
表格单元格分类的端到端不完全监督方法*
2023-05-12 02:25郝昕毓周建涛
计算机与数字工程 2023年1期
郝昕毓 周建涛 王 昊
(1.内蒙古大学计算机学院 呼和浩特 010021)(2.生态大数据教育部工程研究中心 呼和浩特 010021)
1 引言
随着大数据时代的来临,海量数据中蕴含巨大的价值,处理和挖掘海量数据并有效的获取其潜藏价值成为当下关注的焦点问题之一。同时在互联网高度发展下,海量数据中有80%以上的非结构化数据。虽然传统的数据处理方法在处理结构化数据方面较为有效,也能处理大数据的部分特征,但对非结构化数据,因其灵活性和多样性,结构化数据的方法可能不完全适用,必须进行改造[1]。因此面向非结构化数据的处理方法成为数据处理领域研究的重点与难点之一。
表格作为典型的高价值密度非结构化数据被广泛运用在内容管理上。根据Cafarella 等的调查[2],互联网上有大量未被管理的表格数据,这些数据中包含各种领域大量有价值的信息,将其进行识别、提取和集成是一个极有价值的任务。但由于表格主要是为人类用户的使用而设计,用户可以自由设计表格结构和内容[3],虽然为数据管理带来了极大的灵活和便利,但也导致表格总伴随着大量不同的格式、布局和元数据,很大程度上影响了其机器可读性和可重用性,导致严重的数据孤岛问题,使得有效大规模识别、集成和运用表格数据变得困难[4]。因此准确、自动地识别表格是表格数据进一步集成和运用的关键步骤。机器学习为自动表格识别提供了新思路,但其步骤多且独立影响识别结果,只有将独立的模块整合为端到端任务,并合理加入人的判断,才能更好地将识别结果运用在下游任务上。
据此,本文为了将各种结构和展示类型的表格数据识别,提出了一种用于表格单元格分类的端到端不完全监督方法。该方法将表格识别任务建模为单元格分类任务,主要包括以下两个模块:
1)表格单元格特征化模块:该模块根据基于视觉可见的单元格特征化方案对输入的表格进行特征提取,以适应各种类型、结构和语言的表格。
2)不完全监督分类模型模块:该模块分成三个步骤:(1)使用特征化的单元格作为训练数据,通过监督模型进行模型训练,包括训练前的欠采样处理和训练后对未标记数据进行分类。(2)对分类结果通过基于规则的算法进行修正来减轻单元格分类易出错的缺点。(3)将结果交给人类用户进行修正,并在修正后将修正的部分加入到模型训练数据中来提高不同场景下模型的适应性。
同时本文将所提出的端到端不完全监督方法实现为web 工具,用户通过表格可视化界面来确认和修改分类结果,并通过输出来得到包含分类结果的表格数据。
综上,经过实验和模拟表明,本文提出的方法在兼顾通用性的同时能够保证一定程度单元格分类的准确率。同时端到端方法和工具在便于用户修正的同时,还能有效地提取结果,便于结果进一步运用在下游任务上。
2 相关工作
根据Hurst 给出的定义,从表格生成机器可读结构化数据的方法应包括五个步骤[5],本文研究其中的一个:功能分析,识别表中相同功能的区域或单元格集合。
一些学者在表格结构的假设下进行功能分析。如毛等针对纵向表格实现表格行属性的识别[6]。Dou等识别和提取“可扩展组”的固定格式[7]。Chen等着重于行标题的识别[8]。但这类基于假设的功能识别具有不能扩展到任意结构表格的不足。一些学者不进行假设,而将其建模为分类任务,文献[9~10]将表格功能分析建模为块检测,将表格区域按照不同功能进行分类。该类方法可以扩展到任意结构,但具有边界识别困难和距离函数难确定的特点。文献[11~13]将表格功能识别建模为单元格分类,该类方法同样可以识别任意结构且无需考虑边界,但单元格被单独考虑,出现错误的可能会更高。
在表格分类任务中,特征的选取是量化表格类别差异的重点。一些学者人工选取特征[6,11,14~15],另一些学者把特征表示为向量或矩阵[9,12~13]。但这些方案都选择了大量的强特征,如单元格样式特征、字体特征和语言特征等,这些特征仅在特定的场景下适用,无法覆盖各种媒介、语言和展示方式的表格。
从分类模型的角度来看,目前主要使用的方法为无监督方法[9]、监督方法[11~13]和半监督方法[14]。无监督方法实现了自动化但缺乏人的判断,监督方法消耗大量的人力用于生成高质量标注,同时一旦领域变更就需要重新标注数据和训练模型。半监督方法节约一定的人力成本并保证了模型的迁移能力,但无法保证结果的完全正确,无法将结果直接运用在下游任务上。
本文为了使模型的通用性更强,便于将结果运用在下游任务上,将表格识别建模为单元格分类任务,并在特征无法通用、单元格分类易出错、分类结果无法直接运用这三个问题上进行了改进。
3 表格单元格特征化模块
本节针对特征无法适用任意结构、语言和类型表格的情况,设计了基于视觉可见的特征选取方案来提高分类模型的通用性。同时通过该模块可以将任意电子表格转化成相应的特征文件用于模型的训练和预测。
3.1 表格单元格的定义
本文将表格定义为从左上第一个非空单元格到右下最后一个非空单元格依次选取的一维序列,如式(1)。
其中:ci(i=1,2,3,…,n)表示第i个非空单元格,每一个非空单元格都是一个m元组。
为非空单元格所包含的第j个特征。
3.2 表格单元格的特征
表格有多种表现形式,如电子表格、表格图片和web 表格等。但并不是每类表格数据都包含大量的附加格式特征,像CSV文件和表格图片等大多数形式的表格,其附加的特征数量有限或者较难准确的提取出来。在这种情况下,如果通过大量附加特征训练模型就会导致当数据为无格式或者附加格式较少的时候,单元格的分类会被大概率误判,同样的,如果使用较少的附加特征进行训练,复杂的表格往往分类结果就会比较差。
因此,本文在前人特征选取[11,16]的基础上设计了与展示方式和表格复杂度无关的单元格特征和邻域特征。单元格特征筛选了前人研究中与表格展示方式、结构、语言无关的特征。邻域特征新设计了局部邻域特征和行列邻域特征。局部邻域特征将单元格的邻域设计成3*3 的包围盒,获取这些单元格的数据格式特征。如图1 所示,C 代表某个单元格,N则是其局部邻域的选取范围。

图1 单元格邻域特征
行列邻域特征考虑该单元格较远的特征,如同行、同列的数据格式特征和内容特征的统计。这样的邻域特征同时考虑到周边和较远范围的邻域特征,使得单元格的邻域特征更为全面。具体的特征如表1所示。

表1 表格单元格特征
4 不完全监督分类模型模块
由于表格功能识别被建模为单元格分类任务,单元格在分类过程中被单独考虑,相比其他的功能识别算法结果更分散且更容易出错,同时结果也无法直接运用。本节针对这两个问题提出了不完全监督分类模型模块。
4.1 单元格分类建模
本文的目标是给定一个表格,用一组确定的标签对每个非空单元格进行分类。在单元格的类别选择上,本文针对Koci等提出的模型进行了修改[17]。在Koci等的模型中,对于任意非空单元格共有7 个分类,分别是数据(Data)、表头(Header:H)、数据派生(Derived)、组表头(GroupHeader:G)、标题(Ti⁃tle)、注释(Note)和其他(Other)。本文在该模型的基础上对几个分类进行合并处理。首先,Data 和Derived 合并为Data(D),因为无论是聚合还是数据都是数据的一种。Title 和Note 合并为Metadata(M),它们共同为表格数据识别提供了线索,在结构识别上同属于附加信息。Other 被忽略,因为对于结构识别来说这些数据相当于是噪声点。据此,表格单元格的类别可以表示为一个一维序列,如式(2)所示。
其中ri{D,H,G,M},(i=1,2,3,…,n) 是非空单元格ci的类别。
4.2 不完全监督分类模型
不完全监督(incomplete supervision)主要指模型的训练数据中有些数据有标注有些没有。主要的方法有主动学习和半监督学习,主动学习是将部分结果交与人工审核,并把审核结果加到已标注数据中再重新训练模型。半监督学习则是让模型不依赖外界的交互,自动利用未标记样本来提高模型的学习能力[18]。但对于表格单元格分类,主动学习可能会导致用户的标注成本更大,半监督学习则无法保证结果的完全正确,因此这两种方法都无法很好地将结果直接运用在下游任务上。
据此,本文提出了一个不同于主动学习和半监督学习的不完全监督方法。具体来说,该方法首先通过基于规则的修正算法减轻了单元格分类易出错且分类结果零散的问题,然后将修正后的分类结果交给人类用户进行修正,并将修正部分加入到模型的训练数据中。由于人类修正后的数据准确率相对较高,以此作为模型的训练数据会比半监督方法更为准确。该方法不仅能在一定程度上提高模型在不同场景下的适应性,还便于用户将修正后的结果直接用在下游任务如数据集成上。
4.2.1 基于规则的修正算法
在修正之前,首先将所有的单元格先按行索引再按列索引重新进行排列,以还原表格中的空间结构。单元格在此处也被简化为三元组,其中n为该表格的单元格个数。同时也可以通过将其元组中的特征提取,转化成二维坐标的形式去表示一个单元格。其公式如式(3)所示:
本文设计的基于空间规则的修正算法如下:
算法1 基于规则的修正算法
输入包含预测结果的原始表格table
输出修正预测结果后的表格tableexchange
1.newRange=[]//新建修正结果连续范围的数组
2.range=getRange(table)//提取表格的连续范围
3.for i in range{
4.oneLine=judgeOneLine(range[i],range[i+1])
5.if oneLine=True{
6.index=min(range[i],range[i+1])//取最小值下标
7.label=getLabel(range[index],table)//规则修正
8.range[index].label=label
9.isCombine,new=combine(range[i],range[i+1])
10.if iscombine=True{
11.newRange.append(new)}}}
12.tableexchange=updateTable(table,newRange)
算法1~2 行提取每个范围的开始、结束坐标和分类标签。算法3~5 行判断两个序列是否在同行,只有在同行才进行基于规则的修正。算法6 行取出长度较短的序列,因为较短的序列更有可能出现问题。算法7~8 行根据规则确定是否进行修正,具体算法如下。
首先分别根据该序列所在行列计算出行列各自类别单元格的所占比例,然后将行列比例合并作为该序列在每一类上被选中的概率。接着通过一系列规则对这些概率进行增加或减少。针对数据指定的规则为数据单元格不与表头、元数据同行;针对组表头的规则为组表头不与表头、元数据同行;组表头在同行少于数据;组表头一般在左侧。如果违反规则就相应的减少该序列被选中为该类的概率,符合规则就增加选择该类的概率。最终判断完成后选择概率最大的分类作为该序列最终的分类。
算法9~12 行将结果更新到表格中,最终输出的表格单元格分类数组即为修正算法修正的结果。
由于算法将表格划分成由单行相同功能分类的单元格组成的序列,因此需要预留出存放每个序列起点、终点坐标的数组,空间复杂度为On。时间复杂度上,最坏的情况下表格的每个单元格都要统计其同行、同列的单元格情况,并对其进行相应的规则判断,时间复杂度为On2,在最好的情况下每行都有且只有一个序列,只需判断一次,因此时间复杂度为On。
4.2.2 基于人类用户的修正方法
基于规则的分类算法得出结果后,方法会把结果提交给用户进行再修正,同时将用户修正的部分作为新的训练数据参与到模型训练中,来提高模型在不同场景下的适应性。为了便于用户观察和修正分类结果,本文实现了一个用于修正结果的web工具。可视化界面如图2 所示:其中图片的颜色并不是数据所携带的,而是为了让用户更直观地对结果进行判断而增加的颜色。黄色(第8 行)对应表头,粉色(第4~6 行)对应元数据,蓝色(第10 行)对应组表头,绿色(12~14 行)对应数据。用户可以通过该页面中工具栏的工具对相应选中区域的单元格类型进行修改,通过保存功能可以导出相应的携带标注文件的表格数据并把修改的部分增加到训练数据集中。
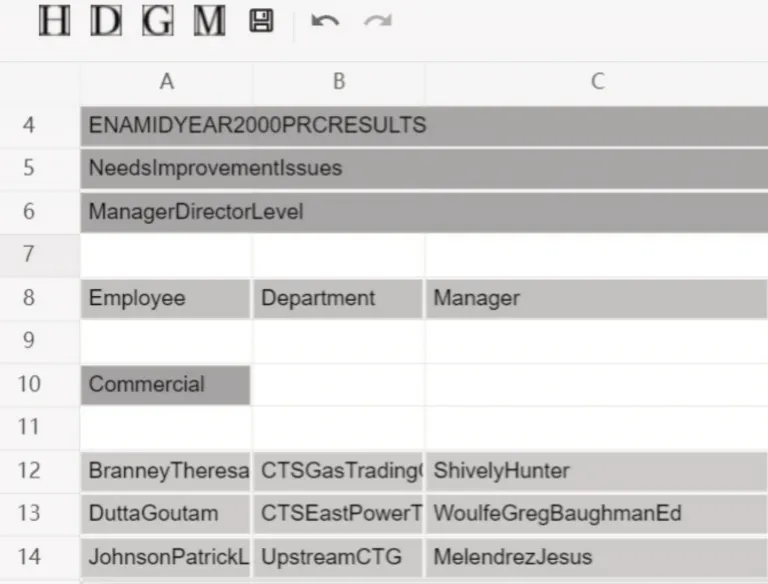
图2 可视化人类用户修正界面
5 端到端方法和实现的工具
本节针对分类结果不能直接运用的情况,将提出的端到端不完全监督方法实现为工具。端到端在不同的领域下有不同的含义,在本文中,端到端是指将方法的两个模块通过串联的方式整合成一个端到端任务,用户输入待预测的电子表格即可通过方法获得预测后带标记的电子表格,这样既便于用户使用,使其无需关心流程内部的参数调整和模型再训练过程,也利于结果进一步运用在下游任务。流程如图3所示。

图3 端到端工具执行流程
其中粗体部分是本文的主要贡献点,其余的步骤是为了完成端到端流程所必须的步骤,而下划线的标记数据则是会持久化到硬盘,每次执行时都会从硬盘读取该数据作为模型的训练数据。
6 实验结果与分析
为了便于表格结构解析,本文选取了一个特殊的表格:电子表格,其是表格数据在计算机中读取的一般形式,具有明确直接可读的布局结构和数据信息,各种形式的表格都能通过各种技术转为电子表格[10]。
6.1 数据集
实验的数据集采用DECO 数据集[17],该数据集由854 个对单元格的类别完成标注的电子表格组成。本文去除了15 张过于庞大且样式单一的表格,对其余的表格通过表格特征化模块进行特征提取,最终得到的标记数据为839张表格,共1115561条标记数据,每个标记数据都是表格中的一个特征化后的单元格。
6.2 基于规则的欠采样处理
统计发现DECO 数据集中D 类别所占的比重过高,会造成数据类别不平衡而导致模型对D类别具有更高的倾向性,而使得分类效果在其他类别上较差。因此本文通过一个基于规则的半随机欠采样进行不平衡数据处理。具体来说,在采样时将所有D 以外的类别单元格都视为一类,数量记为m,对D 的前m个和后m个进行采样,中间随机采样m个。采样后类别将大致平衡为m:3m,大大减少了D类单元格的数量,且全局来看不会丢失过多信息。处理后的数据由原先的1115561 条数据缩减到了124007条数据。
6.3 评价指标
本文在评价模型效果时,除了使用常用于分类任务的指标:平衡F 分数(F1-score:F1),还引入了常用在不平衡数据多分类任务上的评价指标,Mac⁃ro-F1和Micro-F1[19]。
6.4 实验与分析
本文的实验环境为4.2GHz CPU,32GB 内存,在Windows 10 操作系统下,使用JDK1.8 和Py⁃thon3.8.12完成,分类模型采用sklearn的分类模型。
6.4.1 实验情况和分析
为了验证提出方法的有效性,本文进行的实验将一些常见的多分类算法作为基线模型,将本文提出的方法在相应的基线模型进行验证。本文测试的分类模型,如决策树(Decision Tree,DT)、随机森林(Random Forest,RF)、多层感知机(Multilayer Percep⁃tron,MLP)和K最近邻(k-Nearest Neighbor,KNN)。
本文在划分训练集和测试集时与文献[13]相同,选择按文档进行分割,即将单个表格视为最小的拆分单元,因为按单元格拆分可能导致模型提前学习到数据的特点而造成数据泄露。训练集和测试集分别为80%和20%,同时仅在训练集上进行欠采样来减少初始训练数据个数,测试集读取整表来模拟真实情况。实验时将随机种子固定为某值(7、15 和39),重复进行三轮实验并取平均值。最终训练集和测试集的平均单元格个数分别为101055 和188444。同时将修正算法中各个规则的权重设置为0.1,即符合或者违反规则会相应的增减10%的概率。基线方法(方法后加B)为基线分类器在22个特征下(移除行列邻域特征),并除去基于规则修正和人工修正的部分。实验结果如表2 所示,评价指标单位为%。
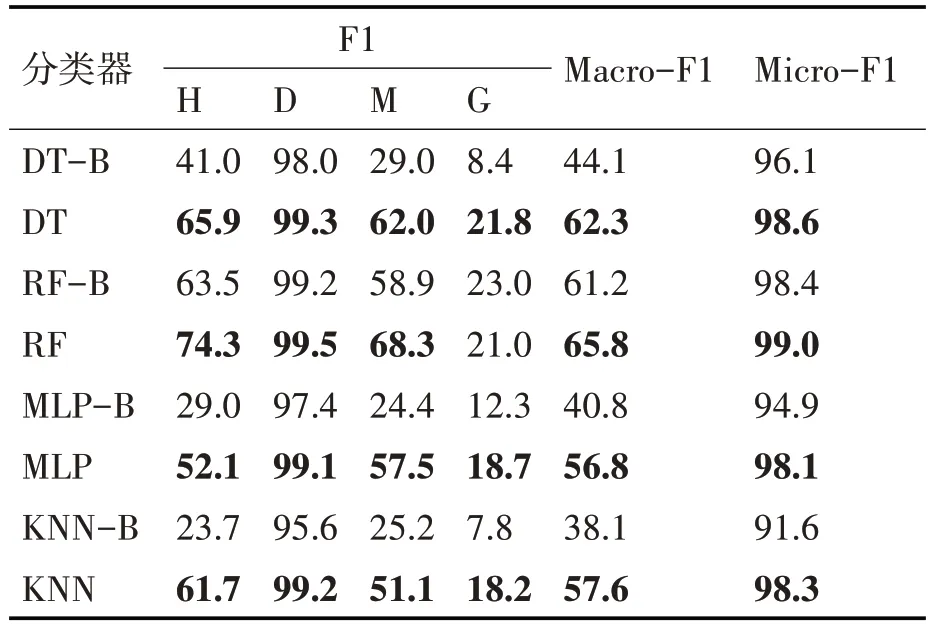
表2 实验结果
经过实验得出,通过本文提出的方法可以在一定程度上提升基分类器的性能,对于H、M 类型的提升效果较为明显。整体效果最好的模型是RF,提升最明显的是KNN。但无论是基线分类器还是改进后的方法,其在M 和G上的结果都不理想。导致M 不理想的原因可能是其高自由度导致的。由于本文将表格的标题和注释进行了合并,虽然减少了类别的数量但也导致M 类的单元格可以出现在表格的任意位置,导致模型无法很好地判断M的特征。而G 可能是因为其与D、H 的特征区分不明显而导致分类器难以识别。经统计原始数据,存在G类型的单元格并不在表格左侧,而是作为独立的行,这也是影响分类效果的一个因素。经过对比统计,G 类型的单元格数量过少也是导致分类结果较差的一个因素。
实验后我们将结果最好的RF与使用相同数据集的Ghasemi-Gol 等[13]和Gonsior[14]等在RF 下的表现进行了对比,对比结果如表3所示。
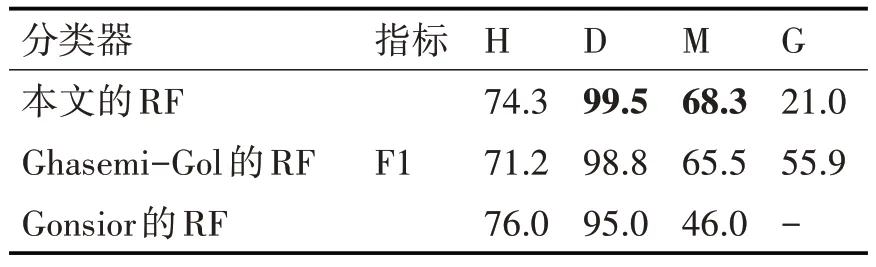
表3 实验结果
经过对比发现,本文的方法在M 和D上要略优于对比的模型,H 与相差不大,在G 上则较差,这是因为本文为了提高模型的通用性而没有使用风格特征和语言特征,但对于G 类型的单元格来说,风格特征和语言特征可能是将其与其他类型单元格区分开的关键特征。但本文提出的方法由于不使用风格特征和语言特征,可以在多种表现形式和不同语言的表格上获得相同的表现,提高了模型的通用性,这是对比的模型所不具备的特点。
6.4.2 修正算法实验分析
通过分析实验结果,分类错误的情况一般为以下两种:错误的单元格与同行两侧正确的单元格分类:1)不同;2)相同。由于算法将单行内连续的同类别单元格组成序列,再判断是否存在错误分类的单元格,据此该算法可以较好地处理1)的情况。如果错误的单元格组成的序列较短,算法对于2)的情况也可以处理。但对于单行为一个序列且其中存在一个或多个错误单元格的情况,算法无法将错误的单元格与正确的单元格分开,这也是G类型的单元格在修正算法之后仍然较差的可能原因。
但本算法仍然可以覆盖一般情况下单元格分类错误的情况,同时也在一定程度上缓解了单元格分类易出错而导致错误单元格排列较为零散,不利于用户修正的问题。实验统计了修正前和修正后每个序列内单元格个数小于2且整行个数大于2的单元格,即零散单元格总数的情况,结果如表4 所示。
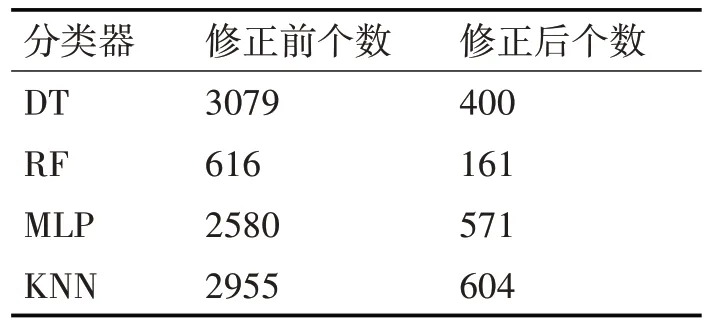
表4 修改前后零散单元格个数
经过对比,本文提出的基于规则的修正算法在各个分类器上都使得分类结果的零散单元格个数有不同程度的下降,能在一定程度上缓解单元格分类易出错和因此导致的错误分类较为零散的问题,这有利于人类用户更好地对结果进行检查和修正。
6.4.3 实验结果分析
总体来说,本文的特征选取方法和基于空间的修正算法能在一定程度上提高各分类器在表格单元格分类上的效果,其中Macro-F1 和Micro-F1 两个指标在RF上取得了最好的结果。对于其中某些表格,其全表的F1 能达到100%,可能是因为对于结构简单的表格,如第一行为H,后面的行为D,模型很容易判断出各单元格的类型。
表格数据类别不平衡的情况在修正算法和采样算法的共同作用下有所缓解,但方法还是有很大的倾向性,M 类型和G 类型的单元格其F1 值还是比较低,可能是当前去除了样式特征和语言特征的特征选取方案并不能很好地描述出这些单元格的特点。
7 结语
本文针对表格数据研究了一种用于表格单元格分类的端到端不完全监督方法。1)选取了兼容多种不同表示形式表格数据的基于视觉可见的特征,并通过表格特征化模块对表格数据进行特征提取。2)通过基于规则的修正算法缓解了单元格分类易出错的问题,让用户能更有效地对结果进行修正。再将修改的数据加入模型的训练集中,以提高模型在后续分类任务上的效果。最后将提出的方法实现为可视化工具,让用户直观进行修改,并即时获得分类结果,使用户便捷地将结果用于下游任务。实验结果表明,本文提出的端到端不完全监督方法在增加了模型通用性的情况下,还能在一定程度上保持一定的分类效果,也在一定程度上增加了分类结果的可用性。
未来的工作我们考虑:1)通过修改分类模型的权重函数,使得少数类的权重更大。2)尝试引入代价敏感学习对表格单元格进行分类,以改进G类别F1较低的情况。
猜你喜欢
现代临床医学(2022年5期)2022-09-28
Journal of Palaeogeography(2022年1期)2022-03-25
现代临床医学(2022年1期)2022-02-12
快乐语文(2021年35期)2022-01-18
电脑爱好者(2021年8期)2021-04-21
数学大王·趣味逻辑(2020年6期)2020-06-22
数学大王·趣味逻辑(2020年5期)2020-06-19
文化创新比较研究(2020年13期)2020-01-01
法律方法(2019年4期)2019-11-16
西部皮革(2018年6期)2018-05-07
