
一种基于支持向量机的等级保护模型
2023-05-08 00:20张雪英
安阳师范学院学报 2023年2期
张雪英
(忻州师范学院 五寨分院,山西 忻州 036200)
0 引言
目前,我国施行信息系统等级保护制度已经20余年,随着云计算、区块链、大数据等新兴技术的发展,等级保护测评继续外延扩展,以跟上互联网技术的飞速发展[1]。1966年,美国杜克大学的Page等人提出了Project Essay Grader (PEG),即作文自动评分技术。但是,PEG只能获取到作文的表层特征,由于不涉及语义研究,PEG的有效性遭到质疑[2-3]。20世纪90年代末期,Electronic Essay Rater(E-Rater)被提出,即托福自动评分系统。E-Rater基于统计学理论提取语言特征,使用了微软语言处理工具。但是,E-Rater主要用于托福英文整体写作水平的判别,无法正确评价内容对错[4-5]。直到Auto Mark系统诞生,该系统才实现语义和内容的自动评价,符合人工阅卷的实际逻辑思维方式,为以后的自动评分技术发展提供了新的启发[6]。国内关于中文自动评分技术的研究较少,系统实践应用不多。罗海蛟等在中文语言环境下,提出了基于文档主题生成模型(LDA)的自动评分,通过隐含主题的概率向量作为文本特征,运用专家知识确定主题范围[7-8]。李舟军等创建了基于语义离散度的自动评分,通过方差提取等构建离散度向量,再采用回归方式完成作文分值预测[9]。
传统的信息系统等级保护测评通常包括采用人工编写方式,缺乏有效的自动评分辅助工具,普遍存在误差大、效率低、成本高等问题[10]。因此,文章提出了将改进的特征提取方法应用于支持向量机模型(SVM)中,并经过实验验证该算法模型的有效性。
1 支持向量机模型
基于支持向量机模型(SVM)在数据集中寻找同时满足不同类型数据要求的最大化超平面。将数据设置成为一个D维向量,SVM模型能够寻找到D-1维度的超平面,以该平面将数据样本进行分类分隔。通常情况下,SVM模型可以在众多符合要求的超平面中寻找最优分离数据超平面,最优超平面也称作最大间隔超平面,能够使两类样本数据之间保持最大间距,支持向量是边缘的训练点。
选取设置类型不同的N维数据样本,此时判断数据样本是否线性可分,如符合要求可以寻找到分离超平面,用公式(1)表示:
WTx+b=0
(1)
其中,w,x,b都是向量,通过超平面将数据样本的特征空间分为正、负两类,最大间隔超平面用g(x)表示,见公式(2):
g(x)=WTx+b
(2)
通过最大间隔超平面可以计算得到分类决策函数,见公式(3):
f(x)=sign(WTx+b)
(3)
sign对应的是分类标签,用来代表取符号函数。当WTx+b大于0时,对应f(x)=+1;WTx+b小于0时,对应f(x)=-1;当WTx+b等于0时,对应的是最大间隔超平面。
如果按照相应比例对向量w,向量b进行缩放,此时超平面之间的间隔会按照相应比例改变,但此时它们之间的集合距离并没有发生变化,不会对超平面之间的间隔造成影响。

s.t.yi(WTx+b)-1≥0
(4)
最优化求解问题属于一个凸优化问题,这是由于指数、范数函数均属于凸函数,得到的局部最优解即为全局最优。由于对偶问题在求解方面不复杂,且能够引入核函数,因此,可以通过拉格朗日变换得到问题的对偶方程,对非线性问题求解,公式(4)的对偶问题公式见公式(5):
L(w,b,α)
(5)
再对向量w、向量b求偏导,将偏导值设置为0,得到公式(6):


(6)
此时就得到了对偶问题,再进一步求得函数最大期望值,见公式(7):
(7)
最后得到分离超平面公式(8):
(8)
以上是SVM模型求解的整个过程,且在线性可分条件下完成。当条件为线性不可分时,通常SVM模型采用核技巧的方式求解。采用核技巧求解的过程主要是将数据映射到高纬度空间中,使其更易于分离和结构化,核技巧为求解提供了线性与非线性的连通方法。当数据样本在基于二维的空间内无法找到超平面时,通过引入核函数,将其映射到三维空间中,以寻找超平面进行数据类别划分。
2 实验过程
实验将支持向量机模型(SVM)与近邻KNN算法、随机森林算法和决策树算法等模型进行实验对比,验证同一实验环境下,不同分类模型的实验结果。该实验在特征提取过程使用了TF-IDF算法加权技术,并引入N-gram汉语语言模型,提出了改进的TIF-NG特征提取方法,最后进行实验结果对比。基于支持向量机模型(SVM)的自动评分包括5个步骤:预处理、特征提取、模型训练、文本分类和分值预测。
2.1 实验环境
采用Windows 10操作系统,以及python开发语言,在虚拟环境Anaconda中进行,选择Jupyter notebook应用程序作为开发工具,在浏览器网页中实现交互。实验环境设置如表1所示。
表1 实验环境设置
2.2 实验数据
由于信息系统数据在等级保护制度下的保密性,实验采用的数据均是由等保测评报告中摘录,数据能够反映信息系统的实际运行情况,对等保测评报告中敏感度高的数据进行脱敏处理后,再用作训练数据。实验数据包括了11 172条记录,其中符合数据8 313条,对应分值1份;部分符合数据1 278条,对应分值0.5分;不符合数据1 581条,对应分值0分。
2.3 文本预处理
1)数据读取。读取测评记录中的数据,通过merge函数对测评指标和测评结果进行合并,合并后的数据作为文本内容,对其所属类别标签进行预测。
2)去停用词。为了有效降低模型训练产生的噪声,减少索引数量,把停词表内的词进行停词处理,将标点符号、数字字母等无任何实际意义的词过滤。
3)分词。分词采用的是集合了规则和统计方法的jieba分词模式,jieba分词模式能够将全部数据构成有向无环图,根据词语的频率实时动态寻找最佳路径,实现切分组合。
2.4 特征提取
通过TF-IDF算法矩阵的构建实现特征提取,词语在某篇文档中的频率用TF表示,体现了该词语在文章中的重要性,IDF则体现了词语的区分能力。TF-IDF算法能够同时保证词语频率和区分的有效性,在过滤常见词语后,存储更加重要的词语。但是,TF-IDF算法下,词语之间相互独立,不能真实体现出序列的信息。为了获得更优质的文本序列信息,实验引入了N-gram汉语语言模型,构成了TIF-NG的特征提取方法。N-gram汉语语言模型能够精准得到某个字的前后信息,以获取更为丰富的特征信息。N-gram汉语语言模型可以从某个句子中提取到N个连续字,并作为集合使用,同时综合考虑了上下文语序的情况,弥补了TIF-NG算法只能对词频进行统计的缺点,构词情况如表2所示。特征提取过程:第一,对文档进行处理,完成分词、标注词性和去除停用词,构成初始候选的关键词集合。第二,利用N-gram汉语语言模型扩充关键词集合,实验采取了混合提取方法,得到了符合条件数据8 313条,部分符合数据1 278条,不符合数据1 581条。第三,通过TF-IDF算法加权技术,选取排名前N的构建关键词集合A,根据增益大小排序选取排名较前的k个词组,作为关键词集合B。第四,集合A和集合B中的交集则为关键词。
2.5 训练过程
通过基于支持向量机模型(SVM)以实现在等保测评中的自动评分功能,SVM模型训练如图1所示:
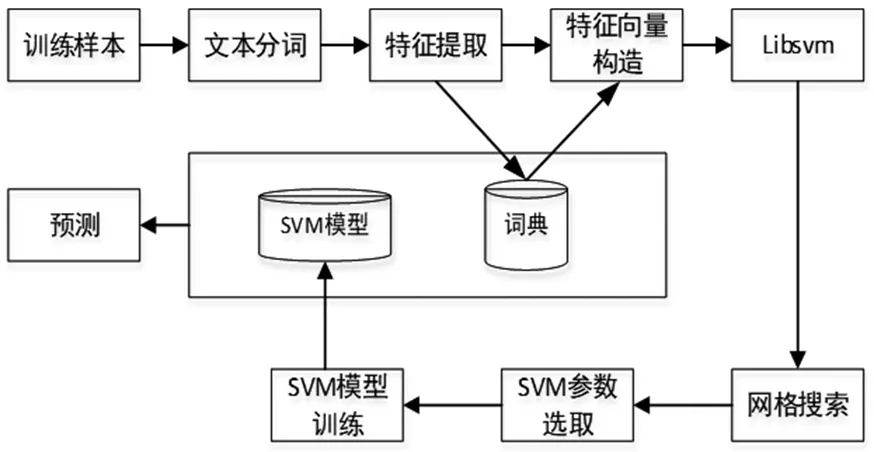
图1 SVM模型训练图
3 实验结果与分析
实验在虚拟环境Anaconda中进行,使用虚拟实验环境能够保证环境相互独立,互相之间不会产生影响,也不会出现由于系统安装程序不兼容产生的各种问题。同时采用Sklearn库,在同一份数据样本中,训练样本占比70%,验证样本占比20%,测试样本占比10%,采用网格搜索调参和交叉验证的方式。
在相同数据集样本环境下,选取精确率系数、召回率系数、F1值和Kappa分类衡量系数作为实验评价指标。使用支持向量机模型(SVM)与KNN模型、朴素贝叶斯模型、逻辑回归模型、随机森林模型、决策树模型进行实验指标对比。基于以上模型,使用TF-IDF和改进的TIF-NG特征提取算法进行实验结果对比,如表3、表4所示。

表3 TF-IDF特征提取的分类实验结果
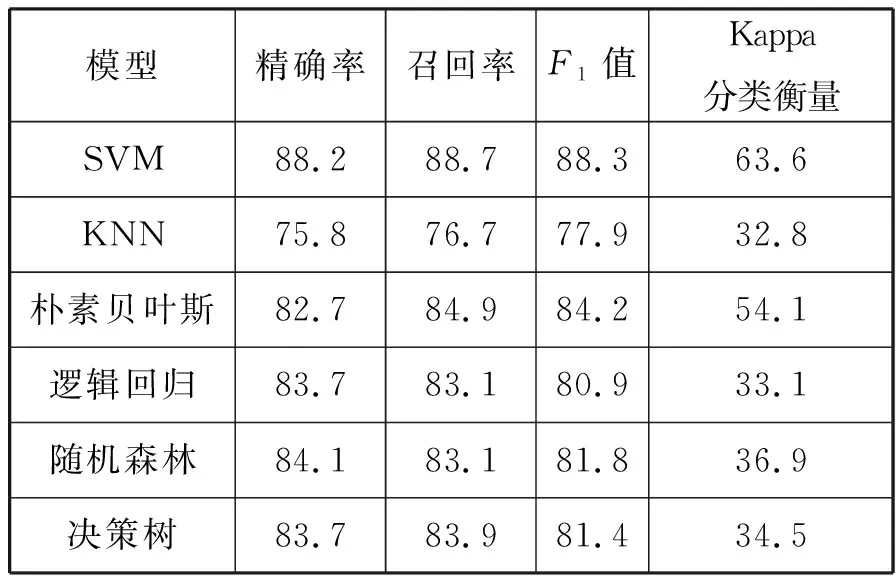
表4 TF-NG特征提取的分类实验结果
由表3、表4可知,6个模型的分类精确率均在80%左右,证明在样本数据集中,采用文本分类的方法具有良好的可行性,适用于等保测评自动评分系统,在使用TF-IDF算法进行特征提取时,决策树模型的精确率和召回率最高;在使用SVM模型时,得到的值和Kappa分类衡量概率最高。当引入N-gram汉语语言模型后,SVM模型的各项性能指标有了明显提升。为了进一步验证和探索N-gram汉语语言模型中N的不同取值在各个模型中的性能情况,实验选取不同N值进行对比得到表5。经过深入统计分析,得到不同N值条件的精确率,如图2所示。

图2 不同N值下N-gram汉语语言模型精确率
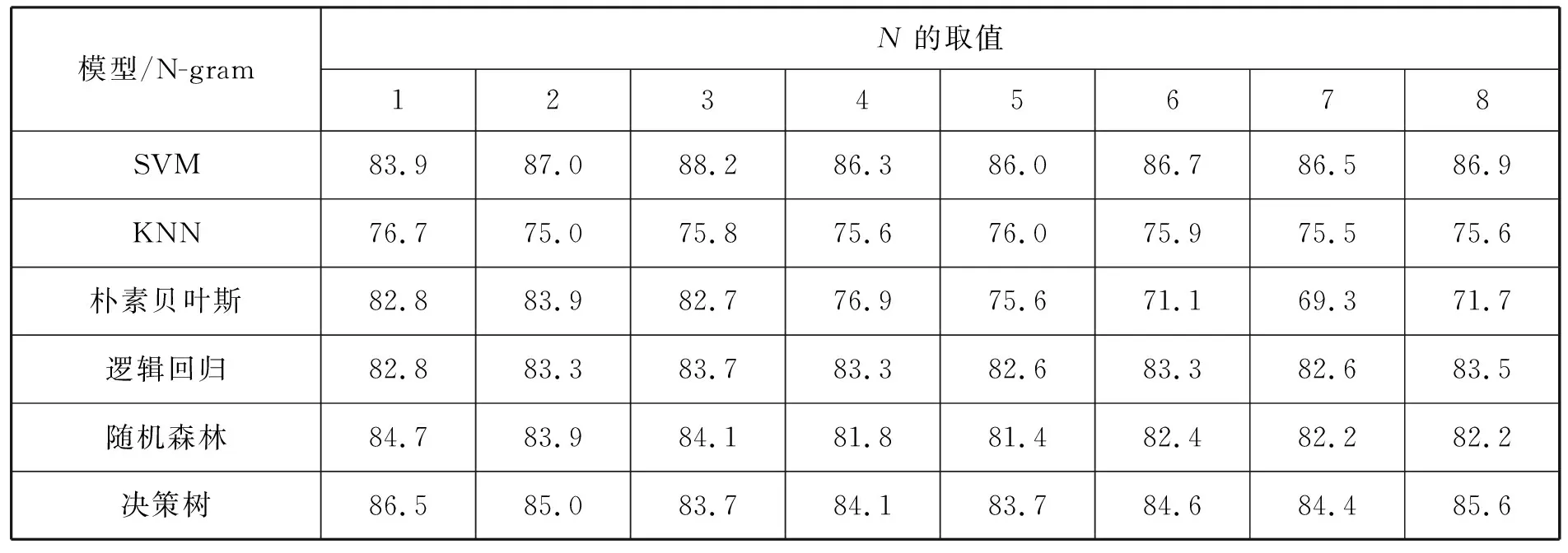
表5 N-gram汉语语言模型中不同N值条件的精确率
当N的取值大于4时,SVM模型、KNN模型、逻辑回归模型、随机森林模型和决策树模型都开始趋于收敛;当N>6时,朴素贝叶斯模型开始收敛。因此,当N取值不同时,不同分类模型对N-gram汉语语言模型的分类精度影响也存在比较大的不同。随着N值的不断增加,其影响度也逐渐降低。在SVM模型中,引入N-gram汉语语言模型有效提高了分类效果,当N=3时,达到最佳的分类效果。当N>3时,N-gram汉语语言模型的表达能力减弱,导致分类效果差,但随着N值的增加,最终模型的分类效果接近收敛。
综上,基于TF-IDF特征提取的文本分类方法,应用于等级保护测评自动评分中具有一定的可行性。在TF-IDF算法中引入N-gram汉语语言建模,从应用于SVM模型的实验结果可以看出,其精准率提高了4.3%,召回率提高了5.0%,F1提高了3.2%,性能指标有了明显提升,分类效果也进一步加强。因此,随着N值的不断增加,SVM模型仍然保持了较高的精度,进一步说明引入N-gram用于特征提取是可行的。
4 结论
文章给出了基于支持向量机模型(SVM)原理,以及获得最大间隔超平面的过程,当数据呈线性无法实现分类时,可以通过核技巧解决。最后通过实验证明了TF-IDF算法在等级保护测评中自动评分的可行性,通过引入N-gram得到改进的TIF-NG特征提取方法,实验证明TIF-NG应用于SVM模型中得到的分类效果最佳。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学年刊A辑(中文版)(2021年3期)2021-11-05
数学年刊A辑(中文版)(2021年2期)2021-07-17
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
数学物理学报(2019年1期)2019-03-21
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
数学年刊A辑(中文版)(2015年1期)2015-10-30
