练效率非常低,且VGG-Net特征提取网络对目标物体区分性局部部位的关注度不够等问题对最后分类效果产生了一定影响。Xiao等人[13]提出的两级注意力模型,首先在图像上生成大量候选区域并过滤保留包含前景物体的候选区域,然后利用网络的两个特征分支分别对物体级特征和部位级特征进行提取并融合,最后进行SVM[10,14]分类。Fu等人[15]提出的循环注意卷积神经网络(RA-CNN)提出使用注意力区域网络(APN)定位出图像中的目标物体区域,并进行裁剪放大操作,然后将其送进下一层网络获取物体部位级别的图像,在最后一层网络融合物体级和部位级特征进行预测分类。
1.3 基于ViT架构的分类模型
ViT框架在传统图像分类任务上表现很出色,主要因为其工作机制就是利用自注意力机制捕获全局上下文的特征信息。许多工作基于ViT展开,如DeiT[16-17]进一步探索了ViT架构如何保证数据高效训练和特征提取。CrossViT[18-19]探索了ViT架构在多尺度情况下的表现,将不同尺度的图像块的特征提取并进行有效融合,取得了非常理想的分类效果。TransFG[20]是第一个将ViT架构应用在细粒度图像分类任务上并取得优异表现的网络。主要工作是在最后一层编码器之前,提出部分选择模块PSM来选择与物体目标区域相关度大的图像块向量,然后和分类标记向量一起作为最后一层编码器的输入进行后续预测分类。
许多研究工作都围绕着如何让ViT模型提取出更具区分性的特征而展开,但是对图像块输入特征做处理的工作非常少。并且编码器中的多头注意力机制主要通过建立所有图像块向量联系来发挥作用,但所有的图像块起到的作用并非相等[20]这一特性在之前的工作中研究并不多。因此,该文是基于ViT架构如何学习到图像块作用的量化值,使后续阶段的多头注意力机制学习到比较重要的图像块特征。同时为了学习到相同类别之间的差异性,提出相似损失函数来优化模型,提升任务效果。
2 文中方法
2.1 赋予图像块相关性权重
自注意力机制捕捉全局上下文信息在视觉信息中就是计算图像块向量的注意力;由于这个过程容易忽略图像局部区域信息,而对于局部上下文信息,即图像块之间的联系,会想到利用卷积操作的特性来使模型可以学习到不同图像块特征的重要程度,这样就从全局和局部两种互补角度使模型更适合细粒度图像分类任务。对于每一组输入向量A∈R(N+1)*D,N代表图像块向量个数,D代表向量维度,通过池化操作,学习到代表每个向量的感受野值:
wi=fpooling(Ai),i∈(0,1,…,N)
(1)
其中,fpooling为平均池化函数。
然后,经过全连接层和激活函数层来捕获图像块向量的相关性,得到和图像块特征数量相等的一组特征权值。
(2)
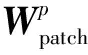
为了更好地提取到具有区分性的局部特征,引入相关度评价函数fα对权值进行过滤,得到一些对细粒度分类任务比较重要的图像块特征。具体做法是首先将上一步得到的图像块特征权值利用排序函数fsort进行降序排序返回代表各权值大小序号的向量组,所以图像块特征并没有被打乱顺序,在相关度评价函数fα中引入图像相关度因子α代表保留的图像块特征数量,经过大量实验证明保留前70%的图像块区域向量效果最佳即α=0.7,剩下的图像块权重值设置为零,这种处理方式抑制了许多的不相关信息表达,同时在一定程度上降低了注意力计算量。最后将所得权值与对应输入向量加权相乘得到加权特征:
Apatch=A⊙fα(fsort(∂patch),∂patch)
(3)
(4)
相关度评价函数fα里Wrank代表权值向量组里面的排序情况,∂代表具体权值,fts函数确定保留图像块区域的权值阈值。模型框架如图1所示。
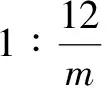
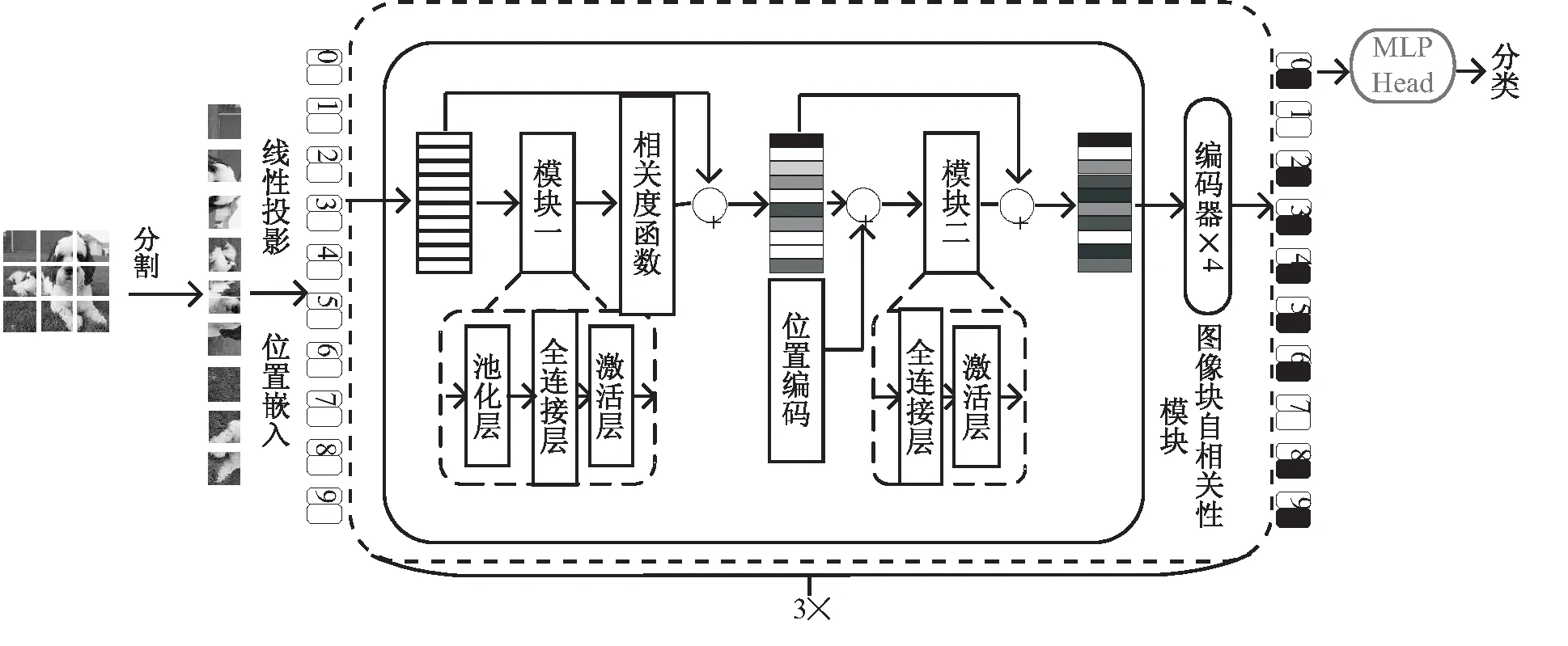
图1 模型框架
2.2 嵌入位置信息加强局部区域特征表达
由于图片分割成一组图像块的操作会使局部区域的特征表达不完整[20],特别是当细粒度图像分类任务所需的类间区分性特征因分割操作受到影响时,就会降低分类精度。为了降低这种影响,可以选择把图片分割成互相有重叠区域的图像块[20],即:
(5)
其中,H、W代表原始图像的分辨率,P代表分割后图像块的分辨率,因为这里分割成的图像块为正方形,所以P也就代表分割后的图像块的长度和宽度,S代表卷积核的滑动窗口大小,也就是实现了重叠的图像块划分,得到的N就是一张图片被分割成多少个图像块。但这也会造成计算量的增加,特别是在分辨率较高的数据集上,会对实验环境产生很高的要求。
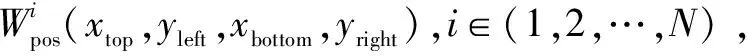
∂pos=σ(W1⊗(Wpos⊗Apos))
(6)
Apos=W2⊗Apatch
(7)
其中,N标识图像块数量;Apos的维度为4*d,d是图像块特征向量维度;(xtop,xbottom)和(yleft,yright)分别代表图像块区域的左上角和右下角坐标。最后学习到的权重信息∂pos与上一阶段的图像块向量相乘作为编码器的输入向量:
Aecd=Apatch⊙∂pos
(8)
2.3 损失函数
为了模型更好地关注到细粒度图像特征,文中方法选择把输出向量中的分类标记向量z即第一个向量作为评价标准,考虑到细粒度图像分类任务子类别之间的差异非常小,为了尽可能学习到这个微小特征的差异性,在交叉熵损失函数基础上增加了相似损失函数Lsim,使相同标签对应的分类标记向量差异性最小化,提升任务效果。
(9)
其中,fcos是计算余弦相似度函数。所以整体模型的损失为:
(10)
其中,Lcross为交叉熵损失函数。在Ltotal的基础上,模型不断训练优化,最后使得整个网络拟合,模型提取出具有区分性的局部特征的能力显著提升。
3 实验与分析
3.1 数据集介绍
CUB-200-2011鸟类数据集包括200种鸟类,共11 788张图像,其中有5 994张训练图像和5 794张测试图像,每张图像均有图像类标记信息,包括鸟的标记框、鸟的关键部位信息,以及鸟类的属性信息。Standford Dogs犬类数据集包括120种犬类,共20 580张图像,其中12 000训练图像和8 580张测试图像,每张图像有类标记信息和的标记框,关键特征包括毛发颜色、鼻子。
3.2 实验参数
采用基于ViT-Base/16的ImageNet21k数据集预训练模型[7]。首先,将输入的原始图像进行预处理。预处理包括将图像像素大小随机缩放,然后裁剪到448*448的像素级别,并对裁剪后的图像进行随机旋转,其中对用于训练的数据集进行随机裁剪,对用于测试的数据集进行中心裁剪。实验中统一把图片分割为16*16大小的图像块,滑动窗口步长大小也为16,Batchsize大小设置为16,Epoch大小为100。网络权值更新使用SGD优化器,SGD优化器的动量设置为0.9。CUB-200-2011数据集的学习率设置为0.03,Standford Dogs数据集的学习率设置为0.003。所有实验均使用了三张NVIDIA GeForce RTX3090 GPU,在Linux系统上运行并基于Pytorch框架,借助了Apex工具。
3.3 消融实验
为证明加入赋予权值模块和嵌入位置编码信息对分类效果的影响,采用ViT作为基准模型,分别对不加入位置编码信息和加入位置编码信息的加强图像块相关性两种模块进行消融实验。采用交叉熵损失函数和相似损失函数,对三种模型分别训练40次,实验结果如表1所示。
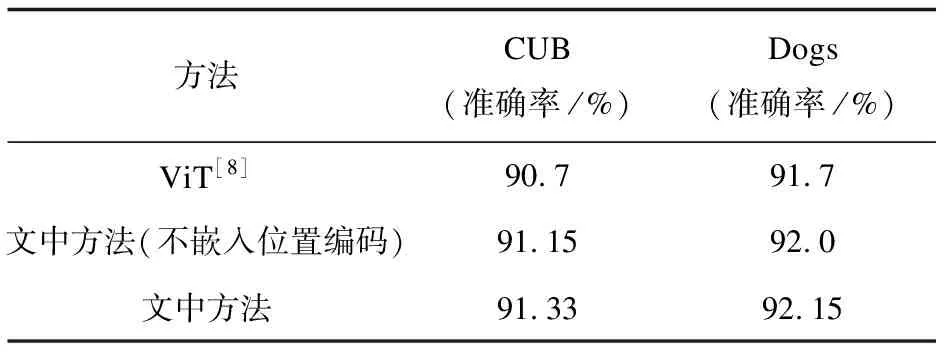
表1 消融实验结果
可以看出,与基准相比,两种模型的准确率均有提升,且因为加入位置编码信息的模型提升了局部区域上下文信息的利用率,较之没嵌入位置编码信息的模型也有提升效果。说明提出的方法能使模型学习到更多局部区分性特征,并降低了分割图片带来的特征不完整表达影响。
3.4 嵌套比和图像块相关度因子选取实验
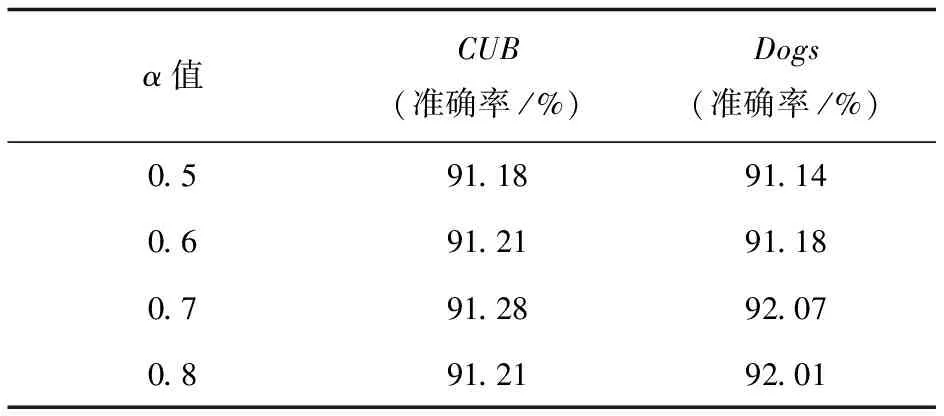
表2 不同α值实验结果
然后调整嵌套比的m值,如表3所示,当把模块叠加到编码器中时,效果都会提升,当m大于等于3时效果相当,但为了减少计算量,应尽可能把模块嵌入数量降低,所以m取值3比较好,也就是嵌入三个模块。
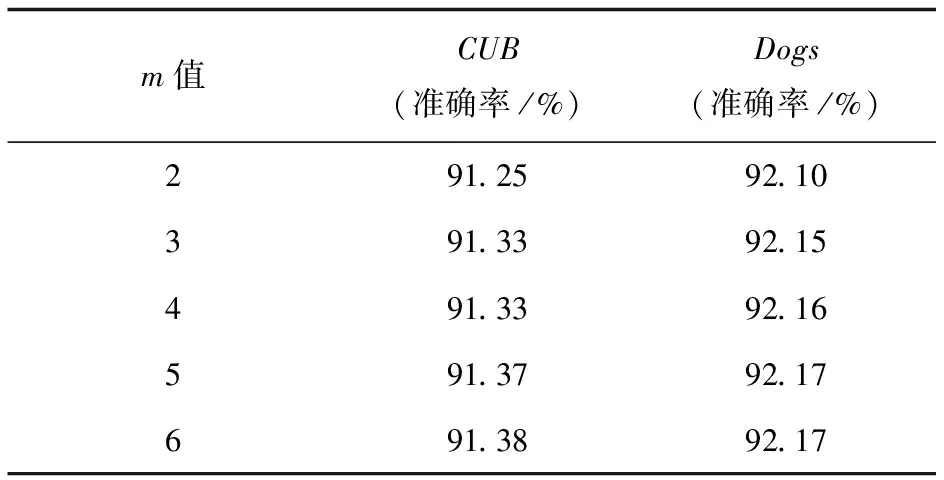
表3 不同m值实验结果
3.5 对比实验
为了证明提出方法的有效性,将文中方法与先进的方法进行对比,文中方法的基准网络为ViT,加入加强图像块相关性模块后,在数据集CUB-200-2011和 Standford Dogs分别提升了0.63、0.45百分点,也证明了文中方法能够有效加强局部信息的表征能力。如表4所示,相比于一些基于CNN方法的模型,文中方法效果提升明显。Cross-X网络利用不同图像之间和不同网络层之间的关系对细粒度图像数据集进行多尺度特征学习,也达到了不错的效果。API-Net通过构建注意力成对交互网络进行互向量学习区分微小差异,达到了非常好的效果,但对微小差异捕捉能力更强,性能更好。对比FDL网络方法,文中方法也表现的非常好。相比于基准网络ViT模型,效果也有提升。
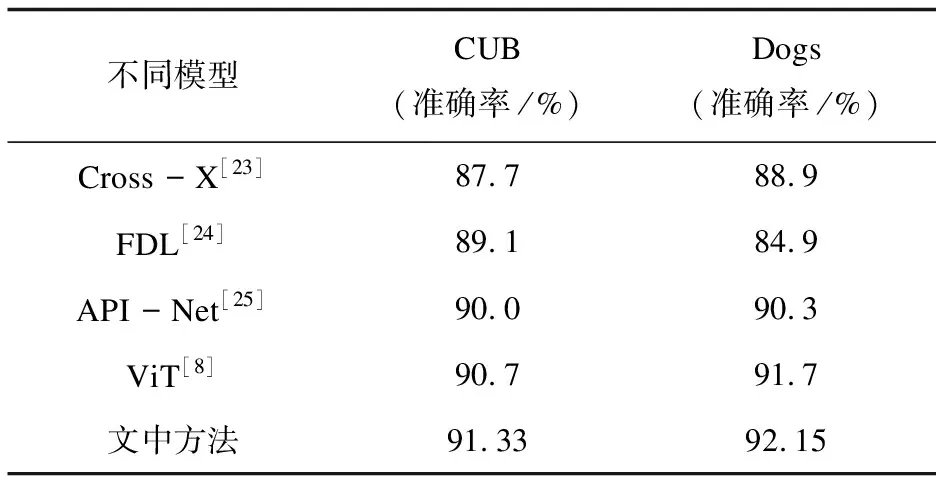
表4 对比实验结果
4 结束语
在细粒度图像分类任务中,针对ViT框架对图像局部区域关注不够的问题且为进一步加强图像块特征的上下文联系,提出一种基于加强图像块相关性的细粒度图像分类方法。赋予图像块相关性权重并对其评价差异化,加强网络对局部区域的关注,引入图像块位置信息加强图像块上下文信息的联系,有效降低了分割图片对图像块造成的特征不完整,整个模块与编码器以嵌套方式组合丰富了不同层次的特征表达,并引入相似损失函数提升任务表现。实验表明,该方法有效提升了细粒度图像分类效果。下一步的研究可以考虑如何充分利用当前图像块与局部相邻图像块区域的联系,进一步加强图像块特征的表征能力,提升分类效果。
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化·七年级数学人教版(2022年11期)2022-02-22 22:13:22
数学物理学报(2021年2期)2021-06-09 08:54:42
高技术通讯(2021年1期)2021-03-29 02:29:24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
电脑与电信(2018年11期)2018-02-16 05:41:32
信息安全研究(2016年3期)2016-12-01 06:06:41
发明与创新(2016年38期)2016-08-22 03:02:50
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31 19:42:13
