
融合滑动窗口和MLP-AdaBoost 的电力负荷预测*
2023-05-12 02:25李先鹏吴若男王义洋王会宇刘妙男
计算机与数字工程 2023年1期
李先鹏 吴若男 王义洋 王会宇 刘妙男 王 魏
(1.大连海洋大学信息工程学院 大连 116023)(2.辽宁科技学院中美双百学院 本溪 117004)(3.华能国际电力股份有限公司大连电厂 大连 116100)
1 引言
电弧炉[1]炼钢及其后续工艺LF 精炼炉的热源均来自于电能[2],其耗电占钢铁企业用电的比例非常大,通常电炉变压器设计的富裕容量大,在炼钢尖峰负荷很大,并且不可控,所以企业都选择按照变压器装机容量来满足工作需要,造成工业成本增加。负荷预测模型,在电弧炉炼钢负荷预测与控制系统中占据决定性作用,预测到负荷尖峰时,可及时对电极调节器[3]进行调节,能够准确地控制电弧炉的最大需量,提高电弧炉电能的利用率,减少工业用电成本。
国内外负荷预测模型主要采用的是数学模型和统计学模型,如灰色预测模型[4~5],自回归模型,随着传统的数学模型不能满足实际的精度要求,模糊表达式和模糊计算[6]也融入模型中。近几年,随着工业和计算机的发展,人工智能模型[7]正在逐步替代数学模型和统计学模型。常见的有K 近邻(K—Nearest Neighbor,KNN),随机森林(Random Forest,RF),支持向量机(Support Vector Regres⁃sion,SVR),BP 神经网络、卷积神经网络(Convolu⁃tional Neural Networks,CNN)循环神经网络(Recur⁃rent Neural Network,RNN)。例如,文献[8]使用KNN 和RF 的结合模型对供热机组的热负荷进行预测。文献[9]糊均值聚类和改进乌鸦搜索算法优化支持向量回归机对低压台区负荷进行预测。如文献[10]用小波变化加权双支持向量回归的方式静态对电弧炉能耗进行预测如文献[11]和文献[12]均采用不同的优化算法,对BP 神经网络进行优化建模,完成热负荷和电负荷的预测。文献[13]用变分模态分解、长短期记忆网络和卷积神经网络建立短期负荷预测模型对建筑负荷进行预测。文献[14]通过长短期记忆网络和自适应增强算法建立负荷预测模型对城市住宅区负荷进行预测。
由于炼钢过程中电弧炉负荷变化具有随机性和突变性,导致序列的时序性降低,故本文未选取处理时序性强的循环神经网络模型,而是采用滑动窗口技术来联系负荷的时序性。在结合上述模型的特点和数据特征后,选取了网络稳定性高和数据容错性强的神经网络多层感知机,最后通过Ada⁃Boost 算法对其进行提升,来建立混合模型提高模型的鲁棒性[15]。同时,MLP的稳定性和容错性能更好地弥补AdaBoost 算法迭代带来的误差累积的缺陷。本文先利用滑动窗口方法构建数据集,再利用MLP_AdaBoodt 模型对电弧炉负荷进行实时预测,将将神经网络和机器学习算法结合,为解决预测鲁棒性低稳定性差提供了新的思路,同时针对工程和社会生产的实际问题建立模型,为不同数据类型的预测建模提供可能。
2 相关工作
针对炼钢电力负荷的调控包括预测和控制两部分,预测是控制的基础,是近年来的研究热点,如何精准预测工业用电负荷是预测控制的关键一步。本文采用了具有较强的稳定性的MLP 神经网络,同时运用Adaboost集成学习算法能够针对预测效果差的数据进行权重分配的特点,使得预测更有针对性。
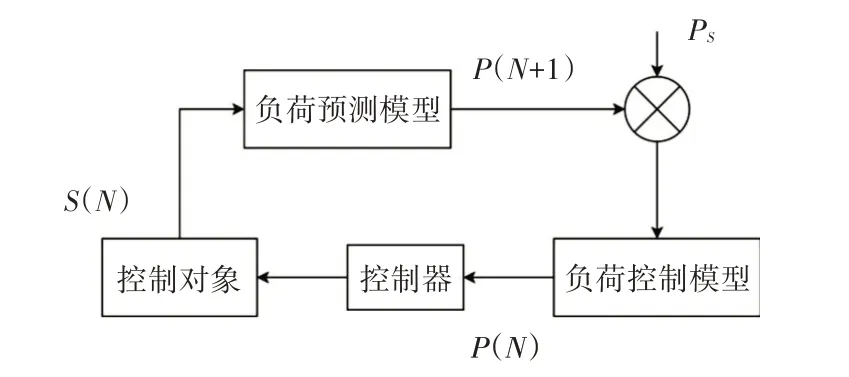
图1 工业用电闭环回路
该系统包括负荷预测模型和负荷控制模型两部分。图中S(N)为控制对象第N 时间段炉况,含电压、电流、档位等;P(N)为第N 时间段的控制量;P(N+1)为15min 预测均值;PS 为负荷设定值。由于电弧炉炼钢生产过程中负荷变化具有很多不确定性,因此仅仅靠传统的方法建立的数学模型很难满足实际使用的精度要求,本文在使用了Adaboost算法解决传统算法的鲁棒性和稳定性差的问题,来提高预测的精度。由负荷预测模型计算出的下一个15min 的负荷预测均值,与负荷设定值进行比较,负荷控制模型则根据差值,计算负荷控制的输出值,从而到达调控用电负荷节约成本的作用。
MLP 分别有输入层、输出层和隐藏层构成,每层由同种类型的神经元构成且每层之间使用全连接的方式,其中输入层和输出层是可视的,可以看成输入到输出的一种映射[16]。其结构如图2所示。
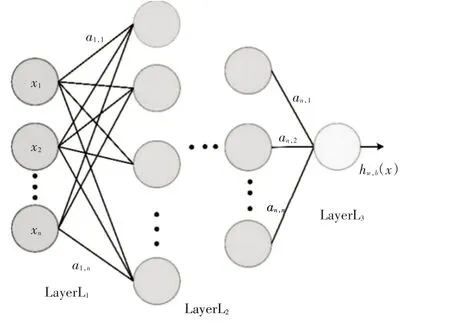
图2 MLP原理图
其中LayerL1表示输入层,用于输入特征向量,LayerL2表示隐藏层,用于提取数据特征,LayerL3表示输出层用来输出结果。MLP 中每个神经元都有一个非线性的激活函数Sigmoid,通过每个神经元的激活函数和层与层连接关系,其在处理非线性问题有好的效果。MLP层节点公式为
MLP由相同的神经元组成,虽然单个的神经元功能和结构简单,但是其网络中的每层神经元并行运行,大大提高运算能力和对信息处理能力。每个神经元受上一层所有神经元影响,通过非线性输入输出的关系,来影响下一层神经元。该模型将大量数据特征储存在每层不同的神经元权值中,采用这种分布式的特点提高了模型的容错性,对数据处理具有更高的稳定性。
自适应增强算法(Adaptive Boosting,Ada⁃Boost),是一种提升集成机器学习算法,通过对模型中样本的权重进行迭代再分配来完成的[17]。Ad⁃aBoost 结合了决策树桩的短一级决策树的预测,AdaBoost 算法试图使用许多弱模型并通过添加额外的弱模型来纠正它们的预测,故也可以用于其他算法中本文将AdaBoost 与MLP 结合。Boosting 算法思想图,如图3所示。
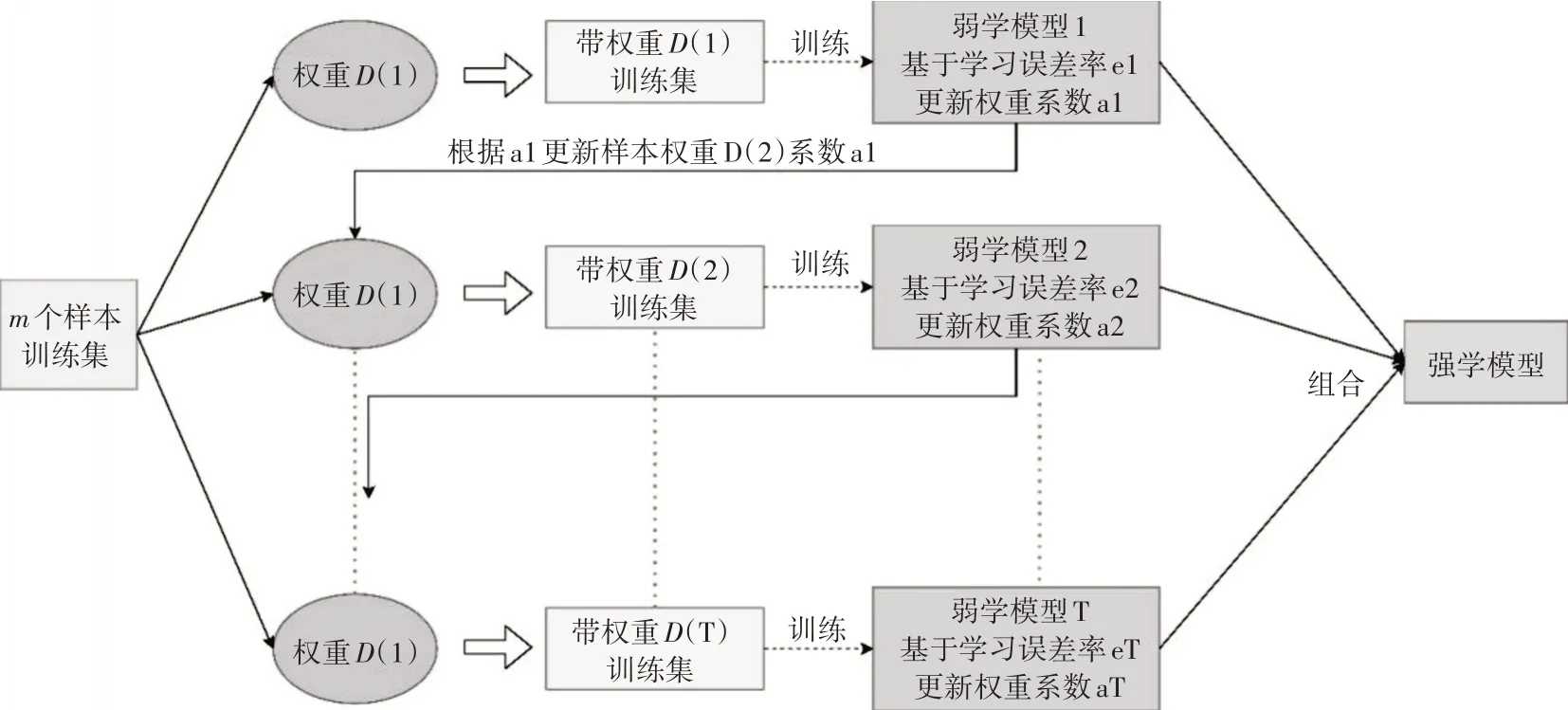
图3 Boosting算法原理图
图3 为Boosting 类算法图,弱学习模型会对数据进行带权训练,通过数据的误差率得到新的权重系数并更新数据权重,重复这一过程得到多个弱学习模型。将多个弱学习模型组合得到强学习模型。
3 算法设计
3.1 MLP-AdaBoost算法设计
本文将AdaBoost 与MLP 相结合,利用MLP 具有高容错性和稳定性,将其作为弱学习模型,使用AdaBoost 集成学习算法对MLP 弱学习进行迭代提升。
MLP-AdaBoost算法计算步骤:
给每个训练样本一个权重:
式中,WT(i)表示算法对MLP 弱学习模型迭代T 次时的样本权重,N表示实验总样本数。
2)采用MLP 建立弱学习模型MT(x),对含权重WT(i)的样本数据进行训练得到弱学习模型,得到预测结果y。
3)通过预测结果y重新计算样本数据权重,对预测误差率大的数据放大其权重,经过弱学习模型迭代训练。
式中:emax表示最大误差,eT表示T 次迭代时弱学习模型的误差率。
4)重复迭代T次结束。
5)将弱学习器按照性能,线性组合,通过每个弱学习模型的性能判断其在强学习模型中的比重:
式中,∂T表示第T 个弱学习模型占强学习模型的比重。
6)每一次训练后,通过数据误差率和模型占比可以来更新训练数据权重:
式中,ZT表示归一化因子,为了将迭代后数据权值归一化。
7)通过最终权值和模型的组合得到强学习模型。
式中H(x)最终强学习模型的输出结果。
3.2 基于MLP-AdaBoost炼钢负荷预测模型
炼钢负荷预测模型流程图如图4所示。
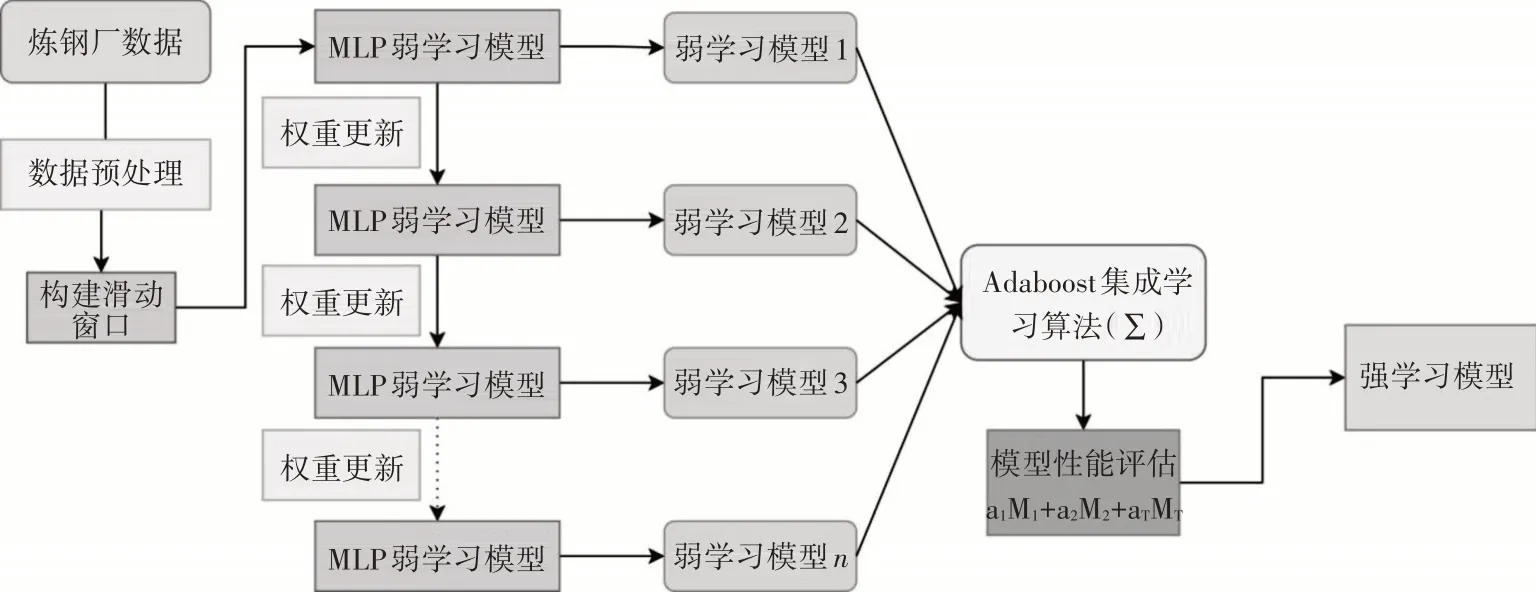
图4 滑动窗口的MLP-AdaBoost炼钢负荷预测模型流程图
MLP-AdaBoost 炼钢负荷预测模型针对炼钢厂有功功率进行建模,通过计算得到负荷,对数据预处理后,通过重构数据并赋予其初始权重,通过MLP 弱学习模型完成第一次预测,然后经过Ada⁃Boost集成学习算法对模型进行提升得到多个弱学习模型,最后这些模型线性组合得到强学习模型。最终通过强学习模型完成炼钢过程中的负荷预测。
4 数据处理
4.1 异常值处理
在实际的数据测量过程中有功功率是通过现场传感器实测的值,所以仪器测量频率、故障,记录或传输异常等诸多因素会影响采集的数据。这样会造成数据的重复、缺失和误差过大等情况,由于AdaBoost 算法在权值分配的时候会将误差数据放大,从而增加模型的误差率,故对数据的预处理非常重要。
根据负荷数据的时序性,针对重复和冗余的数据选择直接删除;针对离群数据采用标准差法进行筛选;针对缺失值的采用插值法对缺失值进行填充。
式中:xi表示当前时刻的值,xi-1表示前一时刻的值,若当前时刻值为空时则使用前一时刻的值来补充数据。
式中:xmean表示数据的均值,xstd表示数据的标准差,把异常值识别为与均值相差超过3 个标准差的临界值。
4.2 数据归一化
本文采用的是单输入模型,但采用了滑动窗口来划分数据集使模型参数复杂,故为了缩小取值范围,避免数值过大,保留所有特征的同时减少参数的大小,本文采用0均值标准化。
其中,x为原始数据,xmean为原始数据的均值,xstd为原始数据的标准差,xscale表示归一化结果。
4.3 滑动窗口
采用滑动窗口方法对数据进行处理,选取窗口大小为N,利用X-N 至X 个实测有功功率预测未来X+1 的有功功率。通过滑动窗口的移动,更久时刻的数据逐渐去除,新数据随着窗口移动不断增加,来实现数据的更替,通过滑动窗口来考虑数据的时序性。
4.4 模型结构参数及训练
基于滑动窗口MLP-AdaBoost炼钢负荷预测模型是单变量预测模型,本实验采用TensorFlow 框架实现。采用MLP 网络构建模型,其中输入层包含神经元150个,隐藏层神经元150个,输出层神经元1个,且在输入层和隐藏层中间加入了Dropout来防止过拟合。优化器Optimizer 选取ADAM 算法来优化,损失函数Loss 选取均方误差MAE(Mean Abso⁃lute Error,MAE)来计算。
5 仿真实验及结果分析
本文实验数据来自某企业2018 年1 月11 日线路1 每秒由现场传感器实测的企业炼钢负荷数据。部分数据见表1。
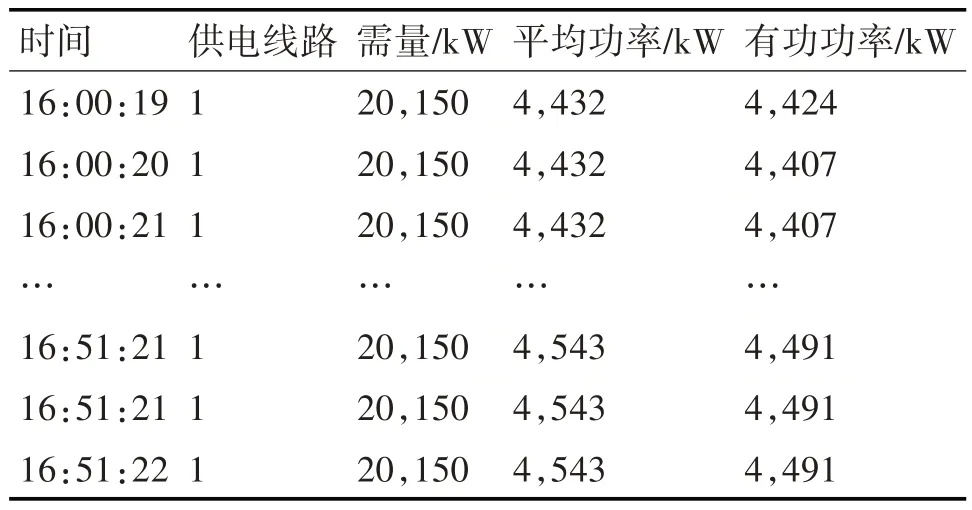
表1 2018年1月11日部分炼钢负荷数据
本数据包括炼钢厂基础负荷和炼钢工作时的负荷,该模型需要预测在炼钢过程中的负荷变化进行下一步调控,来节约资源减少成本,其中负荷是根据有功功率计算得到的,故本文只取数据中炼钢过程中的有功功率变化数据作为实验研究对象。
5.1 数据预处理后结果
数据经异常值处理和归一化处理后,数据预处理结果如图5所示。
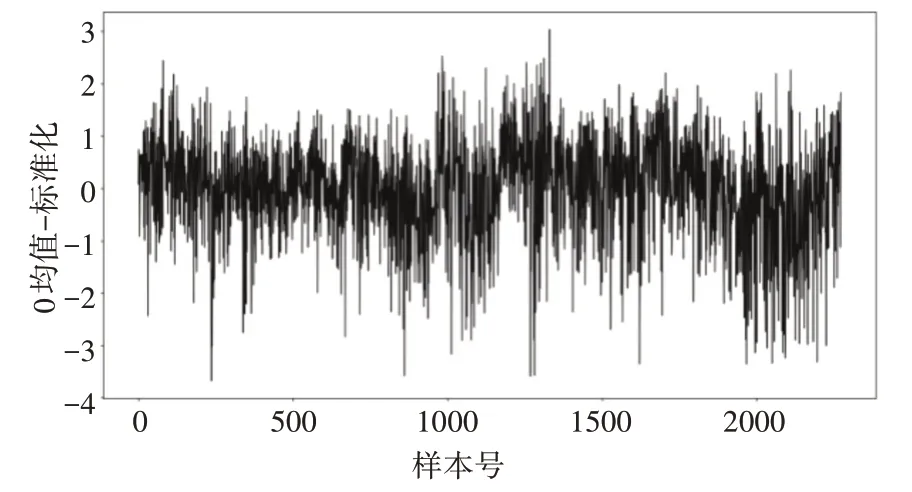
图5 数据预处理结果图
5.2 数据集划分
数据集包括时间、需量和有功功率。其中需量为电路当前时刻负荷最大值,负荷是根据有功功率计算得到的,故预测有功功率即可计算负荷。所以本文将有功功率作为预测对象完成建模,并通过预测的有功功率计算炼钢负荷。在对数据进行建模前,采用滑动窗口方法对数据进行处理。在将数据进行窗口化处理后,选取其中80%作为训练集,20%作为测试集。
5.3 模型预测结果分析
实验中将经过预处理和窗口化的训练样本加入模型进行训练,本文经过多次试验最终选取窗口大小N=10,AdaBoost 迭代次数T=2 次。为了展示预测结果,选取部分点观察预测结果,如图6所示。
由图6 可见,MLP-AdaBoost 预测模型相较其他模型预测效果更好。统计学算法ARIMA、CNN和LSTM 预测模型在面对这类高随机性、强突变性和低时序性的数据时预测效果差。LSTM采用Ada⁃boost 算法提升效果不显著,相反MLP 模型有高容错性和稳定性,故在处理这类问题有更好的效果。可以看出MLP-AdaBoost 预测模型的变化趋势与MLP十分相近,但其在部分细节处的结果相比MLP更好且更稳定。

图6 炼钢负荷预测结果图
本文选取迭代次数T=2,则会有3个子模型,每个子模型处理不同权重的数据,为了便于观察选取部分样本点展示,3个子模型预测结果,如图7所示。
图7(a)为第一次迭代后产生的弱学习模型1,可以看出在点5 和10 点的变化趋势不明显且误差较大。在得到第一个弱模型后,会根据预测结果对数据权重再分配。
图7(b)为第二次迭代后产生的弱学习模型2,在模型1 预测结果基础上对预测效果差的数据权重放大,使模型在处理5和10这类效果不好的点时更准确,同时由于其他点的权重缩小,故图像有所下移整体预测结果较弱模型1差。
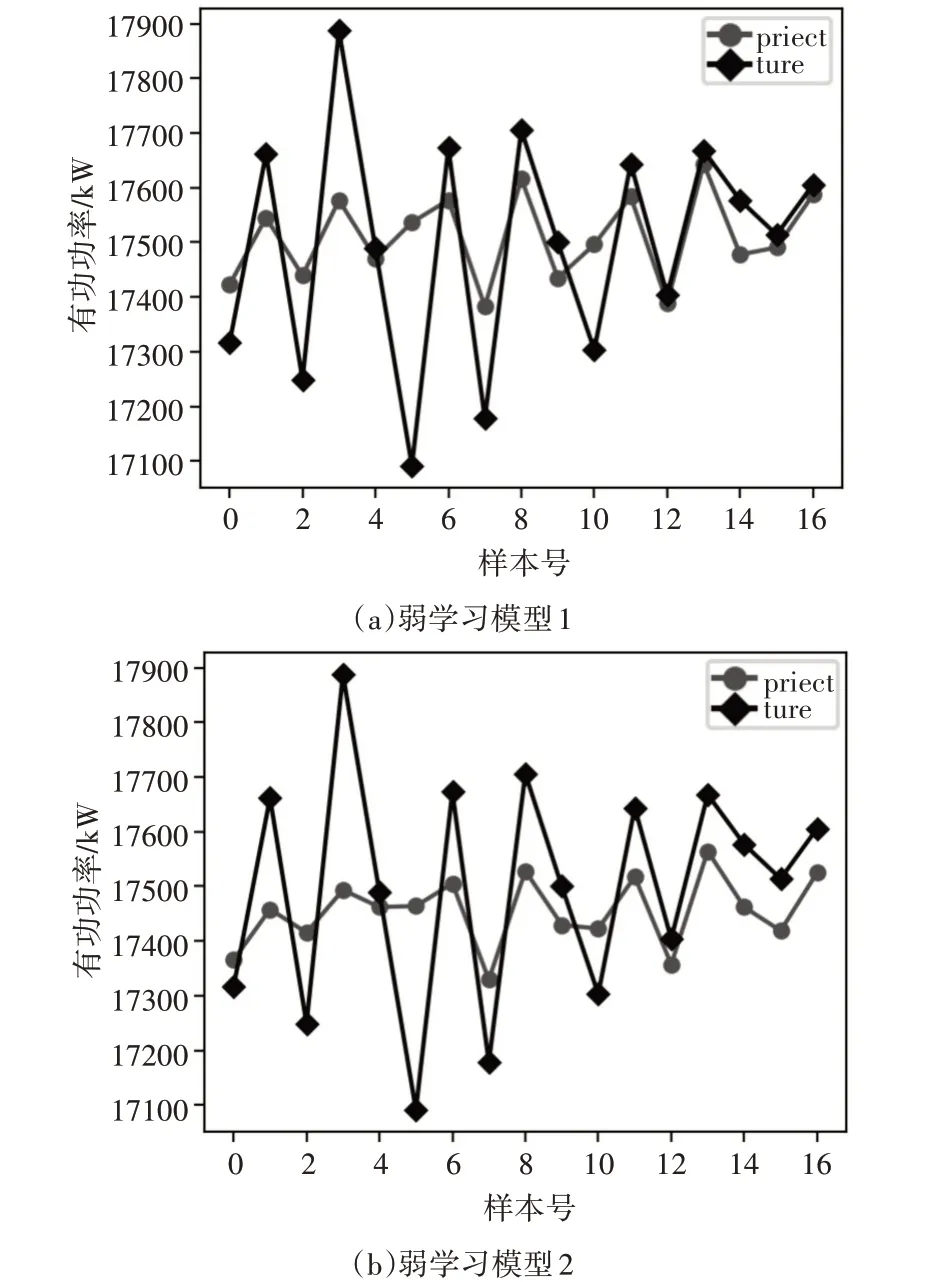
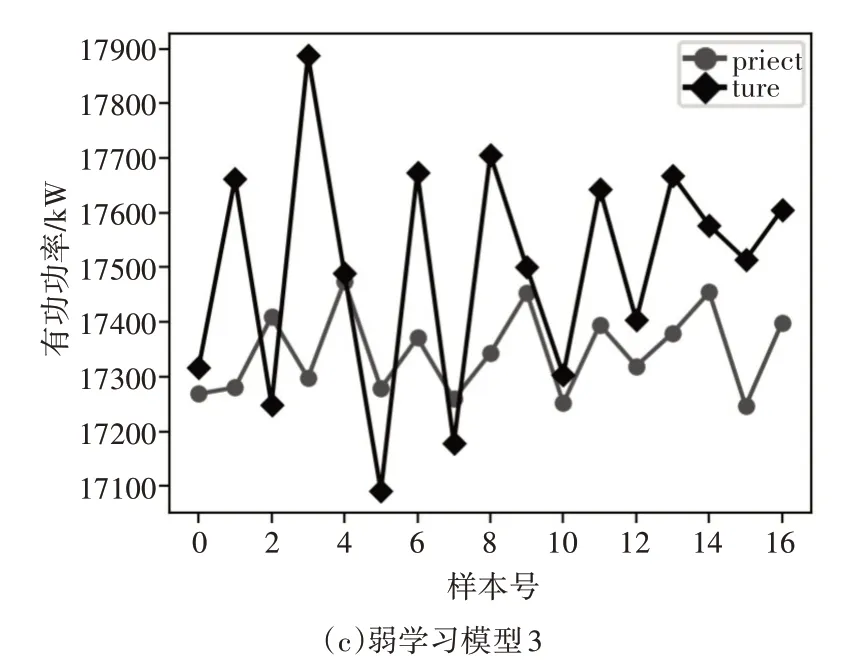
图7 3个子模型预测结果
图7 (a)为第三次迭代后产生的弱学习模型3,该模型建立在前两次的基础上,针对预测结果差的数据再放大。可以看到弱模型3 在处理5 和10 这类点的效果优于弱模型1、2。
图7 分别为三次迭代中的子模型,弱模型2、3的整体预测结果较差,因为是权重再分配的结果。最终的强学习模型经过式(8)的一个非线性叠加,根据每个点的权重分配和预测结果,组成强学习模型。最终的强学习模型集成了所有弱学习模型在处理不同点的优势。
5.4 模型评价
滑动窗口的MLP-AdaBoost炼钢负荷预测模型的准确性采用均方根误差(Root Mean Square Er⁃ror,RMSE)平均绝对误差(Mean Absolute Error,MAE)平均绝对百分比误差(Mean Absolute Percent⁃age Error,MAPE),公式如下:
式中,n表示样本数量;yi为真实值,这里为炼钢有功功率;yi为预测值。本文采用的突变性和随机性高的炼钢负荷其数值相对较大。RMSE、MAE、MAPE 三个指标根据数据特点大小有所不同。本实验采用这三个指标来评价模型的精确度。结果见表2。
表2 中实验结果为10 次实验的平均值。可以看出MLP 处理这类时序性低,突变性强的数据时相较其他模型具有一定的优势。通过三个指标可以直观的反映MLP-AdaBoost预测模型的各项指标比其他数学模型和人工智能模型有显著的降低。

表2 模型评价指标
本文取实验结果中处理时序性序列效果好的LSTM 预测模型、未进行AdaBoost 提升的MLP 预测模型和MLP-AdaBoost 预测模型比较10 次结果RMSE、MAE、MAPE的变化情况,如图8所示。

图8 RMSE、MAE、MAPE三指标对比图
由图8 可以看出在多次实验时MLP-AdaBoost炼钢预测模型的三大指标变化相较比LSTM 和MLP 模型更平稳,说明MLP-AdaBoost 预测模型更稳定。AdaBoost 算法能够有效地解决传统预测模型单次预测鲁棒性差和稳定性低问题。
迭代次数T 取不同次数时MLP-AdaBoost 炼钢预测模型RMSE、MAE、MAPE见表3。

表3 MLP-AdaBoost不同迭代次数结果
表3 中实验结果为10 次实验的平均结果。可以看出,AdaBoost在对模型进行提升时随着迭代次数增大,模型的预测效果在两次迭代后达到最优,继续迭代模型预测精度开始下降。因为AdaBoost迭代次数达到一定时弱学习模型对部分数据预测结果已经达到最优,增加迭代次数只会放大误差数据权重,增大模型的误差率。
6 结语
为了有效调控炼钢工业用电负荷,为下一步控制提出依据。提出MLP-AdaBoost 算法,该算法通过组合弱学习模型有效地解决了以往算法单次预测鲁棒性和稳定性差的问题。同时,该算法对工业炼钢过程数据进行建模,证明了针对这类高随机性、强突变性和低时序性的数据预测效果更好。滑动窗口MLP-AdaBoostl 炼钢预测模型能够有效的为工作过程中控制电弧炉的需量,做出有力的依据,同时该算法可以根据数据特征选取不同的弱学习模型来应用于冶金、水泥、汽车、重型机械、宾馆,水产养殖等场景。
猜你喜欢
昆钢科技(2022年1期)2022-04-19
自然杂志(2021年6期)2021-12-23
中学生数理化·中考版(2020年12期)2021-01-18
山东冶金(2019年2期)2019-05-11
制造技术与机床(2018年11期)2018-11-23
中国工运(2018年8期)2018-08-24
现代装饰(2018年5期)2018-05-26
意林(绘英语)(2018年1期)2018-04-28
电源技术(2015年5期)2015-08-22
弹箭与制导学报(2015年1期)2015-03-11
