
基于HMM的话题风险状态预测方法研究
2023-05-19 07:54:38蔡婷婷朱恒民
计算机技术与发展 2023年5期
蔡婷婷,朱恒民,2,魏 静
(1.南京邮电大学 管理学院,江苏 南京 210003;2.江苏高校哲学社会科学重点研究基地—信息产业融合创新与应急管理研究中心,江苏 南京 210003)
0 引 言
互联网社交媒体是用户发布、传播和获取海量话题信息的重要平台。网络话题是在不断演化的,话题的迅速发酵与扩散会引发网络舆论,甚至是舆情危机。话题的状态可用于描述话题本身的发展趋势和舆论爆发的风险性,对话题的状态演化趋势进行预测有助于舆论监管部门及时采取措施,避免引发舆情危机,进而实现社交网络信息传播的有效监管。
话题演化是对已有话题随着时间演化情况进行的分析[1-2]。话题的状态演化属于话题演化分析的研究范畴,已有工作多是基于生命周期的视角来回溯话题状态的演化过程。Chen等提出一种基于生命周期的老化理论,将话题发展分为萌芽、生长、衰退和消亡四个周期,并将其与传统的single-pass聚类算法相结合,自适应地检测和跟踪在线序列话题事件[3];贾亚敏和曹树金等结合话题生命周期理论将话题状态分为起始、爆发、波动和平息四个阶段,探索每个阶段的话题演化规律[4-5]。部分学者通过定义指标来回溯话题所处的生命周期阶段:Y.Tu等基于老化理论提出新颖指数,并结合已发表量指数来探测处于生命周期新生阶段的热点话题[6];Collon等基于共词分析法提出了向心度和密度两个指标,用于评价科技文献主题的重要性和成熟度[7];刘自强等基于这两个指标,通过平面坐标映射法将科技文献主题划分为新生、成长、收缩、消亡四个生命周期阶段,以期描述主题在整个生命周期的演化过程[8]。相对于科技文献中的专业词汇,网络自由文本中包含了大量同义、近义等具有复杂语义关系的词汇,且词之间的共现频率较低,因此共词分析法并不适用于复杂语义关系的自由文本。
关于话题演化趋势的预测,现有工作多是通过时间序列预测话题热度等指标来分析话题的演化趋势:马晓宁基于粒子群算法优化的BP神经网络方法对话题热度进行趋势预测[9];刘晨等融合LSTM与卷积神经网络方法预测话题的热度趋势[10]。然而关于话题在未来时刻状态趋势预测的已有研究相对较少。范云满等在Y.Tu等[6]的研究基础上新增被引量指标,并利用多项式拟合曲线的方法预测话题状态趋势[11];Kong等结合与话题相关的各动态因素的贡献和模式匹配的方法,从微观和宏观两个层面探索话题流行度状态在未来的发展趋势[12]。隐马尔可夫模型(Hidden Markov Model,HMM)作为一种成熟的概率统计模型,能考虑时间序列的影响,在描述对象统计特性的动态随机过程上面具有突出优势[13],已经成功应用于手势识别、寿命预测等领域[14-15]。话题状态演化可看作是由话题内部状态和外部观测特征构成的一种双重随机过程,它适用于HMM模型,已有少量研究工作将HMM运用于话题状态趋势预测中。Zeng等基于话题内容相似度对舆情话题进行分类,并基于HMM构建话题预测模型来预测话题生命周期阶段[16];Liu等以博文数量和增长率作为观测指标,运用HMM对多个话题分别构建状态预测模型并建立模型库,通过人工判别待预测话题与模型库中已有话题是否相似,从而选择相应模型预测话题未来的生命周期阶段[17]。上述工作提出的话题状态预测模型人工干预量和预测误差较大。而且,话题生命周期受多方面因素和偶发情况影响,准确预测话题未来的生命周期状态具有较大的挑战性。
综上所述,目前相关工作多是从生命周期的视角来回溯话题状态的演化过程,对演化中的话题在未来时刻的状态趋势预测研究较少。该文从话题预警的视角,基于向心度和密度指标将演化中的话题划分为不同等级的风险状态;基于word2vec模型[18]计量状态指标,解决了共词分析法不能有效处理网络自由文本中的复杂语义这一问题;基于HMM提出话题未来时刻的风险状态趋势预测方法,为话题的有效预警提供科学依据。
1 话题风险状态定义
话题状态是对话题当前及潜在影响力的度量,它描述了话题本身的发展趋势和引发舆论危机的风险性。从话题预警的视角将话题状态划分风险等级,可以直观地刻画话题引发舆论危机的风险程度,也是下一阶段话题趋势预测的目标。
Collon等[7]针对科技文献主题提出向心度和密度两个指标,向心度表示主题与其他主题关联的强弱,向心度越大,该主题越接近议题的“中心”,因此向心度反映了主题的重要性。密度表示构成主题的特征词之间的紧密程度,在主题演化的过程中,主题在内容上从分散逐渐收敛,密度也随着增大,因此密度反映了主题的成熟度。向心度和密度可被借鉴来度量网络话题当前及潜在的影响力,该文采用这两个指标来刻画话题的风险状态,进而对话题可能引发舆论危机的风险等级进行划分。考虑到网络自由文本包含同义词、近义词等复杂语义关系,区别于文献[7-8]中采用共词分析法计算话题向心度和密度,该文基于word2vec模型计量两个指标值。
1.1 向心度指标计量
在描述网络话题时,向心度是指一个话题与其他话题关联的强弱程度。向心度越大说明话题与其他话题关联越强,该话题在所有话题中越接近于“中心”位置,越容易受到网民的关注,从而容易引发舆论危机,因此向心度可以反映话题的风险状态。
基于word2vec模型,通过计算两话题之间特征词的相似度来衡量话题之间的关联程度,话题与其他话题特征词的相似度越高,话题的向心度值越大。假设Ti是基于LDA模型提取出的话题,则其可表示成Ti=[(wi1,ti1),(wi2,ti2),…,(wim,tim)],其中tik和wik分别表示构成话题Ti的第k个特征词及其权重,m是特征词的数量;令vik是由word2vec模型训练出的特征词tik对应的向量,则两话题Ti与Tj之间的相似度Sim(Ti,Tj)可由式(1)计算可得。

Sim(vik,vjx)
(1)
其中,Sim(vik,vjx)为向量vik和vjx之间的余弦相似度,|Ti|和|Tj|分别为话题Ti和Tj的模,计算公式如下:
(2)
设Tset为所有话题的集合,即Tset={T1,T2,…,Tn},则话题Ti的向心度Ci可由话题Ti与其他话题之间相似度的均值求得,即:
(3)
由式(3)可知,话题向心度Ci的值域为[0,1]。当Ci=1时,表明话题Ti与其他所有话题均有强关联,位于最“中心”;当Ci=0时,该话题与其他所有话题毫无关联,为整个话题空间的孤立点。
1.2 密度指标计量
在描述网络话题时,密度是指话题内特征词之间的紧密程度。围绕话题展开的讨论越集中,话题会越聚焦,特征词之间的紧密度越高,密度值越大,话题也会趋于成熟。因此,话题的密度反映了话题讨论的集中程度,也是话题风险的表征指标之一。
该文采用话题内部特征词之间的相似度来衡量其紧密程度,话题内特征词之间的相似度越高,话题的密度值越大。话题Ti中第k个特征词wik与其他特征词之间的平均相似度Aik由式(4)计算可得。
(4)
话题的密度可用各个特征词的加权平均相似度表示,如式(5)所示。
(5)
由式(5)可知,话题密度Di的值域为[0,1]。Di值越大,表明话题Ti中的特征词语义越趋于集中;反之,则话题中的特征词语义越趋于分散。
1.3 话题风险等级划分
正如上文所述,向心度和密度分别从不同的角度反映了话题引发舆论危机的风险。借鉴科技文献中划分主题状态的方法——平面坐标映射法,将话题的向心度和密度分别作为平面坐标系的横轴和纵轴,并将两个指标的均值作为坐标原点,则可以把话题的状态空间划分为四个象限,分别对应了话题的四种风险状态,如图1所示。

图1 基于向心度、密度两个特征划分的话题状态类别
(1)I级风险状态:话题的向心度和密度均较低,意味着该话题与其他话题关联弱,处于议题的边缘位置,且话题讨论分散,不聚焦,难以引发舆论危机,因此该类话题定义为I级风险状态。
(3)III级风险状态:话题的密度较低,但向心度较高,意味着虽然该话题讨论不够聚焦,尚未成熟,但与其他话题关联强。随着围绕该话题展开的讨论增多,话题内容趋向聚焦,很容易在全网范围内引发舆论危机,因此该类话题定义为III级风险状态。
(4)IV级风险状态:话题的向心度和密度均较高,意味着该话题与其他话题关联强,处于议题的“中心”位置,且话题聚焦,讨论集中,极易引发全网范围内的舆论危机,因此该类话题定义为IV级风险状态。全民关注的热点与焦点话题往往属于该类风险状态。
相对于I级和II级风险状态,III级和IV级风险状态话题引发舆论危机的可能性较大,政府和舆论监管部门需要格外关注话题走向,必要时采取预警措施,干预话题进一步扩散,营造良好的网络舆论氛围。
2 话题风险状态预测方法
话题风险状态预测方法是根据当前时刻的话题观测数据预测出下一时刻话题所处的风险状态。话题状态随着时间推移不断演化,虽然无法直接观察到话题状态,但可以通过向心度、密度等观测指标来反映。因此,话题状态演化过程是由外部观测指标反映内部话题状态的双重随机过程,可用隐马尔可夫模型描述。
2.1 模型构建
隐马尔可夫模型是一个双重随机过程,一个过程是描述隐藏状态转移的马尔可夫链,另一个过程是描述隐藏状态与观测状态之间的映射关系[19]。图2描述了一段时间内隐藏状态之间的转移关系及隐藏状态与观测状态之间的对应关系。

图2 话题风险状态转移序列与观测序列关系
该文基于HMM构建话题风险状态模型,模型参数描述如下:隐马尔可夫模型可用参数λ={π,A,B}来表示,话题风险状态预测模型参数选取及模型训练的初始值设置描述如下:
(1)隐藏状态集合S:S={s1,s2,s3,s4},s1、s2、s3、s4分别对应话题的I级、II级、III级、IV级风险状态,状态数量N=4。令话题在t时刻的状态为qt,qt∈S。
总之,在小学体育课堂,运用情景教学的最终目的就是激发学生的体育学习热情,让体育教育真正受益于学生,而不只是让小学体育课变成课程表上的一个摆设。因此,作为体育教师,要积极运用情景教学进行教学,同时还需要引导学生进入情景中,感受体育课堂的丰富与乐趣,锻炼学生的体育技能,培养积极健康的心态以及形成正确良好的体育观念。
(2)观测序列O:O={o1,o2,…,ot},表示在1~t时间段内由话题各时刻二维观测值组成的观测序列,ot表示t时刻下话题T的向心度和密度值组成的二维观测值。
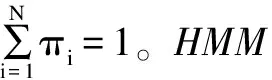

(5)观测状态概率分布B:B={bi(ot)} ,bi(ot)=P(ot|qt=si)。其中,bi(ot)为t时刻隐藏状态为si对应观测状态为ot的概率。当HMM的观测值为连续值时,状态si生成观测状态的概率可以用高斯模型 (Gaussian Model,GM)来拟合,即隐藏状态si对应的观测值服从均值为ui、协方差为Σi的二元高斯概率密度函数,如式(6)所示。该文将话题在四类风险状态下对应的二维观测数据的平均值和协方差作为模型初始均值和协方差。
(6)
文中话题风险状态预测方法是将各个风险状态下对应的观测序列数据作为该状态的表征,分别针对不同的话题风险状态构建HMM模型,从而预测话题演化过程中风险状态的变化趋势,它能够避免原有模型[17]对不同类型话题建模导致模型普适性较低的问题,弥补话题生命周期波动性较高带来的模型稳定性较低的不足。根据平面坐标映射方法,提取出各个风险状态下对应的多条观测序列,作为HMM模型的训练数据,对四类话题风险状态进行模型训练,以期提高模型稳定性和预测效果。
2.2 模型训练
将风险状态si下的全部观测样本序列表示为O(si),作为各话题风险状态模型的训练数据,并利用Baum-Welch算法(EM算法)训练模型,得到模型集合为HMMs={HMM1,HMM2,HMM3,HMM4},对应参数集Ω={λ1,λ2,λ3,λ4},将EM算法的最大迭代次数设置为100,收敛阈值为0.001,经过多次迭代后得到每个模型的最优重估参数。模型训练过程如图3所示。
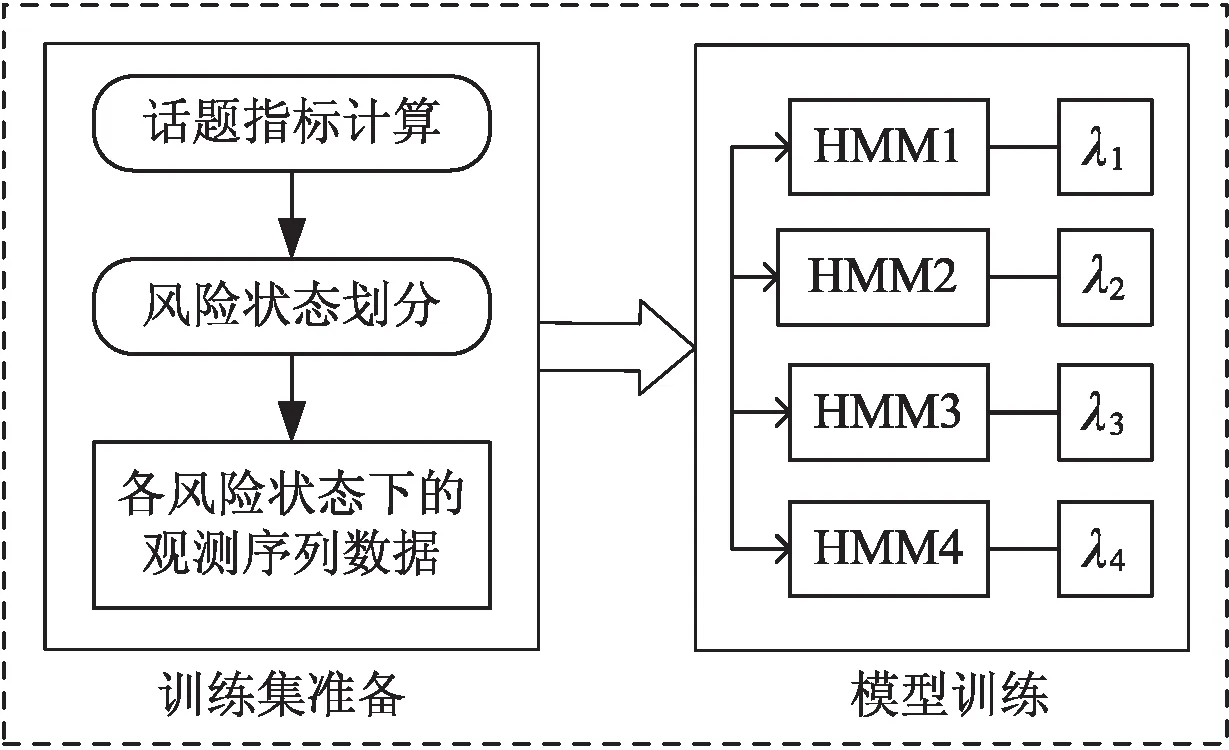
图3 各个话题状态的模型训练过程

2.3 话题状态预测
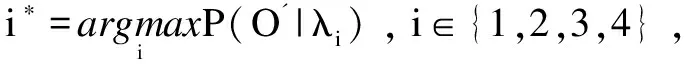
3 实验与分析
3.1 数据来源及预处理
以“疫情、肺炎、新冠”为关键词爬取微博数据,时间跨度为2019年12月31日至2020年5月19日,获得微博数据共307 932条。对数据进行清洗、分词等预处理,运用LDA算法进行话题识别,采用主题一致性指标确定最佳话题数为6。实验以周为时间单位,计算每个话题在时间跨度为20周的向心度和密度指标值,得到总共120条数据。将120条数据映射到坐标系中,获得属于I级、II级、III级、IV级风险状态的观测序列数据分别为24条、35条、24条和37条。
3.2 实验结果分析
观测数据尽管不多,但基本上反映了国内疫情大范围爆发那段时期的微博话题讨论情况。实验采取K折交叉验证法(K-fold Cross Validation)对实验结果进行评估,K取值为4。将120条数据序列分成4等份,每次都取其中的3份(90条观测数据)作为训练集,取剩下的1份(30条观测数据)作为测试集。如此循环4次,在每一次交叉验证中,利用训练集数据中属于各风险状态的观测数据对各个状态训练HMM模型,再利用测试集数据进行状态预测。
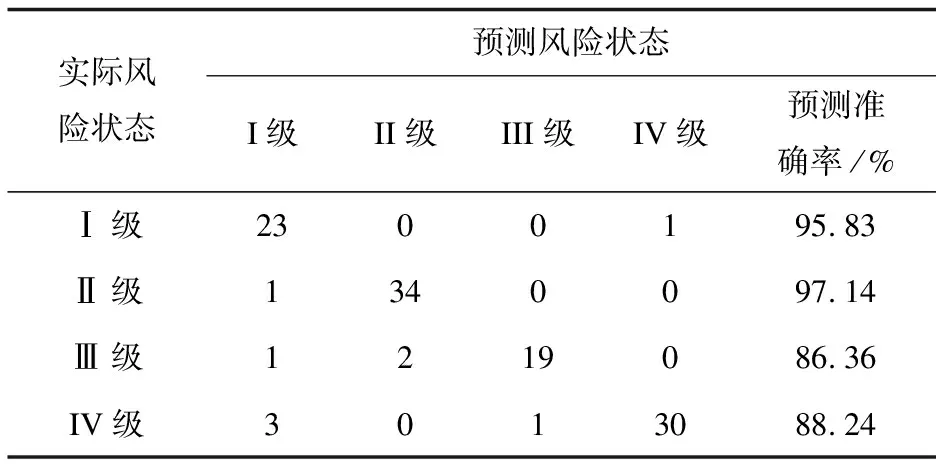
表1 采用话题风险状态方法的混淆矩阵
该文采用t+1时刻的二维观测数据预测值与实际值的误差来评估模型预测效果,选取平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)作为模型预测精度的评价指标。MAPE的计算方式如式(7)所示。
(7)
其中,n为预测次数,Rt+1为t+1时刻的实际值,Pt+1为t+1时刻的预测值。经过计算得出,模型预测的向心度值MAPE为14.13%,密度值MAPE为11.99%。向心度与密度的实际值与预测值对比如图4所示,其中两个指标的预测值与实际值趋势一致,相比向心度,密度值的预测误差更小。

图4 话题状态预测模型的向心度和密度 预测值与实际值对比
根据预测出的t+1时刻观测值判别话题风险状态后,得出话题风险状态预测的混淆矩阵,如表1所示。该方法预测风险状态的平均准确率为92.11%,其中,III级和IV级风险状态更具现实意义,两种状态预测准确率均达到86%以上,说明该预测方法能够有效捕捉话题引发舆论危机的风险性。
3.3 对比验证
为验证该研究方法的准确性和有效性,采用BP神经网络(BPNN)模型、LSTM模型、RNN模型进行对比实验。选取数据预处理得到的6个话题前10周观测值为训练集,将后10周观测值作为测试集评估预测效果。实验采用精确率、召回率与F1值进行模型评估,结果如表2所示。

表2 实验模型效果对比
从实验结果可以看出,对于文中的话题数据集,HMM、BPNN、LSTM和RNN模型得到的准确率、召回率和F1值均高于80%。其中,HMM模型得到的话题风险状态预测的F1值达到90.26%,相较于适用较大数据量的神经网络模型,HMM模型在预测话题风险状态时更具有优势。
4 结束语
为了预测处于演化过程中的话题状态趋势,从话题预警的视角,基于向心度和密度指标将演化中的话题划分为不同等级的风险状态,为话题状态划分提供了新思路。由于话题状态演化过程是由外部观测指标反映内部话题状态的双重随机过程,该文基于HMM提出话题风险状态预测方法,以新冠肺炎疫情事件为例进行了验证。实验结果表明,该方法预测风险状态的平均准确率为92.11%,相对于BP神经网络、LSTM以及RNN时间序列预测模型,该方法预测话题风险状态的误差更小。基于HMM的话题风险状态预测方法为舆情监管部门及时预警话题风险性提供了科学依据。
猜你喜欢
军事文摘(2023年18期)2023-11-03 09:45:42
中学生数理化·八年级物理人教版(2021年12期)2021-12-31 03:23:08
中学生数理化·八年级物理人教版(2021年12期)2021-12-31 03:23:02
中学生数理化·八年级物理人教版(2019年12期)2019-05-21 07:26:36
中学生数理化·八年级物理人教版(2019年12期)2019-05-21 07:26:36
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
测绘科学与工程(2017年1期)2017-05-04 03:40:44
太空探索(2016年7期)2016-07-10 12:10:15
太空探索(2015年8期)2015-07-18 11:04:44
