
基于YOLOv3的钻井现场智能巡检系统设计
2023-04-29 00:44:03钱浩东刘洋汪影
信息系统工程 2023年7期
钱浩东?刘洋?汪影
摘要:机器学习在井场智能巡检中已广泛应用,但油气井场的目标背景较为复杂,为提高井场目标智能检测的精确性和实时性,提出一种可用于视频图像的监测和跟踪的钻井现场智能巡检系统。为了解决缺乏数据集的问题,选择用缩放等同类数据增强方式并结合mixup混类数据增强方式。此外,采用lable smoothing等方法来优化和改善算法,完成算法的模型训练和检测。实验结果表明:改进后的算法检测速度为29每秒检测帧数,平均精度均值为85.90%,可见,经过改进和优化的算法无论在平均精度均值还是在检测速度上,均比其他算法效果好,能快速精确地对井场设备进行识别。
关键词:钻井现场;目标检测;深度学习;YOLOv3
一、前言
传统的油气田井场的巡检工作主要依靠人力进行,不仅效率低下,并且少量气体泄漏无法及时发现,恶劣天气下巡检安全隐患多,故根据井场巡检的需求,智能巡检的发展愈加重要。当前,基于深度学习的目标检测算法包括基于候选区域的Two stage目标检测算法以及基于回归的One stage目标检测算法[1]。其中,以R-CNN为首的Two stage目标检测算法首先需要对图像进行候选区域的提取,再对区域进行CNN分类识别。但是由于生成候选框的算法耗时多,检测速度慢,不能满足实时检测场景。2016年Liu Wei等人提出了基于回归的One stage目标检测算法[2],例如Over Feat、YOLOv1、YOLOv3、SSD和RetinaNet等。YOLOv3是2018年由Joseph推出的,一经推出,便成为了目标检测领域单阶段算法中非常有代表性的算法[3]。基于回归的目标检测算法不需要区域生成这一步,直接在网络中提取特征来预测物体分类和位置,检测速度得到了显著提升。
为解决油气井场背景复杂、不容易检测的问题,提高对油气井场设备检测的速度和精度,通过对算法的改进优化,提出了一种基于YOLOv3算法的钻井现场智能巡检系统[4],实现了包括节控箱、泥浆泵、液面报警器、远控房、振动筛五类目标的精确检测。本文通过K-means聚类得到先验框,通过两个对象之间的距离来判断相似度,然后将相似度大的成员进行分类;为解决井场数据集匮乏的问题,采用平移、旋转等同类增强和mixup混合增强的方法完成数据集的扩充[5];此外,采用标签平滑化来提高分类任务中模型的泛化性和准确率,缓解数据不平衡的问题。最后,将本文介绍的方法与Faster R-CNN检测算法在井场数据集上进行了对比实验。
二、系统整体设计
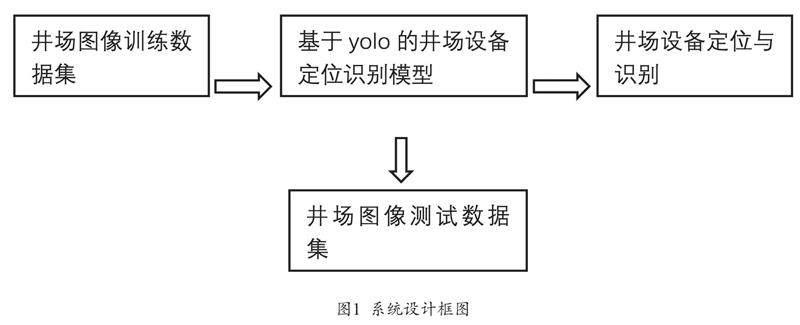
本文设计了一个基于YOLOv3的钻井现场智能巡检系统。在设计过程中,第一步是将井场设备图像整理打包成一个VOC格式的数据集,然后用专业的图像注释工具Labellmg对数据集里的图像进行标注,然后建立一个YOLO模型,这个模型由13个卷积层组成,之后在实验过程中注意观察loss曲线的变化情况,当其逐渐稳定的时候,完成对本次算法模型的训练。最后再将井场的设备图片数据设定为测试集,对图像中的井场设备进行检测识别,得到该系统的性能指标。系统设计框图如图1所示。
三、井场设备定位识别算法设计
(一)YOLO系列算法的原理
YOLO算法的第一代版本YOLOv1将固定尺寸大小的矩形图像划分为7×7个网格(候选区)。在这个过程中,算法实际上是通过利用宽窄两种矩形(先验框),扫描每一个网格部分的图像,同时在网格中记录下候选区为所要检测目标的置信度,然后再以置信度为参考标准来明确目标所在的候选区,最后再适当调整先验框,以便框选出需要检测的物体[6],首先输入了一张448×448×3的固定尺寸的图像,将其划分为7×7的网格,经过YOLO算法得到输出为7×7×30的图像数据。在这里,7×7指的是49个网格,30指的是网格的特征向量,特征向量涵盖了2个边框的置信度和坐标信息(每一个坐标包括4个信息)以及20个对象存在的概率[7]。进行变换是YOLO算法的核心,此变换分为3层,第一层是特征提取层,第二、三层分别为池化层和YOLO层。
1.特征提取层是由多层卷积神经网络组成,提取出输入的图像的特征,将大量的数据量处理成较小数据量的特征图。在这一层用到了卷积运算以及残差运算。其中,卷积运算发挥的作用是提取出图像的特征,而将图像进行压缩的任务则交给池化层。
2.池化层与特征提取层相辅相成,特征提取层也叫卷积层,其任务是经过大量的卷积运算,将最初的数据转换成特征图。池化层则是起着压缩特征图的作用,这个过程可以减少数据量,并且可以进一步获取特征图的主要特征。
3.该算法最重要的组成部分是YOLO层,在这一层需要对候选框进行置信度计算,并且进行待测目标大致轮廓的检测。
(二)YOLOv3算法的改进
YOLOv1存在的缺陷是只有一种尺寸,不容易识别实际生活中过大或过小甚至是奇形怪状的物体,无法满足现实需要。后来改进的v2算法在同层定义了不同尺寸大小的先验框,解决了存在的仅有宽、窄两个回归边框的缺陷,但改善后的效果并不显著。
后来的YOLOv3提出了一种多尺度融合的方法,将得到的特征图分为3类,分别是大、中、小,且可以根据得到的特征图尺寸来调节先验框。这样就很好地满足了生活中不同尺寸目标的识别[8]。因此,YOLOv3特别适合对油气井场不同尺寸大小的设备进行识别。
(三)Darknet-53网络结构
YOLOv3算法在进行图像特征提取的过程中,采用的是由53个卷积层组成的Darknet-53主干网络结构,这53个卷积层由1×1以及3×3等一系列的卷积层构成。
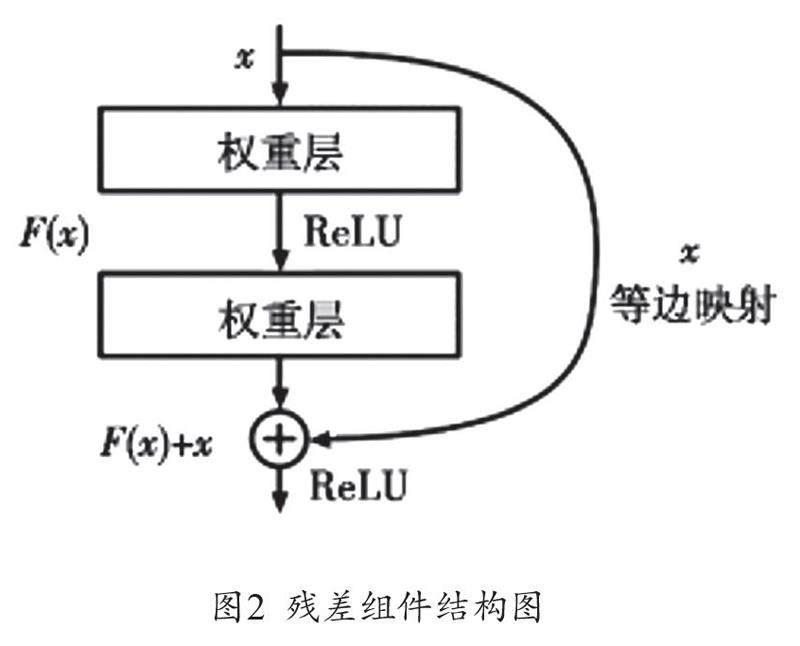
为了解决网络变深带来的性能退化问题,Darknet-53网络采用在卷积层之间利用残差组件来解决。其中,F(x)+x表示残差组件的输出,x表示残差的上层特征输入,F(x)表示学习到的残差,如图2所示。
(四)YOLOv3网络
Darknet-53使用YOLOv3作为网络分类的主干部分,通过对输出的特征图的尺寸大小这一指标进行控制,进而对卷积层的步长进行调整。此外,YOLOv3结合了特征金字塔网络的思想来提升模型的性能,以便检测尺寸不同的物体。利用特征融合与上采样的方法输出3个尺寸的特征图,第1、2、3特征图分别适用于较大目标、中型目标、小型目标。三个不同大小的目标各自对应下采样的32倍、16倍与8倍,最终5L表示网络总共有5层。
(五)多尺度先验框
k-means分别聚类了3种不同采样尺度下的3种大小的验证框,分别聚类10像素×13像素、16像素×30像素、33像素×23像素、30像素×61像素、62像素×45像素、59像素×119像素、116像素×90像素、156像素×198像素以及373像素×326像素。YOLOv3利用k-means聚类获取到了不同尺寸的先验框。
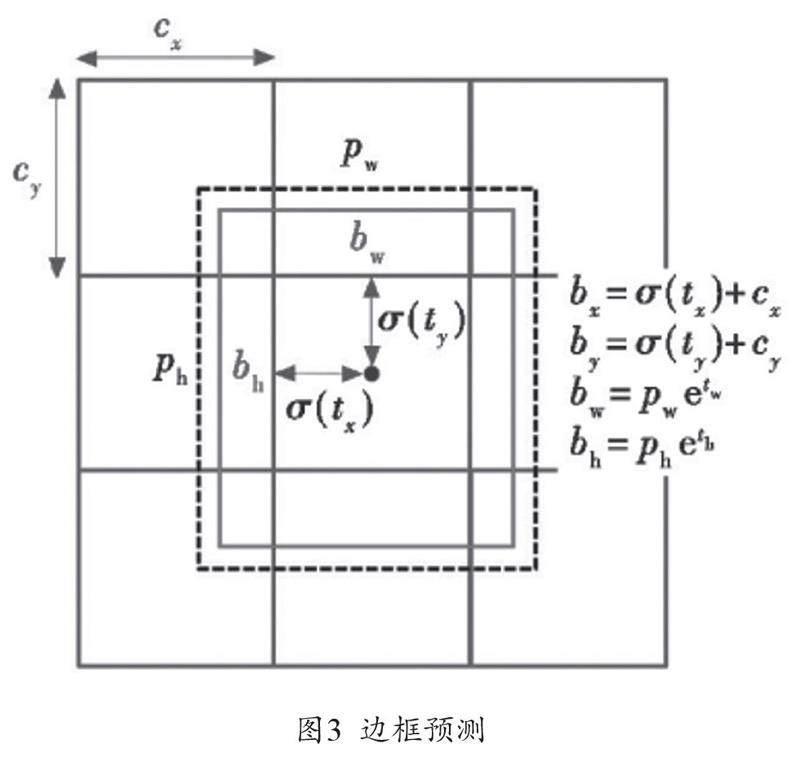
如图3所示,如果一个被检测的目标的中心点在某个网格里面,那么这个目标就由这个网格来完成检测,YOLOv3进行预测回归的依据是被检测目标中心与其对应的网格的偏移量。其中,Pw和Ph各自代表特征值置信图内的宽和高,(CX,Cy)代表网格的左上角的像素的位置,tx,ty代表被检测目标的中心点与网格左上角像素位置的偏移距离,(bx,by)代表预测锚框中心点的位置,bw和bh分别指预测锚框相对于特征图的宽和高,利用常见的Sigmoid激活函数,将tx,ty变换为[0,1]内的输出,以此确保待检测的物体的中心点在网格里,tw,th分别代表特征图宽和高的尺度缩放因子。
四、实验过程及结果
(一)数据集的处理
由于没有标准的井场数据集,仅仅通过现场采集的包含节控箱、泥浆泵、液面报警器、远控房、振动筛五类关键部件的图像作为最原始的数据集。由于采集的图片太少,导致原始数据集不足以支撑模型的训练,因此对训练集图片随机进行如下的数据增强:
1.平移:水平或垂直平移+/-10%;
2.旋转:顺时针或逆时针旋转6°;
3.剪切:水平或垂直剪切;
4.缩放:+/-20%缩放;
5.水平翻转:50%概率水平翻转;
6.HSV饱和度:+/-40%;
7.HSV亮度:+/-40%。
然后使用LabeLlimg对采集的图片进行标注,分为节控箱、泥浆泵、液面报警器、远控房、振动筛五类。在最后得到的上千张图片中,随机选取30%作为测试集,其他的图片当作训练集。
(二)模型的训练
本文实验训练和测试的环境是基于Ubuntu16.04版本的操作系统,GPU用的是GTX2080,预装了Pytorch1.7.1深度学习框架,选择的CUDA版本为10.1。在优化器选择方面,考虑到随机梯度下降算法更具鲁棒性且训练速度快的优点,故选择其作为优化器,训练批次为5×104,学习率为1×10-3,权重衰减为5×10-3。在模型的训练过程中,采用的是有监督的学习方式,通过设计损失函数的回归以及优化油气井场设备的目标识别模型,损失函数的变化情况如图4所示。
(三)实验结果
本次实验过程选择mAP指标作为实验效果的评价指标,该评价指标在目标检测中最常用到,它是人为发明的用来衡量识别精度的评价指标。同时,在对比算法的选取上,由于Faster R-CNN是two-stage目标检测模型中较为成熟的典型代表,故将其作为对比算法与本文的算法进行比较。本次实验测试的结果如表1所示,FPS(Frames Per Second)是衡量检测速度的指标,表示在检测过程中每秒钟能检测到的帧数。
通过表1可发现,网络的检测效果比Faster R-CNN好,尤其在检测速度上。因此,相比Faster R-CNN的性能在检测精度和检测速度方面均有所提升。
五、结语
本文针对油气井场设备目标识别面临的检测困难的问题展开研究,提出一种基于钻井作业现场目标实时监测的方法。采用基于YOLOv3算法的模型,采用mixup混类数据增强扩充数据集,选取k均值聚类算法来获取先验框,采用lable smoothing等策略对算法进行优化,采用自行制作的钻井设备图像集作为数据集,利用云服务器来进行模型的训练。通过分析对比Faster R-CNN算法,结果表明:改进后的YOLOv3算法在检测精度上达到了85.9%,检测效果相比其他算法更好,同时检测速度达到了29FPS,具有较好的鲁棒性,能够满足钻井作业现场实时检测需求。
参考文献
[1]刘彦清.基于YOLO系列的目标检测改进算法[D].长春:吉林大学,2021.
[2]邵延华,张铎,楚红雨,等.基于深度学习的YOLO目标检测综述[J].电子与信息学报,2022,44(10):3697-3708.
[3]邢姗姗,赵文龙.基于YOLO系列算法的复杂场景下无人机目标检测研究综述[J].计算机应用研究,2020,37(S2):28-30.
[4]陈俊.基于YOLOv3算法的目标检测研究与实现[D]成都:电子科技大学,2020.
[5]宋艳艳,谭励,马子豪,等.改进YOLOV3算法的视频目标检测[J].计算机科学与探索,2021,15(1):163-172.
[6]罗建华,黄俊,白鑫宇.改进YOLOv3的道路小目标检测方法[J].小型微型计算机系统,2022,43(3):449-455.
[7]袁小平,马绪起,刘赛.改进YOLOv3的行人车辆目标检测算法[J].科学技术与工程,2021,21(8):3192-3198.
[8]何东,陈金令,王熙.基于改进YOLOv3的红外行人目标检测[J].中国科技论文,2021,16(7):762-769.
作者单位:钱浩东、刘洋,川庆钻探工程有限公司钻采工程技术研究院;汪影,成都信息工程大学通信工程学院
猜你喜欢
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科学与财富(2016年28期)2016-10-14 23:45:18
电脑知识与技术(2016年5期)2016-04-14 13:48:16
